案例分析:并行计算让你的代码“飞”起来
现在的电脑,往往都有多颗核,即使是一部手机,也往往配备了并行处理器,通过多进程和多线程的手段,就可以让多个 CPU 核同时工作,加快任务的执行。
torchpipe : Pytorch 内的多线程计算并行库
云端深度学习的服务的性能加速通常需要算法和工程的协同加速,需要模型推理和计算节点的融合,并保证整个“木桶”没有太明显的短板。

torchpipe : Pytorch 内的多线程计算并行库
云端深度学习的服务的性能加速通常需要算法和工程的协同加速,需要模型推理和计算节点的融合,并保证整个“木桶”没有太明显的短板。

正版IDM激活:地表最强多线程神器!终极解锁,疑幻疑真,支持更新!
IDM是一款超级牛逼的互联网文件下载神器,它可以满足浏览器端大部分网站的文件下载需求。

【Python自动化】多线程BFS站点结构爬虫代码,支持中断恢复,带注释
代码语言:javascript复制from collections import deque
from urllib.parse import urljoin, urlparse
import requests
from pyquery import PyQuery as pq
import re
from EpubCrawler.util import request_retry
import traceback
from functools import reduce
from concurrent.f...
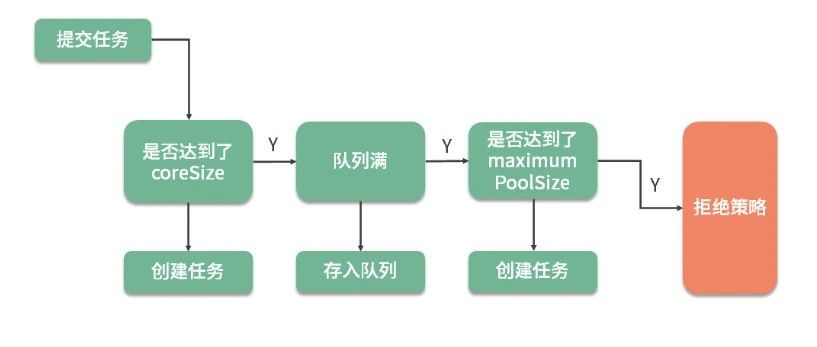
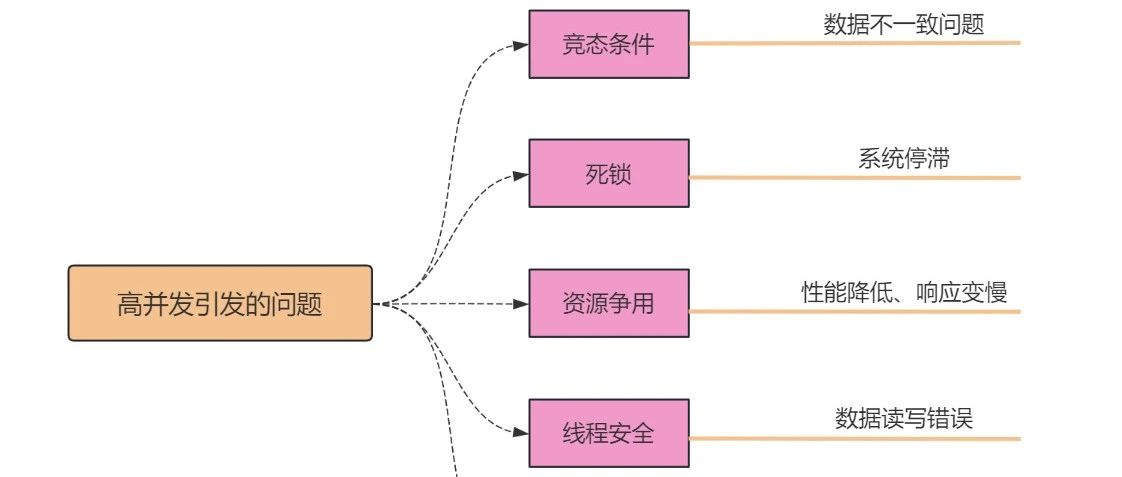
面试薪水被压?那是你还不懂多线程和高并发
大家好,我是小❤,一个漂泊江湖多年的 985 非科班程序员,曾混迹于国企、互联网大厂和创业公司的后台开发攻城狮。
一个健壮免费的Python短信轰炸程序,专门炸坏蛋蛋,请勿滥用
在 GitHub 上看到一个高一美术生写的一个健壮免费的python短信轰炸程序,专门炸坏蛋蛋,百万接口,多线程全自动添加有效接口,支持异步协程百万并发,自己对自己的号码用了一下,确实是短信轰炸,要不是及时 Ctrl C,怕是手机要崩溃。

