概述
业界AI应用中,GPU的使用逐渐增加,业界普遍存在以下两大问题:
- GPU算力显存利用低:直通 GPU 无法多业务共享资源;vGPU 实例资源配置固定不灵活、虚拟机实例调度成本高,非进程级调度。
- 显存/算力/故障资源隔离性差:不同客户、任务之间存在资源的抢占和干扰
腾讯云qGPU提供的GPU共享能力,支持在多个容器间共享 GPU 卡并提供容器间显存、算力强隔离能力,在使用中以更小的粒度进行调度。在保证业务稳定的前提下,为云上用户控制资源成本,提高运行效率提供帮助。
本实践基于腾讯云TKE实现,适用于各AI训练及推理应用场景。

文章分为两部分,第一部分为qGPU云原生化安装,提供全量qGPU和混用nvidia+qGPU两种不同的安装方式,以供实际场景选用。第二部分为qGPU能力验证,分别从调度、隔离和在离线混布三个方面,提供操作用例。
qGPU云原生环境安装
1. 版本安装
本次实践环境,采用腾讯云TKE,其中
- TKE 版本:v1.14+
- 节点型号:GN7.2XLARGE32 * 2
- 节点OS:TencentOS 3.1(tk4),CentOS 7/8,ubuntu 18/20
- GPU型号:T4 / V100 / A10 / A30 / A100
- GPU驱动版本:450或470
2. 模式A:全量部署qGPU节点
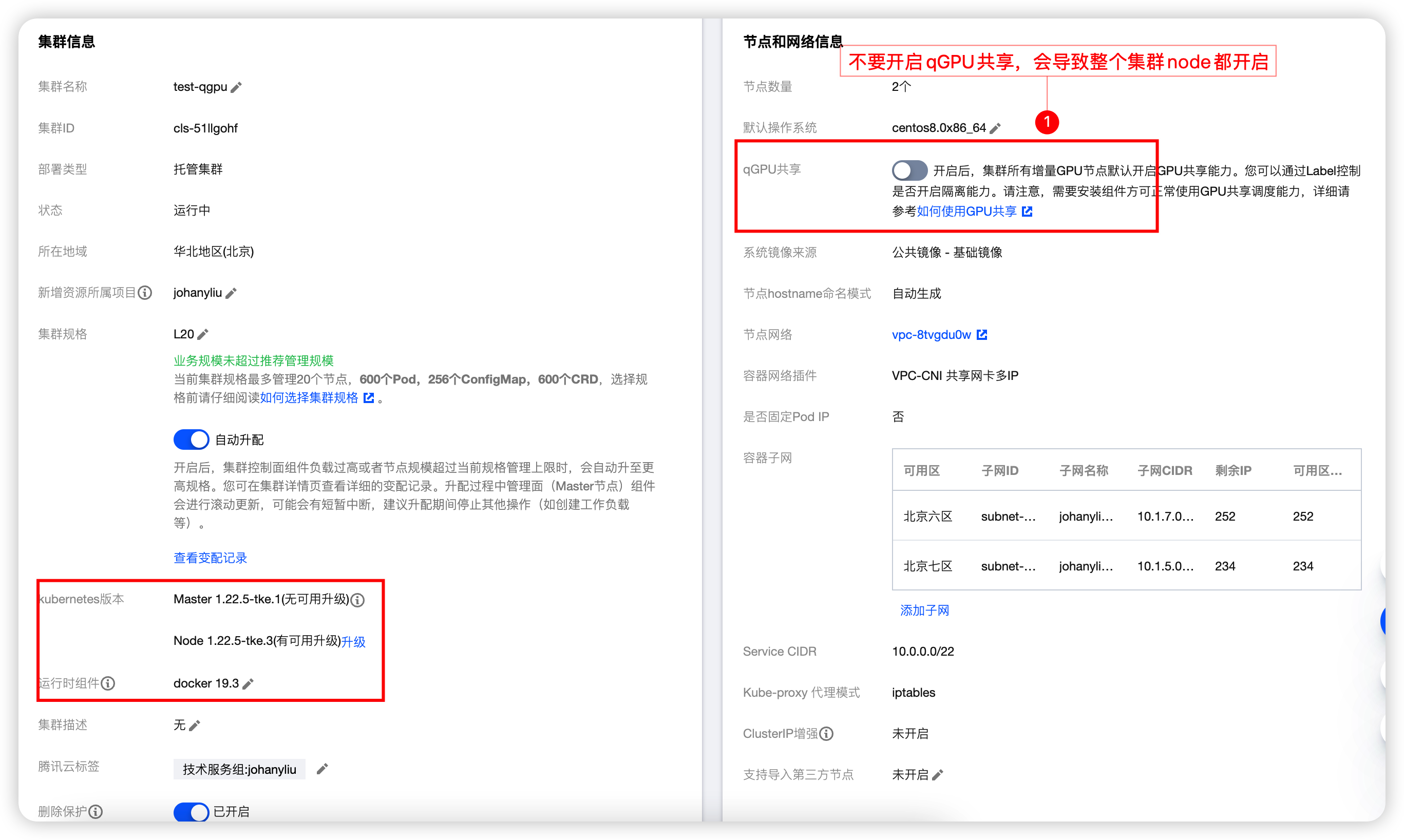
创建TKE集群,开启【qGPU共享】选项
- TKE集群创建,参考:https://cloud.tencent.com/document/product/457/32189
- 部署qGPU,参考:容器服务 使用 qGPU -TKE 标准集群指南-文档中心-腾讯云

