scrapy 爬虫
其实也可以由我们自行创建itcast.py并编写上面的代码,只不过使用命令可以免去编写固定代码的麻烦
Python 爬虫(六):Scrapy 爬取景区信息
Scrapy 是一个使用 Python 语言开发,为了爬取网站数据,提取结构性数据而编写的应用框架,它用途广泛,比如:数据挖掘、监测和自动化测试。安装使用终端命令 pip install Scrapy 即可。

如何使用Scrapy框架抓取电影数据
随着互联网的普及和电影市场的繁荣,越来越多的人开始关注电影排行榜和评分,了解电影的排行榜和评分可以帮助我们更好地了解观众的喜好和市场趋势.豆瓣电影是一个广受欢迎的电影评分和评论网站,它提供了丰富的电影信息和用户评价。因此,爬取豆瓣电影排行榜的数据对于电影从业者和电影爱好者来说都具有重要意义。
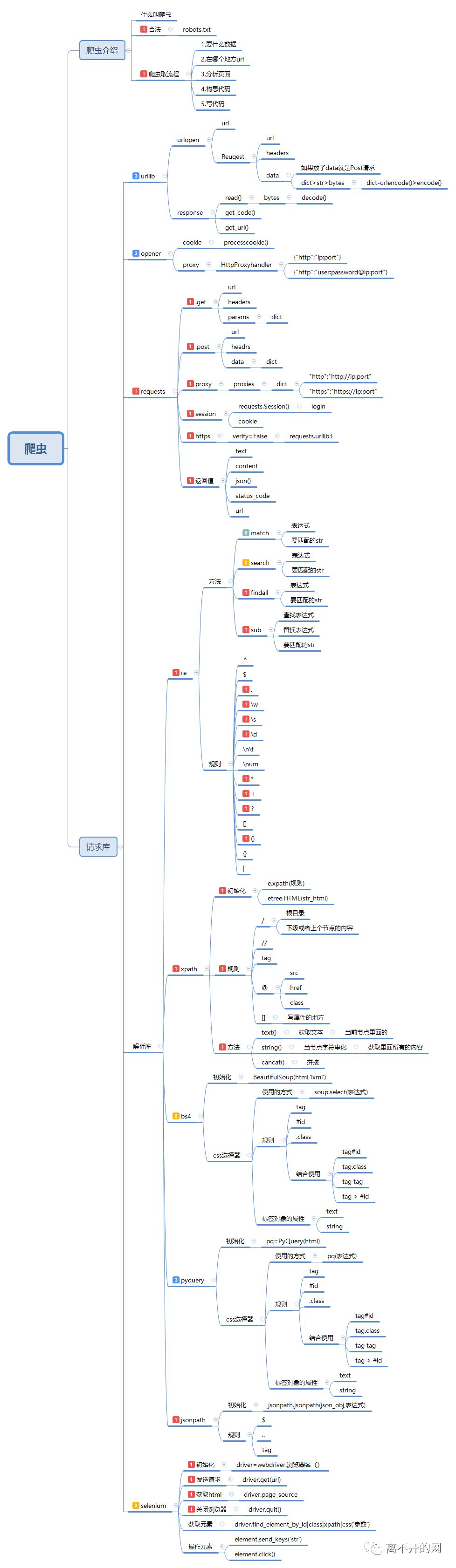
【预备知识篇】python网络爬虫初步_01
网络爬虫,是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本。通俗来说就是模拟用户在浏览器上的操作,从特定网站,自动提取对自己有价值的信息。主要通过查找域名对应的IP地址、向IP对应的服务器发送请求、服务器响应请求,发回网页内容、浏览器解析网页内容四个步骤来实现。

