源码解析 PyTorch 流水线并行实现 (4)--前向计算
目录
- [源码解析] PyTorch 流水线并行实现 (4)--前向计算
- 0x00 摘要
- 0x01 论文
- 1.1 引论
- 1.1.1 数据并行
- 1.1.2 模型并行
- 1.2 模型定义
- 1.3 GPipe计算图
- 1.4 设备执行顺序(Devicewise Execution Order)
- 1.5 PyTorch 实现难点
- 1.6 总结
- 1.1 引论
- 0x02 执行顺序
- 2.1 论文内容
- 2.2 解析
- 2.3 代码
- 2.4 使用
- 0xFF 参考
0x00 摘要
前几篇文章我们介绍了 PyTorch 流水线并行的基本知识,自动平衡机制和切分数据,本文我们结合论文内容来看看如何保证前向计算执行顺序。
流水线并行其他文章链接如下:
[源码解析] 深度学习流水线并行Gpipe(1)---流水线基本实现
[源码解析] 深度学习流水线并行GPipe (2) ----- 梯度累积
[源码解析] 深度学习流水线并行 GPipe(3) ----重计算
[源码解析] 深度学习流水线并行之PipeDream(1)--- Profile阶段
[源码解析] 深度学习流水线并行 PipeDream(2)--- 计算分区
[源码解析] 深度学习流水线并行 PipeDream(3)--- 转换模型
[源码解析] 深度学习流水线并行 PipeDream(4)--- 运行时引擎
[源码解析] 深度学习流水线并行 PipeDream(5)--- 通信模块
[源码解析] 深度学习流水线并行 PipeDream(6)--- 1F1B策略
[源码解析] PyTorch 流水线并行实现 (1)--基础知识
[源码解析] PyTorch 流水线并行实现 (2)--如何划分模型
[源码解析] PyTorch 流水线并行实现 (3)--切分数据和运行时系统
本文图片来自论文和github源码。
0x01 论文
之前我们提到过,因为 GPipe 是基于 TensorFlow 的库(当然了,这是Google的产品嘛),所以kakaobrain的一些工程师就用PyTorch 来实现了 GPipe,并且开源出来,这就是 torchgpipe,其地址为:https://github.com/kakaobrain/torchgpipe,用户可以通过 pip install torchgpipe 进行安装使用。
该作者团队还发表了一篇论文,具体如下:https://arxiv.org/pdf/2004.09910.pdf。
接下来我们就围绕这篇论文进行分析,本文不会全部翻译这篇论文,而是选择与实现密切相关的部分进行翻译分析。
1.1 引论
并行训练的一个障碍是:训练神经网络的常用优化技术本质上是顺序的。这些算法反复执行如下操作:对于给定的小批次(mini-batch)数据,计算其针对损失函数的梯度,并且使用这些梯度来更新模型参数。
1.1.1 数据并行
在有大量计算资源的情况下,数据并行将小批量(mini-batch)划分为微批量(micro-batch)并将每个微批量的计算委托给可用设备,以此来加速整体优化过程。通过仔细的超参数调整,数据并行可以有效地将训练时间减少到一定规模的小批量所需的训练时间,这可能取决于模型、优化算法和数据。
