如何使用Scrapy框架抓取电影数据
随着互联网的普及和电影市场的繁荣,越来越多的人开始关注电影排行榜和评分,了解电影的排行榜和评分可以帮助我们更好地了解观众的喜好和市场趋势.豆瓣电影是一个广受欢迎的电影评分和评论网站,它提供了丰富的电影信息和用户评价。因此,爬取豆瓣电影排行榜的数据对于电影从业者和电影爱好者来说都具有重要意义。
Symfony Panther在网络数据采集中的应用
在当今数字化时代,网络数据采集已成为获取信息的重要手段之一。Symfony Panther,作为Symfony生态系统中的一个强大工具,为开发者提供了一种简单、高效的方式来模拟浏览器行为,实现网络数据的采集和自动化操作。本文将通过一个实际案例——使用Symfony Panther下载网易云音乐,来展示其在网络数据采集中的应用。
在Pyppeteer中实现反爬虫策略和数据保护
爬虫是我们获取互联网数据的神奇工具,但是面对越来越严格的反爬虫措施,我们需要一些我们获取数据的利器来克服这些障碍。本文将带您一起探索如何使用Pyppeteer库来应对这些挑战。
如何用 Python3 和 Playwright 寻找最便宜的暑期旅行机票
想要构建高效且强大的爬虫,Python3 和 Playwright 是最佳组合。Python3 是一种简洁易读的编程语言,拥有丰富的库和框架,可以轻松地开发网络爬虫。Playwright 是一个自动化库,可以模拟浏览器操作,处理复杂的网页和动态内容,提取数据和测试网站。使用 Python3 和 Playwright,你可以编写可靠且可扩展的爬虫,实现数据提取、网络抓取和自动化测试等功能,同时保证代码的可维护性和生产力。

在Windows系统上实现电脑IP更改
今天我要和大家分享一个知识,那就是如何在Windows系统上实现免费的电脑IP更改。你可能会好奇,为什么要更改电脑的IP地址呢?实际上,IP地址在我们的网络连接中起着非常重要的作用,它是我们在互联网上进行通信和访问的标识。而通过更改IP地址,我们可以实现一些有趣和实用的应用。
R语言获取股票信息进行数据分析
style=none&taskId=ufe5a8213-193f-4abf-99f6-220571344f0&title=)

解析Perl爬虫代码:使用WWW::Mechanize::PhantomJS库爬取stackoverflow.com的详细步骤
在这篇文章中,我们将探讨如何使用Perl语言和WWW::Mechanize::PhantomJS库来爬取网站数据。我们的目标是爬取stackoverflow.com的内容,同时使用爬虫代理来和多线程技术以提高爬取效率,并将数据存储到本地。

使用动态IP是否会影响网络
今天我们要谈论的话题是关于动态IP和网络的关系。也许有些小伙伴对这个概念还比较陌生,但别担心,我会简单明了的给你理清楚。让我们一起看看动态IP到底能否影响到网络。
Puppeteer工具简介及其在网页爬取和自动化中的应用
Puppeteer是一个流行的Node.js库,在开发者中广泛使用的用于网页爬取和自动化任务的工具。它提供两种操作模式,即headfull和headless。在headfull模式下,Puppeteer控制的Chrome或Chromium浏览器是有界面的,也就是可以看到浏览器运行的情况。在此模式下,可以使用浏览器的开发者工具进行调试。这种模式非常适合在本地进行开发和调试。而在headless模式下,它在后台运行,没有用户界面,这种模式非常适合在服务器上运行,因为没有界面,所以可以节省很多资源。该工具还提供缓存资源的选项,这可以帮助减少页面加载时间并提高性能。此外,Puppeteer允许开发人员在页面中执行JavaScript代码,并使用代理更改请求的IP地址,这对于匿名请求或从不同区域访问内容很有用。

