Python爬取网页图片
一、爬取的网站内容
爬取http://www.win4000.com/meinvtag26_1.html的COS图片
二、爬取的网站域名
win4000.com
三、完成内容
(1)抓取的内容分布在电脑主题之家网站的24个页面和24个链接中。 (2)抓取一系列图片,并将图片按页面标题建立文件夹分类存入,存入时根据下载先后顺序排序。 (3)抓取内容的命名与抓取内容相衔接。 (4)使用了反爬技术 (5)图像数据选择JPG文档格式来保存
四、爬虫步骤及代码分析
爬虫的思路分为4步,具体如下:
1、分析目标网页,确定爬取的url路径,headers参数
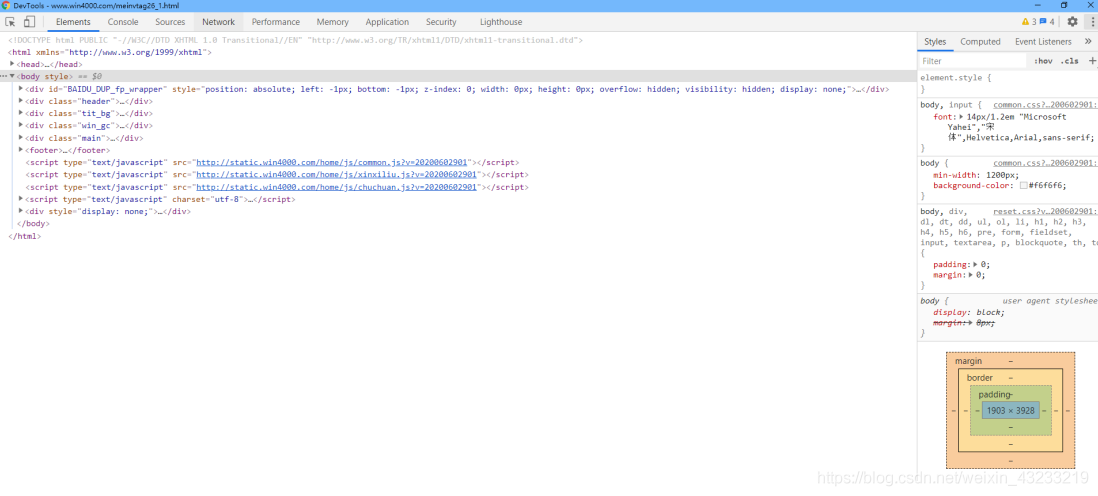
(1)比如按F12后在内容中搜索“王者荣耀”(ctrl+f),寻找该页面的关系
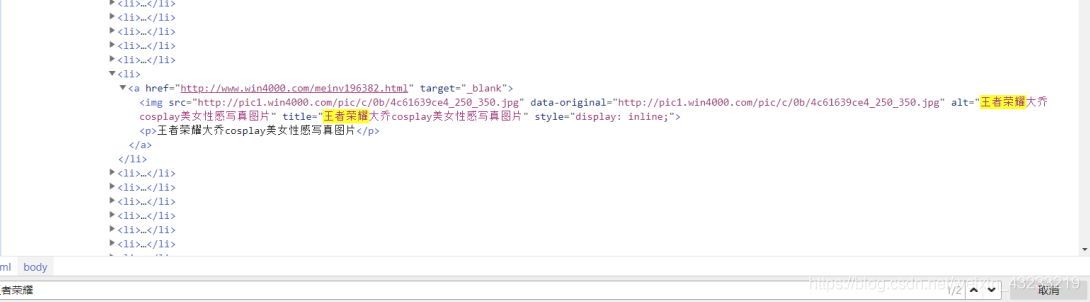
因为可以找到当前网页的数据,所以这个网页是一个静态网页,那么这个网页的URL地址就是地址导航栏中的内容,即:http://www.win4000.com/meinvtag26_1.html
(2)我用谷歌浏览器,在network中找到User-agent
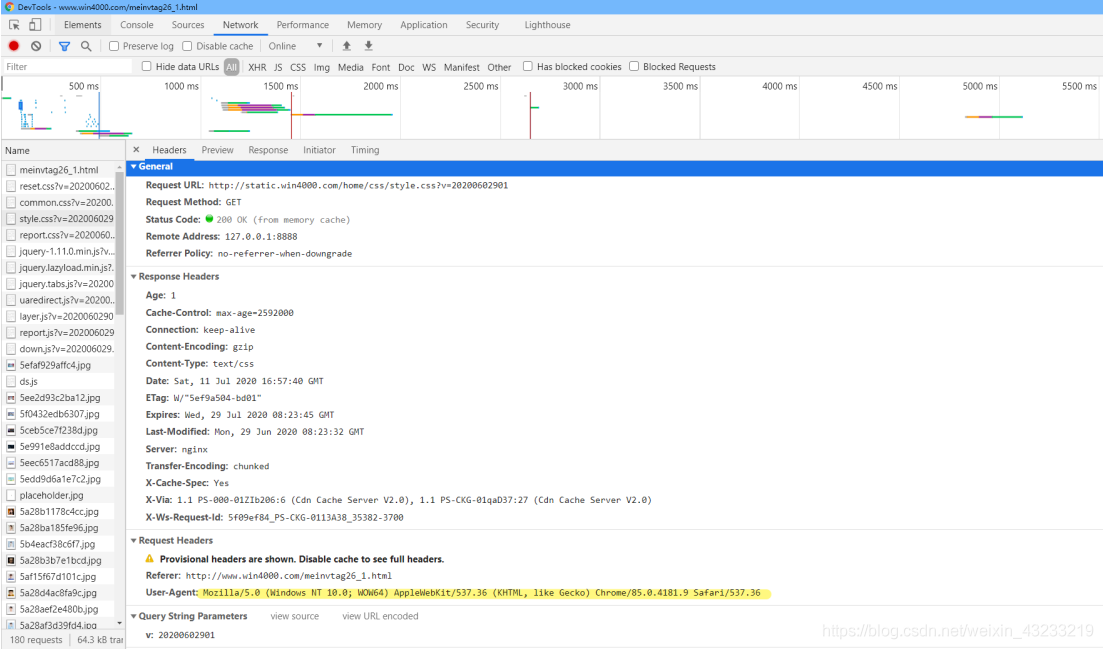
不知道为什么我的谷歌浏览器不能复制network中的User-agent 然后我用到了抓包工具fiddler复制了User-agent
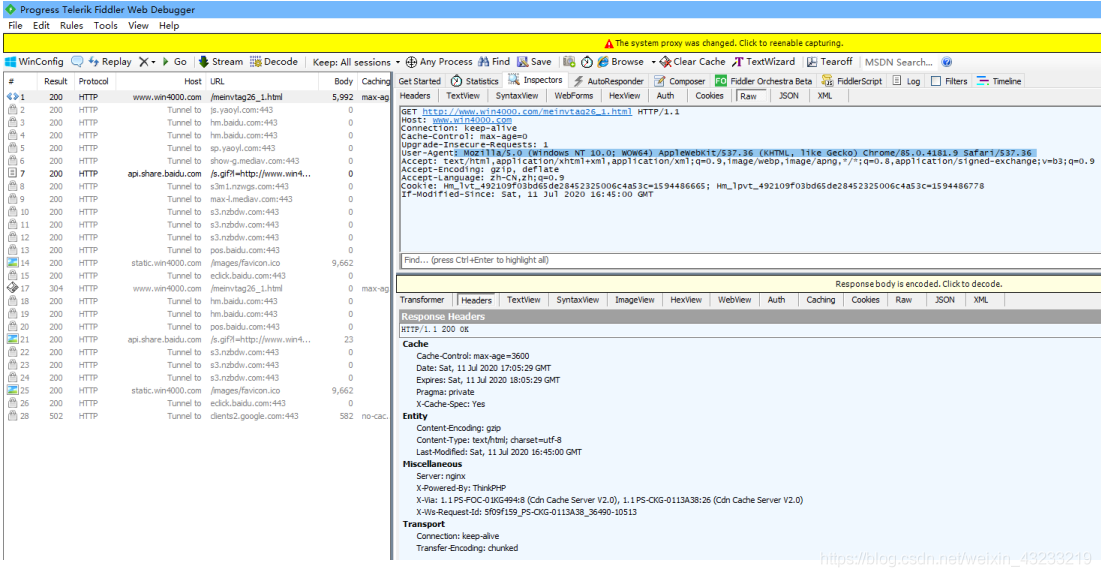
(后来我的”谷歌浏览器不能复制network中的User-agent”问题解决了,原来是我没有用鼠标划取选择的内容…)
(3)代码如下: 1、确定爬取的url路径,headers参数
base_url = 'http://www.win4000.com/meinvtag26_{}.html'.format(page)
##构建一个base_url来存放URL地址
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4181.9 Safari/537.36'}
##构建一个hearders参数来伪装为一个浏览器用户,构造出一个身份2、发送请求 – requests 模拟浏览器发送请求,获取响应数据
(1)首先先导入第三方模块
import requests ##安装后导入第三方模块 requests (HTTP 客户端库)(2)创建response,data 2、发送请求 – requests 模拟浏览器发送请求,获取响应数据
response = requests.get(base_url, headers=headers)
##调出静态网页的get方法,获取该网页的URL,将关键字base_url和headers传入
##进方法中去,并创建一个response对象来接收
data = response.text
##从response对象中获取数据,因为数据是字符串类型的所以用".text"来提取,
##并建立一个data变量来接收(3)但是首先要先输出测试代码是否可以成功运行,确认数据存在后再进行下一步操作
