高并发简介
高并发应用场景涉及大量用户同时访问或操作系统,这对系统的性能、稳定性和扩展性提出了高要求。以下是一些常见的高并发应用场景及其复杂性简介:
1. 电商平台
场景:在大促销活动期间,如双十一、黑色星期五等,电商平台会迎来大量用户同时下单、支付和浏览商品。复杂性:
- 订单系统:需要处理大量的订单生成和支付请求,保证订单的唯一性和准确性。
- 库存管理:需要实时更新库存,避免超卖或库存不足的情况。
- 用户会话管理:大量用户同时登录和操作,需要高效的会话管理和负载均衡。
2. 社交网络
场景:社交网络平台上,用户会频繁发布、评论、点赞和分享内容。复杂性:
- 实时消息推送:需要实时推送消息通知给大量用户,保证消息的及时性和准确性。
- 动态内容加载:频繁更新的动态内容,需要高效的缓存和数据库读取。
- 用户互动:高并发的用户互动请求,需要高效的并发控制和数据一致性保障。
3. 在线直播
场景:在线直播平台,特别是在大型直播活动期间,会有大量观众同时观看、评论和打赏。复杂性:
- 视频流处理:需要高效的编码、转码和分发视频流,保证视频播放的流畅性。
- 实时互动:观众的评论和打赏需要实时显示,保证互动的及时性。
- 负载均衡:高并发的观看请求,需要高效的负载均衡和 CDN 分发。
4. 在线游戏
场景:大型多人在线游戏,需要支持成千上万玩家同时在线互动。复杂性:
- 游戏状态同步:需要实时同步玩家的游戏状态,保证游戏的公平性和一致性。
- 实时通信:玩家之间的实时通信需要高效的网络传输和延迟控制。
- 服务器分区:大规模玩家需要分布在多个服务器上,避免单点过载。
5. 金融交易系统
场景:股票交易、外汇交易等金融系统,在交易高峰期会有大量交易请求。复杂性:
- 交易撮合:需要高效的撮合算法,保证交易的实时性和准确性。
- 数据一致性:交易数据需要高度一致,避免数据错误和异常。
- 安全性:金融交易对系统的安全性要求极高,需要防范各种攻击和风险。
6. 搜索引擎
场景:搜索引擎需要处理大量的搜索请求,并返回相关的搜索结果。复杂性:
- 查询优化:高效的查询优化算法,保证搜索请求的快速响应。
- 索引更新:频繁更新的索引数据需要高效的处理和存储。
- 分布式存储:大量数据需要分布式存储和管理,保证数据的高可用性和一致性。
7. 物联网(IoT)平台
场景:大量物联网设备同时上传数据或接受控制命令。复杂性:
- 数据采集:高频率的数据采集和上传需要高效的处理和存储。
- 设备管理:大量设备的管理和控制需要高效的调度和协调。
- 实时处理:实时的数据处理和分析,保证系统的及时响应。
总结
高并发应用场景具有高度复杂性,需要综合运用多种技术和策略来保证系统的性能、可靠性和可扩展性。这包括分布式架构设计、负载均衡、缓存优化、数据库优化、异步处理、网络优化等。在实际应用中,还需要结合具体场景和业务需求,进行针对性的优化和调整。
高并发优化思路
