网易云音乐热门作品名字和链接抓取(html5lib篇)
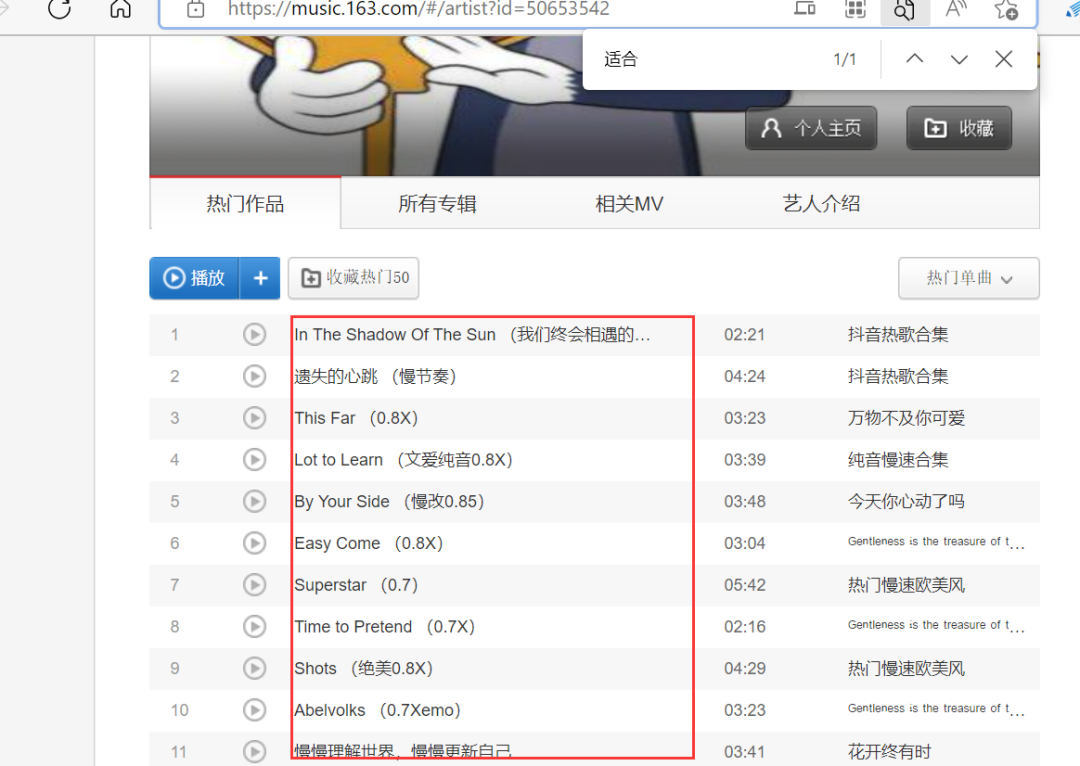
前几天在Python白银交流群有个叫【O|】的粉丝问了一道关于网易云音乐热门作品名字和链接抓取的问题,获取源码之后,发现使用xpath匹配拿不到东西,从响应来看,确实是可以看得到源码的。
网易云音乐热门作品名字和链接抓取(pyquery篇)
前几天在Python白银交流群有个叫【O|】的粉丝问了一道关于网易云音乐热门作品名字和链接抓取的问题,获取源码之后,发现使用xpath匹配拿不到东西,从响应来看,确实是可以看得到源码的。

计算XPath表达式
XPath(XML路径语言)是一种基于XML的表达式语言,用于从XML文档获取数据。使用类中的%XML.XPATH.Document,可以轻松地计算XPath表达式(给定提供的任意XML文档)。
技术分享 | Web 控件定位与常见操作
在做 Web 自动化时,最根本的就是操作页面上的元素,首先要能找到这些元素,然后才能操作这些元素。工具或代码无法像测试人员一样用肉眼来分辨页面上的元素。那么要如何定位到这些元素,本章会介绍各种定位元素的方法。
一日一技:Selenium 抓不到的内容
有一些同学在写爬虫的时候,过于依赖 Selenium,觉得只要使用模拟浏览器,在不被网站屏蔽的情况下,就可以爬到任何内容。

