Series的布尔索引
从Series中获取满足某些条件的数据,可以使用布尔索引

然后可以手动创建布尔值列表
代码语言:javascript
复制
bool_index = [True,False,False,False,True]
scientists[bool_index] # 查询行索引,列索引是用列名
筛选年龄大于平均年龄的科学家
代码语言:javascript
复制
age_mean = sci['Age'].mean()
sci['Age']>age_mean
# 生成
0 False
1 True
2 True
3 True
4 False
5 False
6 False
7 True我们通过逻辑运算获取了对应的布尔值,只需要将布尔值作为索引就可以获得对应的元素
代码语言:javascript
复制
sci[sci['Age']>age_mean]Series 的运算
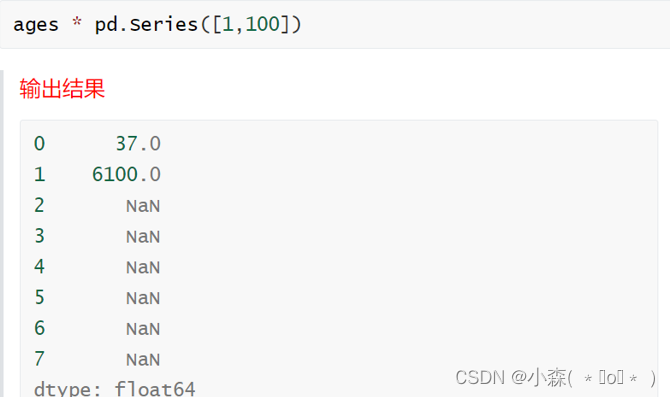
Series和数值型变量计算时,变量会与Series中的每个元素逐一进行计算
两个Series之间计算,如果Series元素个数相同,则将两个Series对应元素进行计算
代码语言:javascript
复制
sci['Age']+sci['Age'] # age列值增加一倍元素个数不同的Series之间进行计算,会根据索引进行 索引不同的元素最终计算的结果会填充成缺失值,用NaN表示.NaN表示Null
DataFrame常用属性方法
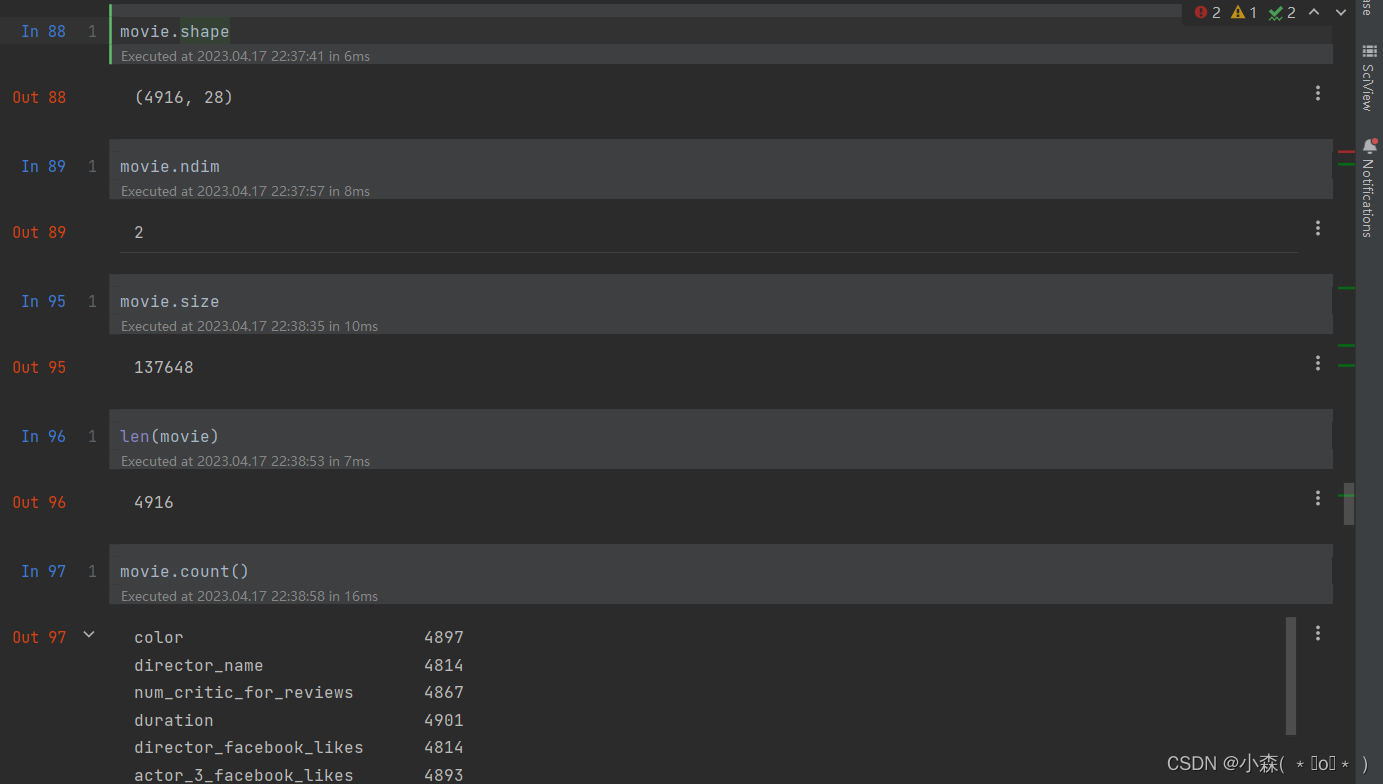
ndim是数据集的维度 size是数据集的行数乘列数 count统计数据集每个列含有的非空元素

也可以利用布尔索引获取某些元素(使用逻辑运算获取最小值)
更改Series 和DataFrame
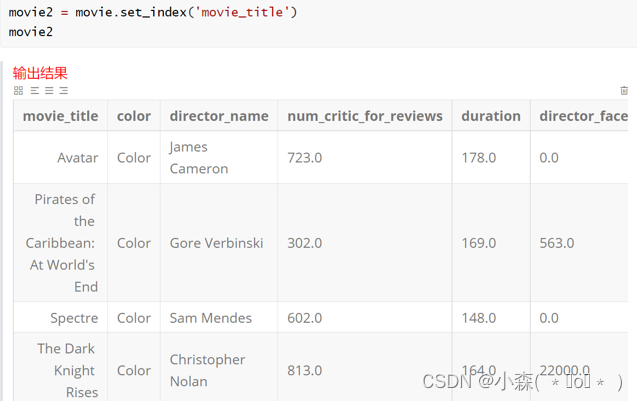
通过set_index()方法设置行索引名字 加载数据文件时,如果不指定行索引,Pandas会自动加上从0开始的索引
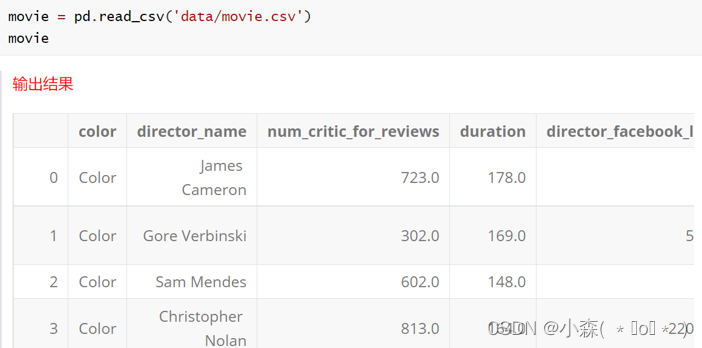
如果提前写好行索引的列表,可以用set_index引入进来,也可以直接写入列表内容
加载数据的时候,也可以通过通过index_col参数,指定使用某一列数据作为行索引
代码语言:javascript
复制
movie2 = pd.read_csv('data/movie.csv',index_col='movie_title')代码语言:javascript
