由于之前要写论文,然后还要投稿,但是有些投稿还需要钱,所以我就爬取了某网站下的免版面费的所有期刊的邮箱地址。

然后就小写了一下代码,用以批量爬取,并保存到本地的表格,到时候可以直接批量发送邮件。
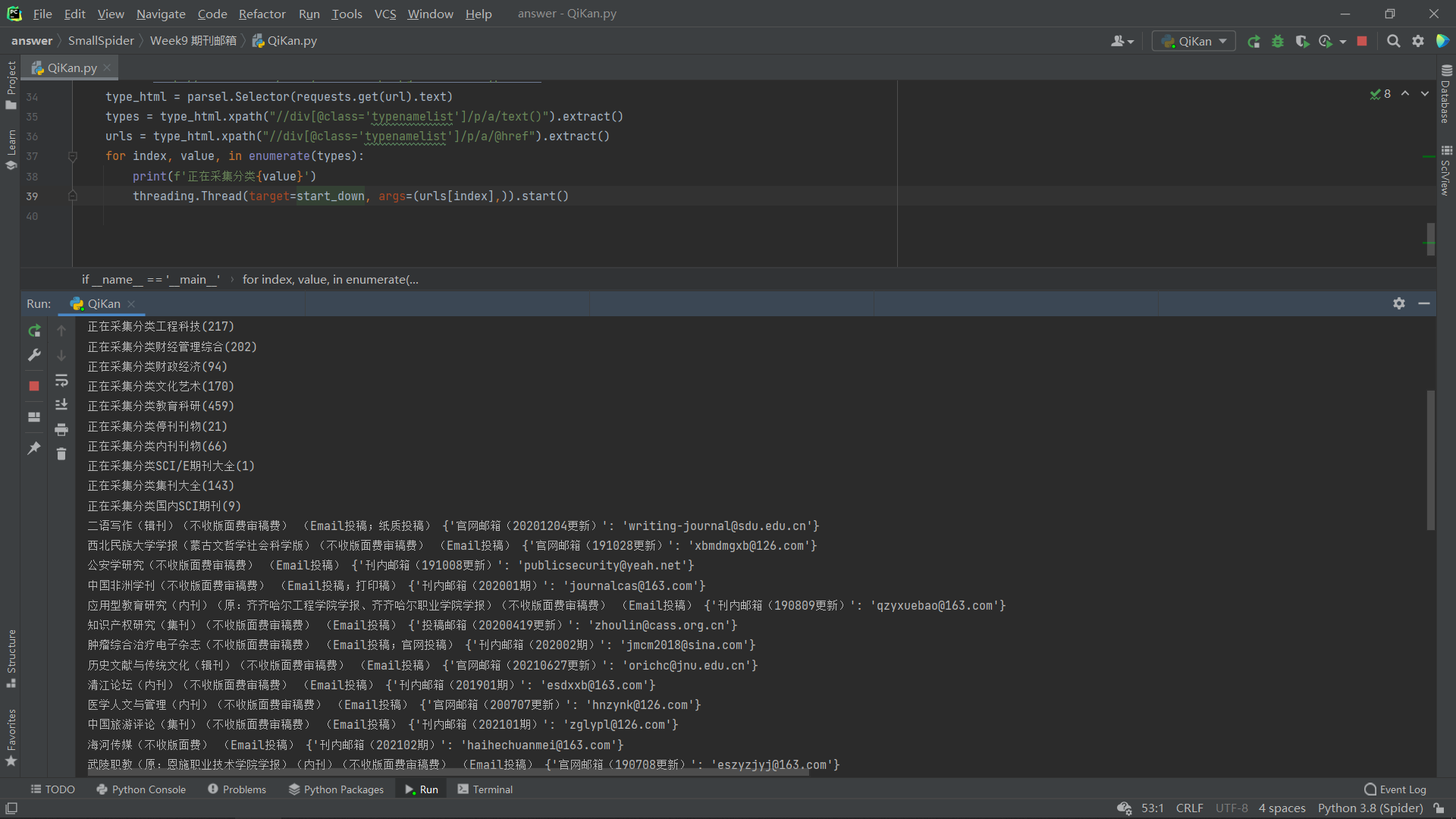
因为考虑到分类比较多,然后速度比较慢,所以直接上了多线程
# -*- coding: utf-8 -*- """ ------------------------------------------------- @ Author :Lan @ Blog :www.lanol.cn @ Date : 2021/7/30 @ Description:I'm in charge of my Code ------------------------------------------------- """ import random import timeimport requests
import parsel
import threadingdef start_down(target, value):
html = parsel.Selector(requests.get(f'http://.com/{target}').text)
tou_di_url = html.xpath("//li[@class='bu']/a/@href").extract()
with open(f'{value.replace("/", "-")}.csv', 'a+', encoding='gbk') as f:
for content_url in tou_di_url:
try:
content_html = parsel.Selector(requests.get(f'http://.com/{content_url}').text)
title = content_html.xpath(
"//div[@class='jjianjie']/div[@class='jjianjietitle']/h1[@class='jname']/text()").extract_first()
if 'Email投稿' in title:
contact = dict(zip((i.replace(' ', '').replace('\r', '').replace('\n', '') for i in
content_html.xpath("//div[@class='sclistclass']//p[2]/text()").extract()),
(i.replace(' ', '').replace('\r', '').replace('\n', '') for i in
content_html.xpath("//div[@class='sclistclass']//p[3]/text()").extract())))
print(title, contact)
f.write(f'{title},{contact}\n')
time.sleep(random.randint(1, 4))
f.flush()
except:
time.sleep(random.randint(1, 4))
if name == 'main':
url = 'http://*.com/NoLayoutFee.aspx?pg=1&hxid=8&typeid=27'
type_html = parsel.Selector(requests.get(url).text)
types = type_html.xpath("//div[@class='typenamelist']/p/a/text()").extract()
urls = type_html.xpath("//div[@class='typenamelist']/p/a/@href").extract()
for index, value, in enumerate(types):
print(f'正在采集分类{value}')
threading.Thread(target=start_down, args=(urls[index], value,)).start()
Week9 期刊邮箱.zip
来源:蓝奏云网盘