1、输入序列怎样传入注意力模块
注意力模块(Attention module)存在于每个Encoder及Decoder中。放大编码器的注意力:
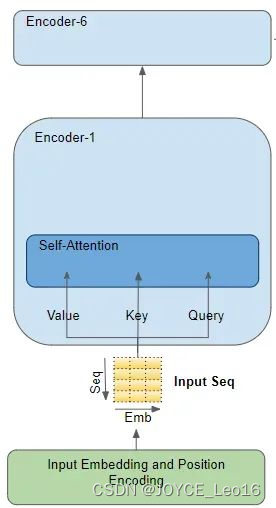
举个例子,假设我们正在处理一个英语到西班牙语的翻译问题,其中一个样本的源序列是“The ball is blue”,目标序列是“La bola es azul”。
源序列首先通过 Embedding 和 Position Encoding层,为序列中的每个单词生成嵌入。随后嵌入被传递给编码器,到达 Attention module。
Attention module中,嵌入的序列通过三个线性层(Linear layers),产生三个独立的矩阵——Quey、Key、Value。这三个矩阵被用来计算注意力得分。这些矩阵的每一“行”对应于源序列中的一个词。
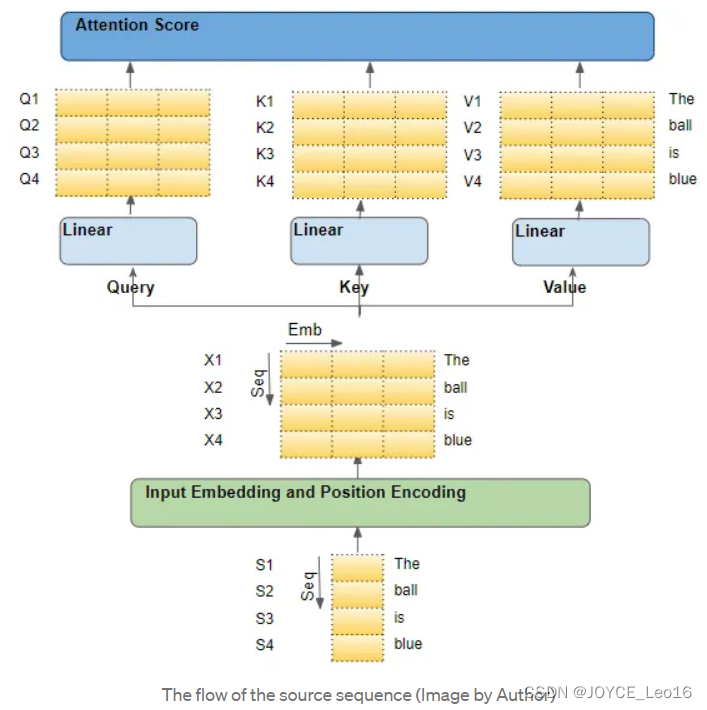
2、进入注意力模块的矩阵的每一行,都是源序列中的一个词
一个理解Attention的方法是。从源序列中的单个词出发,观察其在Transformer中的路径。通过关注Attention module内部的情况,我们可以清楚地看到每个词都是与其他词是如何互动的。
因此,需要特别关注的是 Attention module 对每个词进行的操作,以及每个向量如何映射到原始输入词,而不需要担心诸如矩阵形状、具体计算、多少个注意力头等其他细节,因为这些细节与每个词的去向没有直接关系。
为了简化解释和可视化,让我们忽略嵌入维度,将一个“行”作为一个整体进行理解。
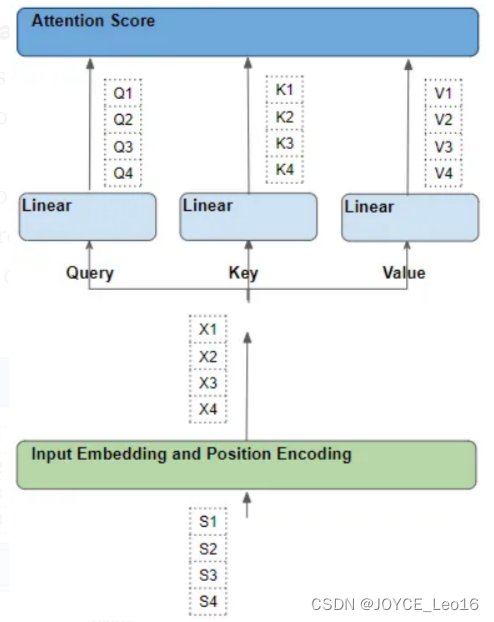
