【GTC2020】Jetson Xavier NX开发套件:边缘计算的下一个飞跃
本次视频将深入探讨新的NVIDIA Jetson Xavier NX开发套件:世界上最小的嵌入式AI超级计算机,性能超过21 TeraOPS。
【GTC2020】Jetson Xavier NX开发套件:边缘计算的下一个飞跃
本次视频将深入探讨新的NVIDIA Jetson Xavier NX开发套件:世界上最小的嵌入式AI超级计算机,性能超过21 TeraOPS。
算力模式创新:亚马逊AWS比作Intel,算力界呼唤台积电和NVIDIA
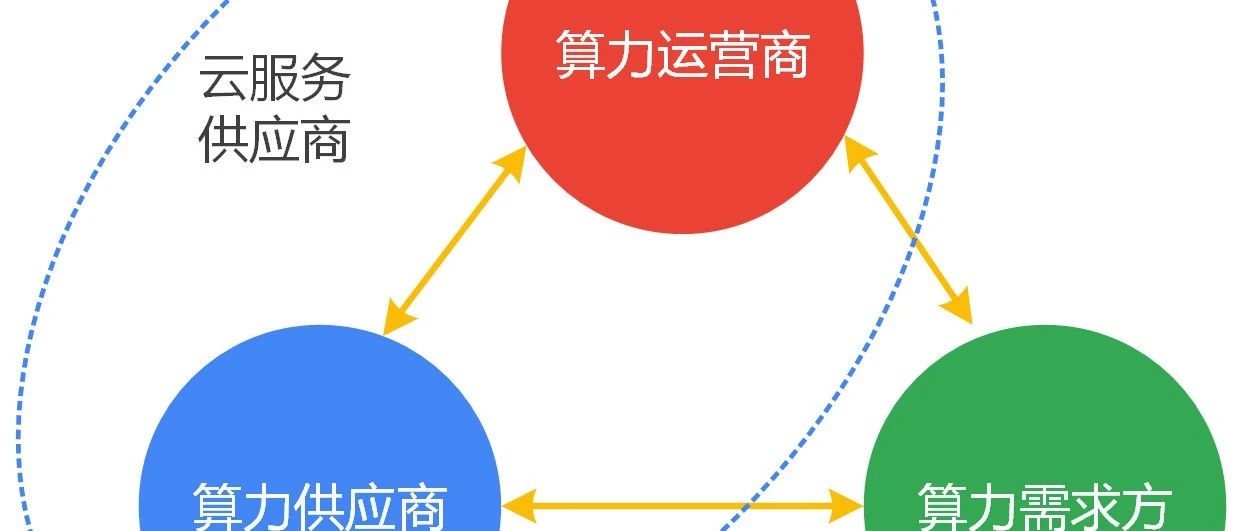
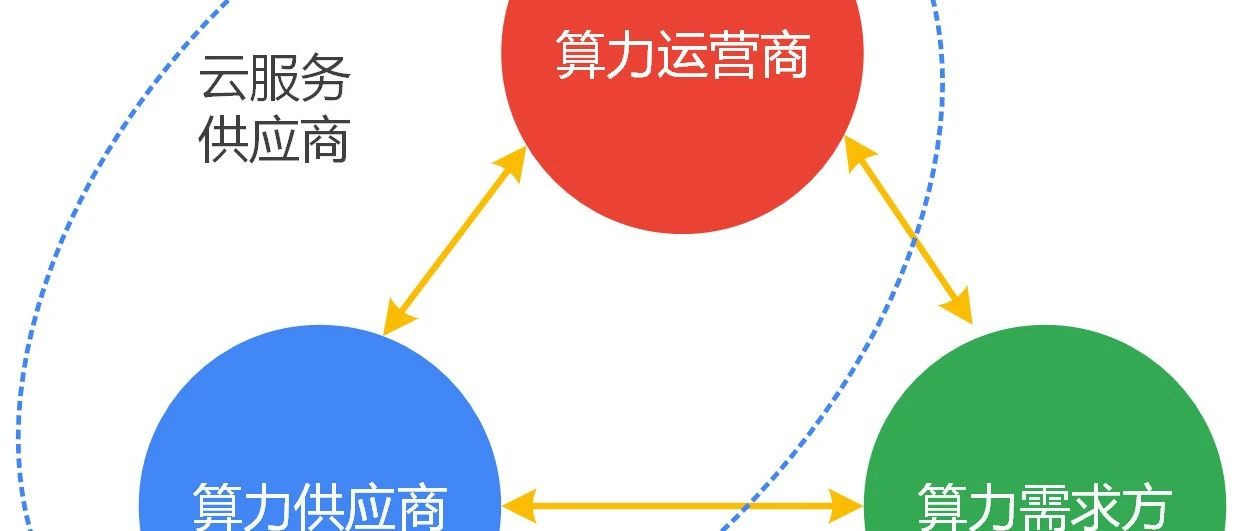
半个世纪以前,芯片行业只有IDM模式,芯片公司自己设计、制造并封装芯片,典型的公司如Intel、未拆分前的AMD、TI等公司。
算力模式创新:亚马逊AWS比作Intel,算力界呼唤台积电和NVIDIA
半个世纪以前,芯片行业只有IDM模式,芯片公司自己设计、制造并封装芯片,典型的公司如Intel、未拆分前的AMD、TI等公司。
模拟整个地球:英伟达Earth-2超级计算机即将上线
「如何让我们的未来在今天就变成现实呢?答案就是模拟,」英伟达创始人、CEO 黄仁勋说道。