高并发系统的优化需要从多个方面入手,综合考虑系统架构、数据库、缓存、网络等因素。以下是一些常见的高并发优化思路:
1. 系统架构优化
- 分布式架构:将单体应用拆分为多个微服务,每个微服务独立部署和扩展,减少单个服务的负载。
- 水平扩展:增加服务器节点,通过负载均衡将请求分发到多个服务器,提升系统的处理能力。
- 异步处理:采用异步编程模型和消息队列,减少请求的阻塞时间,提高系统的响应速度。
2. 负载均衡
- 硬件负载均衡:使用专业的硬件负载均衡设备,如 F5。
- 软件负载均衡:使用软件解决方案,如 LVS、Nginx、HAProxy 等,将流量分发到后端服务器。
3. 缓存
- 页面缓存:将静态页面缓存到 CDN 或代理服务器中,减少服务器的负载。
- 数据缓存:使用内存缓存系统,如 Redis、Memcached,将频繁访问的数据缓存到内存中,减少数据库的压力。
- 数据库缓存:在数据库查询中使用缓存,减少重复查询的开销。
4. 数据库优化
- 索引优化:为常用查询添加索引,提升查询性能。
- 分库分表:将大表拆分为多个小表,或将数据库按业务分为多个子库,减小单个数据库的负载。
- 读写分离:主从复制,主库处理写操作,从库处理读操作,提升数据库的读写性能。
- 事务优化:尽量减少事务的范围和时间,避免长时间占用数据库资源。
5. 网络优化
- CDN 加速:使用内容分发网络(CDN),将静态资源分发到靠近用户的节点,减少网络延迟。
- 压缩传输:使用 gzip 或其他压缩算法压缩数据,减少传输的数据量。
6. 应用层优化
- 代码优化:优化代码逻辑,减少不必要的计算和 I/O 操作。
- 连接池:使用数据库连接池、线程池等,重用连接和线程,减少连接建立的开销。
- 资源复用:尽量复用已有资源,避免频繁创建和销毁对象。
7. 并发控制
- 限流:对系统的请求进行限流,避免瞬时大流量冲击系统。
- 熔断:在检测到系统负载过高时,自动熔断部分服务,防止系统崩溃。
- 降级:在系统负载过高或部分服务不可用时,自动降级非核心功能,保证核心功能的正常运行。
8. 性能监控与调优
- 监控:使用监控工具(如 Prometheus、Grafana)实时监控系统性能,及时发现性能瓶颈。
- 日志分析:通过日志分析发现性能问题,优化代码和系统配置。
- 性能测试:定期进行性能测试,模拟高并发场景,提前发现和解决性能问题。
9. 前端优化
- 资源合并:合并 CSS 和 JavaScript 文件,减少请求次数。
- 懒加载:对图片和其他资源使用懒加载,减少初始加载时间。
- 减少重绘和重排:优化 DOM 操作,减少浏览器的重绘和重排次数。
10. 安全性优化
- 防止 DDoS 攻击:使用防火墙和其他安全措施,防止分布式拒绝服务攻击。
- 身份验证和授权:确保只有合法用户可以访问系统,防止恶意请求对系统造成负载。
通过以上优化思路,可以有效提升高并发系统的性能和可靠性,确保系统在高负载情况下依然能够稳定运行。
LVS与高并发