创建节点,购买GPU机型
注:在验证还原时,根据用例按需配置节点,参见【测试用例】-【环境准备】
在TKE集群入口新建节点,购买节点过程中可以选择
- 公共镜像,tencentos 3.1(tk4),centos 7/8, ubuntu 18.04/20.04;其中安装GPU驱动版本(450/470)

- 市场镜像,选择标识为“混部”的机器,其OS里已经安装GPU驱动

- 查看每台机器可分配资源
kubectl describe node x.x.x.x- 若qGPU配置正确,可看到如下输出

3. 模式B:混合部署qGPU及Nvidia节点
创建TKE集群
不要开启【qGPU共享】,否则无法混合开通节点,(开启后,后面开启的任何节点,都是qGPU节点)
开通Nvidia方案节点
选择【公共镜像】,可选centos7.8操作系统,安装470 GPU驱动


节点打标签
- 给节点打上标签,方便调度任务时,通过nodeSelector选择不同节点类型
kubectl label node x.x.x.x gputype=nvidia- 或者在开通节点时,通过控制台操作

安装qGPU插件
通过TKE控制台,添加【qGPU组件】插件


开通qGPU方案节点
选择【市场镜像】 —— 选择标识为“混部”的机器,OS里已经安装GPU驱动,无需重复安装
注意:在这种混用模式下,qGPU只能用【市场镜像】,【公共镜像】都是Nvidia方案节点

给节点打上标签,方便调度任务时,通过nodeSelector进行选择
kubectl label node x.x.x.x gputype=qgpu查看nvidia和qGPU机器可分配资源
kubectl describe node x.x.x.x

