原文在这里:https://medium.com/@n83072/dynamic-time-warping-dtw-cef508e6dd2d
當要計算時間序列資料的相似程度時,我們可以使用不同的距離計算方式。DTW就是其中一種距離方式計算,他的優勢在於:
- 可以比較長度不同的資料:在實際生活裡,通常我們想比較的資料長度都是不固定的
- delay也不怕:比如可以計算出A序列的第一個資料點(ta1)對應到B序列的第五個資料點(tb5),強大的應用包括語音辨識(比較同一個人的說“hello”的方式,第一種正常說,第二種像樹懶一樣說出“Heeeeeelllooooo”,DTW還是能偵測出你們是同一個人)
python:
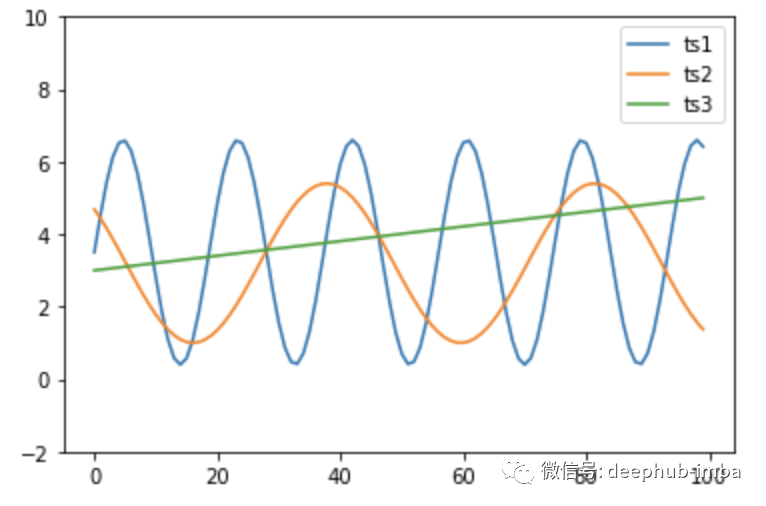
我們先創造出三個相同長度的資料ts1, ts2, ts3,從圖裡我們可以很明顯地看出ts1和ts2比較相似,第一種方法先透過最簡單的euclidean distance計算相似度,跑出的結果卻是ts1與ts3比較相近,因為euclidean distance僅考慮同個時間點下的兩的序列直線距離,無法捕捉到趨勢上的相似程度。
代码语言:javascript
复制
def euclid_dist(t1,t2):
return sqrt(sum((t1-t2)**2))print('ts1 vs. ts2:',euclid_dist(ts1,ts2))
print('ts1 vs. ts3:',euclid_dist(ts1,ts3))
接下來,我們來用用dtw,這個為了簡潔方便我們就使用fastdtw package來計算:
代码语言:javascript
复制
from fastdtw import fastdtw from scipy.spatial.distance import euclideandistance, path = fastdtw(ts1, ts2)
print('ts1 vs. ts2:',distance)
distance2, path2 = fastdtw(ts1, ts3)
print('ts1 vs. ts3:',distance2)

我們可以發現dtw的計算結果正確地告訴我們ts1與ts3較為相近!以上只是dtw的簡單小介紹,如果對背後的數學邏輯有興趣也歡迎一起討論
作者:Nancy Sun