数据并行训练的问题则是,每个设备拥有自己的模型网络版本来执行子任务,并且在每次参数更新后必须同步模型网络参数。当有许多参数需要同步时,这可能会导致沉重的通信负载。
但是,当模型太大以至于即使将单个机器无法容纳模型,也无法计算梯度时,数据并行性不适用。
1.1.2 模型并行
模型并行性是一种训练庞大模型的方法,它将模型分成若干部分,并将它们放在不同的设备上。每个设备只计算模型的一小部分,并且只更新该部分中的参数。然而,模型并行性受到其"无法充分利用"行为的影响。因为大多数神经网络由一系列的层组成,持有模型后期部分的设备必须等待直到持有模型早期部分的设备计算结束。
一种可能的解决方案是使用梯度检查点,它只存储激活值的子集,并在需要时重新计算丢弃的激活值,从而节省内存。显然,这需要对模型的某些部分进行两次计算,并增加总体训练时间。
在后续部分,我们将讨论如何将前向和后向过程分解为子任务(在某些假设下),描述微批次管道并行的设备分配策略,并演示每个设备所需的执行顺序。也会讨论在PyTorch中实现管道并行最佳时间线的复杂之处,并解释torchgpipe如何解决这些问题。
此外,我们放松了模型是按顺序组合的假设,并提供了一种使用长跳跃连接表示模型的方法,以便在不放弃效率的情况下仍然应用管道并行性。
1.2 模型定义
假定我们有一个神经网络,其由一系列子网络构成。我们假定这些子网络是
,其参数分别是
,则整个网络是:
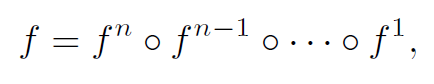
参数是
,为了清楚起见,我们称
表示 f 的第 j 个分区,并假设分区的参数是相互不相交的。
在训练网络时,基于梯度的方法(如随机梯度下降法)需要在给定小批量训练数据 x 和相应损失之后,计算网络的输出结果f(x)。以及损失相对于网络参数
的梯度g。这两个阶段分别称为向前传播和向后传播。
既然 f 由其 L 层 子模块 ((f^L, f^{L-1},...f^1)) 顺序组成,那么前向传播(f(x)) 可以通过如下方式计算:让 (x^0=x)(就是输入x),然后顺序应用每一个 partition,即 (x^j = f^j (x^{j-1})),这里 j = 1, ..., L 。就是 (f(x)) 可以表示为 :
[f(x) = f^L(f^{L-1}(f^{L-2}(... f^1(x)))) ]
再进一步,令 x 由 m 个更小的批次
组成,这些更小的批次叫做微批次(micro-batches)。则
的计算可以进一步分割为小的 tasks
,这里
,所以得到定义:
[x_i^j \leftarrow f^j(x_i^{j-1})\qquad\qquad\qquad (F_{i,j}) ]
这里 i = 1,..,m 和 j = 1,...,n ,假定 f 不参与任何 intra-batch 的计算。
用同样的方式,后向传播也被分割为 task,
,这里
是损失对于
的梯度。
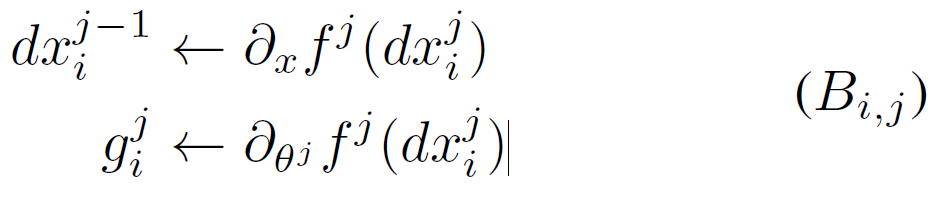