一日一技:Selenium 抓不到的内容
有一些同学在写爬虫的时候,过于依赖 Selenium,觉得只要使用模拟浏览器,在不被网站屏蔽的情况下,就可以爬到任何内容。

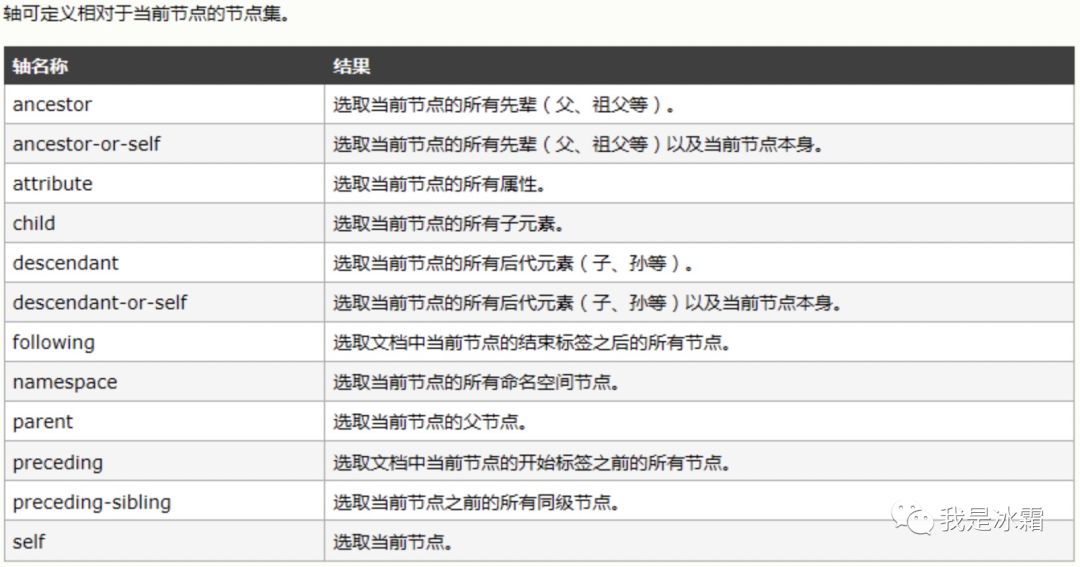
XPATH定位(进阶篇)
当某个元素的各个属性及其组合都不足以定位时,可以利用其兄弟节点或者父节点等各种可以定位的元素进行定位。
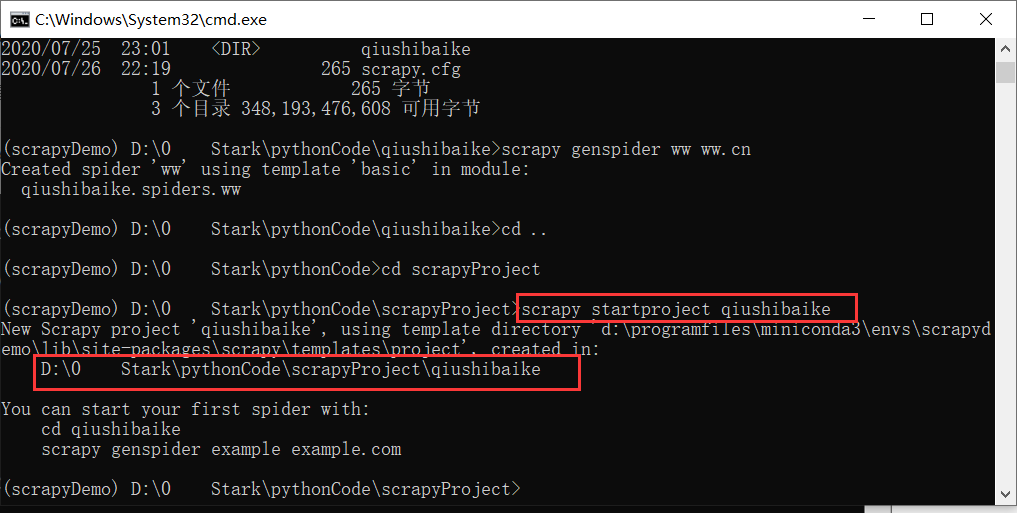
使用Scrapy网络爬虫框架小试牛刀
默认情况下,直接pip install scrapy可能会失败,如果没有换源,加上临时源安装试试,这里使用的是清华源,常见安装问题可以参考这个文章:Windows下安装Scrapy方法及常见安装问题总结——Scrapy安装教程。
《手把手教你》系列练习篇之5-python+ selenium自动化测试(详细教程)
今天我们继续前边的练习,学习和练习一下:如何使用webdriver方法获取操作复选框-CheckBox、测试不同的分辨率、如何断言title、如何获取某一个元素的text属性值等等,这些小练习,来巩固基础。
python爬虫(四)
一.JSON模块
Json是一种网络中常用的数据交换类型,一个文件要想在网络进行传输,需要将文件转换为一种便于在网络之间传输的类型,便于人们进行阅读,json就是这样应运而生的。Json中的数据是由键值对构成的,与python中字典不同的是,json将数据转换为一种字符串的形式。
在电脑上如何安装json呢?
打开电脑的cmd,输入pip install json,然后在python命令行中运行 import json,如果没有出现什么错误,说明已经成功安装了。
Json中有许多模块,我目前在爬虫中用到的就两个方法,其他的
方法等碰见了再讲解。
json.loads() #把json字符串转换为python类型
def loads(s, encoding=None, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw):
这是loads的源代码,可以参考一下。
爬虫入门经典(十一) | 一文带你爬取传统古诗词(超级简单!)
中国文学源远流长,早在远古时代,虽然文字还没有产生,但在人民中间已经流传着神话传说和民间歌谣等口头文学。随着时间线的推移,先后出现了:诗经(西周)——楚辞(战国)——乐府(汉)——赋(晋)——唐诗——宋词——元曲——明清小说。
还有 Selenium 抓不到的内容?
有一些同学在写爬虫的时候,过于依赖 Selenium,觉得只要使用模拟浏览器,在不被网站屏蔽的情况下,就可以爬到任何内容。

