前言
之前一段时间还做过这个需求,输出了两篇关于静态和动态网页数据获取和网络数据交互流程的详解博文。能够获取到数据之后,有数据资源下一步无非就是打通API进行数据交互就行。该项目的难点在于现在很多网站都设置了反爬机制,可能会存在层层障碍阻止数据获取,而且光靠会Python编程还不够,很多时候都需要对前端代码有所了解,才能清晰的获取到定位信息。总体来说数据采集项目算得上是一个考验全方位技术栈的综合项目,那么本篇文章将带你从操作实践学会Python数据采集,并完成采集文章到微信公众号平台。
一、网址通讯流程
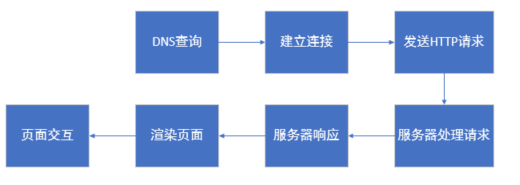
因为涉及到网址通讯流程,这里简要介绍一下网页信息传输流程更方便以后了解我们应该如何获取静态数据以及抓取信息。当我们在浏览器中输入一个网址并访问时,发生的网络通讯流程可以分为以下几个主要步骤:
二、URL/POST/GET
大家不妨在浏览器开发者模式,点击网络一栏可以查看每次网络数据交互情况,基本上都会有涉及到GET和POST,所有这里详细讲述GET和POST的具体作用和形式。

1.URL
URL想必大家都知道,诸如:https://www.csdn.net/就是一个URL,但是这里要较为详细的讲述一下URL的参数,也就是除去标准的URL后续?后面所带的参数含义。
URL参数是指在URL(统一资源定位符)中包含的一组键值对,用于向服务器传递额外的信息。它们通常出现在问号(?)之后,并使用等号(=)分隔键和值,不同键值对之间使用和号(&)分隔。这种传递参数的方式使得客户端(通常是浏览器)能够向服务器发送特定的请求,以获取或提交特定的数据。 比如https://www.csdn.net/?spm=1010.2135.3001.4476,?后面的参数就是。其中,spm是一个参数,它的值是1010.2135.3001.4476;这样,服务器就能够识别客户端的请求,并根据这些参数来执行相应的操作,比如执行搜索操作并过滤到编程相关的结果。 这里需要URL的四个特点:
- 键值对: URL参数是以键值对的形式存在的,一个键对应一个值。在上面的例子中,
q是键,python是值。 - 多个参数: URL可以包含多个参数,它们之间使用
&符号分隔。在上面的例子中,q=python和category=programming是两个不同的参数。 - 编码: 由于URL中不能包含一些特殊字符,参数的键和值通常需要进行URL编码。例如,空格可能被编码为
%20。 - GET请求: URL参数通常与HTTP的GET请求一起使用。在GET请求中,参数会被附加到URL上,而在POST请求中,参数通常包含在请求体中。
URL参数在Web开发中被广泛使用,用于传递用户输入、筛选数据、进行搜索等各种场景。在服务端,开发人员可以通过解析URL参数来理解客户端请求的意图,并采取相应的操作。
2.GET
在浏览器与服务器之间的网络交互中,GET请求是最常用的请求类型之一,主要用于从服务器检索数据。GET主要有四种作用:
- 数据检索:GET请求的主要目的是请求服务器发送资源(如网页、图片、文件等)。它是一个“只读”请求,意味着它应该不对服务器上的数据产生任何影响。
- 简单和无副作用:GET请求被设计为安全和幂等的,这意味着重复执行相同的GET请求应该得到相同的结果,且不会对服务器的数据状态产生改变。
- 可被缓存:GET请求的结果往往可以被浏览器或服务器缓存以加速后续访问。
- 书签和分享:GET请求可以通过URL完整表达,这使得请求的资源可以通过链接共享或保存为书签。
形式
URL结构如 https://www.example.com/page,指定请求的服务器和资源路径。查询字符串:以?开始,后接一个或多个参数。每个参数由键值对组成,格式为key=value,多个参数之间用&分隔,如 ?query=search&sort=asc。比如:
https://www.example.com/search?query=keyword&sort=ascending&page=1上述GET请求中客户端请求服务器上的/search资源,并传递了三个参数:query(搜索关键字)、sort(排序方式)、page(页码)。
GET请求还包括HTTP请求头部,其中可能包含浏览器类型、接受的响应格式、语言偏好等信息。例如:User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36。
一般用到GET的场景有:
- 检索数据:当需要从服务器获取数据时使用,如加载网页、图片、视频或任何其他类型的文件。
- 搜索查询:在搜索引擎中输入查询,提交的就是一个GET请求。
- 简单的表单提交:用于提交非敏感数据的表单,虽然不推荐(出于安全和数据长度限制的考虑)。
3.POST
