全文链接:http://tecdat.cn/?p=30360
原文出处:拓端数据部落公众号
随着网络的迅速发展,依托于网络的购物作为一种新型的消费方式,在全国乃至全球范围内飞速发展。电子商务成为越来越多消费者购物的重要途径。我们被客户要求撰写关于网络购物行为的研究报告。
项目计划使用数据挖掘的方法,以京东商城网购用户的网络购物数据为基础,对网络购物行为的三个要素:行为过程、行为结果、行为主体进行分析。
(1)使用关联规则分析方法分析网络购物用户的行为过程,分别探析信誉度、搜索排名对网购用户购买决策的影响程度;
(2)使用聚类分析方法,对网购用户的行为结果进行讨论,发现不同网购群体的网购习惯和特征;
(3)使用分类/预测分析方法,对网购行为主体进行研究。本项目还将引用其它研究的数据及观点对本数据分析所得结论进行比较验证。
本项目的结论为以京东商城为代表的网购平台运营商、商家提供网站管理、网店运营方面的参考,为商家制定网络营销策略提供决策支持。
关联规则挖掘
data1[,i]=as.factor(data1[,i])##将每个变量转成因子形式}
inspect(frequentsets[1:10])#查看频繁项集

从上面的表 可以看到部分频繁出现的一些选项规则,抽取的10个频繁项集的支持度在0.3左右。
然后查看支持度最高的前10个规则

可以看到支持度最高的前十个选项集合(称为频繁项集)的支持度在0.9左右,因此在下面使用apriori模型对数据进行分析时,选取最小支持度为0.9左右,以便发现合适数量的规则。
set of 47 rules
rule length distribution (lhs + rhs):sizes
1 2 3
11 24 12
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.000 2.000 2.000 2.021 2.500 3.000
summary of quality measures:
support confidence lift
Min. :0.9000 Min. :0.9000 Min. :0.9977
1st Qu.:0.9050 1st Qu.:0.9400 1st Qu.:1.0000
Median :0.9150 Median :0.9585 Median :1.0043
Mean :0.9191 Mean :0.9572 Mean :1.0043
3rd Qu.:0.9300 3rd Qu.:0.9846 3rd Qu.:1.0083
Max. :0.9850 Max. :0.9945 Max. :1.0141