LVS(Linux Virtual Server)是一个用于构建高性能、高可用性服务器集群的负载均衡解决方案。LVS 在高并发环境中扮演着重要角色,通过分发流量到多个后端服务器来处理大量的并发请求,从而提高系统的整体性能和可靠性。以下是 LVS 与高并发的关系和工作原理:
1. 什么是 LVS
LVS 是 Linux 内核中的一组 IP 负载均衡技术,提供基于 IP 层的负载均衡。它主要包括 IP 负载均衡(IPVS)和 DR(Direct Routing)模式。
2. LVS 的工作模式
LVS 提供多种工作模式,适用于不同的场景和需求。常见的模式有:
- NAT(Network Address Translation)模式:LVS 将请求转发到后端服务器,并将响应返回给客户端。适用于小规模集群。
- DR(Direct Routing)模式:请求通过 LVS 分发到后端服务器,但响应直接从后端服务器返回客户端。适用于大规模集群,因为它减少了 LVS 服务器的网络带宽占用。
- TUN(IP Tunneling)模式:LVS 将请求通过隧道技术转发到后端服务器,后端服务器直接返回响应给客户端。适用于跨网络的负载均衡。
3. LVS 在高并发中的作用
在高并发环境中,LVS 通过以下方式提高系统性能和可用性:
- 负载均衡:LVS 将大量并发请求分发到多个后端服务器,从而避免单点过载,提高系统的整体吞吐量。
- 高可用性:通过集群管理工具(如 Keepalived),LVS 可以实现负载均衡器的高可用性。当一个 LVS 节点发生故障时,另一个节点可以自动接管。
- 伸缩性:LVS 易于扩展,可以通过增加后端服务器来应对更高的并发请求量。
- 低延迟:DR 模式下,响应直接从后端服务器返回给客户端,减少了请求的往返时间,降低了系统的延迟。
4. LVS 的优势
- 性能:LVS 基于内核实现,具有很高的性能和低延迟,适合处理大规模的并发请求。
- 灵活性:支持多种负载均衡算法(如轮询、最小连接数、加权轮询等),可以根据具体需求选择合适的算法。
- 稳定性:LVS 是一个成熟的解决方案,经过广泛使用和验证,具有高稳定性和可靠性。
5. 实际应用
LVS 通常与其他技术结合使用,以构建高并发、高可用性的系统。例如:
- Keepalived:用于管理 LVS 的高可用性,实现主备切换。
- HAProxy 或 Nginx:LVS 前端可以结合 HAProxy 或 Nginx 进行应用层的负载均衡,提供更灵活的路由和健康检查功能。
总结
LVS 在高并发系统中起到至关重要的作用,通过高效的负载均衡和可扩展性设计,帮助系统在高负载情况下依然保持稳定和高性能运行。
LVS工作流程
可以通过Mermaid图表来体现数据包在不同 LVS 工作模式下的 IP 和 MAC 地址变化。以下是各模式下数据包源和目的 IP、MAC 地址的变化示意。
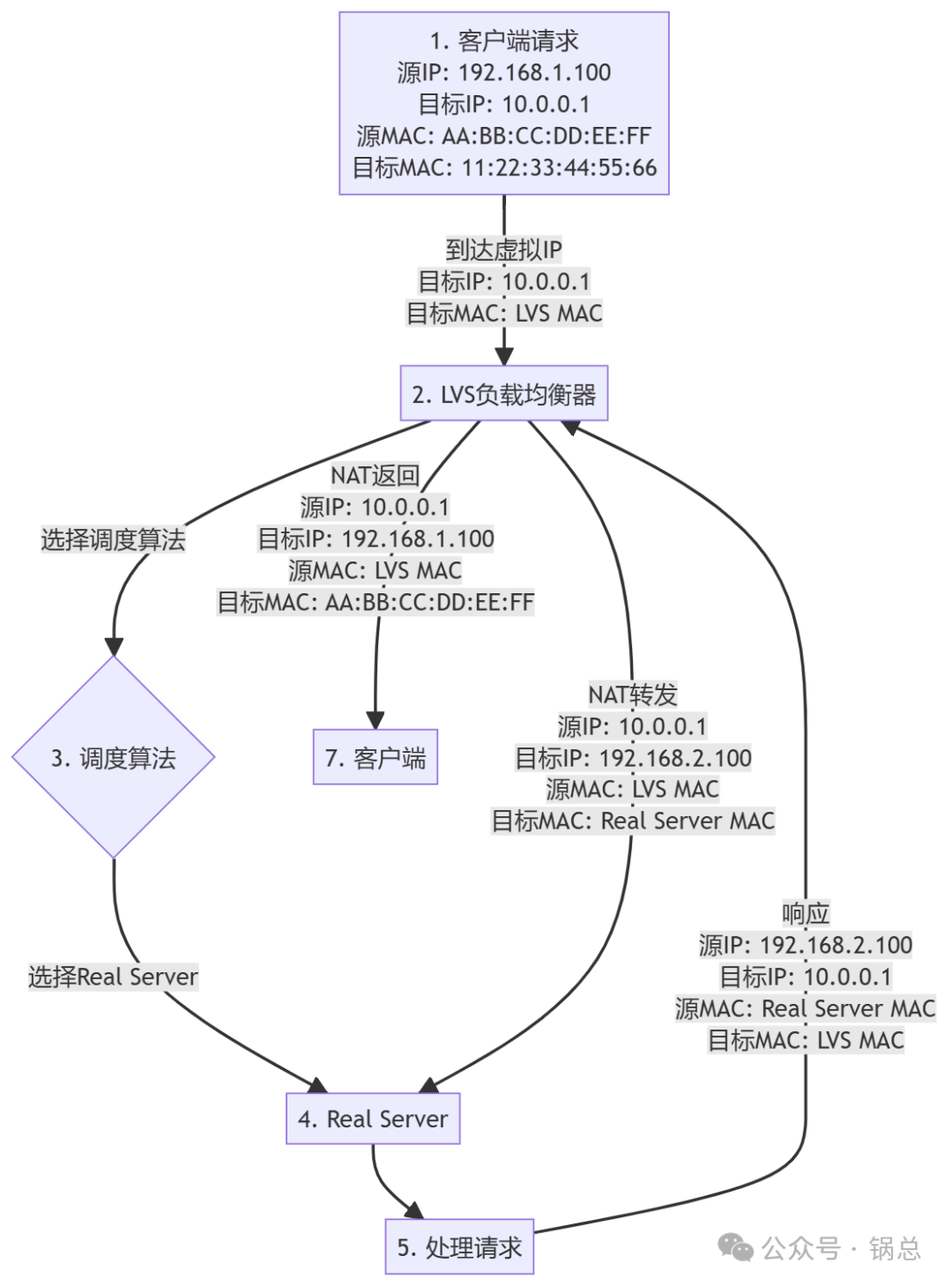