复制
movie.set_index('movie_title',inplace=True)
# pandas的API中, 凡是涉及数据修改的, 基本都有一个inplace参数, 默认值都是False, inplace参数用来控制实在副本上修改数据, 还是直接修改原始数据通过reset_index()方法可以重置索引,将索引重置成自动的索引
修改列名(columns) 和 行索引(index)名:
1.通过rename()方法对原有的行索引名和列名进行修改
2.将index 和 columns属性提取出来,修改之后,再赋值回去
3.通过dataframe[列名]添加新列
4.使用insert()方法插入列 loc 新插入的列在所有列中的位置(0,1,2,3...) column=列名 value=值
代码语言:javascript
复制
# index 如何调整行名字 传入字典 {老名字: 新名字, 老名字:新名字}
# columns 如何调整列名 传入字典 {老名字: 新名字, 老名字:新名字}
movie2.rename(index={'Avatar':'阿凡达','Star Wars: Episode VII - The Force Awakens':'星球大战7'},columns={'director_name':'导演名字','actor_1_name':'主演'}).head()代码语言:javascript
复制
# 添加一列
movie['社交媒体点赞总数'] = movie.actor_1_facebook_likes+movie.actor_2_facebook_likes+movie.actor_3_facebook_likes+movie.director_facebook_likes
# 删除一列
movie.drop('社交媒体点赞总数',axis='columns',inplace=True)
# 插入一列
movie.insert(loc=0,column='利润',value=movie['gross']-movie['budget'])代码语言:javascript
复制
columns = movie2.columns
columns = columns.to_list() # 将原列名放入列表
columns[1] = '导演'
columns[3] = '时长'
movie2.columns = columns # 将修改后的列表命名为数据的全部列名