概述
量子计算和机器学习都是当前最炙手可热的研究领域。在量子计算方面,理论和硬件的一个个突破性进展让人们看到大规模通用量子计算机的脚步越来越近。在机器学习方面,具备机器学习能力的人工智能在某些方面的能力远超人类。
但传统计算机数据处理能力逐渐接近极限,而数据却在不断增长。机器学习技术的快速发展有赖于计算能力的提高,而量子计算因其独特性质,使得它无论在数据处理能力还是数据储存能力,都远超经典计算,从而可以解决目前机器学习算法处理海量大数据时计算效率低的问题,也有利于开发更加智能的机器学习算法,将大力加速机器学习的发展。本文将对量子计算在机器学习领域的发展进行介绍。
1. 经典机器学习
1.1 什么是机器学习
机器学习是一门能够让计算机像人类一样学习和行动的科学,也是计算机科学和数据科学的特定应用的一个子领域。机器学习的核心是“使用算法解析数据,从中学习,然后对新数据做出预测与判断”,也就是说计算机利用以获取的数据得出某一模型,然后利用此模型进行预测的一种方法,这个过程跟人的学习过程有些类似,比如人获取一定的经验,可以对新问题进行预测。其流程如下图所示:
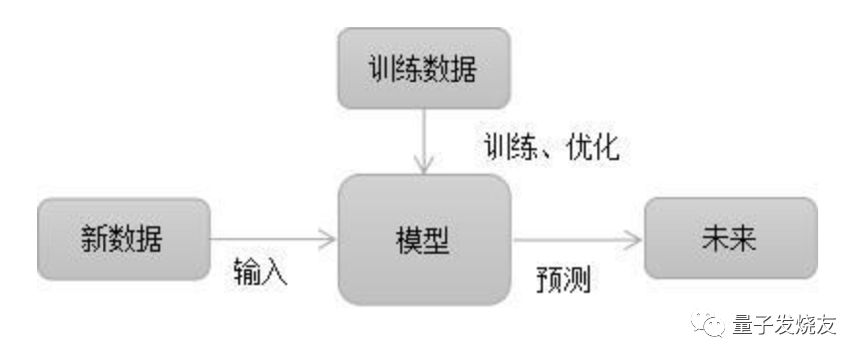
1.2 机器学习的方法论
机器学习算法的基本目标是对训练样本进行泛化,即成功地解释以前从未见过的数据。机器学习的方法论和人类科研的过程有着异曲同工之妙,下面以“机器从牛顿第二定律实验中学习知识”为例,来深入理解机器学习(监督学习)的方法论本质,即在“机器思考”的过程中确定模型的三个关键要素:假设、评价、优化。
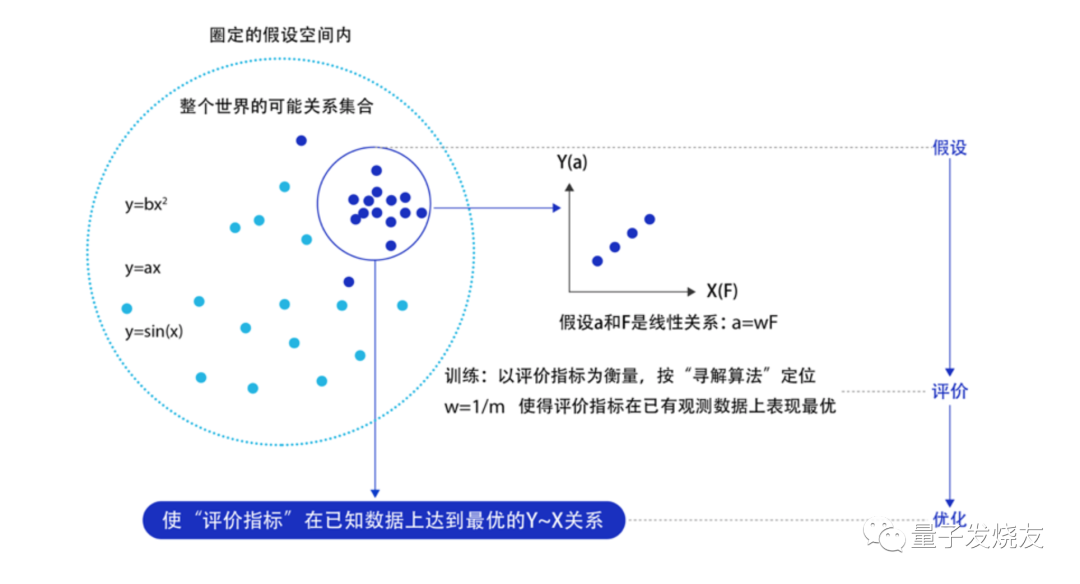
机器学习算法有很多不同的类型,通常按学习方式(即监督学习,无监督学习,半监督学习)或形式/功能相似(即分类,回归,决策树,聚类,深度学习等)分类。机器学习算法的所有组合均包含以下内容:
• 模型假设:世界上的可能关系千千万,漫无目标的试探 Y ~ X 之间的关系显然是十分低效的。因此假设空间先圈定了一个模型能够表达的关系可能,如蓝色圆圈所示。机器还会进一步在假设圈定的圆圈内寻找最优的 Y ~ X 关系,即确定参数 w 。
• 评价函数:寻找最优之前,需要先定义什么是最优,即评价一个 Y~X 关系的好坏的指标。通常衡量该关系是否能很好的拟合现有观测样本,将拟合的误差最小作为优化目标。
• 优化算法:设置了评价指标后,就可以在假设圈定的范围内,将使得评价指标最优(损失函数最小/最拟合已有观测样本)的 Y~X 关系找出来,这个寻找最优解的方法即为优化算法。最笨的优化算法即按照参数的可能,穷举每一个可能取值来计算损失函数,保留使得损失函数最小的参数作为最终结果。
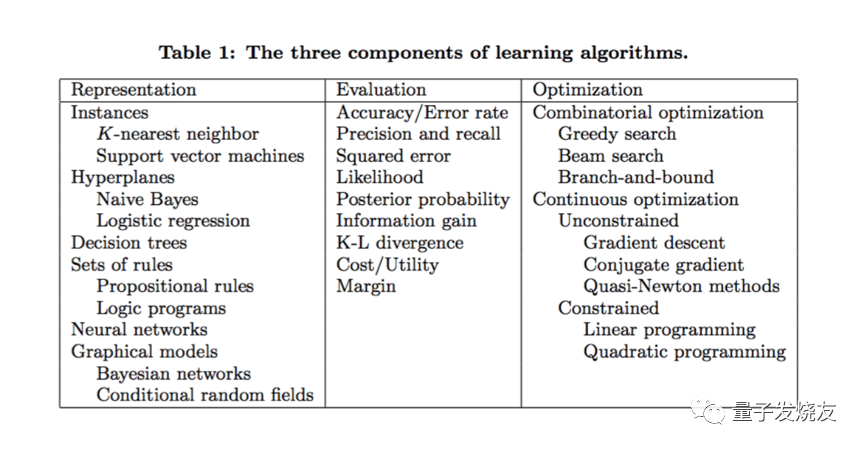
图片来源:华盛顿大学Pedro Domingo博士
1.3 机器学习的实现
机器学习的实现可以分成两步:训练和预测,类似于归纳和演绎:
• 归纳: 从具体案例中抽象一般规律,机器学习中的“训练”亦是如此。从一定数量的样本(已知模型输入X和模型输出Y)中,学习输出Y与输入X的关系(可以想象成是某种表达式)。
• 演绎: 从一般规律推导出具体案例的结果,机器学习中的“预测”亦是如此。基于训练得到的Y与X之间的关系,如出现新的输入X,计算出输出Y。通常情况下,如果通过模型计算的输出和真实场景的输出一致,则说明模型是有效的。
1.4 机器学习的主要分类
机器学习是一种能从数据中学习的算法,通过建立模型进行自我学习。机器学习有以下几种学习方法:
(1)监督学习
监督学习通过对数据样本因子和已知的结果建立联系,提取特征值和映射关系,通过已知的结果,已知数据样本不断的学习和训练,对新的数据进行结果的预测。监督学习使用一组标记数据来训练机器学习算法,以理解特定任务,例如在两个不同的对象(猫与狗)之间进行分类。该算法引入了一个新的未知数据点,并且根据其先前的训练,它必须预测如何对该新输入进行分类(无论是狗还是猫都是基于其不同特征集)。
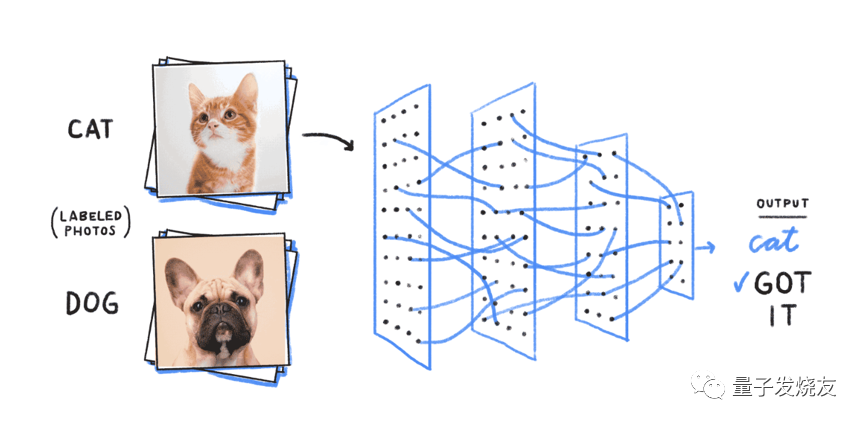
(2)半监督学习
半监督学习是将监督学习和无监督学习结合的一种学习方式。半监督学习训练中含有部分标记数据和未标记数据构成。通过半监督学习的方法可以实现分类、回归、聚类的结合使用。半监督学习是最近比较流行的方法。
分类: 是在无类标签的样例的帮助下训练有类标签的样本,获得比只用有类标签的样本训练得到更优的分类;
回归: 在无输出的输入的帮助下训练有输出的输入,获得比只用有输出的输入训练得到的回归器性能更好的回归;