1. NAT 模式(Network Address Translation)
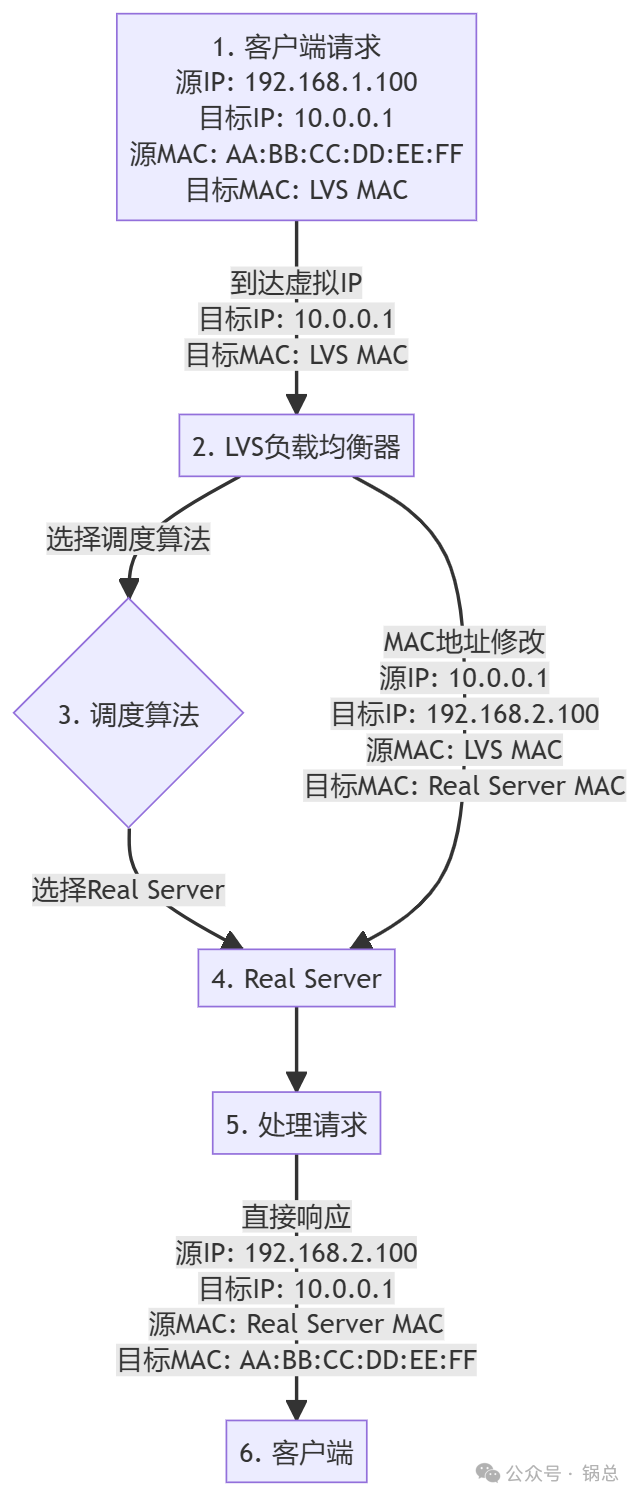
2. DR 模式(Direct Routing)
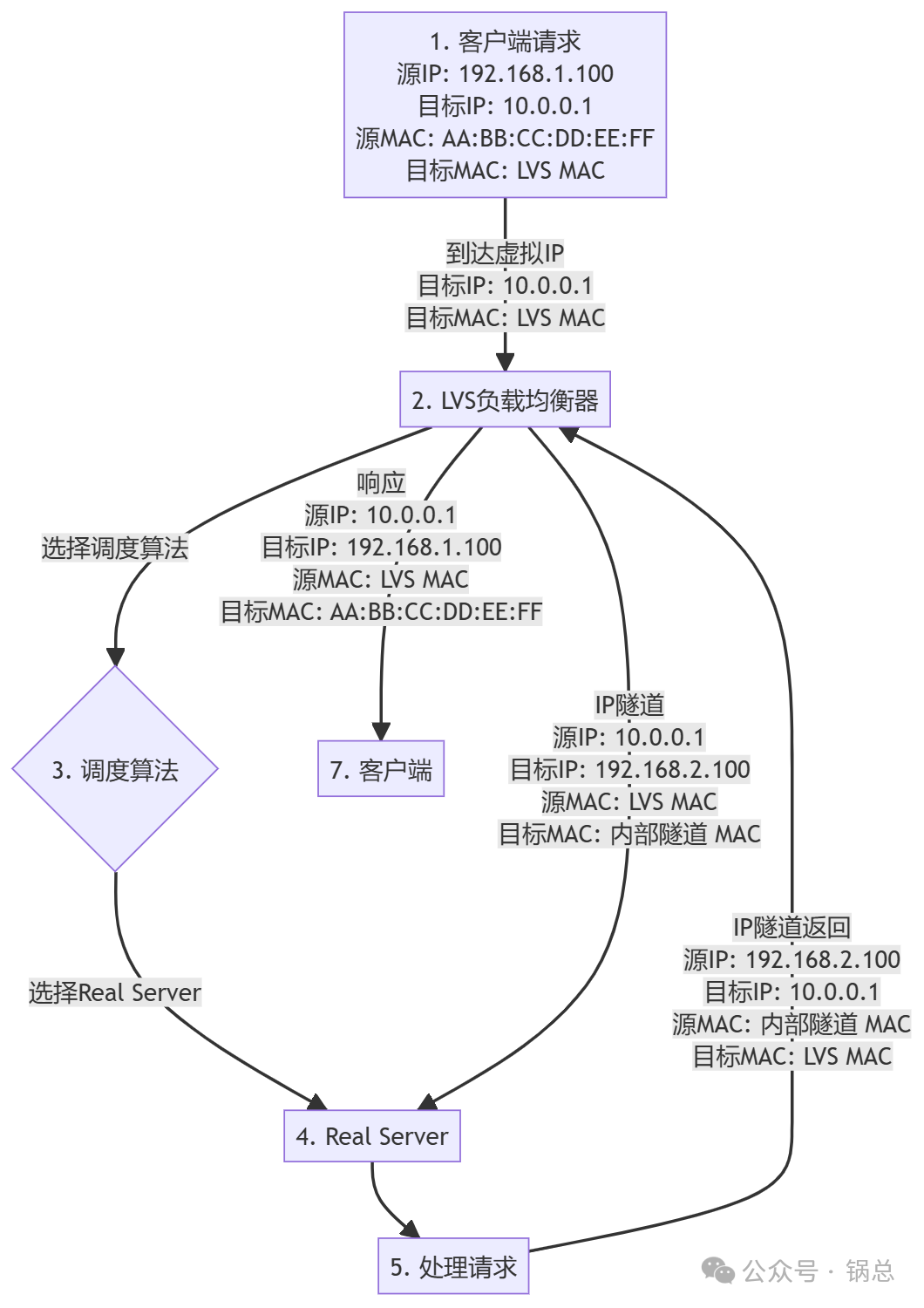
3. TUN 模式(IP Tunneling)
解释
- NAT 模式(Network Address Translation):
- 客户端请求到达 LVS,目标 IP 是 LVS 的虚拟 IP,目标 MAC 地址是 LVS 的 MAC 地址。
- LVS 将请求的目标 IP 修改为 Real Server 的 IP,目标 MAC 地址修改为 Real Server 的 MAC 地址。
- Real Server 处理请求后,将响应返回给 LVS,LVS 再将响应的目标 IP 和 MAC 地址修改回客户端的 IP 和 MAC 地址。
- DR 模式(Direct Routing):
- 客户端请求到达 LVS,目标 IP 和 MAC 地址都是 LVS 的。
- LVS 修改数据包的目标 MAC 地址为 Real Server 的 MAC 地址。
- Real Server 直接处理请求并将响应直接发送回客户端,源和目标 MAC 地址是 Real Server 和客户端的 MAC 地址。
- TUN 模式(IP Tunneling):
- 客户端请求到达 LVS,目标 IP 和 MAC 地址是 LVS 的。
- LVS 通过 IP 隧道将请求转发给 Real Server,源和目标 IP 地址是 LVS 和 Real Server 的 IP 地址,目标 MAC 地址是内部隧道的 MAC 地址。
- Real Server 处理请求并通过 IP 隧道返回响应,LVS 再将响应发送给客户端,源和目标 IP 地址回到客户端的 IP 地址和 LVS 的 IP 地址,源和目标 MAC 地址回到 LVS 和客户端的 MAC 地址。
这些 Mermaid 图表可以帮助你理解 LVS 在不同工作模式下如何处理和转发数据包。
高并发涉及理论
高并发系统的设计和优化需要遵循多个计算机科学理论和原则。以下是一些关键理论和原则,它们在高并发系统中发挥重要作用:
1. CAP 定理
CAP 定理(CAP Theorem)指出,在分布式系统中,不可能同时保证一致性(Consistency)、可用性(Availability)和分区容忍性(Partition Tolerance),最多只能同时满足其中的两项。
- 一致性(C):每次读取操作都能返回最新的写入结果。
- 可用性(A):每次请求都能收到成功或失败的响应。
- 分区容忍性(P):系统在出现网络分区时仍能继续运行。在高并发系统中,设计者需要根据具体需求在 CAP 特性之间进行权衡。
2. BASE 理论
