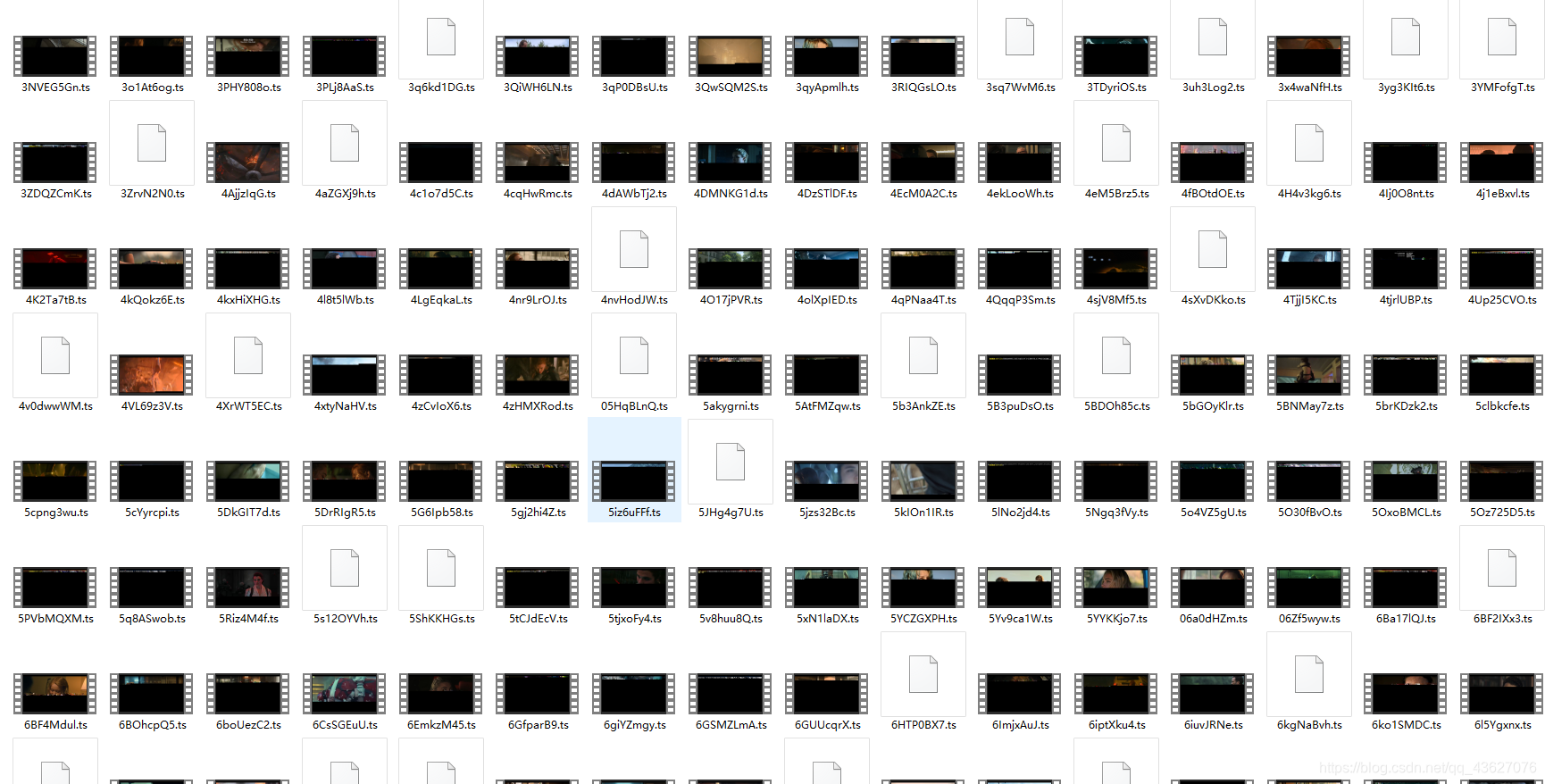
#记录创立的线程
task_list = []
# 获取ts的真实地址和顺序
tss, order = getTss(url)
# 这里将ts文件顺序存储在m3u8,至于为啥这么做,因为ts文件数量太多了
file = open("E://file//order.m3u8", 'w')
# 这里将下载ts文件的本地路径输入到order.m3u8之中
for i in order:
file.write(f"file 'E:\\file\\ts\\" + i + "'");
file.write("\n")
#线程池的创立
pool = ThreadPoolExecutor(max_workers=50)
for i in range(0, len(order)):
# 启动多个线程下载文件
task_list.append(pool.submit(FileDownload.downloadFile, 'E://file//ts//' + order[i], tss[i]))
# 判断所有下载线程是否全部结束
while (True):
if len(task_list) == 0:
break
for i in task_list:
if i.done():
task_list.remove(i)
# 进行多个ts文件的合并
VideoUtil.mixTss(name)
# 合并结束之后把ts文件都删了,不然太占空间了
for u in order:
turl = f"E:\\file\\ts\\" + u
os.remove(turl)</code></pre></div></div><h5 id="4a4vg" name="ts%E6%96%87%E4%BB%B6%E9%A1%BA%E5%BA%8F%E5%AD%98%E5%82%A8%E5%88%B0%E6%9C%AC%E5%9C%B0%E6%96%87%E4%BB%B6%E4%B8%AD">ts文件顺序存储到本地文件中</h5><p><strong>主要代码</strong></p><div class="rno-markdown-code"><div