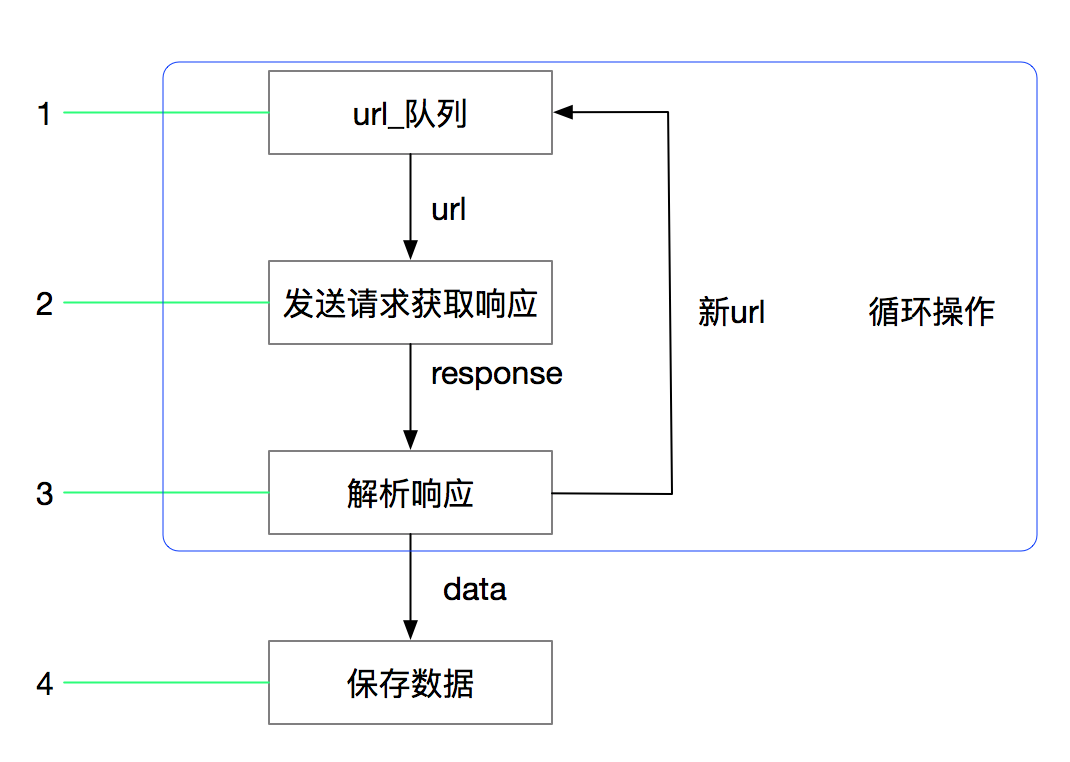
Python爬虫之scrapy的概念作用和工作流程
Scrapy是一个Python编写的开源网络爬虫框架。它是一个被设计用于爬取网络数据、提取结构性数据的框架。