qGPU能力实践
1. 实践目标
操作过程对qGPU的以下四个能力,进行方案实践
- 虚拟化:单节点同时运行多个任务
- 隔离性:显存和算力是否符合设置预期
- 抢占性:是否能抢占,抢占的同时能否对配置资源进行保底
- 在离线混布:高、低优先级任务切换
2. 前置操作
前置操作
为避免数据抖动,操作时可先锁定GPU频率,根据显卡型号在GPU节点执行如下命令:
显卡型号 | 操作命令 |
|---|---|
T4 | nvidia-smi --lock-gpu-clocks=1590 |
V100 | nvidia-smi --lock-gpu-clocks=1530 |
A100 | nvidia-smi --lock-gpu-clocks=1410 |
A10 | nvidia-smi --lock-gpu-clocks=1695 |
准备镜像
实践基于Tensorflow CNN Benchmark进行模拟仿真,程序根据卷积神经网络的多个图像分类模型,进行图像数据的分类训练。使用如下方式创建镜像,并推送镜像仓库TCR
mkdir -p /tmp/qgpu cd /tmp/qgpugit clone https://github.com/tensorflow/benchmarks.git
cat <<'EOF' > start.sh
#! /bin/bash
python3 /benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --forward_only=True --model=resnet50 --num_batches="$@" --allow_growth --batch_size=16
EOFchmod +x start.sh
cat <<EOF > Dockerfile
FROM nvcr.io/nvidia/tensorflow:21.08-tf1-py3
ADD benchmarks /benchmarks
ADD start.sh /start.sh
EOF
docker build -t qgpu-tf-test:21.08-tf1-py3 .
3. 场景1 - Nvidia节点调度能力实践
步骤1:
- 部署TKE集群,包含一个单GPU卡的Nvidia节点
- 预期结果:只有一个Job可以获取到GPU资源,正常启动;另外一个Job无法获取到GPU资源,无法启动
步骤2:
- 查看节点 GPU 算力 / 显存
kubectl describe node <node-name>- 预期结果:在Allocatable:部分,可以看到nvidia-gpu资源,类似如下信息:
Allocatable: nvidia.com/gpu: 1步骤3:
- 创建两个GPU负载(部署在Nvidia节点上),查看Pod运行状态
cat <<EOF | kubectl create -f -
apiVersion: batch/v1
kind: Job
metadata:
name: scene1-job1
namespace: qgpu-test
spec:
template:
spec:
nodeSelector:
gputype: nvidia
restartPolicy: Never
containers:
- name: container1
image: ccr.ccs.tencentyun.com/qcbm/qgpu-tf-test:21.08-tf1-py3
command: [ "/start.sh", "50000" ]
resources:
limits:
nvidia.com/gpu: 1
EOF
cat <<EOF | kubectl create -f -
apiVersion: batch/v1
kind: Job
metadata:
name: scene1-job2
namespace: qgpu-test
spec:
template:
spec:
nodeSelector:
gputype: nvidia
restartPolicy: Never
containers:
- name: container1
image: ccr.ccs.tencentyun.com/qcbm/qgpu-tf-test:21.08-tf1-py3
command: [ "/start.sh", "50000" ]
resources:
limits:
nvidia.com/gpu: 1- 预期结果:kubectl get pod仅可以查询到一个pod,scene1-job1或scene1-job2,取决于调度顺序
4. 场景2 - qGPU节点调度能力实践
步骤1:
- 部署TKE集群,部署2个qGPU节点:其中一个节点包含1张卡,一个节点包含2张卡
- 预期结果:两个Job可以同时启动,在保证各5G显存隔离的前提下,抢占剩余显卡资源
步骤2:
- 查看节点 GPU 算力 / 显存
kubectl describe node <node-name>- 预期结果:在Allocatable:部分,可以看到qgpu-core及qgpu-memory资源,类似如下信息:
Allocatable: tke.cloud.tencent.com/qgpu-core: 100
tke.cloud.tencent.com/qgpu-memory: 14步骤3:
- 创建GPU负载(部署在qGPU节点上),查看Pod运行状态
cat <<EOF | kubectl create -f -
apiVersion: batch/v1
kind: Job
metadata:
name: scene2-job1
namespace: qgpu-test
spec:
template:
spec:
nodeSelector:
gputype: qgpu
restartPolicy: Never
containers:
- name: container1
image: ccr.ccs.tencentyun.com/qcbm/qgpu-tf-test:21.08-tf1-py3
command: [ "/start.sh", "50000" ]
resources:
limits:
tke.cloud.tencent.com/qgpu-memory: "5"
tke.cloud.tencent.com/qgpu-core: "40"
EOF- 预期结果:在pod里执行如下命令,显存显示5120MiB
kubectl exec -it scene2-job1 nvidia-smi步骤4:
- 删除现有GPU负载,创建两个GPU负载,通过node selector选择调度到指定Node上(仅1个卡的qGPU节点),查看多容器共享 GPU能力。
cat <<EOF | kubectl create -f -
apiVersion: batch/v1
kind: Job
metadata:
name: scene2-job1
namespace: qgpu-test
spec:
template:
spec:
nodeSelector:
gputype: qgpu
restartPolicy: Never
containers:
- name: container1
image: ccr.ccs.tencentyun.com/qcbm/qgpu-tf-test:21.08-tf1-py3
command: [ "/start.sh", "50000" ]
resources:
limits:
tke.cloud.tencent.com/qgpu-memory: "5"
tke.cloud.tencent.com/qgpu-core: "40"
EOF
cat <<EOF | kubectl create -f -
apiVersion: batch/v1
kind: Job
metadata:
name: scene2-job2
namespace: qgpu-test
spec:
template:
spec:
nodeSelector:
gputype: qgpu
restartPolicy: Never
containers:
- name: container1
image: ccr.ccs.tencentyun.com/qcbm/qgpu-tf-test:21.08-tf1-py3
command: [ "/start.sh", "50000" ]
resources:
limits:
tke.cloud.tencent.com/qgpu-memory: "5"
tke.cloud.tencent.com/qgpu-core: "30"
EOF- 预期结果:
- 两个pod运行成功 kubectl get po -o wide,显示scene2-job1和scene2-job2
- 在两个pod执行如下命令,显存显示不大于5G
kubectl exec -it scene2-job1 nvidia-smi
kubectl exec -it scene2-job2 nvidia-smi
步骤5:
- 在两个Pod分别执行如下命令,查看
kubectl logs scene2-job1 --tail=20
kubectl logs scene2-job2 --tail=20- 预期结果:
YAML中Pod1与Pod2设置不同算力,因默认抢占策略,两个Pod会抢占剩余资源,因运行负载都很重,导致运行结果基本相同。其中Pod1训练日志约为202 images/sec,Pod2训练日志约为198 images/sec。