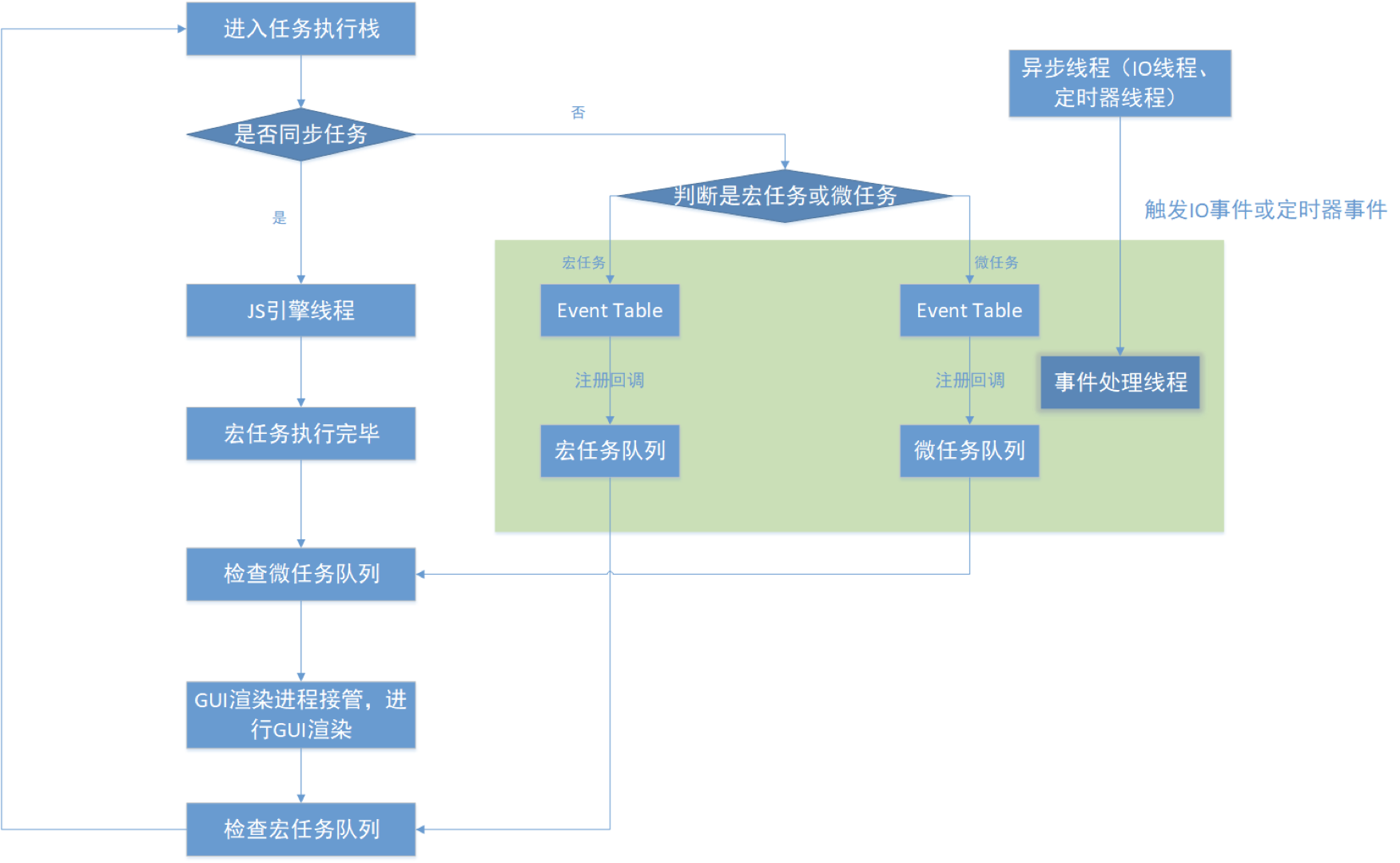
JavaScript执行机制
JavaScript为什么是单线程的呢?由于设计之初,JavaScript是用来做用户交互以及页面动态渲染,所以为了简洁和方便入手,决定了它只能是单线程,否则将会带来非常复杂的同步问题。
解析Perl爬虫代码:使用WWW::Mechanize::PhantomJS库爬取stackoverflow.com的详细步骤
在这篇文章中,我们将探讨如何使用Perl语言和WWW::Mechanize::PhantomJS库来爬取网站数据。我们的目标是爬取stackoverflow.com的内容,同时使用爬虫代理来和多线程技术以提高爬取效率,并将数据存储到本地。

IDM:广受欢迎的高速下载管理器
[IDM(Internet Download Manager)](Internet Download Manager is a powerful download accelerator)是一款功能强大的下载管理工具,它通过多线程技术和断点续传功能,有效提高了下载速度和稳定性,深受用户喜爱。IDM支持多种协议,如HTTP、HTTPS、FTP等,并能与主流浏览器无缝集成,简化下载过程。

ts视频下载 准备下载视频的你确定不进来看看吗
之前一直爬取的内容都是完整的文件,例如一整个mp3或则mp4,但是目前很多视频网站都开始采用ts流媒体视频的方式进行视频的展示,不知道你有没有这样的体验,兴致勃勃的打开一个电影网站,准备开始施展爬虫大法
查看xhr请求之后,本以为可以找到一个返回mp4的接口,没想到返回的是这一堆ts文件