因此
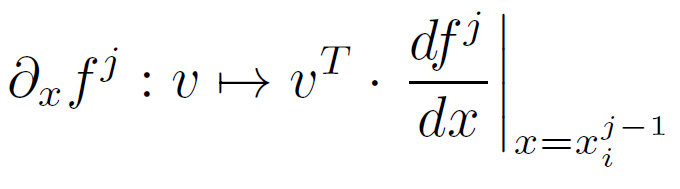
是通过分区
来计算后向传播(也叫vector-Jacobian product)的函数。
最终,我们依靠把
通过 i 来求和来得到损失针对
的梯度。
需要注意的是在tasks之间有数据依赖。比如
需要
,而
只有在
计算完成之后才有效,因此,
必须在
开始之前结束。同理,
必须在
之前结束。
下图就是一个依赖图,这里 m = 4, n = 3 。即,模型被分成3个子网络,小批次被分割成 4个微批次。
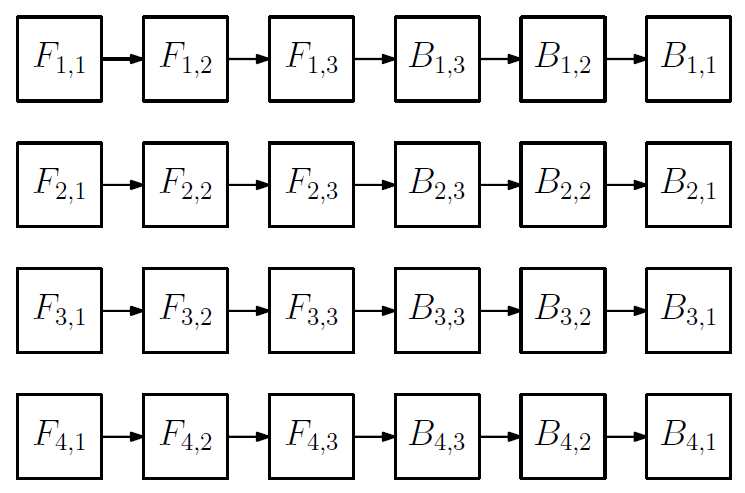
前面三个 F 是三个子网络的前向传播,后面三个 B 是三个子网络的后向传播。
下面表示第一个微批次,顺序完成三个子网的前向传播和后向传播。

给定 task 的集合
和
,和一个可以并行工作的设备池,不同的并行化策略有自己分配任务给设备的规则。
一旦解决依赖关系,每个设备就会计算一个或多个分配的任务。在上面的设置中,tasks 的所有依赖项都具有相同微批次索引 i。因此,通过将具有不同微批量索引的任务分配给不同的设备,可以有效地并行化任务,这就是数据并行。
1.3 GPipe计算图
管道并行的策略是根据分区索引 j 分配任务,以便第 j 个分区完全位于第 j 个设备中。除此之外,还强制要求
必须在
之前完成,和
必须在执行
之前完成。
除了微批量流水线之外,GPipe还通过对每个
使用梯度检查点进一步降低了内存需求。因为第
个设备每次只执行
,所以当计算
时候,只需要拿到
的激活图。
因为恰恰在执行
之前计算前向传播
,所以我们内存消耗减少了m倍。此外,当设备等待
时,可以进行重新计算,这些信息如下图所示:

其中虚线箭头表示因为引入了微批次顺序而带来的独立任务之间的执行顺序。颜色表示不同的设备。
我们注意到最后一个微批次的重新计算,即
,这里
是不必要的。
这是因为在第j台设备上,前向传递中的最后一个任务是
、 因此,在前向传递中放弃中间激活,并在后向传递开始时重新计算它们,不会减少内存,只会减慢管道速度。因此,图中省略了
。
1.4 设备执行顺序(Devicewise Execution Order)
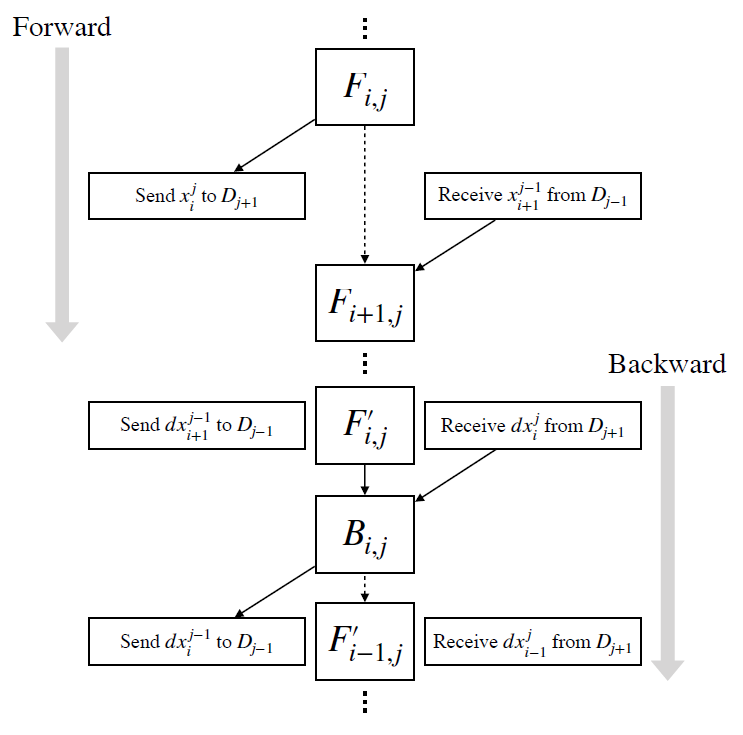
总之,在流水线并行性(带有检查点)中,每个设备都被分配了一组具有指定顺序的任务。一旦满足跨设备依赖关系,每个设备将逐个执行给定的任务。然而,这个图片中缺少一个组件——设备之间的数据传输。为了便于说明,设备 j 必须遵循的完整执行如图所示顺序。而且为了强调,数据传输操作被明确表示为“接收”和“发送”。
为方便起见,库提供了子模块 torchgpipe.balance 来计算得到分区,目的是让两两分区(pairwise)之间的资源差别尽量小。资源占用情况是通过分析(profile)来计算。具体是使用了 2 Imre B´ar´any and Victor S Grinberg. Block partitions of sequences. Israel Journal of Mathematics, 206(1):155–164, 之中的算法。