Java不适合做爬虫?试试这个工具!
TJ君前几天不能用电脑的时候,就在逛各种论坛,逛着逛着就想,是不是可以弄个爬虫,把这些网上的信息都下下来,自己有空时慢慢研究来着,也是赶巧,这么想的时候正好看到一个爬虫项目,用了下感觉还不错,赶紧来和大家分享以下~

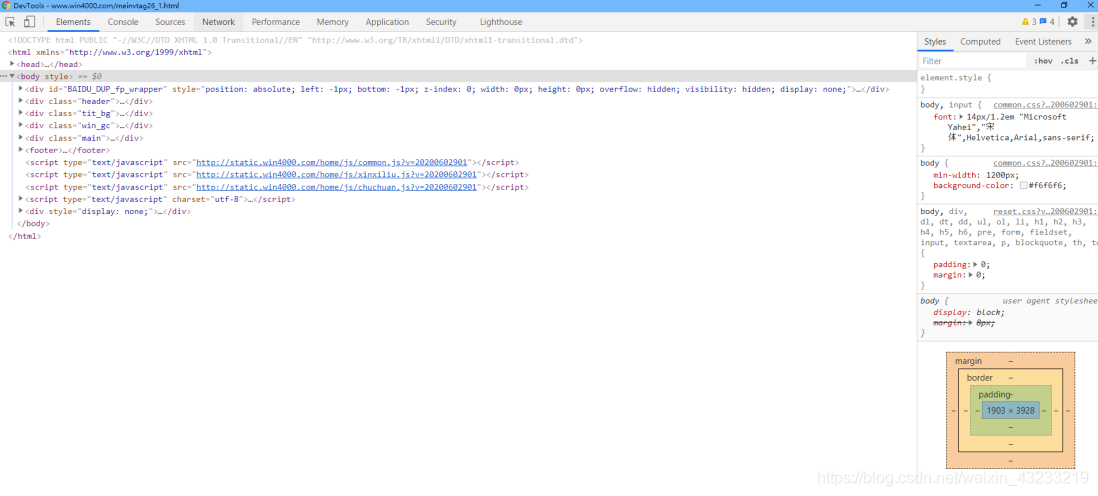
用Python爬取COS网页全部图片
爬取http://www.win4000.com/meinvtag26_1.html的COS图片
web自动化测试入门篇03——selenium使用教程
web自动化测试作为软件自动化测试领域中绕不过去的一个“香饽饽”,通常都会作为广大测试从业者的首选学习对象,相较于C/S架构的自动化来说,B/S有着其无法忽视的诸多优势,从行业发展趋、研发模式特点、测试工具支持,其整体的完整生态已经远远超过了C/S架构方面的测试价值。接上一篇文章,我们将继续深入探讨Selenium的相关使用方法与技巧。