BASE 理论是对 CAP 定理的实际应用和补充,特别适用于需要高可用性和高性能的系统。
- 基本可用(Basically Available):系统在发生故障时仍能保证基本的可用性。
- 软状态(Soft State):系统状态可以是软的,并不要求实时一致。
- 最终一致性(Eventual Consistency):系统最终会达到一致状态,但不要求实时一致。BASE 理论强调通过牺牲强一致性来换取系统的可用性和性能。
3. 负载均衡算法
高并发系统中的负载均衡器需要使用各种算法来分发请求,确保各服务器的负载均衡。这些算法包括:
- 轮询(Round Robin):依次将请求分发到服务器。
- 最小连接数(Least Connections):将请求分发到当前连接数最少的服务器。
- 加权轮询(Weighted Round Robin):根据服务器的权重分发请求。
- 一致性哈希(Consistent Hashing):通过哈希算法将请求分发到特定服务器,减少服务器变化时的请求转移。
4. 队列理论
队列理论用于分析和优化系统中的等待时间和处理时间。常见的队列模型有:
- M/M/1 队列:单服务器、泊松到达、指数服务时间。
- M/M/c 队列:多服务器、泊松到达、指数服务时间。队列理论帮助设计者理解系统的排队行为,优化资源分配和调度策略。
5. 分布式一致性协议
在分布式系统中,为了保证数据一致性和系统的可靠性,需要使用一致性协议,如:
- Paxos:一种经典的分布式一致性算法,保证在分布式系统中达成一致。
- Raft:一种更易理解和实现的分布式一致性算法,提供领导选举、日志复制和故障恢复等机制。这些协议确保在高并发环境下,多个节点能够保持一致的状态。
6. 异步编程模型
异步编程模型通过非阻塞操作和回调机制,提高系统的并发处理能力。常见的异步编程模型有:
- 事件驱动模型:通过事件循环和回调函数处理异步操作,如 Node.js。
- Future/Promise 模型:通过 Future 或 Promise 对象表示异步操作的结果,如 Java 的 CompletableFuture、JavaScript 的 Promise。异步编程减少了线程阻塞,提高了系统的响应速度和吞吐量。
7. ACID 和 BASE
在数据库事务处理中,ACID 和 BASE 是两种不同的理论:
- ACID:强调强一致性和可靠性的事务属性(原子性、一致性、隔离性、持久性)。
- BASE:强调高可用性和最终一致性的事务属性(基本可用、软状态、最终一致性)。高并发系统需要根据具体需求选择合适的事务处理模型,以平衡一致性和可用性。
8. 幂等性
幂等性是指操作可以重复执行多次而不会产生不同的结果。在高并发系统中,确保操作的幂等性可以避免重复请求带来的问题,如重复支付、重复下单等。
总结