mining info:
data ntransactions support confidence
trans 200 0.9 0.3
我们得到规则的概述,可以看到他们的支持度在0.9到0.98之间,置信度也非常高,说明这些规则具有较高的的可预测度(Predictability)。因此从这些规则可以得到比较可靠的推断结论。置信度太低的规则在实际应用中也不会有多大用处。

从规则中剔除掉其他选项的规则后,我们得到以上的规则,从以上规则,我们可以看出网购用户大多通过论坛或者社区的弹窗信息进入网购的页面,他们在论坛中看到了某些用户的评论,并且通过弹窗信息进入购买,而他们选择网购的原因也是因为评论真实性,看到了其他网购的用户经验从而影响他们的购买决策。
对规则进行可视化
plot(rules, method="grouped")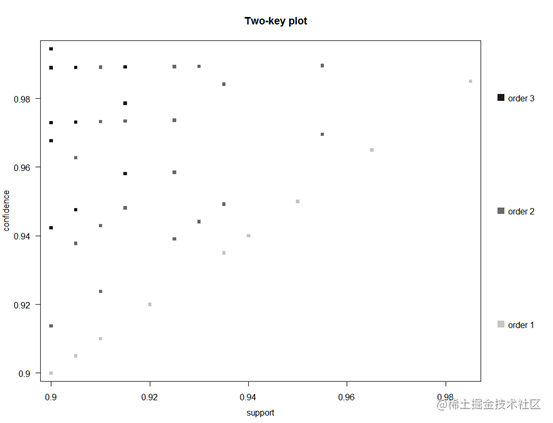
上图表示支持度和置信度的二维散点图,从上图来看,规则的置信度和支持度较高,大部分规则位于左上方,说明规则大多有较高的置信度,具有较好的可信性。
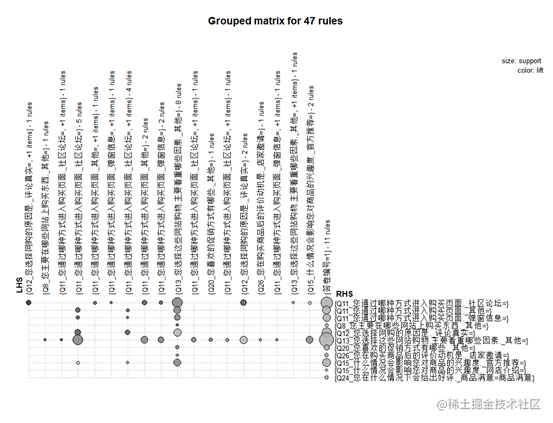
上图表示规则前项和规则后项的联系,图中的点越大表示规则的支持度越高,可以看到规则中社区论坛进入购买页面和选择网购原因是评论真实之间有较高的支持度。
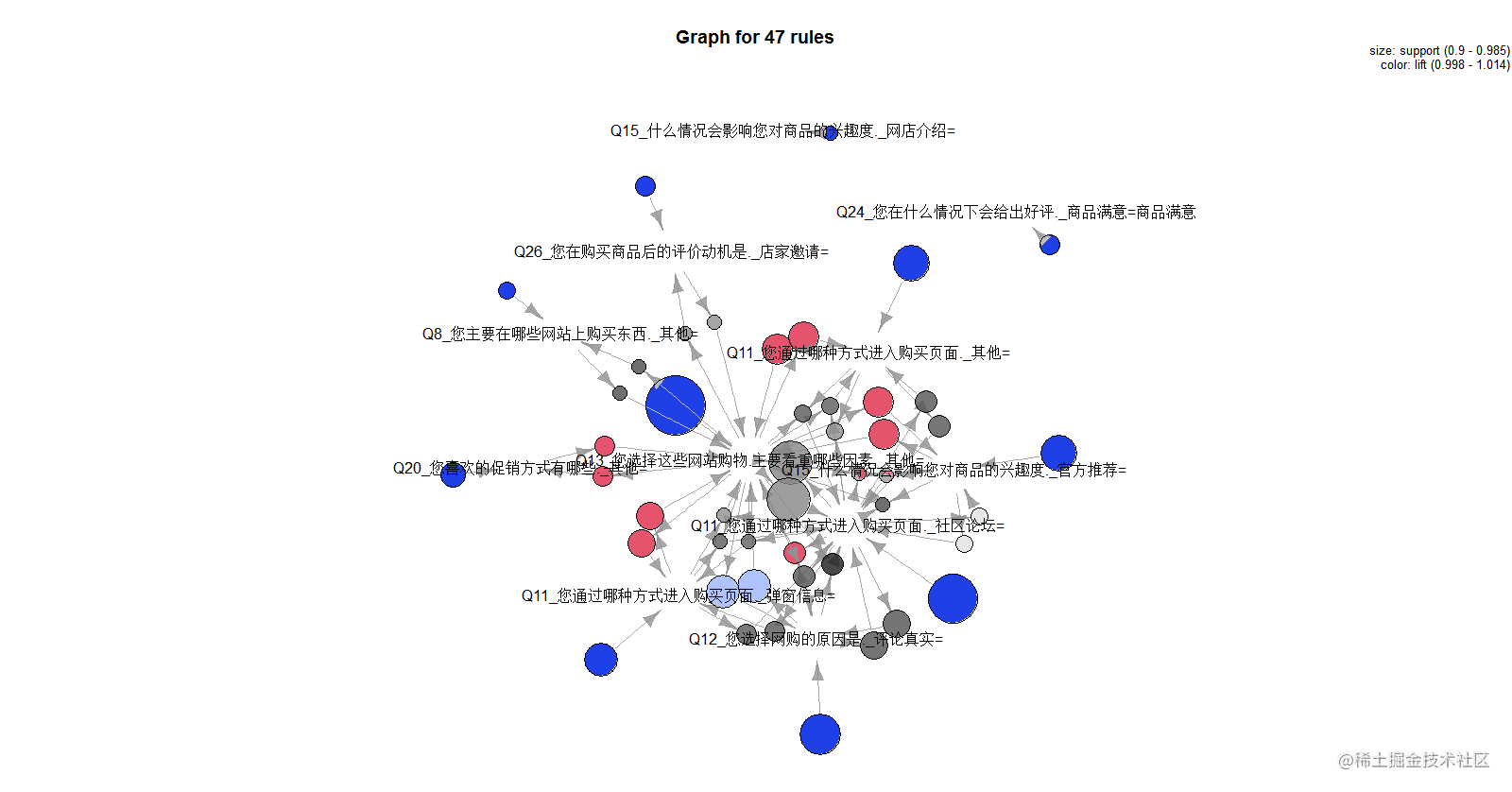
上图是一个规则的网络图表示,箭头表示规则之间的递推关系。从上图我们也可以直观地看到我们得到的规则。
d=dist(data2)#对数据的样本求欧几里得距离
hmod=hclust(d)#使用欧几里得距离对样本进行层次聚类
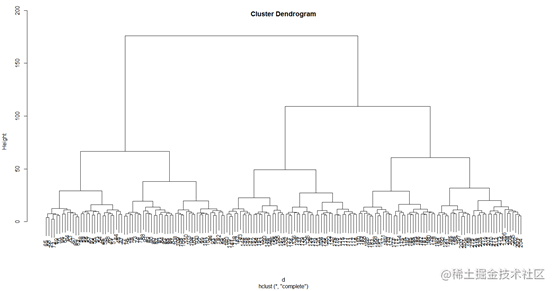
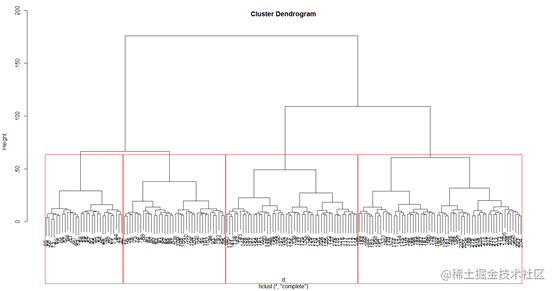
从树状图的结果来看,使用高度为60左右对树状图进行横截,所有样本大致可以分成4类。
cent <- rbind(cent, colMeans(data2[memb == k, , drop = FALSE]))#筛选出第4层次以上的样本}
hc1 <- hclust(dist(cent)^2, method = "cen", members = table(memb))#重新对新样本进行层次聚类
opar <- par(mfrow = c(1, 2))
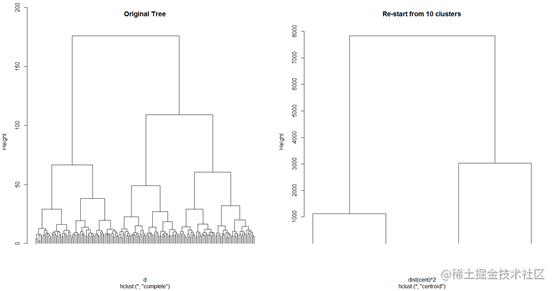