3、每一行,都会经过一系列可学习的变换操作
每个这样的“行”都是通过一系列的诸如嵌入、位置编码和线性变换等转换,从其相应的源词中产生。而所有的转换都是可训练的操作。这意味着在这些操作中,使用的权重不是预先确定的,而是通过模型输出进行学习的。
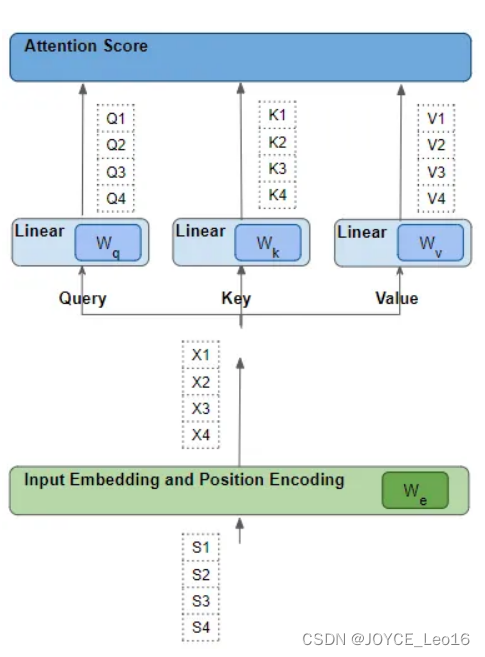
关键问题是,Transformer 如何确定哪一组权重会给它带来最佳效果?(记住这一点,稍后会回到这个问题上)。
4、如何得到注意力分数
Attention module 中执行多个步骤,在这里,我们只关注线性层和 "注意力 "得分(Attention Score)。
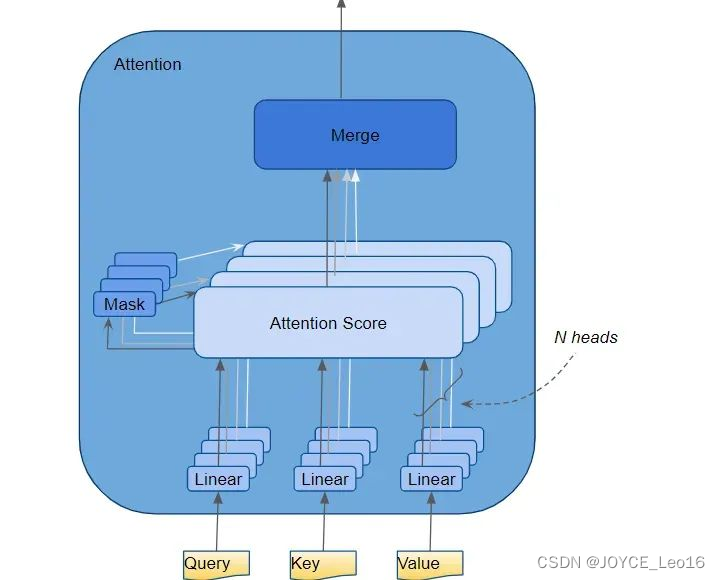
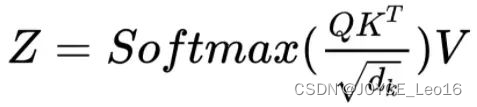
从公式中可以看到,Attention module的第一步是在Query矩阵的 Key 矩阵的转置之间进行矩阵的点积运算。看看每个单词会发生什么变化。
Query 与 Key的转置进行点积,产生一个中间矩阵,即所谓“因子矩阵”。因子矩阵的每个单元都是两个词向量之间的矩阵乘法。
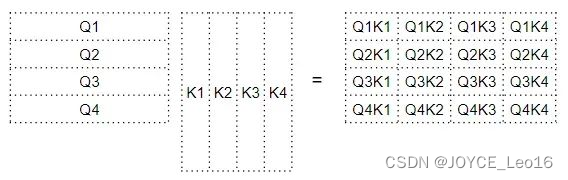
如下所示,因子矩阵第4行的每一列都对应于Q4向量与每个K向量之间的点积;因子矩阵的第2列对应与每个Q向量与K2向量之间的点积。
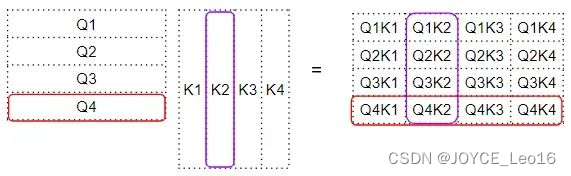
因子矩阵再和 V 矩阵之间进行矩阵相乘,产生注意力分数(Attention Score)。可以看到,输出矩阵中第 4行对应的是Q4矩阵与所有其他对应的 K和V相乘:
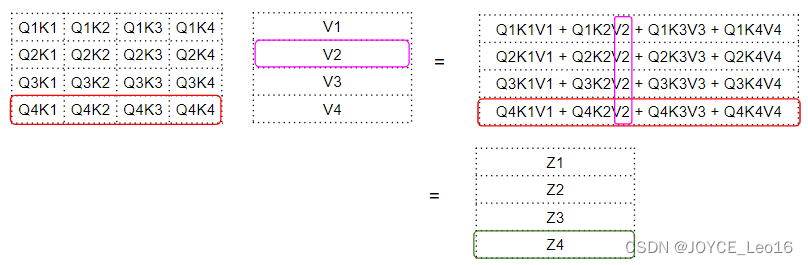
这就产生了由注意力模块输出的注意力分数向量——Attention Score Vector(Z)。
可以将注意力得分理解成一个词的“编码值”。这个编码值是由“因子矩阵”对 Value 矩阵的词加权而来。而“因子矩阵”中对应的权值则是该特定单词的Query向量和Key向量的点积。再啰嗦一遍:
- 一个词的注意力得分可以理解为该词的“编码值”,它是注意力机制最终为每个词赋予的表示向量。
- 这个“编码值”是由“值矩阵”(Value矩阵)中每个词的值向量加权求和得到的。
- 加权的权重就是“因子矩阵”中对应的注意力权重。
- “因子矩阵”中的注意力权重是通过该词的查询向量(Query)与所有词的键向量(Key)做点积计算得到的。

5、Query、Key、Value的作用
对某一个查询向量Query,可以理解为正在计算注意力分数的词。而Key向量和Value向量是我们正在观察的词,即该词与查询词的相关程度。
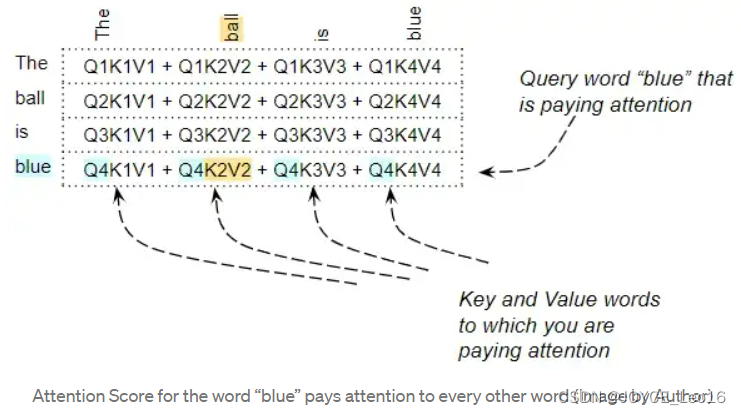
例如,对于“The ball is blue”这个句子,单词“blue”这一行包含“blue”与其他每个单词的注意力分数。在这里,“blue”是Query word,其他词是“Key / Value”。
注意力的计算还包含其他操作,如除法和Softmax计算,但本文可以忽略它们。它们只是改变了矩阵中的数值,但并不影响矩阵中每个词行的位置。它们也不涉及任何词间的相互作用。
6、点积:衡量向量之间的相似度
Attention Score是通过做点乘,然后把它们加起来,捕捉某个特定的词和句子中其他词之间的关系。但是,矩阵乘法如何帮助Transformer确定两个词之间的相关性?