它与GET请求相比,通常用于发送数据到服务器以便更新或创建资源。POST请求主要用于向服务器提交数据,通常不会被缓存。这些数据通常用于更新现有资源或创建新资源。由于POST请求将数据包含在请求体中,而不是URL中,因此它比GET请求更适合发送敏感或大量的数据。相同的POST请求如果被重复发送,可能会每次都产生不同的结果,例如在数据库中创建多个资源。
形式
请求体:
- 数据是在HTTP请求的主体中发送的,而不是在URL中。
- 数据可以采用多种格式,例如表单数据、JSON、XML等。
HTTP头部:
Content-Type头部指定了发送数据的格式,例如application/x-www-form-urlencoded(表单数据)、application/json(JSON格式)等。Content-Length头部显示数据的大小。
我们举个POST例子来看:
POST /submit-form HTTP/1.1 Host: www.example.com Content-Type: application/x-www-form-urlencoded Content-Length: 27
name=John&age=30&city=New York
客户端向/submit-form路径发送POST请求,请求体中包含了表单数据。
一般来说POST发送的场景有:
- 表单提交:在用户提交表单(尤其是包含敏感信息的表单,如登录凭证)时使用。
- 文件上传:在上传文件到服务器时使用。
- API交互:在与API进行交互,尤其是在创建或更新数据时使用。
POST请求因其安全性和非幂等性,被广泛用于敏感数据的传输和处理。
三.获取静态网页数据
Requests 是一个简单易用的 Python HTTP 库,用于发送网络请求。它是基于 urllib3 构建的,并提供了大量直观的功能来发送 HTTP/1.1 请求。它是 Python 社区中最受欢迎的 HTTP 客户端库之一。我们可以使用Requests去模拟每一次与服务端网络数据交互的过程,通过requests支持的常用函数就可以看出:
- requests.get(url, params=None, **kwargs):发送一个 GET 请求到指定的 URL。
- requests.post(url, data=None, json=None, **kwargs):发送一个 POST 请求到指定的 URL。
- requests.put(url, data=None, **kwargs):发送一个 PUT 请求到指定的 URL。
- requests.delete(url, **kwargs):发送一个 DELETE 请求到指定的 URL。
- requests.head(url, **kwargs):发送一个 HEAD 请求到指定的 URL。
- requests.options(url, **kwargs):发送一个 OPTIONS 请求到指定的 URL。
大家可以通过跑一下我给出的demo:
import requests
r =requests.get('https://cloud.tencent.com/developer/user/9822651')
print("文本编码:",r.encoding)
print('响应状态码:',r.status_code)
print('字符串的方式的响应体:',r.text)其中输出的text文本文件就是我们要获取的网页信息,但是有些网页需要对Requests的参数进行设置才能获取需要的数据,这里暂时不做展开,以后详细讲述request的时候再讲。笔者主要带大家要了解的是动态网页数据获取。
四、动态网页数据获取
动态网页是一种在用户浏览时实时生成或变化的网页。与静态网页不同,后者通常是预先编写好的HTML文件,直接由服务器传送给浏览器,内容在服务端生成且固定不变,获取静态数据的文章课查阅博主上一篇文章:详解静态网页数据获取以及浏览器数据和网络数据交互流程-Python。相比之下,动态网页可以根据用户的互动、请求或其他条件在浏览器端或服务器端生成新的内容。而且现在的网页一般都是采用前后端分离的架构,前端负责展示和用户交互,后端负责数据处理。这种架构使得前端可以更加灵活地实现动态内容的加载和展示。所以说以后想要获取到数据,动态网页数据获取会成为我们主流获取网页数据的技术。所以在动态网页数据获取这方面我们需要下足功夫了解动态网页数据交互形式、数据存储访问模式等方方面面的知识,我们才好更加灵活的获取到数据。
一、动态网页和静态网页的区别
当我们谈论动态网页和静态网页时,我们主要是在讨论网页的内容是如何生成和呈现给用户的。想象一下,网页就像是餐厅里的菜单。
静态网页
就像是一张印刷好的菜单,上面的内容是固定的。每次你去餐厅,看到的菜单都是一样的,不会根据你的偏好或者是时间的变化而改变。
在网页方面,静态网页是一次创建好,之后内容就不再改变的。无论何时访问这个网页,你都会看到同样的内容。它们是直接从服务器上以文件形式提供的,不涉及任何内容的即时生成或处理。
动态网页