聚类: 在有类标签的样本的信息帮助下获得比只用无类标签的样例得到的结果更好的簇,提高聚类方法的精度。
(3)无监督学习
无监督学习跟监督学习的区别就是选取的样本数据无需有目标值。我们无需分析这些数据对某些结果的影响,只是分析这些数据内在的规律;现实中因为缺乏先验知识,难以人工的标注类别或者人工的进行标注成本太高。自然的希望通过直接使用未知的训练样本解决模式识别中的各种学习。在训练含有很多特征的数据集,学习到数据集上有用的结构性质。
(4)强化学习
强化学习是一种比较复杂的机器学习方法,强调系统与外界不断的交互反馈,它主要是针对流程中不断需要推理的场景,比如无人汽车驾驶,它更多关注性能。它是机器学习中的热点学习方法。
(5)深度学习
深度学习归根结底也是机器学习,不过它不同于监督学习、半监督学习、无监督学习、强化学习的这种分类方法,它是另一种分类方法,基于算法神经网络的深度,可以分成浅层学习算法和深度学习算法。浅层学习算法主要是对一些结构化数据、半结构化数据一些场景的预测,深度学习主要解决复杂的场景,比如图像、文本、语音识别与分析等。
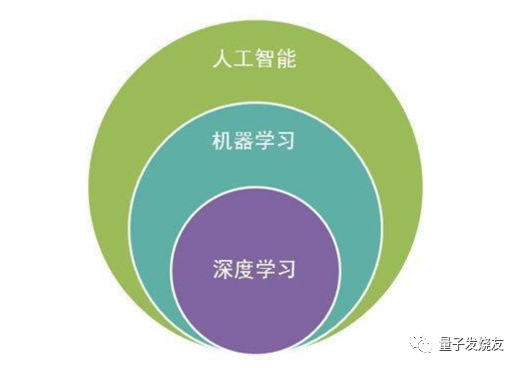
人工智能、机器学习、深度学习关系如下图所示:
1.5 机器学习的优缺点
现在人工智能主要依赖于机器学习,特别是监督学习,比如分类、回归。机器学习可以基于数据,帮助智能系统做出各种各样的判断。机器学习既有优势也有局限。
机器学习的优点
(1)补充数据挖掘
数据挖掘是检查一个或多个数据库以处理或分析数据并生成信息的过程。机器学习当应用于数据挖掘领域时,不仅可以自动化大数据分析,而且可以提供可用于支持决策的实际假设。
(2)持续改进
通过机器学习进行持续改进具有许多实际应用。以机器学习系统为例,该系统用于预测特定市场的消费模式。该系统不仅将参考历史数据来预测特定时期,还将继续参考新获取的数据以改善其分析消费模式的方式。
(3)任务自动化
使用机器学习的更实际的好处涉及可以导致任务自动化的自主计算机,软件程序和流程的开发。通过补充数据挖掘和不断改进,已开发并部署了机器学习系统以自行执行任务。自动化仍然可以补充人类活动。
机器学习的局限性
(1)严重依赖于数据
极端情况如果完全没有数据,那么机器学习也面临“巧妇难为无米之炊”的困境。比如人脸检测,如果给出的训练数据不充分,系统就很难检测出在各种情况下照片中的人脸,人在墙后露出半张脸或者把脸捂上的时候,系统就无法检测。如果想让系统能够覆盖这些情况,就要给系统提供充分的训练数据。数据驱动是机器学习的重要特点,换句话说也是它的局限。
(2)依赖于学习模型的类型
构建机器学习系统时,需要事先决定模型的类型,或者说定义模型的可能集合,比如做分类时,需要决定要学习的模型是线性模型还是非线性模型。如果问题是非线性问题,而选择的是线性模型,那么分类的效果就不会好。模型类型的选择左右了机器学习系统的性能。深度学习的本质是复杂模型的学习。
(3)不能执行不特定多种任务
可以把智能系统做一简单分类,首先看环境是否动态变化,如果环境不是动态变化的,这样的智能系统可能就是工业机器人。如果环境动态变化,其次看智能系统是否需要执行不特定多种任务,也就是说要做的事情是否已经事先定义好,只能执行特定多种任务就是汽车自动驾驶的情况,比如“直行、刹车、换道”。
(4)错误诊断与纠正
机器学习的一个显着局限性是它对错误的敏感性。这种不可避免的事实的实际问题是,当他们犯错时,诊断和纠正它们可能很困难,因为这将需要遍历算法和相关流程的潜在复杂性。
(5)学习中的时间限制
使用机器学习系统无法立即做出准确的预测。请记住,它是通过历史数据学习的。数据越大,暴露给这些数据的时间越长,其性能就会越好。例如,使用系统玩游戏并击败人类对手将需要向系统提供历史数据,并将其连续暴露于新获取的数据,以做出更好的预测或决策。
(6)验证问题
机器学习的另一个限制是缺乏可变性。机器学习处理的是统计事实,而不是文字事实。在历史数据未包括的情况下,将很难完全确定地证明机器学习系统所作的预测适用于所有情况。
(7)预测的局限性
与人类不同,计算机不是讲故事的人。机器学习系统无法始终为特定的预测或决策提供合理的理由。他们也仅限于回答问题而不是提出问题。另外,这些系统不了解上下文。根据所提供的用于训练的数据,机器学习还容易出现隐性和无意的偏差。人工输入对于更好地评估这些系统的输出仍然很重要。
2. 量子机器学习
2.1 什么是量子机器学习