1.5 PyTorch 实现难点
我们最关心的是效率。为了使管道并行性按预期工作,必须以正确的顺序将任务分配给每个设备。在Pytorch中实现这一点有几个复杂之处。
- 首先,由于PyTorch的define by run风格及其eager execution的执行行为(与in construct-and-run 框架相反),核函数(kernel)被动态地发布到每个设备。
- 因此,必须仔细设计主机代码(host code),这样不仅可以在每个设备中以正确的顺序发布绑定到设备的任务,而且还可以避免由于Python解释器未能提前请求而延迟在设备上(与CPU异步)执行任务。
- 当某些任务是CPU密集型任务或涉及大量廉价kernel调用时,可能会发生这种延迟。作为一种解决方案,torchgpipe引入了确定性时钟周期(deterministic clock-cycle),它给出了任务的总体顺序。其次,后向传播的计算图是在前向传播过程中动态构造的。换句话说,“它避免了“正向图”的具体化,只记录微分计算所需的内容”。因为PyTorch既不记录正向计算图,也不维护一个梯度磁带(gradient tape),PyTorch的自动微分(autograd)引擎仅对计算图进行反向传播。这意味着自动加载引擎可能不会完全按照与正向过程相反的执行顺序运行,除非由图的结构强制执行。为了解决这个问题,torchgpipe开发了一对名为“fork”和“join”的基本函数,在后向计算图中动态创建显式依赖关系。- 第三,如果不小心管理,多个设备之间的通信可能导致双向同步。这会导致利用率不足,因为即使在副本和队列中的下一个任务之间没有显式依赖关系时,发送方也可能等待与接收方同步,反之亦然。torchgpipe通过使用非默认CUDA流避免了这个问题,这样副本就不会阻止计算,除非计算必须等待数据。
- 最后,torchgpipe试图放宽微批处理流水线并行性的限制(模型必须是顺序的)。
- 尽管原则上任何神经网络都可以以顺序形式编写,但这需要提前知道整个计算图,而PyTorch中则不是这样。特别是,如果有一个张量从设备 中的一层跳到设备
中的另一层,则该张量将被复制到中间的所有设备,因为torchgpipe无法提前知道它。为了避免这个问题,我们设计了一个接口来表示跳过了哪些中间张量以及哪些层使用了它们。
1.6 总结
我们总结一下目前核心难度,从而引入下面的工作。
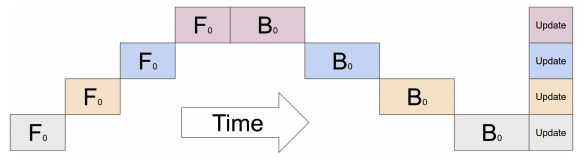
- 原始流水线状态如下:
- 管道并行的策略是根据分区索引 j 分配任务,以便第 j 个分区完全位于第 j 个设备中。
- 持有模型后期部分的设备必须等待,直到持有模型早期部分的设备计算结束。
- 目标流水线状态如下:
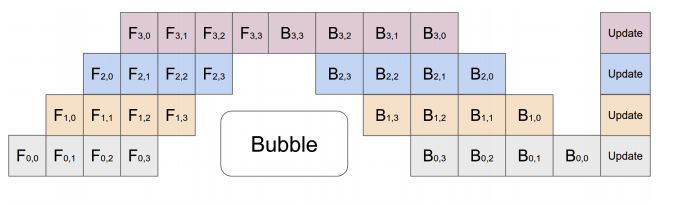
- 目前问题:
- 如果分成若干个微批次,则需要强制要求 必须在
之前完成,以及
必须在执行
之前完成。