NVIDIA Eos 揭晓:全球十大超级计算机排名第9
NVIDIA 的突破性 DGX AI 超级计算机是全球企业的蓝图,旨在为 AI 创新的下一个前沿提供动力

埃尼公司采用Dell系统,发布全新HPC5超级计算机
新的超级计算机支持以前的系统(HPC4),它的计算能力从18增加到52千万亿次/秒,相当于每秒5200亿次数学运算,使埃尼的超级计算生态系统达到70千万亿次/秒的峰值。事实上,HPC5是世界上工业领域最强大的超级计算机基础设施,并使该公司在其数字化进程中达到另一个里程碑。
用NVIDIA 嵌入式Jetson 平台做个AI“云监工” (续)
前两天我们用Jetson NANO做个AI“云监工” ,一些朋友留言建议我们找原始视频。于是我们到Youku上找火神山的施工视频,发现还真有一些,所以我们今天再做一个测试。

如何快速打造具备自有知识产权的边缘计算利器?
AI时代的来临伴随着智慧城市的诞生,过去梦想中的科技生活型态逐渐在现实环境中发生。云计算下的边缘计算成为越来越重要的支撑力量,是通过技术手段来真正实现高传输、低延阻的核心驱动因子。

重磅发布!一图看懂天翼云紫金DPU
2022天翼
数字科技生态大会
重磅发布天翼云紫金DPU
📷
视频版
年终岁末
国产DPU进入爆发期
华山论剑 谁是DPU大英雄
别抢,另起一行,人人都是第一名!
📷
一花独放不是春
万紫千红春满园
中国芯雄起,天翼云加油!
📷
全球DPU/智能网卡生态图:
一、投资篇:
FPGA智能网卡市场分析报告
分析师靠的住,智能网卡能上树!
第一代智能网卡投资人已经被割韭菜
分析师有多大胆,智能网卡市场有多大产!
二、白皮书篇:
中国移动DPU技术白皮书(2022年)
全球智能网卡大会资料下载(2022年)
运

GTC 2024 | 使用NVIDIA GPU和VMAF-CUDA计算视频质量
传统的视频质量评价指标包括 PSNR 和 SSIM 等。而 VMAF 由 Netflix于 2017 年提出,是一种全参考的视频质量评价指标,分数范围由 0 到 100,越高代表质量越好。VMAF 试图准确地捕捉人类的感知,将人类视觉建模与不断发展的机器学习技术相结合,使其能够适应新的内容,在与人类视觉感知保持一致方面表现出色。VMAF 现在已经被 Netflix,Snap,V-Nova等公司采用。