量子机器学习 (QML) 基于两个概念构建:量子数据和混合量子经典模型。量子机器学习借助量子计算的高并行性,实现进一步优化传统机器学习的目的。
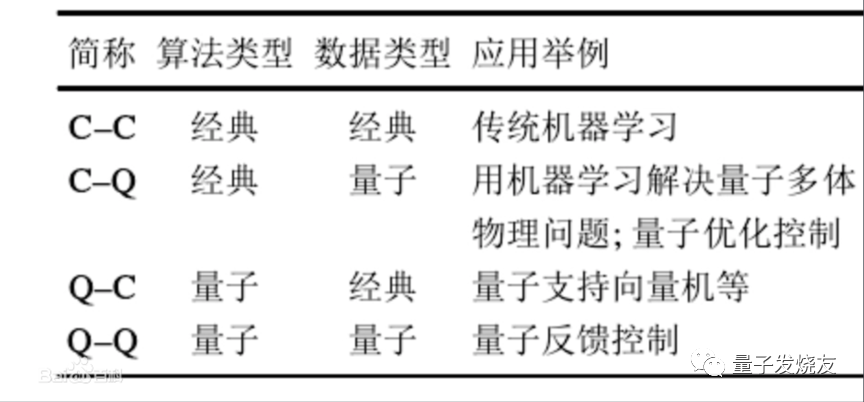
近年来, 随着量子计算机在计算规模和稳定性的突破, 基于量子算法的机器学习重新得到关注, 并成为一个迅速发展的研究方向。事实上,从经典–量子的二元概念出发可以将机器学习问题按照数据和算法类型的不同分为4类。
利用量子理论改进机器学习的方法大致可以分为两种:
(1) 通过量子算法使某些在经典计算机上不可计算的问题变为可计算的, 从而大幅降低机器学习算法的计算复杂度, 如量子退火(quantum annealing,QA)算法、Gibbs采样等;
(2) 量子理论的并行性等加速特点直接与某些机器学习算法深度结合, 催生出一批全新的量子机器学习模型,如张量网络、概率图模(probabilistic graphical model, PGM)等。
量子机器学习的训练数据必须以某种可以为量子计算机识别的格式载入, 经过量子机器学习算法处理以后形成输出, 而此时的输出结果是量子格式的, 需要经过测量读出得到笔者所需的最终结果。因此, 量子机器学习的复杂度与这3个过程都有关系。

量子数据
量子数据是在自然或人工量子系统中出现的任何数据源。这可以是由量子计算机生成的数据,例如从用于证明 Google 的量子霸权的 Sycamore 处理器收集的样本。量子数据具有叠加和纠缠的特性,使得其联合概率分布依赖大量经典算力资源来表示和存储。量子数据可以在量子处理器、传感器、网络中产生和模拟,包括化合物模拟、量子控制、量子通信网络、量子方法等。
下面是可以在量子设备上生成或模拟的量子数据示例:
• 化学模拟 - 提取有关化学结构和动力学的信息,并将其潜在地应用于材料科学、计算化学、计算生物学和药物发现等领域。
• 量子物质模拟 - 对高温超导或表现出多体量子效应的其他奇特物质状态进行建模和设计。
• 量子控制 - 可以对混合量子经典模型进行变分训练,以执行最佳的开环或闭环控制、校准和误差抑制。这包括用于量子设备和量子处理器的错误检测与纠正策略。
• 量子通信网络 - 使用机器学习来区分非正交量子态,并将其应用于结构化量子中继器、量子接收器和纯化装置的设计与构造。
• 量子计量 - 量子增强的高精度测量(例如量子传感和量子成像)本质上是在探针这种小型量子设备上完成的,可以通过变分量子模型来设计或改进。
混合量子经典模型
由于近来的量子处理器还相对较小,充满噪声,量子模型不能仅依赖量子处理器——NISQ 处理器需要和经典处理器配合,才能变得高效。
量子模型可以表示和归纳包含量子力学起源的数据。由于近期的量子处理器仍然很小且嘈杂,因此量子模型无法仅使用量子处理器来归纳量子数据。NISQ 处理器必须与传统的协处理器协同工作才能生效。
TFQ 包含了量子计算所需的基本结构(如量子比特、门、电路……),用户指定的量子计算可在模拟的环境以及真实的硬件上执行。Cirq 还包含大量的构件,用以帮助用户为 NISQ 处理器设计高效的算法,使得量子-经典混合算法的实现能在量子电路模拟器上运行,最终在量子处理器上运行。
3. 量子机器学习框架介绍
随着机器学习的快速崛起,特别是深度学习中从数据挖掘到人脸识别,从医学诊断到自动驾驶,人类生活中很多方面都被机器学习技术所影响。为适应大数据时代海量数据的处理和分析,量子机器学习应运而生。量子机器学习基于经典计算机的机器学习算法,利用量子计算的处理效率可进一步提高数据处理能力。针对不同的应用场景,量子机器学习与经典的机器学习将共存很长一段时间。越来越多的研究机构及大型IT公司开发和运用量子机器学习,产生大量的机器学习开发框架,但仍缺乏一种开发框架来同时支持经典的机器学习和量子机器学习。
3.1 TensorFlow Quantum
TensorFlow Quantum(TFQ)是一个用于混合量子经典机器学习的 Python 框架。该框架允许量子算法研究人员和机器学习研究人员探索将量子计算与机器学习结合在一起,用于构建量子机器学习模型。机器学习研究人员可以在单个计算图中构造量子数据集、量子模型和经典控制参数作为张量。
TFQ的核心思想是将量子算法和机器学习程序都交织在TensorFlow编程模型中。谷歌将这种方法称为量子机器学习,并能够通过利用一些最新的量子计算框架(如谷歌Cirq)来实现它。TFQ的重点在于量子数据集和建立混合量子经典模型。它集成了许多量子算法和逻辑,并提供与现有 TensorFlow API 兼容的量子计算原函数,以及高性能量子电路模拟器。