上图是对树重新进行层次聚类的结果与原来树的对比,从左边 我们可以i看到,树具有4个分支,因此可以认为样本大致可以聚成4类。
kmeans聚类
fitted(kc); #查看具体聚类情况
#聚类结果可视化
plot(data2[,c(1:20)], col = kc$cluster); #不同的颜色代表不同的聚类结果。

上图表示不同问题选项之间样本的聚类情况,不同的颜色代表不同的样本,可以看到不同颜色的类别分别聚到了不同的类中,因此类别之间的区分效果良好。
可以看到红色类用户的Q2,Q7,Q11得分较高Q4得分较低,Q21得分较高,蓝色用户Q10Q23的得分较高,黑色用户的得分分布比较普遍,在每个问题中不同选项均有分布。绿色用户Q2,Q19得分较低,Q10的得分较高。
可以看到红色用户大多是年龄较大,4线城市的用户,接触网购不多,因此也不会使用手机电脑网络等方式进入网购页面。蓝色用户代表接触网购时间较长的用户,他们进入网络页面的方式大多是搜索引擎,他们大多熟悉网购操作,对自己需要的商品也比较熟悉,然而一般对网购不进行评论,除非对商品非常满意。绿色是年龄较小的用户,但是他们接触网络的时间也较长,大多是青少年,因此接触新兴事物的兴趣较大,因此他们的网购花费较低,但是网购的频率较高。
决策树
将Q30_总体而言,您对网购是否满意?的答案作为网购用户分类的分类目标属性,使用其他属性作为分类属性,对数据进行分类
draw.tree(CARTmodel)交叉验证的估计误差(“xerror”列),以及标准误差(“xstd”列),平均相对误差=xerror±xstd
printcp(CARTmodel)
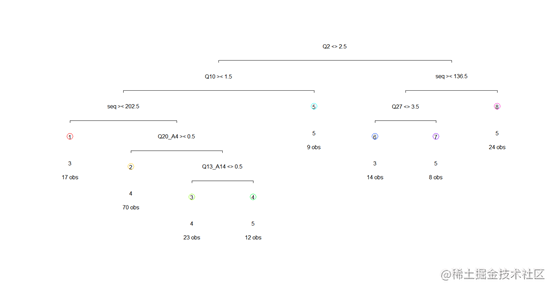
> CARTmodelcptable[which.min(CARTmodelcptable[,"xerror"]),"CP"]
[1] 0.04938272
根据最小误差的最小变异系数来对树进行剪枝。
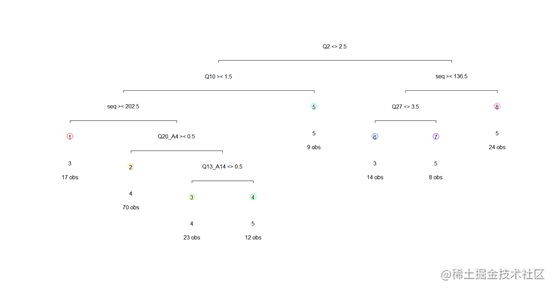
得到剪枝后的决策树。
从决策树图来看 ,我们可以发现问题的选项作为决策树的分支,分别将年龄,网购历史,网站购物主要看重的因素,喜欢的促销方式和网购花费作为决策条件,将样本分成了8个类别。
并使用决策树进行对样本的预测。
> table(pre,data2$Q30)#混淆矩阵
pre 3 4 5 6
3 20 9 2 0
4 9 74 9 1
5 6 13 34 0
6 0 0 0 0
从混淆矩阵的结果来看,对4个类别的预测效果较好,说明模型的拟合效果良好。