GPU 超算完整体验 —— AMD FirePro 通用计算特性
使用显卡或者说 GPU 执行通用计算早就已经不是什么新鲜的事情,这得益于整个行业近年来不遗余力的推动,例如 AMD、Apple、NVIDIA、Intel 等都把 GPU 执行非图形处理作为新业务的重中之重来推广。
虽然说 GPU 通用计算不再是新鲜事,但是对于许多人而言,可能也就仅限于听过而已,其中的一些关键信息缺并不十分了解,这并不奇怪,因为“听过”的人当中其实大部分都是游戏玩家,就算对这方面有更多认识(例如懂得写 OpenCL 代码)的人来说,也未必能对厂商为什么会推出专门的超算卡有充分
GPU机密计算——以NVIDIA H100为例
机密计算通过在基于硬件的经验证的受信任执行环境中执行计算来保护正在使用的数据。这些安全且隔离的环境可以防止未经授权访问或修改使用中的应用程序和数据,从而提高管理敏感数据和受监管数据的组织的安全级别。为了将GPU也纳入可信执行环境,保护GPU上的数据的机密性和完整性,英伟达在H100显卡首次集成了机密计算能力。

利用基于NVIDIA CUDA的点云库(PCL)加速激光雷达点云技术
在这篇文章将介绍如何使用CUDA-PCL处理点云来获得最佳性能,由于PCL无法充分利用Jetson上的CUDA,NVIDIA开发了一些具有与PCL相同功能的基于CUDA的库。代码地址:https://github.com/NVIDIA-AI-IOT/cuPCL.git(只有动态库和头文件,作者说源码将在未来开源)。

详细介绍NVIDIA边缘计算解决方案
首先,什么是边缘计算?这是一个广泛的概念,但简单来说,它是在数据源头或靠近数据源头处理数据的方式。它有许多不同的好处或理念。大多数人寻求每秒处理毫秒级的数据,因为他们想要低延迟,同时也想要能够节省带宽。他们不需要将所有原始数据发送到顶层,每个人可能都熟悉云计算,因为这是我们每天工作的术语,云数据中心是全球部署的,平均响应时间,虽然到今天可以做到毫秒级,但绝对不是实时的。有时您实际上需要更多的处理时间,可以是分钟或有时候小时,最后一个是,您通常需要更大的带宽来进行处理,因为所有数据都需要被传输到数据中心的某个地方进行处理和发送回来。因此,这需要大量的资源。所以说。边缘计算具有本地处理、实现低延迟和减少带宽的好处。

qGPU云原生最佳实践
腾讯云qGPU提供的GPU共享能力,支持在多个容器间共享 GPU 卡并提供容器间显存、算力强隔离能力,在使用中以更小的粒度进行调度。在保证业务稳定的前提下,为云上用户控制资源成本,提高运行效率提供帮助。

Cupy:利用 NVIDIA GPU 来加速计算
CuPy 是一个开源的 Python 库,它的设计初衷是为了使得在 GPU 上的计算变得简单快捷。
它提供了与 NumPy 非常相似的 API,这意味着如果你已经熟悉 NumPy,那么使用 CuPy 将会非常容易。
CuPy 的亮点在于它能够利用 NVIDIA GPU 来加速计算,这在处理大规模数据时尤其有用。
https://github.com/cupy/cupy
Cupy:利用 NVIDIA GPU 来加速计算
CuPy 是一个开源的 Python 库,它的设计初衷是为了使得在 GPU 上的计算变得简单快捷。
它提供了与 NumPy 非常相似的 API,这意味着如果你已经熟悉 NumPy,那么使用 CuPy 将会非常容易。
CuPy 的亮点在于它能够利用 NVIDIA GPU 来加速计算,这在处理大规模数据时尤其有用。
https://github.com/cupy/cupy
2010年之前电脑ubuntu安装nvidia驱动黑屏处理
这个链接指向的是Launchpad上的一个个人仓库,名为nvidia-legacy,由用户kelebek333维护。Launchpad是Ubuntu社区的一个网站,它提供了托管项目、构建软件包、跟踪bug等功能。

短文本识别说明文档
主要目标是针对临床试验筛选标准进行分类,所有文本数据均来自于真实临床试验,短文本数据来源于中文临床试验注册网站(http://chictr.org.cn/)的临床试验公示信息中的筛选标准模块。数据公开透明,官网也提供下载链接。
