任务目标
主要目标是针对临床试验筛选标准进行分类,所有文本数据均来自于真实临床试验,短文本数据来源于中文临床试验注册网站(http://chictr.org.cn/)的临床试验公示信息中的筛选标准模块。数据公开透明,官网也提供下载链接。
任务说明
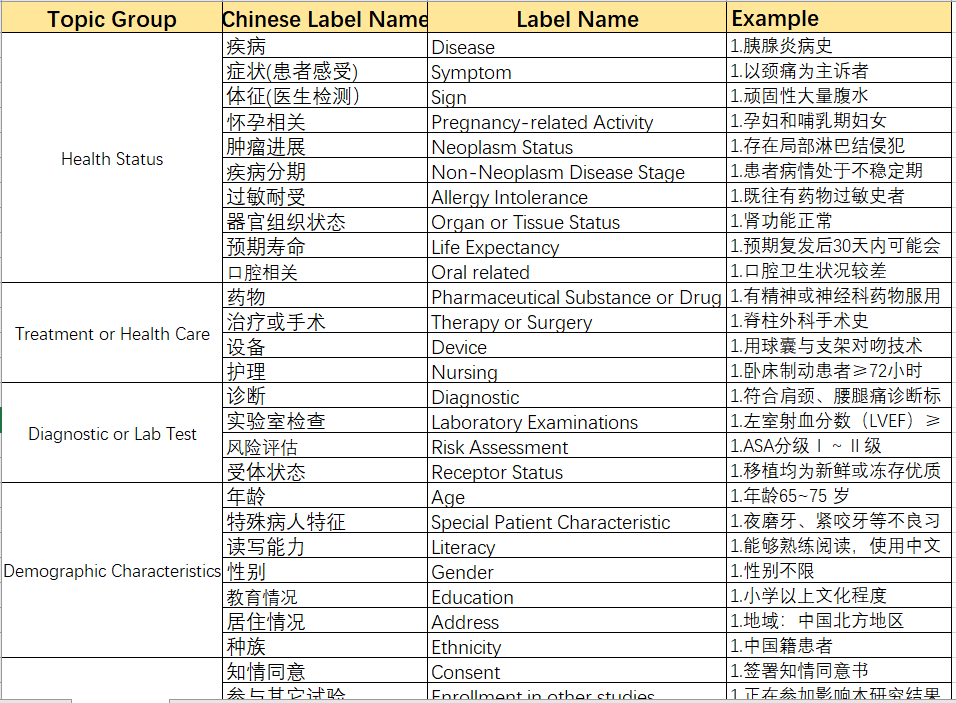
短文本分类标注以及示例如下:
评价指标
本任务的评价指标使用宏观F1值(Macro-F1,或称Average-F1)。最终排名以Macro-F1值为基准。假设我们有n个类别,C1, … …, Ci, … …, Cn。 准确率Pi = 正确预测为类别Ci的样本个数 / 预测为Ci类的样本个数。 召回率Ri = 正确预测为类别Ci的样本个数 / 真实的Ci类的样本个数。
模型介绍
试验过程
运行设备
NVIDIA-SMI 430.26 Driver Version: 430.26 CUDA Version: 10.2 GPU: Tesla P100 * 2 显存:36GB CPU:7核 Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz 内存:120GB 硬盘:2T SSD
运行环境
Python 3.8.10 pip install ark-nlp==0.0.2 pip install scikit-learn pip install pandas pip install elasticsearch pip install openpyxl pip install python-Levenshtein
试验超参数
代码语言:javascript
复制
argg = {
'model_dir': 'data/model_data',
'model_type': 'bert',
'model_name': 'chinese-bert-wwm-ext',
'task_name': 'ctc',
'output_dir': './data/output/ctc/',
'do_train': True,
'do_predict': False,
'result_output_dir': './data/result',
'max_length': 128,
'train_batch_size': 16,
'eval_batch_size': 16,
'learning_rate': 3e-05,
'weight_decay': 0.01,
'adam_epsilon': 1e-08,
'max_grad_norm': 0.0,
'epochs': 5,
'warmup_proportion': 0.1,
'earlystop_patience': 5,
'logging_steps': 200,
'save_steps': 10,
'seed': 2021,
'device': torch.device("cuda"
if torch.cuda.is_available()
else "cpu")
}结果介绍
epoch:5
代码语言:javascript
复制
## 结果介绍
precision: 0.8520105137135594 - recall: 0.8032168382072119 - f1 score: 0.817622871761937