万维书刊网所有期刊邮箱地址爬取
由于之前要写论文,然后还要投稿,但是有些投稿还需要钱,所以我就爬取了某网站下的免版面费的所有期刊的邮箱地址。

如何应对爬虫请求频繁
相信很多爬虫工作者在进行数据爬取过程中经常会遇到“您的请求太过频繁,请稍后再试”,这个时候心里莫名的慌和烦躁、明明爬虫代码也没有问题啊,怎么突然爬不动了呢?那么,很有可能,你的爬虫被识破了,这只是友好的提醒,如果不降低请求就会拉黑你的ip了。
我们都知道遇到这种情况使用代理就解决了,用代理IP确实不失为一个解决问题的好办法。IP被封了就换新IP继续爬,或者用很多IP同时多线程爬,都很给力的。但是有时候没有爬多久又被提示“您的请求太过频繁,请稍后再试”。再换IP还是被封,再换再封,封的越来越快,效率非常低下,这是为什么呢?
那是因为,你用的代理IP凑巧也是别人用来访问相同的网站的,而且用的还比较频繁。可能你们使用了共享ip池,或者使用的代理ip池很小。所以我们在找代理IP的时候,在保证IP有效率的同时IP池越大越好的,这样可以保证IP的新鲜度。例如亿牛云…列如还有的在使用代理的过程中也出现这样的情况。HTTP\HTTPS代理,系统会返回429 Too Many Requests;但不会对爬虫的运行产生影响,爬虫会根据返回结果自动重新发起请求,这是HTTP\HTTPS的标准应答模式。
所以,当您遇到“您的请求太过频繁,请稍后再试”时,不要慌,要镇定,检查下自己的爬虫策略,是否真的访问太过频繁,检查下自己的代理IP是否真的比较干净,调整自己的策略,选择更加纯净的IP,就能有效的避免这个错误了
通过几段代码,详解Python单线程、多线程、多进程
在使用爬虫爬取数据的时候,当需要爬取的数据量比较大,且急需很快获取到数据的时候,可以考虑将单线程的爬虫写成多线程的爬虫。下面来学习一些它的基础知识和代码编写方法。

如何让Python爬虫在遇到异常时继续运行
在数据收集和数据挖掘中,爬虫技术是一项关键技能。然而,爬虫在运行过程中不可避免地会遇到各种异常情况,如网络超时、目标网站变化、数据格式不一致等。如果不加以处理,这些异常可能会导致爬虫程序中断,影响数据采集效率和完整性。本文将概述如何使用Python编写一个健壮的爬虫,确保其在遇到异常时能够继续运行。我们将通过使用try/except语句处理异常,结合代理IP技术和多线程技术,以提高爬虫的采集效率。
这些新项目一定不要错过「GitHub 热点速览」
本周 GitHub 热点上榜的项目有不少的新面孔,比如搞电子商务的 eShop,还有处理表数据的 onetable。还有用来方便处理数据同步问题的 loro,以及网易新开源的 tts 项目 EmotiVoice。

python爬虫增加多线程获取数据
Python爬虫应用领域广泛,并且在数据爬取领域处于霸主位置,并且拥有很多性能好的框架,像Scrapy、Request、BeautifuSoap、urlib等框架可以实现爬行自如的功能,只要有能爬取的数据,Python爬虫均可实现。数据信息采集离不开Python爬虫,而python爬虫离不开代理ip,他们的结合可以做的事情很多,如广告营销、各种数据采集大数据分析,人工智能等,特别是在数据的抓取方面可以产生的作用巨大。
如何使用异常处理机制捕获和处理请求失败的情况
在爬虫开发中,我们经常会遇到请求失败的情况,比如网络超时、连接错误、服务器拒绝等。这些情况会导致我们无法获取目标网页的内容,从而影响爬虫的效果和效率。为了解决这个问题,我们需要使用异常处理机制来捕获和处理请求失败的情况,从而提高爬虫的稳定性和稳定性。

好物周刊#47:快捷启动器
All-in-One 的数据洞察中心,同时具备网站分析器 + 状态监控器 + 服务状态上报的功能。
重定向爬虫和多线程爬虫
在日常爬取工作中会遇到程序返回302的情况,这种是网站重新定向问题,就是爬取的网站进行了跳转,我们想要的数据又需要跳转连接才能取到,比如,我们访问 http/www.baidu.com 会跳转到 https/www.baidu.com,发送请求之后,就会返回301状态码,然后返回一个location,提示新的地址,浏览器就会拿着这个新的地址去访问。