长效和短效HTTP:哪个适合爬虫的代理类型?
在进行网络爬虫任务时,选择适合的代理类型对爬虫的效率和稳定性至关重要。长效和短效HTTP代理是两种常见的代理类型,它们各具特点和适用场景。本文将为您分享长效和短效HTTP代理的区别以及选择适合爬虫的代理类型的实用技巧,帮助您提升爬虫效率和稳定性。
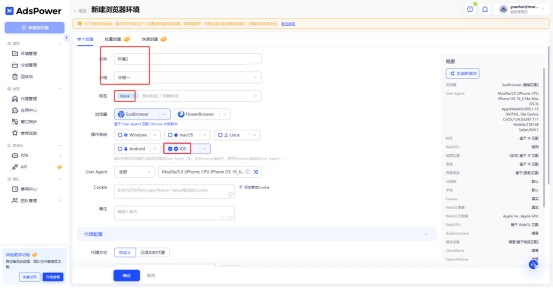
如何在Adspower指纹浏览器中配置IPXProxy,实现TikTok快速访问
许多软件或者网站会追踪用户的IP地址来判断其地理位置,并且会根据地区限制内容的推送。例如你无法直接访问到美区的tiktok,如果你想要畅享全球网络的话,指纹浏览器和代理IP可以帮助到你。那如何快速访问tiktok?下面给大家带来Adspower指纹浏览器配置IPXProxy代理IP的详细教程。
使用Puppeteer提升社交媒体数据分析的精度和效果
社交媒体是互联网上最受欢迎的平台之一,它们包含了大量的用户生成内容,如文本、图片、视频、评论等。这些内容对于分析用户行为、舆情、市场趋势等有着重要的价值。但是,如何从社交媒体上获取这些数据呢?一种常用的方法是使用网络爬虫,即一种自动化地从网页上提取数据的程序。

C++语言实现网络爬虫详细代码
以上代码使用了 libcurl 库,它是一个用于发送 HTTP 请求和处理响应的常用开源库。在代码中,我们首先通过 curl_global_init() 函数初始化 libcurl,然后创建一个 CURL 实例,并设置要抓取的网页地址。接着,我们设置了一个回调函数 writeCallback() 来处理获取到的响应数据,并使用 curl_easy_perform() 函数执行 HTTP 请求。最后,我们打印获取到的网页内容,并清理 CURL 实例和 libcurl。
Puppeteer动态代理实战:提升数据抓取效率
Puppeteer是由Google Chrome团队开发的一个Node.js库,用于控制Chrome或Chromium浏览器。它提供了高级API,可以进行网页自动化操作,包括导航、屏幕截图、生成PDF、捕获网络活动等。在本文中,我们将重点介绍如何使用Puppeteer实现动态代理,以提高数据抓取效率。

Selenium Python 更改 chrome 默认下载目录
关于使用Selenium和Python无法更改Google Chrome默认下载目录的可能问题和解决方法:

Selenium Python 更改 chrome 默认下载目录
关于使用Selenium和Python无法更改Google Chrome默认下载目录的可能问题和解决方法:

C#和HttpClient结合示例:微博热点数据分析
微博是中国最大的社交媒体平台之一,它每天都会发布各种各样的热点话题,反映了网民的关注点和舆论趋势。本文将介绍如何使用C#语言和HttpClient类来实现一个简单的爬虫程序,从微博网站上抓取热点话题的数据,并进行一些基本的分析和可视化。

C#和HttpClient结合示例:微博热点数据分析
微博是中国最大的社交媒体平台之一,它每天都会发布各种各样的热点话题,反映了网民的关注点和舆论趋势。本文将介绍如何使用C#语言和HttpClient类来实现一个简单的爬虫程序,从微博网站上抓取热点话题的数据,并进行一些基本的分析和可视化。

如何用 Python 和 Selenium 构建一个股票分析器
在金融市场中,股票价格是一个重要的指标,它反映了公司的经营状况、市场需求和供应、投资者的预期和情绪等因素。股票价格的变化会影响投资者的决策和收益,因此,实时分析股票价格是一项有价值的技能。在本文中,我们将介绍如何使用 Python 语言和 Selenium 库来实时分析雅虎财经中的股票价格,并展示一个简单的示例代码。

动态ip和静态ip有什么区别?
动态IP和静态IP是两种常见的IP地址类型,它们的主要区别在于IP地址是否固定不变。