就像是一张电子菜单,可以根据你的口味偏好、季节、甚至是目前的库存来动态调整菜单内容。比如,如果是夏天,菜单可能会显示更多清凉饮品或沙拉;如果你是素食者,它会向你展示更多素食选项。
动态网页在你访问时才生成内容。这意味着网页可以根据用户的请求、时间、用户互动等因素来更改显示的内容。动态网页通常会使用服务器端的脚本语言(如PHP、ASP.NET、Java等)来生成页面内容,并且经常与数据库交互,以提供实时更新的内容。
这就是动态网页和静态网页之间的主要区别。动态网页更加灵活,能够提供个性化和交互式的体验,而静态网页则相对简单,内容固定。
二、网页何谓动态
动态网页技术在网页的HTML源码中通常不直接可见,因为它们在服务器端进行处理,然后生成最终的HTML内容发送给用户的浏览器。动态网页技术在网页HTML源码中通常不局限于特定的板块,而是遍布于整个页面的各个部分。比如用户登录状态的动态显示(比如显示用户的名字或头像)、基于用户角色或权限动态生成菜单项、分页或无限滚动,动态加载更多内容。最常见的当属通过按钮、滑块、标签页等,这些元素响应用户操作,如点击或滑动,来触发动态变化。
我们以一个网页实例开发会遇到的问题来看,比如评论区的开发,许多网站有文章或产品评论区,这些评论是实时从数据库加载的,并根据用户的浏览或互动实时更新。以Django的实例展示:
# Django 示例
def article(request, article_id):
article = Article.objects.get(pk=article_id)
comments = Comment.objects.filter(article=article).order_by('-date')
return render(request, 'article.html', {'article': article, 'comments': comments})一些网站使用动态表单,根据用户的输入或选择来调整表单的选项。这些通常是通过JavaScript实现的,但可能会与服务器端代码交互以获取必要的数据。
document.getElementById('country-select').addEventListener('change', function() {
var country = this.value;
fetch('/api/getStates?country=' + country)
.then(response => response.json())
.then(data => {
// 更新状态选择框
});
});动态网页技术的一个关键特点是它们通常依赖于JavaScript来操控DOM(文档对象模型),使得页面可以在不重新加载的情况下更新其内容。这种技术可以应用于几乎任何页面元素,并使得网页能够提供更加丰富和交互式的用户体验。
三、获取动态网页数据
Selenium
Selenium是一个自动化测试工具,它可以模拟用户在浏览器中执行的操作,如点击、滚动等。Selenium非常适合于爬取JavaScript动态加载的内容,因为它实际上是运行在一个真正的浏览器中,可以执行JavaScript。我之前的项目一半以上都是用selenium来做,现在各类反爬技术都在逐渐普及运用,selenium虽然较慢但不失为保底的技术策略。举一个简易的selenium的例子:
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC import time配置Selenium驱动器(以Chrome为例)
driver = webdriver.Chrome(executable_path='path/to/chromedriver')
打开目标网页
driver.get('https://example-ecommerce.com/products')
等待页面动态加载完成
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, 'product'))
)模拟向下滚动以加载更多产品(如果需要)
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(3) # 等待额外内容加载获取产品信息
products = driver.find_elements(By.CLASS_NAME, 'product')
for product in products:
name = product.find_element(By.CLASS_NAME, 'product-name').text
price = product.find_element(By.CLASS_NAME, 'product-price').text
print(f'Product Name: {name}, Price: {price}')关闭浏览器
driver.quit()