class="rno-markdown-code-toolbar"><div class="rno-markdown-code-toolbar-info"><div class="rno-markdown-code-toolbar-item is-type"><span class="is-m-hidden">代码语言:</span>javascript</div></div><div class="rno-markdown-code-toolbar-opt"><div class="rno-markdown-code-toolbar-copy"><i class="icon-copy"></i><span class="is-m-hidden">复制</span></div></div></div><div class="developer-code-block"><pre class="prism-token token line-numbers language-javascript"><code class="language-javascript" style="margin-left:0"># 这里将下载ts文件的本地路径输入到order.m3u8之中
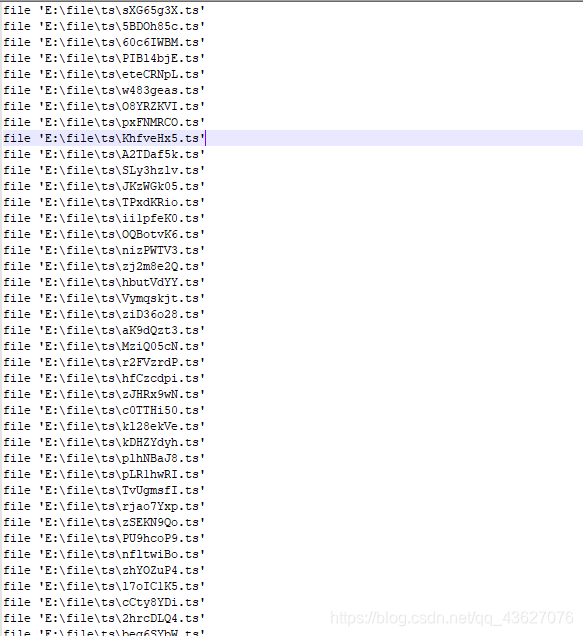
for i in order:
file.write(f"file 'E:\\file\\ts\\" + i + "'");
file.write("\n")</code></pre></div></div><p>最终文件中存储的内容
#线程池的创立
pool = ThreadPoolExecutor(max_workers=50)
for i in range(0, len(order)):
# 启动多个线程下载文件
task_list.append(pool.submit(FileDownload.downloadFile, 'E://file//ts//' + order[i], tss[i]))
# 判断所有下载线程是否全部结束
while (True):
if len(task_list) == 0:
break
for i in task_list:
if i.done():
task_list.remove(i)