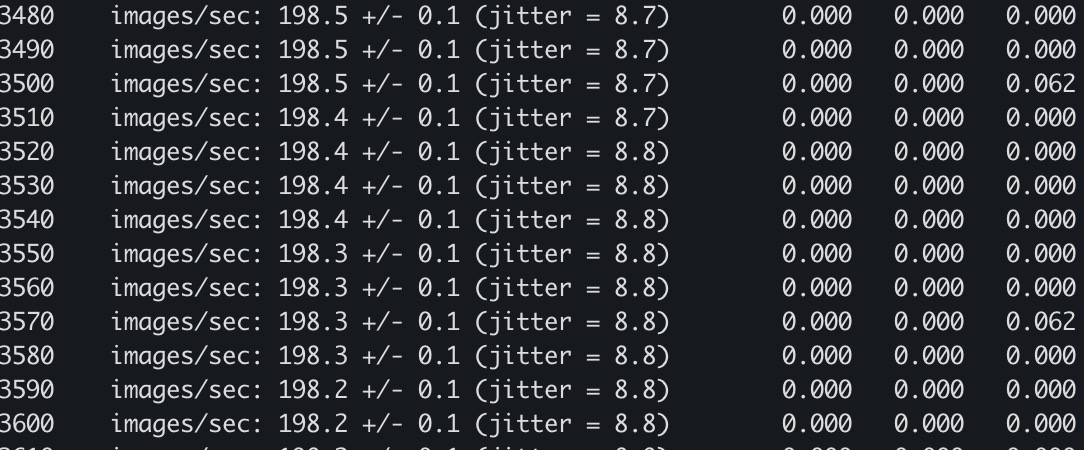
通过底层CVM节点监控,也可以查看到GPU使用率为100%

步骤6:
- 删除现有GPU负载,创建两个GPU负载,通过node selector,选择调度到qGPU的Node上。查看支持 binpack / spread 策略调度能力。
cat <<EOF | kubectl create -f -
apiVersion: batch/v1
kind: Job
metadata:
name: scene2-job1
namespace: qgpu-test
spec:
template:
spec:
nodeSelector:
gputype: qgpu
restartPolicy: Never
containers:
- name: container1
image: ccr.ccs.tencentyun.com/qcbm/qgpu-tf-test:21.08-tf1-py3
command: [ "/start.sh", "50000" ]
resources:
limits:
tke.cloud.tencent.com/qgpu-memory: "5"
tke.cloud.tencent.com/qgpu-core: "40"
EOF
cat <<EOF | kubectl create -f -
apiVersion: batch/v1
kind: Job
metadata:
name: scene2-job2
namespace: qgpu-test
spec:
template:
spec:
nodeSelector:
gputype: qgpu
restartPolicy: Never
containers:
- name: container1
image: ccr.ccs.tencentyun.com/qcbm/qgpu-tf-test:21.08-tf1-py3
command: [ "/start.sh", "50000" ]
resources:
limits:
tke.cloud.tencent.com/qgpu-memory: "5"
tke.cloud.tencent.com/qgpu-core: "30"
EOF等待两个Pod进入Running状态后,执行如下命令,并记录输出信息
kubectl exec -it scene2-job1 nvidia-smi
kubectl exec -it scene2-job2 nvidia-smi删除所有GPU负载,执行如下命令,查找binpack,替换为spread并保存退出
kubectl edit deploy -n kube-system qgpu-scheduler等待旧的qgpu-scheduler Pod退出,新的qgpu-scheduler Pod进入Running状态。再次提交GPU负载,并执行nvidia-smi命令,再次记录输出信息
- 预期结果:第一次在两个Pod中执行nvidia-smi时,可以看到输出的类似00000000:00:09.0的显卡bus信息相同,说明在默认binpack调度策略下,两个Pod被调度到同一个显卡上;在修改为spread后,可以看到bus信息不同,说明两个Pod在spread策略下,被调度到同一节点的不同显卡上
步骤7:
- 删除现有GPU负载,创建一个GPU负载,指定qGPU-core为100。查看GPU 整卡调度策略。
cat <<EOF | kubectl create -f -
apiVersion: batch/v1
kind: Job
metadata:
name: scene2-job1
namespace: qgpu-test
spec:
template:
spec:
nodeSelector:
gputype: qgpu
restartPolicy: Never
containers:
- name: container1
image: ccr.ccs.tencentyun.com/qcbm/qgpu-tf-test:21.08-tf1-py3