为了理解这一点,请记住,Query,Key,Value行实际上是具有嵌入维度的向量。让我们放大看看这些向量之间的矩阵乘法是如何计算的:
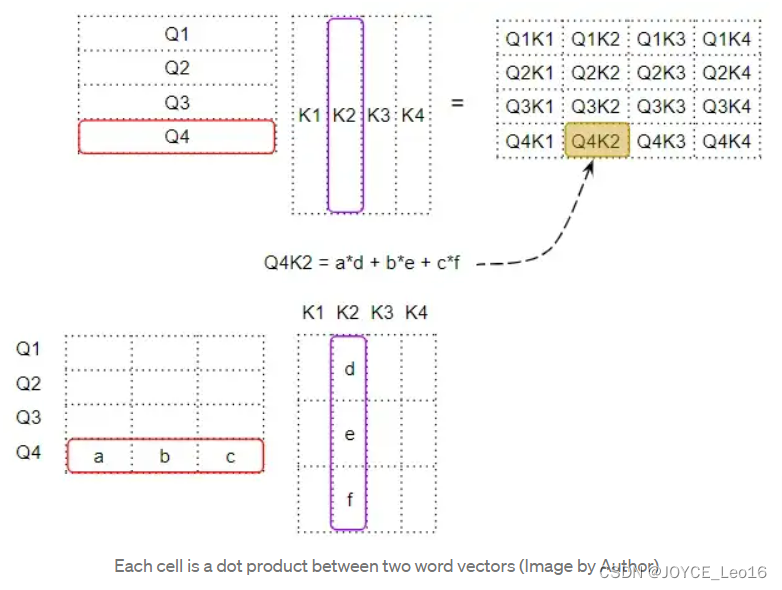
当我们在两个向量之间做点积时,我们将一对数字相乘,然后相加:
- 如果这两个成对的数字(如上面的‘a’和‘d’)都是正数或都是负数,那么积就会是正数。乘积会增加最后的总和。
- 如果一个数字是正数,另一个是负数,那么乘积将是负数。乘积将最后减少最后的总和。
- 如果乘积是正数,两个数字越大,它们对最后的总和贡献越大。
这意味着,如果两个向量中相应数字的符号是一致的,那么最终的和就会更大。
7、Transformer如何学习单词之间的相关性
上述点积的概念也适用于Attention Score的计算。如果两个词的向量更加一致,Attention score就会更高。我们希望Transformer的操作是,对于句子中的两个词,若相互关联,二者的Attention score就高。而对于两个互不相关的词,我们则希望其得分较低。
例如,对于“The black cat drank the milk”这个句子,“milk”这个词与“drank”非常相关,与“cat”的相关性可能稍差,而与“black”无关。我们希望“milk”和“drank”产生一个高的注意力分数,“milk”和“cat”产生一个稍低的分数,而“milk”和“black”则产生一个可以忽略的分数。这就是我们希望模型学习产生的输出。
而要做到这一点,“milk”和“drank”的词向量必须是一致的。“milk”和“cat”的向量会有一些分歧。而对于“milk”和“black”来说,它们会有很大的不同。
让我们回到前述的问题—Transformer 是如何找出哪一组权重会给它带来最佳结果的?