TensorFlow Quantum (TFQ) 专为解决 NISQ 时代的量子机器学习问题而设计。它将量子计算基元(如构建量子电路)引入 TensorFlow 生态系统。使用 TensorFlow 构建的模型和运算使用这些基元来创建功能强大的量子经典混合系统。
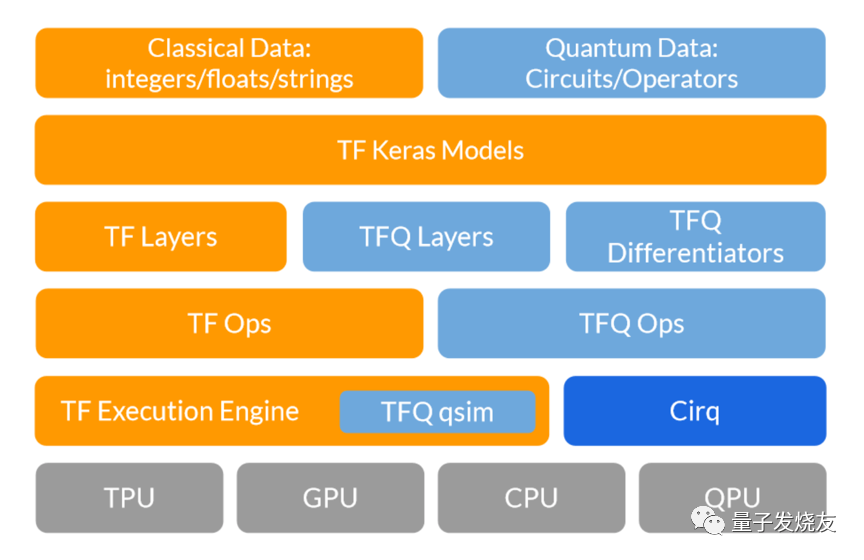
以上为 TensorFlow Quantum 的软件堆栈图,它展示了 TensorFlow 和 Cirq 之间的交互。
TensorFlow Quantum 基元
TensorFlow Quantum 实现了将 TensorFlow 与量子计算硬件集成所需的组件。为此,TFQ 引入了两个数据类型基元:
• 量子电路:表示 TensorFlow 中 Cirq 定义的量子电路 (cirq.Circuit)。创建大小不同的电路批次,类似于不同的实值数据点的批次。
• Pauli 和:表示 Cirq 中定义的 Pauli 算子张量积的线性组合 (cirq.PauliSum)。像电路一样,创建大小不同的算子批次。
Cirq框架
建立混合量子模型的第一步是能够利用量子操作。为了做到这一点,TensorFlow Quantum依靠Cirq,这是一个用于在近期设备上调用量子电路的开源框架。Cirq包含基本结构,如量子位、门、电路和测量操作符,这些都是指定量子计算所必需的。Cirq背后的想法是提供一个简单的编程模型,抽象出量子应用的基本构建块。当前版本包括以下主要构建模块:
(1)电路(Circuits):在Cirq中,Cirquit代表量子电路的最基本形式。一个Cirq电路被表示为一个力矩的集合,其中包含了在一些抽象的时间滑动期间可以在量子位上执行的操作。
(2)调度和设备(Schedules 、 Devices):调度是量子电路的另一种形式,它包含有关闸的时间和持续时间的更详细信息。从概念上讲,一个调度是由一组调度操作和运行调度的设备描述组成的。
(3)门(Gates):在Cirq中,门对量子位的集合进行抽象运算。
(4)模拟器(Simulators):Cirq包含一个Python模拟器,可用于运行电路和调度。模拟器架构可以跨多个线程和cpu进行扩展,这允许它运行相当复杂的电路。
TensorFlow Quantum如何运行
TFQ 允许研究人员在单个计算图中将量子数据集、量子模型和经典控制参数以张量的形式创建。量子测量的结果导致了经典概率事件,该结果通过 TensorFlow Ops 实现。使用标准 Keras 函数可以完成训练。
为了了解如何利用量子数据,有人可能考虑使用量子神经网络对量子态进行监督式分类。正如经典 ML 一样,量子 ML 的主要挑战也在于「噪声数据」的分类。为了构建和训练量子 ML 模型,研究人员可以执行以下操作:
从执行角度来看,TFQ遵循以下步骤来训练和构建QML模型。以判别式混合模型的训练为例,以下是流程图:
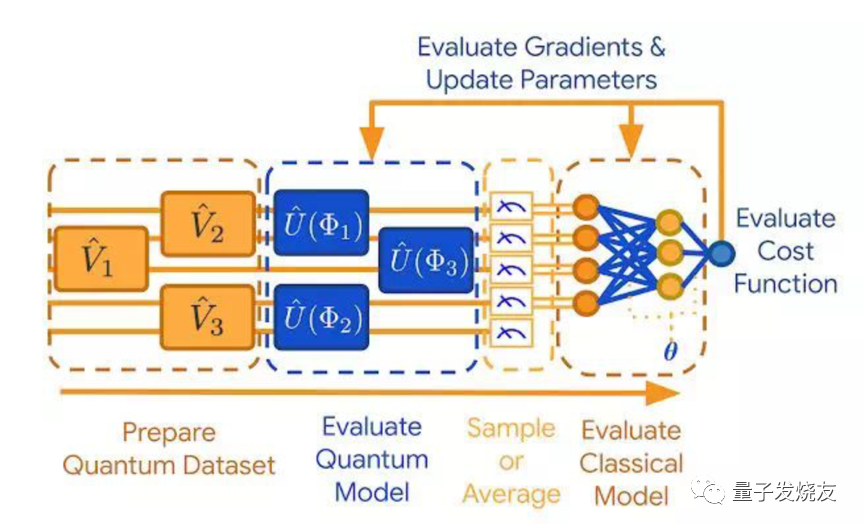
(1)制备量子数据集:量子数据作为张量加载,指定为在Cirq中编写的量子电路。张量由TensorFlow在量子计算机上执行,生成量子数据集。
(2)量子模型估计:在这一步中,研究人员可以使用Cirq创建一个量子神经网络的原型,他们稍后将该模型嵌入到TensorFlow计算图中。
(3)采样或求平均值:此步骤利用方法计算涉及步骤(1)和(2)的多个运行的平均值。
(4)经典模型估计:经典信息被提取出来后,可以进一步做经典后处理,以提取测量期望值之间的关联信息。这一过程可以通过经典深度神经网络实现。
(5)代价函数 (cost function) 估计:在得到经典后处理结果之后,研究人员对代价函数进行评估。需要注意的是,如果量子数据被标记,则评估过程基于模型执行分类任务的准确度;如果任务是无监督式的,则基于其他标准。
(6)梯度估计和参数更新:完成代价函数的估计之后,整个模型中的自由参数应当向代价降低的方向更新。
Tensorflow Quantum编译环境的搭建步骤:
(1) 在anaconda中创建新的环境
conda create --name tensorflowq python=3.7(2) 安装tensorflow和tensorflow-quantum包
conda activate tensorflowq
pip install tensorflow==2.2.0
pip install tensorflow-quantum (3) 将环境配置到jupyter notebook