print(data)##确定代码是否可以成功运行,如果成功运行则可以注释掉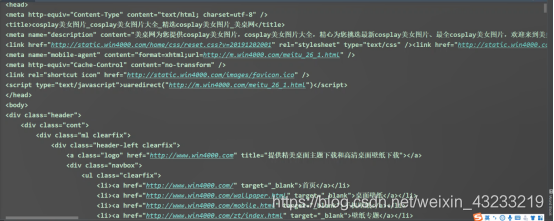
在pycharm中搜索“圣诞节美女”,因为有显示,代表代码可以成功运行,进行下一步的操作

3、解析数据 – parsel 转化为Selector对象,Selector对象具有xpath的方法,能够对转化的数据进行处理
(1)获取当前页面的每一个URL地址

可以看见a标签中的详细地址,点进去后发现当前相册每一个地址都是包裹在a标签下的,每一个a标签对应的href值即是每一个相册的url地址
(2)把相册内部的图片解析出来 进入一个相册后发现img标签内有src,点击进去后看见该相册内的一张高清大图

相册内部每一个src属性就是每一张图片的链接地址
(3)安装第三方模块
import parsel ##安装后导入第三方模块 parsel(数据解析模块)
import os ##系统自带模块,无需安装,直接导入第三方模块 os( 4 ) 将data转化为Selector对象 3、解析数据 – parsel 转化为Selector对象,Selector对象具有xpath的方法,能够对转化的数据进行处理
html_data = parsel.Selector(data)##转换对象,将data数据传递进变量html_data中,即将data数据自动转换为Selector对象 用“print(html_data)”打印html_data发现他就是一个Selector对象

(5)将data转化为Selector对象 将data转化为Selector对象解析成功后才可以与xpath进行交互 在页面中按<class=”Left_bar>,
- ,
- ,顺序查找
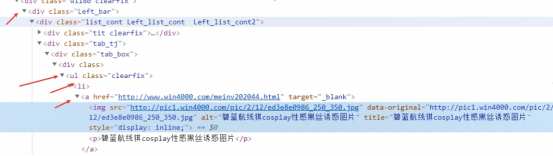
并在最后a标签中的href属性,再用“.extract()”方法将Selector数据取出
data_list = html_data.xpath('//div[@class="Left_bar"]//ul/li/a/@href|//div[@class="Left_bar"]//ul/li/a/img/@title').extract()
#将转化为Selector对象的data_list运用xpath,在div中跨节点找到“class="Left_bar"进行精确定位再按照同样跨节点的方式依次找到
- ,
- ,,@a标签中的href属性,再用“.extract()”方法将Selector数据取出,并创建一个data_list变量来接收
(6)打印data_list
“print(data_list)”打印data_list出来发现是一个一个的字符串
4、保存数据
(1)观察不同的分页,得出规律
发现是通过26_xxx最后一个数字来实现分页效果 for page in range(1, 6):#构建翻页的范围,从1开始到6(即第5页)结束
base_url = 'http://www.win4000.com/meinvtag26_{}.html'.format(page) ##构建一个base_url来存放URL地址
##构建一个“.format(page)”来传入页数(2)获取相册地址与名字,并对返回的列表分组