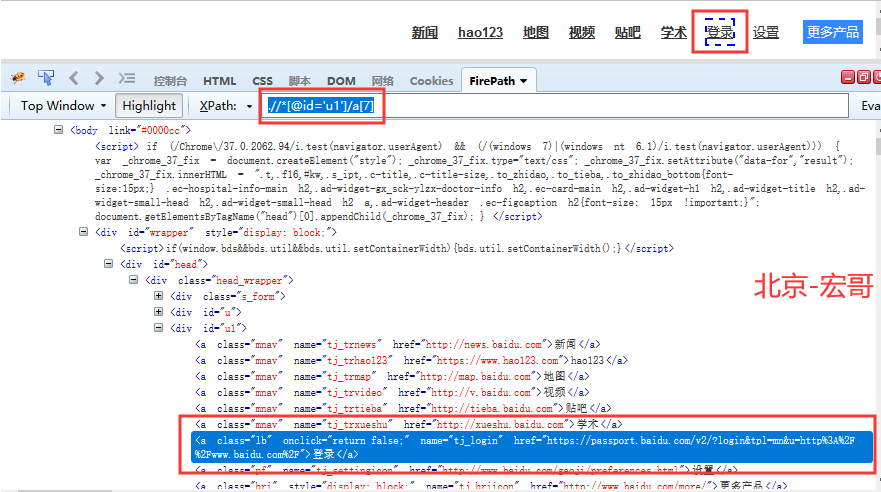
XPath语法
XPath语法
XPath路径表达式:XPath使用路径表达式来选取XML文档中的节点或者节点集。
XPath节点:元素、属性、文本、命名空间、处理指令、注释、根节点。
XPath语法。(注:下面的例
Scrapy spider 主要方法
Spider 类是 Scrapy 中的主要核心类,它定义了爬取网站的规则。 Spider 是循环爬取,它的而爬取步骤是:
python3 爬虫第二步Selenium 使用简单的方式抓取复杂的页面信息
网站复杂度增加,爬虫编写的方式也会随着增加。使用Selenium 可以通过简单的方式抓取复杂的网站页面,得到想要的信息。
项目实战 | 手把手做一款小说阅读器
前一段时间书荒的时候,在喜马拉雅APP发现一个主播播讲的小说-大王饶命。听起来感觉很好笑,挺有意思的,但是只有前200张是免费的,后面就要收费。一章两毛钱,本来是想要买一下,发现说的进度比较慢而且整本书要1300多张,算了一下,需要200大洋才行,而且等他说完,还不知道要到什么时候去。所以就找文字版的来读,文字版又有它的缺点,你必须手眼联动才行。如果要忙别的事情,但是又抑制不住想看的冲动,就很纠结了。在网上找了一圈,没有其他的音频。而且以前用的那些有阅读功能的软件,比如微信阅读、追书神器也都开始收费了。那怎么办呢?这能难倒一个程序员吗?必须滴、坚决滴不能。我用的可是世界上最好的编程语言-Python

用python实现自己的小说阅读器
前一段时间书荒的时候,在喜马拉雅APP发现一个主播播讲的小说-大王饶命。听起来感觉很好笑,挺有意思的,但是只有前200张是免费的,后面就要收费。一章两毛钱,本来是想要买一下,发现说的进度比较慢而且整本书要1300多张,算了一下,需要200大洋才行,而且等他说完,还不知道要到什么时候去。所以就找文字版的来读,文字版又有它的缺点,你必须手眼联动才行。如果要忙别的事情,但是又抑制不住想看的冲动,就很纠结了。在网上找了一圈,没有其他的音频。而且以前用的那些有阅读功能的软件,比如微信阅读、追书神器也都开始收费了。那怎么办呢?这能难倒一个程序员吗?必须滴、坚决滴不能。我用的可是世界上最好的编程语言-Python