pip install ipykernel
python -m ipykernel install --user --name tensorflowq (4) 在 jupyter notebook 中测试环境
import cirq
import tensorflow_quantum as tfq (5) 编译通过即配置成功
3.2 Qiskit
Qiskit提供了量子程序计算的必要的模块。Quantum circuit是Qiskit的基础模块。一个基础的Qiskit任务包括两部分:Build和Run。Build允许使用不同的量子电路,代表需要解决的问题。Run允许在不同的后端编译器运行量子电路。在任务运行后,数据依据设计的输出后,收集和处理数据。
Qiskit 机器学习引入了基本的计算构建块 - 例如量子内核和量子神经网络 - 用于不同的应用程序,包括分类和回归。一方面,这种设计非常易于使用,并且允许用户在没有深度量子计算知识的情况下快速制作第一个模型的原型。另一方面,Qiskit 机器学习非常灵活,用户可以轻松扩展它以支持前沿的量子机器学习研究。
Qiskit 是一个开源软件,用于在电路(circuits)、脉冲(pulses)和算法(algorithms)级别使用量子计算机。此外,在此核心模块之上还存在几个特定于领域的应用程序 API。
Qiskit 的核心目标是构建一个软件堆栈,让任何人都可以轻松使用量子计算机,无论他们的技能水平或感兴趣的领域如何;Qiskit 允许人们轻松设计实验和应用程序,并在真正的量子计算机和/或经典模拟器上运行它们。Qiskit 已经在世界各地被初学者、业余爱好者、教育工作者、研究人员和商业公司使用。
使用 Qiskit 时,用户工作流程名义上包括以下四个高级步骤:
• 构建:设计一个代表您正在考虑的问题的量子电路。
• 编译:为特定的量子服务编译电路,例如量子系统或经典模拟器。
• 运行:在指定的量子服务上运行编译电路。这些服务可以是基于云的或本地的。
• 分析:计算汇总统计数据并可视化实验结果。
Qiskit安装
使用 pip 命令安装 qiskit 包:
pip install qiskit以下是整个工作流程的步骤说明:
第 1 步:导入包
import numpy as np
from qiskit import QuantumCircuit
from qiskit.providers.aer import QasmSimulator
from qiskit.visualization import plot_histogram • QuantumCircuit: 可以认为是量子系统的指令。它拥有你所有的量子操作。
• QasmSimulator: 是 Aer 高性能电路模拟器。
• plot_histogram: 创建直方图。
第 2 步:初始化变量
circuit = QuantumCircuit(2, 2)第 3 步:添加门
circuit.h(0)
circuit.cx(0, 1)
circuit.measure([0,1], [0,1]) 第 4 步:可视化电路
circuit.draw()第 5 步:模拟实验
Qiskit Aer 是一个高性能的量子电路模拟器框架。它提供了几个后端 来实现不同的模拟目标。
import numpy as np
from qiskit import QuantumCircuit, transpile
from qiskit.providers.basicaer import QasmSimulatorPy
... 使用qasm_simulator模拟该电路
simulator = QasmSimulator()
compiled_circuit = transpile(circuit, simulator)
job = simulator.run(compiled_circuit, shots=1000)
result = job.result()
counts = result.get_counts(circuit)
print("\nTotal count for 00 and 11 are:",counts) 第 6 步:可视化结果
plot_histogram(counts)3.3 Paddle Quantum
Paddle Quantum(量桨)是一种开放源代码的机器学习工具包,旨在帮助数据科学家在量子计算应用程序中训练和开发AI。