command: [ "/start.sh", "50000" ]
resources:
limits:
tke.cloud.tencent.com/qgpu-core: "100" #显卡比例
EOF- 预期结果:任务显存及算力,为单GPU卡的全部资源
5. 场景3 - qGPU节点隔离能力实践
步骤1:
- 部署包含一个单GPU卡的qGPU节点
- 预期结果:两个Job可以同时启动,在保证各5G显存隔离的前提下,按照配置比例严格隔离运行,总体GPU使用在90%左右
步骤2:
- 登录GPU节点,然后运行如下命令
cat /proc/qgpu/0/policy- 预期结果:显示默认隔离策略 best-effort
步骤3:
- 执行如下命令,设置该GPU节点的隔离策略为fixed-share
kubectl label node <node-name> --overwrite tke.cloud.tencent.com/qgpu-schedule-policy=fixed-share再次执行以下命令
cat /proc/qgpu/0/policy- 预期结果:显示默认隔离策略 fixed-share
步骤4:
- 创建两个GPU负载
cat <<EOF | kubectl create -f -
apiVersion: batch/v1
kind: Job
metadata:
name: scene3-job1
namespace: qgpu-test
spec:
template:
spec:
nodeSelector:
gputype: qgpu
restartPolicy: Never
containers:
- name: container1
image: ccr.ccs.tencentyun.com/qcbm/qgpu-tf-test:21.08-tf1-py3
command: [ "/start.sh", "50000" ]
resources:
limits:
tke.cloud.tencent.com/qgpu-memory: "6"
tke.cloud.tencent.com/qgpu-core: "60"
EOF
cat <<EOF | kubectl create -f -
apiVersion: batch/v1
kind: Job
metadata:
name: scene3-job2
namespace: qgpu-test
spec:
template:
spec:
nodeSelector:
gputype: qgpu
restartPolicy: Never
containers:
- name: container1
image: ccr.ccs.tencentyun.com/qcbm/qgpu-tf-test:21.08-tf1-py3
command: [ "/start.sh", "50000" ]
resources:
limits:
tke.cloud.tencent.com/qgpu-memory: "3"
tke.cloud.tencent.com/qgpu-core: "30"
EOF- 预期结果:稳定一段时间后,可以在云监控处看到,两个进程总的GPU-Util不超过90%

步骤5:
- 在两个Pod分别执行如下命令,查看显存资源使用量
kubectl exec -it scene3-job1 nvidia-smi
kubectl exec -it scene3-job2 nvidia-smi- 预期结果:可以看到显存一个不超过6G,一个不超过3G
步骤6:
- 在两个Pod分别执行如下命令,查看
kubectl logs scene2-job1 --tail=20
kubectl logs scene2-job2 --tail=20- 预期结果:YAML中设置Pod1为Pod2的两倍算力及显存,运行结果显示,Pod1约为274 images/sec,Pod2约为129 images/sec,Pod1的吞吐量大致为Pod2的吞吐量2倍,并且保持稳定运行。