- 后向传播的计算图是在前向传播过程中动态构造的。PyTorch既不记录正向计算图,也不维护一个梯度磁带(gradient tape),PyTorch的自动微分(autograd)引擎仅对计算图进行反向传播。这意味着自动加载引擎可能不会完全按照与正向过程相反的执行顺序运行,除非由图的结构强制执行。
- 目前难点:
- 如何在每个设备中以正确的顺序发布那些绑定到设备的任务,以避免由于Python解释器未能提前请求而延迟在设备上(与CPU异步)执行任务。
- 如何建立这些小批次之间的跨设备依赖关系。- **如何保证正确执行顺序?**torchgpipe引入了确定性时钟周期(deterministic clock-cycle),它给出了任务的总体顺序。
- **如何保证计算图中的动态显式依赖关系?**针对clock\_cycles产生的每一个运行计划:
- 利用 fence 函数调用“fork”和“join”,以此在向后计算图中动态创建显式后向传播依赖关系。
- 利用 compute(schedule, skip\_trackers, in\_queues, out\_queues) 进行计算。本文就首先看看前向计算中,如何保证正确执行顺序。
0x02 执行顺序
下面我们看看确定性时钟周期算法(Forward Dependency: Deterministic Clock-cycle)。这个排序就是专门在前向传播中使用,前向传播按照这个算法来进行逐一计算。
一般来说,前向传播计算是按照模型结构来完成的,但是因为流水线并行是特殊的,模型已经被分割开了,所以 torch-gpipe 需要自己提供一个前向传播执行序列以执行各个微批次。
2.1 论文内容
任务的总顺序由前向传播中的主机代码决定。每个设备通过CPU分配的顺序隐式地理解任务之间的依赖关系。理想情况下,如果可以无代价的将任务分配给设备,只要设备内的顺序正确,CPU就可以按任何顺序将任务分配给设备。然而,这种假设不够现实,因为在GPU上启动核函数对CPU来说不是免费的,GPU之间的内存传输可能需要同步,或者任务是CPU密集型的。因此,为了最小化来自CPU的延迟,我们通过"某节点到
的距离"对所有任务进行排序。

我们把这种方案命名为确定性时钟周期(deterministic clock-cycle)算法。在该算法中,CPU在计数器 (k=1)到(k=m+n-1) 的时钟周期内执行。在第k个时钟周期内,对于 i +j-1 = k 这些index:
- 首先执行 task
所需数据的所有复制(copy)核函数。
- 然后将用于执行任务的计算核函数注册到相应的设备(由于同一时钟周期中的任务是独立的,因此可以安全地进行多线程处理)。
2.2 解析

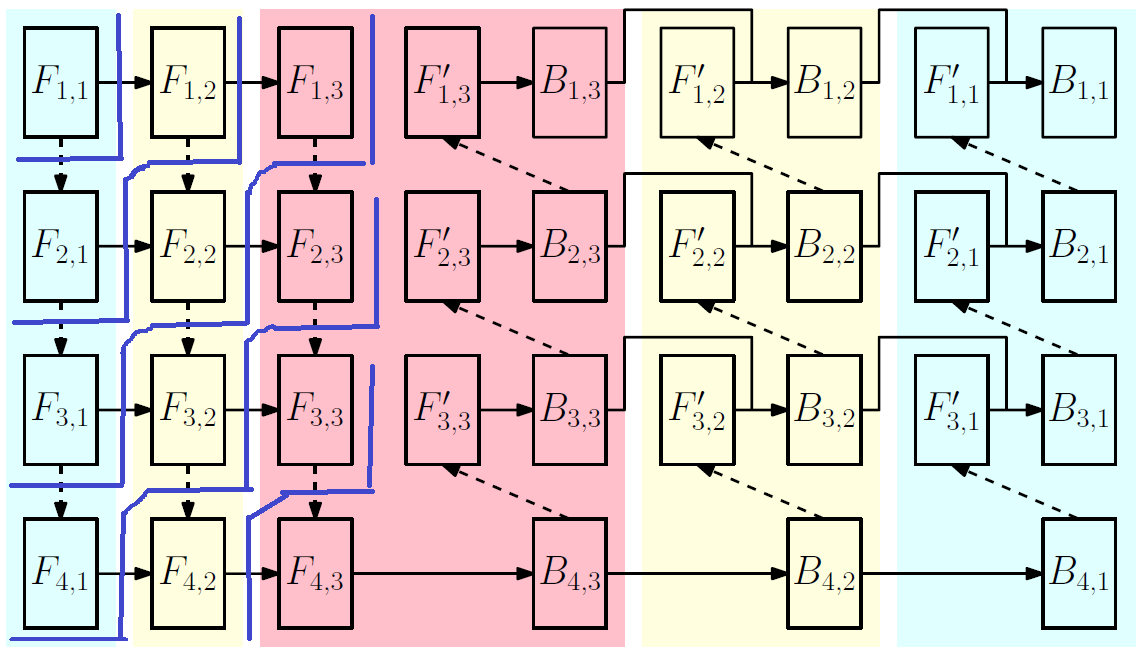
我们结合论文的图片看看,即:
- clock 1 时候,运行图上的
- clock 2 时候,运行图上的
。就是向右运行一格到
,同时第二个微批次进入训练,即运行
。
- clock 3 时候,运行图上的
。就是
向右运行一格到
,
向右运行一格到
,同时第三个微批次进入训练流程,即运行
。
- clock 4 时候,运行图上的
。就是
向右运行一格到
,
向右运行一格到
,同时第四个微批次进入训练流程,即运行
。
- 依次类推.....