Paddle Quantum支持三种量子应用程序-量子机器学习,量子化学模拟和量子组合优化-开发人员可以使用它从头开始或按照分步说明来构建量子模型。它包括解决组合优化问题和量子化学模拟等挑战的资源,以及支持量子电路模型和通用量子计算的复杂变量定义和矩阵乘法。它还具有QAOA的实现,该实现可通过经典模拟识别模型或直接在量子计算机上运行来转换为量子神经网络。
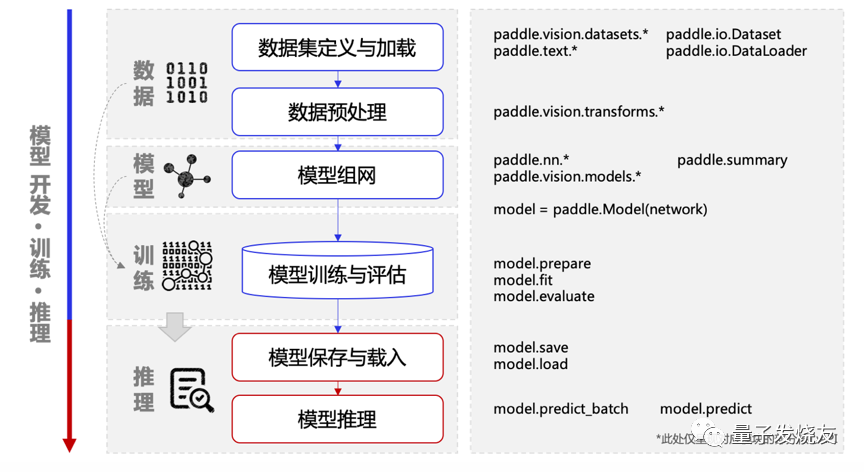
Paddle Quantum模型开发流程
量子生成对抗网络与经典的类似,只不过不再用于生成经典数据,而是生成量子态。在实践中,如果我们有一个量子态,其在观测后会坍缩为某一本征态,无法恢复到之前的量子态。
假设现在已有的目标量子态是一个混合态,它们属于同一个系综,其密度算符为ρ。然后我们需要有一个生成器 G,它的输入是一个噪声数据,我们用一个系综 ρz=∑ipi|zi⟩⟨zi| 来表示。因此我们每次取出一个随机噪声样本 |zi⟩,通过生成器后得到生成的量子态 |x⟩=G|zi⟩,我们期望生成的 |x⟩ 与目标量子态ρ相近。
值得注意的是,对于上文中提到的目标态的系综和噪声数据的系综,我们都认为有一个已有的物理设备可以生成出一个该系综下的量子态,而由于量子物理的相关性质,我们每次可以得到一个真正随机的量子态。但是在计算机程序中,我们仍然只能模拟这一过程。对于判别器,我们期望判别器可以判断我们输入的量子态是已有的目标态还是生成的量子态,这一过程可以由测量给出。
以量子生成对抗网络为例,如何在Paddle Quantum 上的实现,以下是相关步骤:
第1步:首先导入相关的包。
import numpy as np
import scipy
import warnings
import paddle
import paddle_quantum
from paddle_quantum.state import zero_state
from paddle_quantum.ansatz import Circuit
from paddle_quantum import Hamiltonian
from paddle_quantum.loss import ExpecVal
from paddle_quantum.qinfo import partial_trace
from tqdm import tqdm
warnings.filterwarnings("ignore") 第2步:定义网络模型 QGAN。
# 设置模拟方式为密度矩阵 paddle_quantum.set_backend('density_matrix')class QGAN(paddle_quantum.gate.Gate):
def init(self, target_state):
super().init()
self.target_state = target_state.clone()# 生成器的量子电路 self.generator = Circuit(3) self.generator.u3([0, 1]) self.generator.cnot([0, 1]) self.generator.u3(0) # 判别器的量子电路 self.discriminator = Circuit(3) self.discriminator.u3([0, 2]) self.discriminator.cnot([0, 2]) self.discriminator.u3(0) def disc_target_as_target(self): """ 判别器将目标态判断为目标态的概率 """ state = self.discriminator(self.target_state) expec_val_func = ExpecVal(Hamiltonian([[1.0, 'z2']])) # 判别器对目标态的判断结果 target_disc_output = expec_val_func(state) prob_as_target = (target_disc_output + 1) / 2 return prob_as_target def disc_gen_as_target(self): """ 判别器将生成态判断为目标态的概率 """ # 得到生成器生成的量子态 gen_state = self.generator() # 判别器电路 state = self.discriminator(gen_state) # 判别器对生成态的判断结果 