6. 场景4 - qGPU在离线混布能力实践
在离线环境安装
注意:开启在离线混部后,前面的best和fix隔离策略,都会失效。在离线混部为节点维度。
- 打开在离线混部
kubectl label node xxxx mixed-qgpu-enable=enable- 重启qgpu-manager
kubectl delete pod qgpu-manager-xxx -n kube-system - 重启qgpu-scheduler
kubectl delete pod qgpu-scheduler-xxx -n kube-system - 查看node上的allocatable资源
kubectl describe node xxxx如下显示即为成功

在离线任务配置方法
- 创建低优任务 Pod:通过设置 Pod annotation tke.cloud.tencent.com/app-class: offline 标识一个 Pod 为低优任务。低优 Pod 可以同时设置低优算力与显存:
- 低优算力:tke.cloud.tencent.com/qgpu-core-greedy,单位为百分比
- 显存:tke.cloud.tencent.com/qgpu-memory,单位为 GB
apiVersion: v1
kind: Pod
annotations:
tke.cloud.tencent.com/app-class: offline
spec:
containers:
- name: offline-container
resources:
requests:
tke.cloud.tencent.com/qgpu-core-greedy: xx
tke.cloud.tencent.com/qgpu-memory: xx- 创建高优任务 Pod:通过设置 Pod annotation tke.cloud.tencent.com/app-class: online 标识一个 Pod 为高优任务。在线 Pod 只支持设置显存,算力占用为100%,高优 Pod 不会抢占低优 Pod 的显存资源
apiVersion: v1
kind: Pod
annotations:
tke.cloud.tencent.com/app-class: online
spec:
containers:
- name: online-container
resources:
requests:
tke.cloud.tencent.com/qgpu-memory: xx步骤1:
- 部署k8s集群,包含一个单GPU卡的节点
步骤2:
- 创建离线任务
cat <<EOF | kubectl create -f -
apiVersion: batch/v1
kind: Job
metadata:
name: scene4-job1
namespace: qgpu-test
spec:
template:
metadata:
annotations:
tke.cloud.tencent.com/app-class: offline #离线
spec:
nodeSelector:
gputype: qgpu
restartPolicy: Never
containers:
- name: container1
image: ccr.ccs.tencentyun.com/qcbm/qgpu-tf-test:21.08-tf1-py3
command: [ "/start.sh", "50000" ]
resources:
limits:
tke.cloud.tencent.com/qgpu-memory: "7" #显存大小
tke.cloud.tencent.com/qgpu-core-greedy: "60" #低优资源
EOF- 创建在线任务
cat <<EOF | kubectl create -f -
apiVersion: batch/v1
kind: Job
metadata:
name: scene4-job2
namespace: qgpu-test
spec:
template:
metadata:
annotations:
tke.cloud.tencent.com/app-class: online #在线
spec:
nodeSelector:
gputype: qgpu
restartPolicy: Never
containers:
- name: container1
image: ccr.ccs.tencentyun.com/qcbm/qgpu-tf-test:21.08-tf1-py3
command: [ "bash", "-c", "while true; do /start.sh 2000 && sleep 90;done" ]
resources:
limits:
tke.cloud.tencent.com/qgpu-memory: "7" #显存大小
EOF- 预期结果:在线任务执行期间,离线任务暂停执行;在线任务暂停期间,离线任务恢复执行。显存部分以隔离方式分配,不发生抢占
步骤3:
- 通过以下命令,查看日志,观察图片处理训练吞吐:
kubectl logs -f scene4-job1
kubectl logs -f scene4-job2- 预期结果:在线任务运行后,离线任务被暂停,日志暂停打印。在线任务结束后,离线任务继续前面的运行状态,并输出日志;观察在线POD的任务,性能数据接近整卡

步骤4:
- 执行以下命令:
kubectl exec -it scene4-job1 nvidia-smi
kubectl exec -it scene4-job2 nvidia-smi- 预期结果:高优和低优之间,显存是显式静态分割的,不会发生抢占,通过Nividia-SMI命令,可以观察到单Pod的显存资源为7G,和设置中一致
