容量规划的本质就是在「没有足够硬件资源」和「花钱买了太多硬件资源」之间的一种权衡;在同时,容量规划也是一门玄学,因为没人能清楚未来会发生什么,所以通常来说是数据和直觉相结合的过程。
容量规划背景
在没有进行容量规划之前,尝试问自己如下三个问题。
问题1 谁需要进行容量规划?
致力于成长为国内一线互联网公司,并经常需要为流量激增而大规模扩容的公司。
问题2 什么时间进行容量规划
容量规划就是资源管理,当资源有限且具有一定成本时就需要进行容量规划。
问题3 为什么要进行容量规划?
现在互联网,不仅是软件之间的互动,更多的是人和软件之间的互动。主动权不掌握在软件运营者的手中,某个话题的出现都会导致用户激增,进而导致网站崩溃,为了防止网站崩溃,就要精准预测流量,为不可预知的流量做准备。
容量规划目标
在没有目标之前,不要进行容量规划,也没有办法进行容量规划。
一般目标如下:
- 服务SLA,通常包括可用性和性能指标两个维度,要给出具体数字,99.9%可用还是99.99%可用,比如有些系统提供商承诺99%可用性,给人一种可用性很高的错觉,其实算下一年就要有5k多分钟处于不可用状态。

另外就是时延,对于延迟敏感高的系统,不要用平均数,要用中位数,比如:P99.99 保证 50ms 以内延迟。因为多数服务都存在长尾问题。
- 软件架构,服务是否低耦合,是否可以横向扩展。多数公司做架构都停留于编程语言和通信协议层面,但这仅仅是最表面的一层。要想提升稳定性,更多的是隔离、限流、熔断、超时、负载均衡、链路追踪、监控,每一个拿出来都可以当一个专门的课题去研究。
- 基础设施架构,是否支持自动扩缩容,具体包括水平扩容,垂直缩放。
- 灾难恢复,多数据中心建设,这个之前有过介绍
容量规划方法和过程
- 收集最近半年或者一个季度 QPS 增长趋势,根据增长趋势预估接下来的增长倍数;
- 根据预估流量算出所需硬件数量;
- 计算处理能力,并添加限流;
- 不断收集指标、持续优化系统处理能力,并校正容量规划指标。
下面我会针对这四个步骤进行详细解释
1、指标收集
每个(重要的)系统都应该量化它的处理能力并且可视化当前状态(QPS、延迟、错误率),如果不能,那就让它变得可量化、可视化。
服务运行指标不可或缺,不仅仅容量规划,也是日常监控告警指标的一部分。
指标收集有诸多陷阱,就以常用的 Prometheus 为例,当计算QPS时,应该用irate把瞬时峰值计算出来,而不应该使用rate;即便使用irate,可能还会存在误差,一般 Prometheus 的采集指标是 15s,只对规定采样周期内的最后两个样本进行计算,而忽略前面所有样本。

Grafana只是一个指标观测工具,不能完全靠它去做容量评估,我们知道当你查询最近半小时的 QPS 时,分钟展示;但是你进行容量评估可能会查看连续多天的数据指标,这样的话单位就变成了天,如果里面有一个短暂的峰值,grafana并不会展示,那么峰值可能被忽略掉。