笔者推荐新手使用selenium框架会更好,篇幅有限暂不展开,感兴趣的朋友推荐去阅读笔者的博文有详细介绍。
五、采集文章到微信公众号
现在我们来进行实战操作,因设计到个人隐私这样不指名具体数据来源:
1.获取目标URL数据:
比如我想获取目标URL的数据,首先我们需要新建一个,包含我们要拿到的title、data和目标文章的url:
class BasicWebScraper:
def init(self):
# 配置WebDriver的选项
self.options = Options()
# 示例:无头模式运行(不打开浏览器窗口)
self.options.add_argument("--headless")
data = {
"title": [],
"date": [],
"urls": []
}
self.df=pd.DataFrame(data)
# 初始化WebDriver
self.driver = webdriver.Firefox(options=self.options)之后编写获取方法:
def get_url_info_JXRST(self,url):
self.driver.get(url)
# 等待页面加载
time.sleep(3) # 根据网速和网站响应时间调整等待时间
# 提取文章标题和发布日期
articles = self.driver.find_elements(By.XPATH, "//li/span/a")
dates = self.driver.find_elements(By.XPATH, "//li/em[@class='date']")
for article, date in zip(articles, dates):
try:
title = article.get_attribute('title')
urls = article.get_attribute('href')
publish_date = date.text
#print(f"Title: {title}, Date: {publish_date},URL: {url}")
new_data = {
"title": title,
"date": publish_date,
"urls": urls
}
if not self.df[self.df['urls'] == urls].empty:
continue # 如果 URL 已存在,则跳过此次循环
self.df=self.df.append(new_data, ignore_index=True)
except NoSuchElementException:
# 没有找到 'a' 元素,终止循环
break2.数据保存
将采集到的数据保存入库,或者保存到本地excel中记录:
def save_df(self):
# 获取当前日期并格式化为字符串(例如:2023-01-03)
current_date = datetime.now().strftime('%Y-%m-%d')
filename = f'\recruitment_{current_date}.xlsx'
self.to_excel(filename, index=False)
print("已经保存完毕:" + filename)
return filename3.消息发送
当用户和公众号产生特定动作的交互时(具体动作列表请见下方说明),微信将会把消息数据推送给开发者,开发者可以在一段时间内(目前为48小时,2023年6月12日后启用新规则,查看公告)调用客服接口,通过POST一个JSON数据包来发送消息给普通用户,这里不作展示详细可看微信公众号官方文档,我们需要的是提供JSON文件:
def convert_xlsx_to_json(excel_path):
current_date = datetime.now().strftime("%Y-%m-%d") # 获取当前日期
excel_file=excel_path+'recruitment_{}.xlsx'.format(current_date)
df = pd.read_excel(excel_file)
# 将DataFrame转换为JSON格式
json_data = df.to_json(orient='records', force_ascii=False)
# 将JSON数据保存到文件
json_file_path = 'D:/claw/claw_json/recruitment_{}.json'.format(current_date)
with open(json_file_path, 'w', encoding='utf-8') as json_file:
json_file.write(json_data)
print('转化完毕')即可完成转化,再POST提交表单数据即可。
我正在参与2024腾讯技术创作特训营第五期有奖征文,快来和我瓜分大奖!