高并发系统的设计和优化需要综合运用多个计算机理论和原则,包括 CAP 定理、BASE 理论、负载均衡算法、队列理论、分布式一致性协议、异步编程模型、ACID 和 BASE、以及幂等性等。这些理论和原则帮助设计者在高负载和高并发环境下,构建高性能、可扩展和可靠的系统。
Go伪代码实现
实现一个遵循上述计算机理论的高并发系统,需要综合运用各种技术和原则。以下是一个示例伪代码,展示如何使用 Go 语言实现一个高并发 HTTP 服务器,并结合 CAP 定理、负载均衡、缓存、异步处理等技术。
示例伪代码
package mainimport (
"fmt"
"log"
"net/http"
"runtime"
"sync/atomic"
"time""github.com/gomodule/redigo/redis")
// RequestCount tracks the number of processed requests
var RequestCount int64// Redis pool for caching
var redisPool *redis.Pool// Initialize Redis pool
func initRedis() {
redisPool = &redis.Pool{
MaxIdle: 10,
MaxActive: 100,
IdleTimeout: 240 * time.Second,
Dial: func() (redis.Conn, error) {
c, err := redis.Dial("tcp", "localhost:6379")
if err != nil {
panic(err)
}
return c, err
},
}
}// CacheGet gets a value from Redis
func CacheGet(key string) (string, error) {
conn := redisPool.Get()
defer conn.Close()
return redis.String(conn.Do("GET", key))
}// CacheSet sets a value in Redis
func CacheSet(key string, value string) error {
conn := redisPool.Get()
defer conn.Close()
_, err := conn.Do("SET", key, value)
return err
}// Handler function for HTTP requests
func handler(w http.ResponseWriter, r *http.Request) {