data_list = html_data.xpath('//div[@class="Left_bar"]//ul/li/a/@href|//div[@class="Left_bar"]//ul/li/a/img/@title').extract() #获取相册的名字,返回的是一个列表
#使用列表推导式对列表进行分组
data_list = [data_list[i:i + 2] for i in range(0, len(data_list), 2)]#将相册的名称和相册的url地址进行分组
(3)遍历列表并创建图片文件夹
遍历列表元素
for alist in data_list:
html_url = alist[0]#取到每一个相册的URl地址
file_name = alist[1]#取到每一个相册的名称
创建图片的文件夹
root = 'G:/COS1/'
if not os.path.exists('img\' + file_name):
os.mkdir('img\' + file_name)#如果没有存在当前文件夹,则创建文件夹
print('正在下载:', file_name)#打印出正在下载的图片名称(4)观察每一个相册页面的地址,发现规律
for url in range(1, int(page_num) + 1):
# 构建相册翻页的url地址
url_list = html_url.split('.')
all_url = url_list[0] + '.' + url_list[1] + '.' + url_list[2] + '_' + str(url) + '.' + url_list[3]
#嵌套出当前相册的每一张图片的URL地址,并拼接(5)
发送详情页的请求,解析详情页的图片url地址
response_3 = requests.get(all_url, headers=headers).text
html_3 = parsel.Selector(response_3)
img_url = html_3.xpath('//div[@class="pic-meinv"]//img/@data-original').extract_first()
#因为仅当他加载图片时才返回图片数据,所以这个网页是软加载图片
#将转化为Selector对象的html_3运用xpath,在div中跨节点找到“class="pic-meinv"进行精确定位
#再按照同样跨节点的方式依次找到<img>,@a标签中的hdata-original属性,并创建一个img_url变量来接收
#使用“.extract_first()”提取出整一个数据,如果不加则只有一张图片
print(img_url)#请求图片的url地址
img_data = requests.get(img_url, headers=headers).content
#图片的文件名
img_name = str(url) + '.jpg'#准备文件名称
#取当前for循环的索引做为文件名
(5)保存数据
with open('img\{}\'.format(file_name) + img_name, 'wb') as f:
print('下载完成:', img_name)
f.write(img_data)#写入文件数据完整代码如下:
import requests ##安装后导入第三方模块 requests(HTTP 客户端库)
import parsel ##安装后导入第三方模块 parsel(数据解析)
import os ##系统自带模块,无需安装,直接导入第三方模块 os(操作系统交互功能)
for page in range(1, 6):#构建翻页的范围,从1开始到6(即第5页)结束
print('=======================正在爬取第{}页数据====================='.format(page))
# 1、确定爬取的url路径,headers参数
base_url = 'http://www.win4000.com/meinvtag26_{}.html'.format(page) ##构建一个base_url来存放URL地址
##构建一个“.format(page)”来传入页数
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4181.9 Safari/537.36'}
#构建一个hearders参数来伪装为一个浏览器用户,构造出一个身份
# 2、发送请求 -- requests 模拟浏览器发送请求,获取响应数据
response = requests.get(base_url, headers=headers)
#调出静态网页的get方法,获取该网页的URL,将关键字base_url和headers传入进方法中去,并创建一个response对象来接收
data = response.text
#从response对象中获取数据,因为数据是字符串类型的所以用".text"来提取,并建立一个data变量来接收
# print(data)##确定代码是否可以成功运行,如果成功运行则可以注释掉
# 3、解析数据 -- parsel 转化为Selector对象,Selector对象具有xpath的方法,能够对转化的数据进行处理
html_data = parsel.Selector(data)
#转换对象,将data数据传递进变量html_data中,即将data数据自动转换为Selector对象
data_list = html_data.xpath('//div[@class="Left_bar"]//ul/li/a/@href|//div[@class="Left_bar"]//ul/li/a/img/@title').extract()
#获取相册的名字,返回的是一个列表
#将转化为Selector对象的data_list运用xpath,在div中跨节点找到“class="Left_bar"进行精确定位
# 再按照同样跨节点的方式依次找到<ul>,<li> ,<a>,@a标签中的href属性,再用“.extract()”方法将Selector数据取出,并创建一个data_list变量来接收
# print(data_list)
# 使用列表推导式对列表进行分组
data_list = [data_list[i:i + 2] for i in range(0, len(data_list), 2)]#将相册的名称和相册的url地址进行分组
# print(data_list)
# 遍历列表元素
for alist in data_list:
html_url = alist[0]#取到每一个相册的URl地址
file_name = alist[1]#取到每一个相册的名称
# print(html_url, file_name)
# 创建图片的文件夹
root = 'G:/COS1/'
if not os.path.exists('img\\' + file_name):
os.mkdir('img\\' + file_name)#如果没有存在当前文件夹,则创建文件夹
print('正在下载:', file_name)#打印出正在下载的图片名称
# 发送详情页的请求,解析出总页数
response_2 = requests.get(html_url, headers=headers).text
html_2 = parsel.Selector(response_2)
page_num = html_2.xpath('//div[@class="ptitle"]//em/text()').extract_first()
# print(page_num)
for url in range(1, int(page_num) + 1):
# 构建相册翻页的url地址
url_list = html_url.split('.')
all_url = url_list[0] + '.' + url_list[1] + '.' + url_list[2] + '_' + str(url) + '.' + url_list[3]
#嵌套出当前相册的每一张图片的URL地址,并拼接
# print(all_url)
# 发送详情页的请求,解析详情页的图片url地址
response_3 = requests.get(all_url, headers=headers).text
html_3 = parsel.Selector(response_3)
img_url = html_3.xpath('//div[@class="pic-meinv"]//img/@data-original').extract_first()
#因为仅当他加载图片时才返回图片数据,所以这个网页是软加载图片
# 将转化为Selector对象的html_3运用xpath,在div中跨节点找到“class="pic-meinv"进行精确定位
# 再按照同样跨节点的方式依次找到<img>,@a标签中的hdata-original属性,并创建一个img_url变量来接收
#使用“.extract_first()”提取出整一个数据,如果不加则只有一张图片
# print(img_url)
# 请求图片的url地址
img_data = requests.get(img_url, headers=headers).content
# 图片的文件名
img_name = str(url) + '.jpg'#准备文件名称
#取当前for循环的索引做为文件名
# 4、保存数据
with open('img\\{}\\'.format(file_name) + img_name, 'wb') as f:
print('下载完成:', img_name)
f.write(img_data)#写入文件数据</code></pre></div></div>