对应到图上,我们可以看到,
到
的步进距离是1,走一步可到。
到
的步进距离是2,分别走两步可到。
这个逻辑从下图可以清晰看到。所以,这个clock的算法就是 利用任务到
的距离对所有任务进行排序。这个很像把一块石头投入水中,泛起的水波纹一样,从落水点一层一层的从近处向远处传播。
这里颜色表示不同的设备。
2.3 代码
我们再来看看代码。首先是生成时钟周期,这里:
- min(1+k, n) 就是在 k 时钟时候,可以启动的最大device数目(partition)。
- max(1+k-m, 0) 就是在 k 时钟时候,可以启动的最小微batch(micro-batch)。
所以最终返回的序列就是k 时钟时候,可以启动的(index of micro-batch,index of partition)序列。
def clock_cycles(m: int, n: int) -> Iterable[List[Tuple[int, int]]]:
"""Generates schedules for each clock cycle."""
# m: number of micro-batches
# n: number of partitions
# i: index of micro-batch
# j: index of partition
# k: clock number
#
# k (i,j) (i,j) (i,j)
# - ----- ----- -----
# 0 (0,0)
# 1 (1,0) (0,1)
# 2 (2,0) (1,1) (0,2)
# 3 (2,1) (1,2)
# 4 (2,2)
# 我们解析一下,这里 k 就是时钟数,从1开始,最多时钟序号就是 m+n-1。
# min(1+k, n) 就是在 k 时钟时候,可以启动的最大device数目
# max(1+k-m, 0) 就是在 k 时钟时候,可以启动的最小batch
for k in range(m+n-1):
yield [(k-j, j) for j in range(max(1+k-m, 0), min(1+k, n))]设定 m = 4, n =3,solve(4,3) 的输出是:
[(0, 0)]
[(1, 0), (0, 1)]
[(2, 0), (1, 1), (0, 2)]
[(3, 0), (2, 1), (1, 2)]
[(3, 1), (2, 2)]
[(3, 2)]因为论文有一个示例图,而这个图和注释&代码不完全一致,为了更好的说明,我们就按照图上来,因为图片是从
开始,所以我们把注释修正以下:
# 0 (0,0) ----> clock 1 运行图上的 (1,1)
# 1 (1,0) (0,1) ----> clock 2 运行图上的 (2,1) (1,2)
# 2 (2,0) (1,1) (0,2) ----> clock 3 运行图上的 (3,1) (2,2) (1,3)
# 3 (2,1) (1,2) ----> clock 4 运行图上的 (3,2) (2,3)
# 4 (2,2) ----> clock 5 运行图上的 (3,3)我们把 solve代码修改下,为了打印正确的index,这样大家就可以更好的把代码和图片对应起来了。
m=4 # m: number of micro-batches n=3 # n: number of partitions for k in range(m + n - 1): print( [(k - j + 1 , j +1 ) for j in range(max(1 + k - m, 0), min(1 + k, n))] )
打印是:
[(1, 1)] # 第 1 轮训练计划 & 数据
[(2, 1), (1, 2)] # 第 2 轮训练计划 & 数据
[(3, 1), (2, 2), (1, 3)] # 第 3 轮训练计划 & 数据
[(4, 1), (3, 2), (2, 3)] # 第 4 轮训练计划 & 数据
[(4, 2), (3, 3)] # 第 5 轮训练计划 & 数据
[(4, 3)] # 第 6 训练计划 & 数据
我们把流水线的图再祭出来看看。

我们把上面的输出按照流水线的图绘制一下作为比对。
可以看到,前 4 个时钟周期内,分别有 4 个 micro-batch 进入了 cuda:0,分别是(1,1) (2,1) (3,1) (4,1) 。然后按照 clock_cycles 算法给出的顺序,每次迭代(时钟周期)内执行不同的schedule,经过了 6 个时钟周期之后,完成了第一轮 forward 操作。这就形成了流水线。
流水线优势在于,如果 number of micro-batches 配置的合适,那么可以在每个时钟周期内,最大程度的让所有设备都运行起来。与之对比,原生流水线每一时间只能让一个设备互活跃。
+ + + + + + +
| | | | | | |
| | | | | | |
cuda:0 | (1,1) | (2,1) | (3,1) | (4,1) | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
cuda:1 | | (1,2) | (2,2) | (3,2) | (4,2) | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
cuda:2 | | | (1,3) | (2,3) | (3,3) | (4,3) |
| | | | | | |
| | | | | | |
| | | | | | |
| clock 1 | clock 2 | clock 3 | clock 4 | clock 5 | clock 6 |
+ + + + + + +