atomic.AddInt64(&RequestCount, 1)// Check cache cachedValue, err := CacheGet("key") if err == nil && cachedValue != "" { fmt.Fprintf(w, "Cached Value: %s", cachedValue) return } // Simulate processing and generate response response := "Hello, World!" // Cache the response CacheSet("key", response) fmt.Fprintf(w, response)}
func main() {
// Set the maximum number of CPU cores to use
runtime.GOMAXPROCS(runtime.NumCPU())// Initialize Redis pool initRedis() // Create a new HTTP server http.HandleFunc("/", handler) // Start the HTTP server in a separate goroutine go func() { log.Fatal(http.ListenAndServe(":8080", nil)) }() // Monitor and print the request count go func() { for { log.Printf("Handled %d requests\n", atomic.LoadInt64(&RequestCount)) time.Sleep(1 * time.Second) } }() // Block the main goroutine to keep the program running select {}
}
解释
- CAP 定理和 BASE 理论:
- 使用 Redis 缓存数据,实现最终一致性,符合 BASE 理论。
- 在分布式环境中,需要根据实际情况选择在 CAP 三者中的权衡。
- 负载均衡:
- 伪代码示例假设在前端使用了 Nginx 或 HAProxy 进行负载均衡,将流量分发到多个实例。
- 缓存:
- 使用 Redis 实现内存缓存,通过
CacheGet和CacheSet方法进行缓存操作,减少数据库压力。
- 使用 Redis 实现内存缓存,通过
- 异步处理:
- 使用 goroutines 处理 HTTP 请求和监控系统性能,充分利用 Go 的并发特性。
- 幂等性:
- 确保缓存操作是幂等的,多次相同请求会得到相同的结果。
- 监控和日志:
- 在独立的 goroutine 中监控并记录请求数,方便性能调优和问题排查。
扩展
实际生产环境中,可能需要进一步优化和扩展这个示例:
- 连接池:
- 使用数据库连接池和 HTTP 连接池,重用连接,减少频繁创建和销毁连接的开销。
- 限流和熔断:
- 实现限流和熔断机制,防止过载请求对系统造成影响。可以使用工具如 Hystrix 来实现这些功能。
- 性能监控:
- 使用 Prometheus 和 Grafana 实现更全面的性能监控和报警。
- 日志系统:
- 集成 ELK 堆栈(Elasticsearch、Logstash、Kibana)实现集中化日志管理。
通过合理利用 Go 语言的并发特性和相关工具,可以构建一个高效、可靠的高并发系统。
高并发历史演进
最后讲一讲高并发系统的演进历史,可以分为以下几个阶段,每个阶段都有其代表性技术和特点。
1. 单机高并发
在计算机初期,单台计算机被用于处理所有任务。为提高单机处理能力,出现了多任务处理和多线程技术。
特点:
- 多任务处理:操作系统能够同时处理多个任务。
- 多线程编程:单个应用程序内可以创建多个线程并发执行。
2. 集群和负载均衡
随着互联网的普及,单机无法满足高并发需求,开始出现集群技术和负载均衡技术。
特点:
- 集群技术:多台服务器组成一个集群,共同处理请求。
- 负载均衡:通过硬件或软件(如 LVS、Nginx)将请求均匀分发到集群中的各个节点。
3. 分布式系统
为了进一步提高并发处理能力和系统可靠性,系统开始向分布式架构发展。
特点:
- 分布式计算:任务被分解为多个子任务,分配到不同的节点处理(如 MapReduce)。
- 分布式存储:数据被分散存储在多个节点上(如 HDFS)。
- 一致性协议:如 Paxos、Raft,用于保证分布式系统中的数据一致性。
4. 微服务架构
随着业务复杂度增加,单一的分布式系统难以维护和扩展,微服务架构应运而生。
特点:
- 服务拆分:将单一应用拆分为多个独立的服务,每个服务负责特定的业务功能。
- 服务通信:使用轻量级通信协议(如 HTTP、gRPC)进行服务间通信。
- 容器化:使用 Docker、Kubernetes 等容器技术部署和管理微服务。
5. 云计算和无服务器架构
云计算提供了按需扩展的能力,无服务器架构进一步简化了应用部署和运维。
特点:
- 云计算平台:如 AWS、Azure、Google Cloud 提供弹性计算资源和各种服务。
- 无服务器架构:如 AWS Lambda,开发者只需关注代码逻辑,无需管理服务器。
6. 现代高并发技术
现代高并发系统结合了多种技术和理念,以应对复杂的业务需求和极高的并发量。
特点:
- 事件驱动架构:如 Kafka、RabbitMQ 等消息队列,用于解耦和异步处理。
- 流处理:如 Apache Flink、Kafka Streams 实时处理大量数据流。
- 多样化数据库:如 NoSQL 数据库(MongoDB、Cassandra)和 NewSQL 数据库(CockroachDB、TiDB),满足不同的数据存储需求。
- 智能调度:结合 AI 和大数据分析进行智能调度和资源管理。
总结
高并发系统的演进是一个不断追求性能优化、扩展性和可靠性的过程。从单机系统到分布式系统,再到微服务和云计算,每个阶段都有其独特的技术和方法。通过这些技术的演进和结合,我们能够构建出更加高效、可靠的高并发系统。
完。