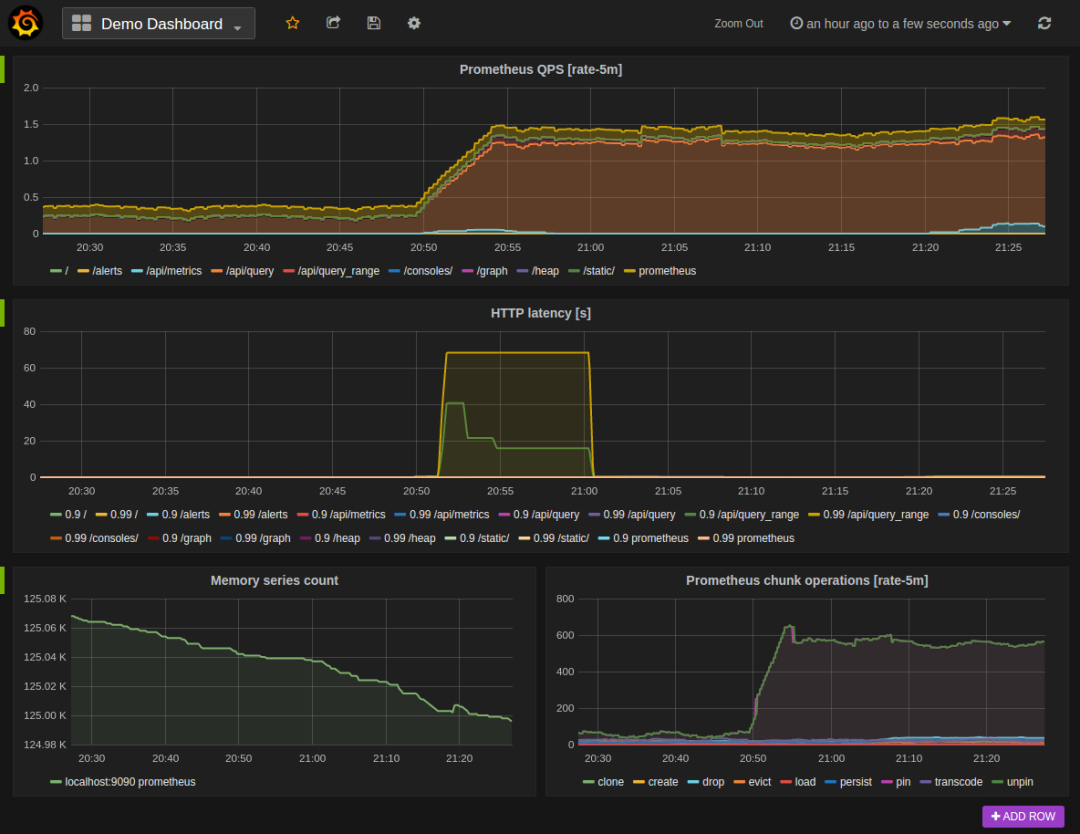
基于肉眼查看界面会存在误判,所以不要依赖界面化操作,而是实现自动化指标查询。Prometheus 本身就是个时序数据库,可以通过HTTP调用的方式以采集周期为单位把某段时间内最大数据指标收集出来。例如使用以下表达式查询请求表达式在30秒范围内以15秒为间隔计算PromQL表达式的结果。
$ curl 'http://localhost:9090/api/v1/query_range?query=http_requests_total{environment=~"staging|testing|development",method!="GET"}
&start=2015-07-01T20:10:30.781Z&end=2015-07-01T20:11:00.781Z&step=15s'
{
"status" : "success",
"data" : {
"resultType" : "matrix",
"result" : [
{
"metric" : {
"__name__" : "up",
"job" : "prometheus",
"instance" : "localhost:9090"
},
"values" : [
[ 1435781430.781, "1" ],
[ 1435781445.781, "1" ],
[ 1435781460.781, "1" ]
]
},
{
"metric" : {
"__name__" : "up",
"job" : "node",
"instance" : "localhost:9091"
},
"values" : [
[ 1435781430.781, "0" ],
[ 1435781445.781, "0" ],
[ 1435781460.781, "1" ]
]
}
]
}
}
建议每2个小时存储一个最大值,然后把以天、月为单位画出走势图,根据走势图预测下个周期预测值。
2、计算所需资源
既然资源评估,那就需要计算自己需要的资源,CPU、内存、磁盘;其中内存和磁盘使用都会存在一个固定趋势,根据现有指标相对更容易的计算出来。
这里通常有两个原则:
- 一是可以回收资源,比如CPU和内存,随着进程的消失而回收,这类资源通常需要预测一段时间的峰值使用
- 持续增长的资源,比如硬盘,就需要查看存储的增长曲线,根据增长曲线预测未来多久需要进行硬件的采购和安装上架
量化你的QPS和延迟的关系,量化你的QPS和硬件(CPU、内存、磁盘、IO)的关系, 量化你的每个请求需要消耗的资源。
下面我以计算 CPU 为例,说明下如何进行计算资源的评估。
首先我们需要计算出每个请求消耗的 CPU 资源,计算公式如下:
每个请求 CPU% = 总的 CPU% 消耗/请求总数
承载 QPS 最大值 = 100% * CPU 数量/ 每个请求消耗CPU%
首先根据监控查看 QPS 对应的 CPU 消耗,建议使用线上数据,如果第一次上线,则使用基准压测数据。
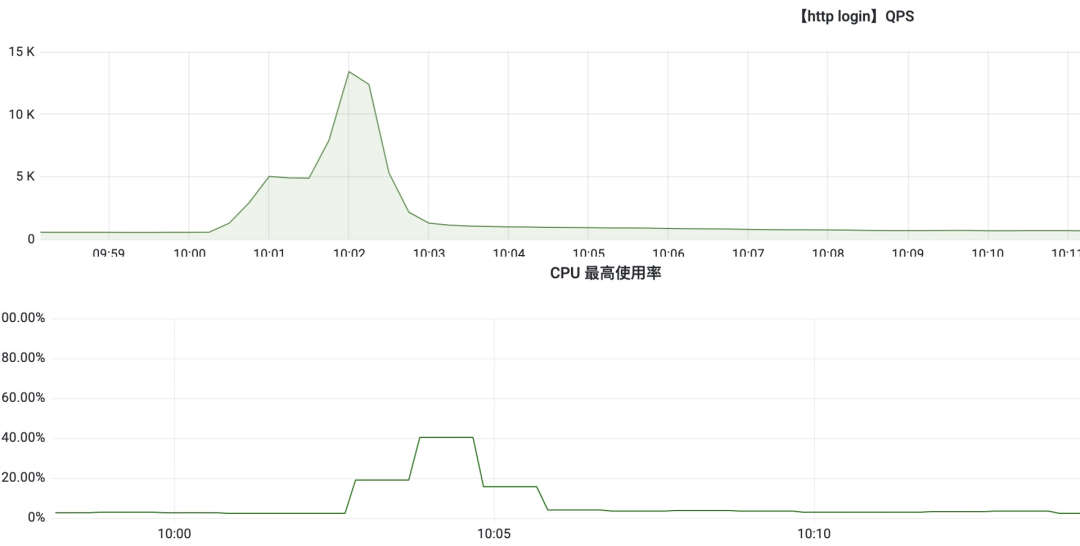
假设上述qps占用32core
- 每个请求占用的CPU资源 =
32 * 40%/13400 = 0.09% - 32core满载的情况下承载 QPS 最大值 =
3200/0.09 = 35,555 - 当然按照业界标准一般CPU占用率安全线 85%,那么
35,555 * 0.85 = 30221 qps - 如果要满足 10w qps 需求,那么就需要
106core = 100000/30221 * 32
当然这是一种资源评估方法,并不能完全解决服务中存在的问题,比如说 JVM 在某个不确定的时间发生了 GC、存在 SQL 慢查询....这种偶尔故障导致的CPU消耗超过阈值,只能具体问题具体分析,比如:JVM 调优,尽可能少发生 FGC。添加监控告警指标,出现不符合正常逻辑指标升高,告警、人工处理等。
3、采购硬件
硬件资源是软件运行过程中不可忽略的成本,只有根据上述数据评估清楚,到底需要购买多少硬件,才应该开始硬件的采购和安装过程。
事项 | 内容 | 完成时间 |
|---|---|---|
确定需求 | ||
采购理由 | ||
征求供应商报价 | ||
订购设备 | ||
物理安装设备 | ||
操作系统和应用程序配置安装 | ||
测试 | ||
上线服务 |
这里的原则是尽可能采购同类型的机器,减少机器之间的差异性,简化故障维修;当机器不同零部件出现问题时可以同型号装配,提高硬件资源利用率;最后尽量不做做定制化设置,有利于后期的自动化。
容量规划问题讨论
- 性能优化和容量规划区别与联系
在我工作过程中,经常有人把性能优化和容量规划混为一谈,认为他们两个可以直接划等号,其实并没有什么关系,性能优化只是其中一个过程,通过性能优化可以提高服务处理能力,降低资源消耗,但是容量规划还是需要按部就班的做。
- 产品规划前期没有容量规划,导致后期没有资源
在很多开发团队中,产品和开发甚至运维人员都是相对比较独立的团队,这就导致产品人员不关心开发进度、开发不关心运维如何部署,这个没什么好的办法,只能改变企业文化,加强产品开发运维的一体化,这就现在工作中倡导的DevOps。
- 如何最大自己的资源
使用操作系统虚拟化技术,比如现在的Kubernetes,能够轻松完成资源的调度和分配,从而实现峰谷互补。
总结
容量规划这种事不去做,一直都是个空白,只要迈开第一步,随着时间的推移,会逐渐认识到自己服务的处理能力,容量预测也会变得更加准确,服务稳定性也会在一定程度上得到保障。