词向量是根据词嵌入和线性层的权重生成的。因此,Transformer 可以学习这些嵌入向量、线性层权重等来产生上述要求的词向量。
换句话说,它将以这样的方式学习这些嵌入和权重:
如果一个句子中的两个词是相互关联的,那么它们的词向量将是一致的。从而产生一个更高的关注分数;对于那些彼此不相关的词,词向量将不会被对齐,并会产生较低的关注分数。
因此,"milk "和 "drank "的嵌入将非常一致,并产生较高的注意分数。对于 "milk "和 "cat",它们会有一些分歧,产生一个稍低的分数,而对于 "milk "和 "black",它们会有很大的不同,产生一个非常低的分数。
这就是注意力模块的原理。
8、总结
Query 和 Key 之间的点积计算出每对词之间的相关性。然后,这种相关性被用作一个 "因子 "来计算所有 Value 向量的加权和。该加权和的输出为注意力分数。
Transformer 通过对嵌入向量的学习,使彼此相关的词更加一致。
这就是引入三个线性层的原因之一:为 Attention module 提供更多的参数,使其能够通过学习调整词向量。
9、回顾:Transformer中的几种Attention module
Transformer 中共有三处使用到了注意力机制:
1. Encoder 中的自注意力机制:源序列与自身的注意力计算;
2. Decoder 中的自注意力机制:目标序列与自身的注意力计算;
3. Encoder-Decoder 中的注意力机制:目标序列对原序列的注意力计算。
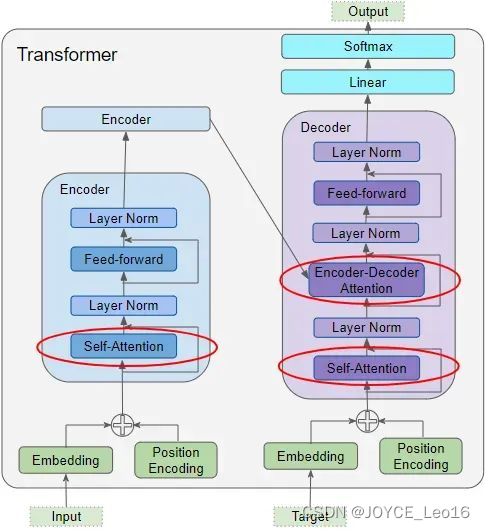
在 "Encoder Self Attention "中,我们计算源序列中每个单词与源序列中其他单词的相关性。这发生在编码器堆栈中的所有 Encoder 中。
Encoder Self Attention 中看到的大部分内容也适用于 Decoder Self Attention,只是存在一些微小但重要的区别。
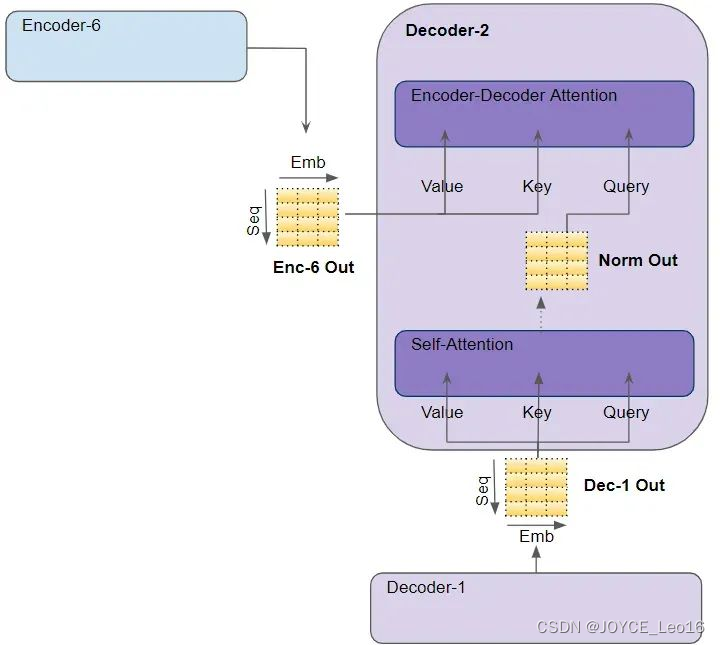
在 Decoder Self Attention 中,我们计算目标序列中每个单词与目标序列中其他单词的相关性。

在 "Encoder-Decoder Attention "中,Query 来自目标句,而Key/Value来自源句。这样,它就能计算出目标句中每个词与源句中每个词的相关性。
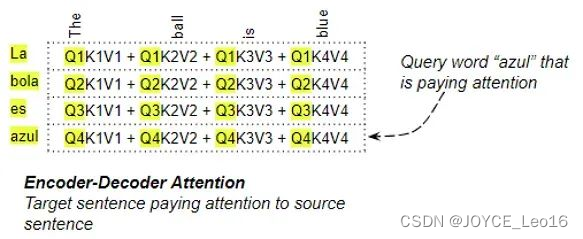
原文链接:https://towardsdatascience.com/transformers-explained-visually-not-just-how-but-why-they-work-so-well-d840bd61a9d3
参考:Afunby AI Lab