运行Scrapy程序时出现No module named win32api问题的解决思路和方法
有小伙伴在群里边反映说在使用Scrapy的时候,发现创建项目一切顺利,但是在执行Scrapy爬虫程序的时候却出现下列报错:“No module named win32api”,如下图所示,但是不知道怎么破,今天就这个问题讲解一下解决方案。
scrapy的概念和流程
请注意,本文编写于 1724 天前,最后修改于 993 天前,其中某些信息可能已经过时。
用Scrapy爬取当当网书籍信息
今天通过创建一个爬取当当网2018年图书销售榜单的项目来认识一下Scrapy的工作流程
爬虫系列(18)Python-Spider。
Python-Spider作业
day01
了解爬虫的主要用途
了解反爬虫的基本手段
理解爬虫的开发思路
熟悉使用Chrome的开发者工具
使用urllib库获取《糗事百科》前3页数据
使用urllib库登录《速学堂》官网
爬取
https://knewone.com/
58同城二手信息
day02
获取豆瓣电影分类排行榜 -前100条数据
数据opener的用法
opener的构建
代理的使
cookie的使用
了解cookie的作用
使用cookie登录虾米音乐
使用requests 库获取数据《纵横
使用Scrapy框架抓取小红书上的#杭州亚运会#相关内容
杭州亚运会作为一项重要的国际体育盛事,吸引了全球的关注。在亚运会期间,人们对于相关新闻、赛事、选手等信息都表现出了浓厚的兴趣。而小红书作为一个以分享生活和购物为主题的社交平台,也有大量关于#杭州亚运会#的用户笔记,文将介绍如何使用Python的Scrapy框架来抓取小红书上的经验与#杭州亚运会#相关的内容,以便我们能够更方便地获取这些信息。
使用Scrapy框架抓取小红书上的#杭州亚运会#相关内容
杭州亚运会作为一项重要的国际体育盛事,吸引了全球的关注。在亚运会期间,人们对于相关新闻、赛事、选手等信息都表现出了浓厚的兴趣。而小红书作为一个以分享生活和购物为主题的社交平台,也有大量关于#杭州亚运会#的用户笔记,文将介绍如何使用Python的Scrapy框架来抓取小红书上的经验与#杭州亚运会#相关的内容,以便我们能够更方便地获取这些信息。
python常见的5种框架
scrapy框架是一套比较成熟的python爬虫框架,是使用python开发的快速、高层次的信息爬取框架,可以高效率地爬取web页面并提取出我们关注的结构化数据。
python常见的5种框架
scrapy框架是一套比较成熟的python爬虫框架,是使用python开发的快速、高层次的信息爬取框架,可以高效率地爬取web页面并提取出我们关注的结构化数据。
Scrapy框架基础
简介
Scrapy是一个高级的Python爬虫框架,它不仅包含了爬虫的特性,还可以方便的将爬虫数据保存到csv、json等文件中。
首先我们安装Scrapy。
其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy 使用了 Twisted异
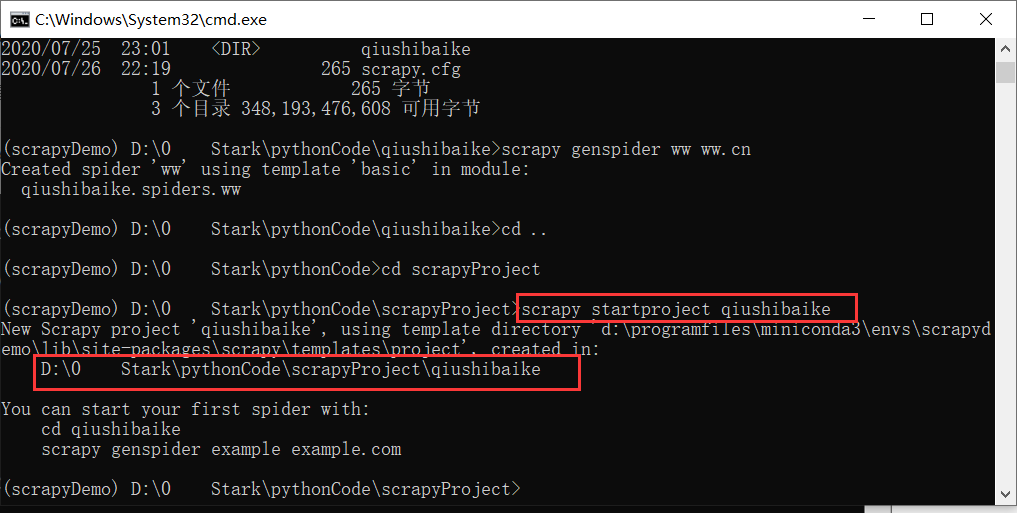
手把手教你如何新建scrapy爬虫框架的第一个项目(下)
前几天小编带大家学会了如何在Scrapy框架下创建属于自己的第一个爬虫项目(上),今天我们进一步深入的了解Scrapy爬虫项目创建,这里以伯乐在线网站的所有文章页为例进行说明。

毕业设计(一):爬虫框架scrapy
1、scrapy startproject Demo(项目名):创建一个新的项目。
数道云科技深度解析:国内外大数据挖掘工具有哪些?有什么特点?
数据挖掘工具是使用大数据挖掘技术从互联网的海量数据中发现、采集并挖掘出有有价值数据一种软件。利用特定的技术,例如:Hadoop、Spark……实现对互联网非机构化的大数据进行挖掘并获得正确、有价值数据的一种快速、便捷的方法。
手把手教你如何新建scrapy爬虫框架的第一个项目(下)
前几天小编带大家学会了如何在Scrapy框架下创建属于自己的第一个爬虫项目,今天我们进一步深入的了解Scrapy爬虫项目创建,这里以伯乐在线网站的所有文章页为例进行说明。

Python:Spider
Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。 换句话说,Spider就是您定义爬取的动作及分析某个网页(或者是有些网页)的地方。
使用Scrapy网络爬虫框架小试牛刀
默认情况下,直接pip install scrapy可能会失败,如果没有换源,加上临时源安装试试,这里使用的是清华源,常见安装问题可以参考这个文章:Windows下安装Scrapy方法及常见安装问题总结——Scrapy安装教程。