expec_val_func = ExpecVal(Hamiltonian([[1.0, 'z2']])) gen_disc_output = expec_val_func(state) prob_as_target = (gen_disc_output + 1) / 2 return prob_as_target def forward(self, model_name): if model_name == 'gen': # 计算生成器的损失函数,loss值的区间为[-1, 0], # 0表示生成效果极差,为-1表示生成效果极好 loss = -1 * self.disc_gen_as_target() else: # 计算判别器的损失函数,loss值的区间为[-1, 1], # 为-1表示完美区分,为0表示无法区分,为1表示区分颠倒 loss = self.disc_gen_as_target() - self.disc_target_as_target() return loss def get_target_state(self): """ 得到目标态的密度矩阵表示 """ state = partial_trace(self.target_state, 2, 4, 2) return state.numpy() def get_generated_state(self): """ 得到生成态的密度矩阵表示 """ state = self.generator() state = partial_trace(state, 2, 4, 2) return state.numpy() </code></pre></div></div><p>第3步:使用 PaddlePaddle 来训练模型</p><div class="rno-markdown-code"><div class="rno-markdown-code-toolbar"><div class="rno-markdown-code-toolbar-info"><div class="rno-markdown-code-toolbar-item is-type"><span class="is-m-hidden">代码语言:</span>javascript</div></div><div class="rno-markdown-code-toolbar-opt"><div class="rno-markdown-code-toolbar-copy"><i class="icon-copy"></i><span class="is-m-hidden">复制</span></div></div></div><div class="developer-code-block"><pre class="prism-token token line-numbers language-javascript"><code class="language-javascript" style="margin-left:0"> # 学习率LR = 0.1
总的迭代次数
ITR = 25
每次迭代时,判别器的迭代次数
ITR1 = 40
每次迭代时,生成器的迭代次数
ITR2 = 50
制备目标量子态
target_state = zero_state(num_qubits=3)
target_state = paddle_quantum.gate.RY(0, param=0.9 * np.pi)(target_state)
target_state = paddle_quantum.gate.RZ(0, param=0.2 * np.pi)(target_state)
target_state.data = paddle.to_tensor(target_state.data.numpy())用来记录loss值的变化
loss_history = list()
paddle.seed(18)
gan_demo = QGAN(target_state)
optimizer = paddle.optimizer.SGD(learning_rate=LR, parameters=gan_demo.parameters())
pbar = tqdm(desc="Training: ", total=ITR * (ITR1 + ITR2), ncols=100, ascii=True)
