在AI的世界里,"token"就像是把我们说的话或写的文字拆分成的小块块,每块可以是一个词、一个短语、一个标点,甚至一个字母。不同的AI系统可能有不同的拆分方法。
阿里云的灵积平台有个工具,叫做Token计算器。这个工具就是用来帮我们估算一段文字里有多少个这样的小块块。这个工具是免费的,用来帮助我们大概知道要花多少钱,但它只是个估计,可能不是完全准确的。
比如,在灵积平台的一些AI模型里,像通义千问、Llama2这样的,它们算钱是根据我们输入和输出的小块块数量来的。有时候,一个字符可能就代表一个小块块,有时候可能几个字符才代表一个。比如说,在通义千问的一个模型里:
- "苹果"这个词,算作1个小块块;
- "my friends"这个短语,算作3个小块块;
- "周"这个字,虽然只有一个字,但也被算作3个小块块。
我们可以让AI写一个程序来调用这个token计算API来自动计算文档的token数量。
在deepseek中输入提示词:
你是一个Python编程专家,现在要完成一个编写基于qwen-turbo模型Token计算API和dashscope库的程序脚本,具体步骤如下:
打开文件夹:F:\AI自媒体内容\待翻译;
逐个读取里面的TXT文档文件名,设为变量{txtfilename};
将每个TXT文档的内容作为输入,API Key为:XXX,model为qwen-turbo;
请求的输入长度范围应当在[1, 6000]之间,如果超长,需要对TXT内容分拆成多份,使单个输入内容不超过6000个字符,然后再一个个发送至API,接收API返回的结果;
接收API返回的结果usage.input_tokens(这是输入文本对应的token数目),如果文本长度低于6000字符,直接输出信息:{txtfilename}这篇文档的Token数量估计为{usage.input_tokens}个;如果文本长度大于6000字符,将分拆的各个txt文档的Token数目加总在一起,设为变量{totalusagetokens},输出信息:{txtfilename}这篇文档的Token数量估计为{totalusagetokens};
最后,把所有的{totalusagetokens}求和,设为变量{finaltotalusagetokens},然后输出信息:这些文档一共Token数量估计为{finaltotalusagetokens}
注意:
每一步都要打印相关的信息;
根据API的限流和请求要求,合理安排任务的发送频率,避免触发API的速率限制;
要有错误处理和调试信息,这有助于找出问题所在;
在读取文件时避免递归地处理同一个文件夹下的所有文件;
在文件的开始处添加以下导入语句:from http import HTTPStatus;
qwen-turbo的Token计算API的使用方法,请参照下面这个例子:
from http import HTTPStatus
import dashscope
import os
def tokenizer():
response = dashscope.Tokenization.call(
model='qwen-turbo',
messages=[{'role': 'user', 'content': '你好?'}],
api_key=os.getenv("DASHSCOPE_API_KEY"),
)
if response.status_code == HTTPStatus.OK:
print('Result is: %s' % response)
else:
print('Failed request_id: %s, status_code: %s, code: %s, message:%s' %
(response.request_id, response.status_code, response.code,
response.message))
if __name__ == '__main__':
tokenizer()
返回结果示例
JSON
{
"status_code": 200,
"request_id": "2ecfce1f-b7af-9b3a-9482-01e4a5511e8f",
"code": "",
"message": "",
"output": {
"token_ids": [
108386,
11319
],
"tokens": [
"你好",
"?"
]
},
"usage": {
"input_tokens": 2
}
}
返回参数说明
status_code 200(HTTPStatus.OK)表示请求成功,否则表示请求失败,可以通过code获取错误码,通过message字段获取错误详细信息。
request_Id 系统生成的标志本次调用的id。
code表示请求失败,表示错误码,成功忽略。
message失败,表示失败详细信息,成功忽略。
Output 调用结果信息。
output.token_ids 本次输入文本对应的token_ids。
output.tokens本次输入文本对应的tokens。
usage.input_tokens 输入文本对应的token数目。
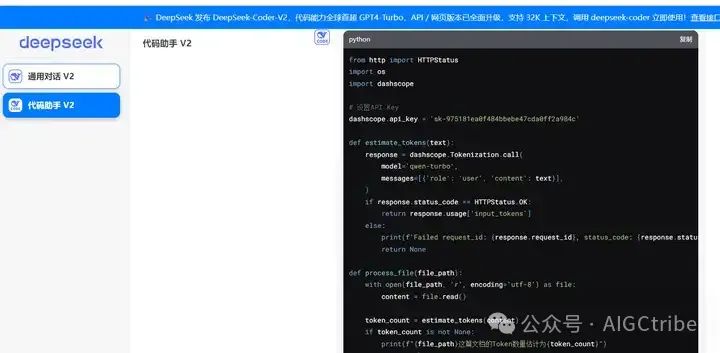
源代码如下:
from http import HTTPStatus
import os
import dashscope
# 设置API Key
dashscope.api_key = 'XXX'
def estimate_tokens(text):
response = dashscope.Tokenization.call(
model='qwen-turbo',
messages=[{'role': 'user', 'content': text}],
)
if response.status_code == HTTPStatus.OK:
return response.usage['input_tokens']
else:
print(f'Failed request_id: {response.request_id}, status_code: {response.status_code}, code: {response.code}, message: {response.message}')
return None
def process_file(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
content = file.read()
token_count = estimate_tokens(content)
if token_count is not None:
print(f"{file_path}这篇文档的Token数量估计为{token_count}")
return token_count
else:
print(f"Failed to estimate tokens for file: {file_path}")
return 0
def main():
folder_path = 'F:\\AI自媒体内容\\待翻译'
total_token_count = 0
for filename in os.listdir(folder_path):
if filename.endswith('.txt') and not filename.endswith('翻译.txt'):
file_path = os.path.join(folder_path, filename)
print(f"Processing file: {file_path}")
token_count = process_file(file_path)
total_token_count += token_count
print(f"这些文档一共Token数量估计为{total_token_count}")
if __name__ == "__main__":
main()