+------------------------------------------------------------------------------> Time
具体数据batch的走向是:
+ + + + + + +
| | | | | | |
cuda:0 | (1,1) | (2,1) | (3,1) | (4,1) | | |
| + | + | + | + | | |
| | | | | | | | | | |
| | | | | | | +----------+ | |
| | | | | +-----------+ | | | |
| | | +------------+ | | | | | |
| | | | | | | | | | |
| +------------+ | | | | | | | |
| | | | | | | | | | |
| | | | v | v | v | |
| | v | | | | |
cuda:1 | | (1,2) | (2,2) | (3,2) | (4,2) | |
| | + | + | + | + | |
| | | | | | | | | | |
| | | | | | | | +-------------+ |
| | | | | | +----------+ | | |
| | | | +------------+ | | | | |
| | +-----------+ | | | | | | |
| | | | | v | v | v |
| | | v | | | |
cuda:2 | | | (1,3) | (2,3) | (3,3) | (4,3) |
| | | | | | |
| | | | | | |
| | | | | | |
| clock 1 | clock 2 | clock 3 | clock 4 | clock 5 | clock 6 |
+ + + + + + +
+-----------------------------------------------------------------------------------> Time
2.4 使用
在 Pipeline 类之中,我们可以看到,就是按照时钟周期来启动计算,这样在前向传播之中,就按照这个序列,像水波纹一样扩散。
def run(self) -> None:
"""Runs pipeline parallelism.
It modifies the given batches in place.
"""
batches = self.batches
partitions = self.partitions
devices = self.devices
skip_layout = self.skip_layout
m = len(batches)
n = len(partitions)
skip_trackers = [SkipTrackerThroughPotals(skip_layout) for _ in batches]
with spawn_workers(devices) as (in_queues, out_queues):
for schedule in clock_cycles(m, n): # 这里使用,给出了执行序列计划,后续按照这个来执行
self.fence(schedule, skip_trackers) # 构建后向传播依赖关系
self.compute(schedule, skip_trackers, in_queues, out_queues) # 进行计算</code></pre></div></div><p>至此,前向传播过程分析完毕,下一篇我们分析依赖关系。</p><h3 id="39292" name="0xFF-%E5%8F%82%E8%80%83">0xFF 参考</h3><p>Markdown公式用法大全</p><p>markdown中公式编辑教程</p><p>https://docs.nvidia.com/cuda/cuda-runtime-api/stream-sync-behavior.html#stream-sync-behavior</p><p>CUDA学习:基础知识小结</p><p>CUDA随笔之Stream的使用</p><p>NVIDIA解决方案架构师深度解析大规模参数语言模型Megatron-BERT</p><p>Accelerating Wide & Deep Recommender Inference on GPUs</p><p>HugeCTR: High-Performance Click-Through Rate Estimation Training</p><p>https://discuss.pytorch.org/t/how-to-prefetch-data-when-processing-with-gpu/548</p><p>https://github.com/NVIDIA/apex/</p><p>https://github.com/justheuristic/prefetch_generator</p><p>https://pytorch.org/tutorials/intermediate/model_parallel_turotial.html</p><p>https://pytorch.org/docs/stable/autograd.html</p><p>https://pytorch.org/docs/notes/cuda.html</p><p>https://zhuanlan.zhihu.com/p/61765561</p><p>https://pytorch.apachen.org/docs/1.7/64.html</p><p>https://zhidx.com/p/217999.html</p>