for itr0 in range(ITR):# 记录判别器loss值的变化 loss_disc_history = list() # 训练判别器 for itr1 in range(ITR1): pbar.update(1) loss_disc = gan_demo('disc') loss_disc.backward() optimizer.minimize( loss_disc, parameters=gan_demo.discriminator.parameters(), no_grad_set=gan_demo.generator.parameters() ) gan_demo.clear_gradients() loss_disc_history.append(loss_disc.numpy()[0]) # 记录生成器loss值的变化 loss_gen_history = list() # 训练生成器 for itr2 in range(ITR2): pbar.update(1) loss_gen = gan_demo('gen') loss_gen.backward() optimizer.minimize( loss_gen, parameters=gan_demo.generator.parameters(), no_grad_set=gan_demo.discriminator.parameters() ) optimizer.clear_grad() loss_gen_history.append(loss_gen.numpy()[0]) loss_history.append((loss_disc_history, loss_gen_history))pbar.close()
得到目标量子态
target_state = gan_demo.get_target_state()
得到生成器最终生成的量子态
gen_state = gan_demo.get_generated_state()
print("the density matrix of the target state:")
print(target_state, "\n")
print("the density matrix of the generated state:")
print(gen_state, "\n")计算两个量子态之间的距离,
这里的距离定义为 tr[(target_state-gen_state)^2]
distance = np.trace(np.matmul(target_state-gen_state, target_state-gen_state)).real
计算两个量子态的保真度
fidelity = state_fidelity(target_state, gen_state)
fidelity = np.trace(
scipy.linalg.sqrtm(scipy.linalg.sqrtm(target_state) @ gen_state @ scipy.linalg.sqrtm(gen_state))
).real
print("the distance between these two quantum states is", distance, "\n")
print("the fidelity between these two quantum states is", fidelity)
参考链接:
【1】https://blog.csdn.net/sinat_35678407/article/details/84979501
【2】https://blog.csdn.net/dfsgwe1231/article/details/107267654
【3】https://cloud.tencent.com/developer/news/399745
【4】https://www.meipian.cn/3he0ofq7
【5】https://tensorflow.google.cn/quantum/concepts
【6】https://qiskit.org/documentation/machine-learning/
【7】https://qiskit.org/documentation/machine-learning/tutorials/index.html
【8】https://qml.baidu.com/tutorials/machine-learning/quantum-generative-adversarial-network.html