
我们今天的主要内容将不谈论H100(作为一个卡)本身具有的特性,像是功耗,频率范围,SP数量, 访存带宽这些"商品指标",而是想更多集中于这一代卡(计算能力9.0+)的可能的通用特性。这样今天的讨论可能对本系列的卡(包括还未出的家用版)都有用,而不至于变成针对一款谁都买不起的空中楼阁的讨论。
对具体卡的指标感兴趣的人可以自行看到时候的广告。
在Hopper白皮书里,有这样一个图:
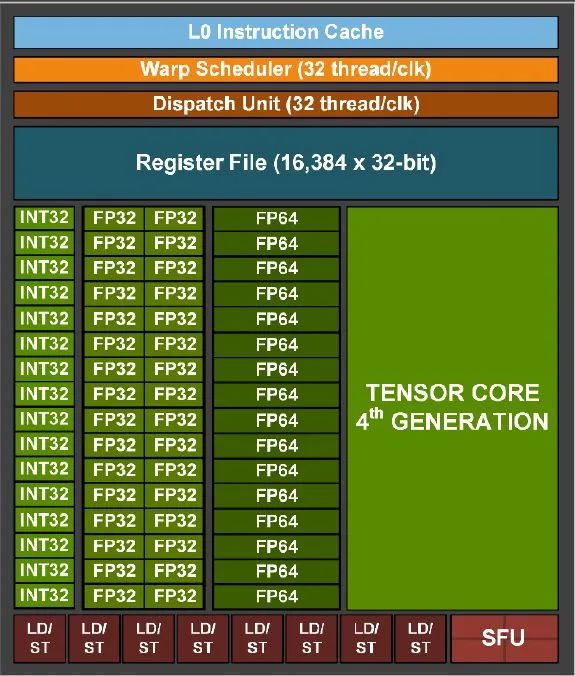
这一带的卡的SM里面,依然是4个Schedulers吗?或者说,这一代卡的SM,拥有什么样的变化?这个whitepaper没有给出。但是从结构上看,非常像是计算能力8.6的稍微改动版本。具体依然是256KB的寄存器堆,外加L1+Shared存储公用的结构(但是变大了),以及,外加Tensor Core单元,和一些其他的变化。
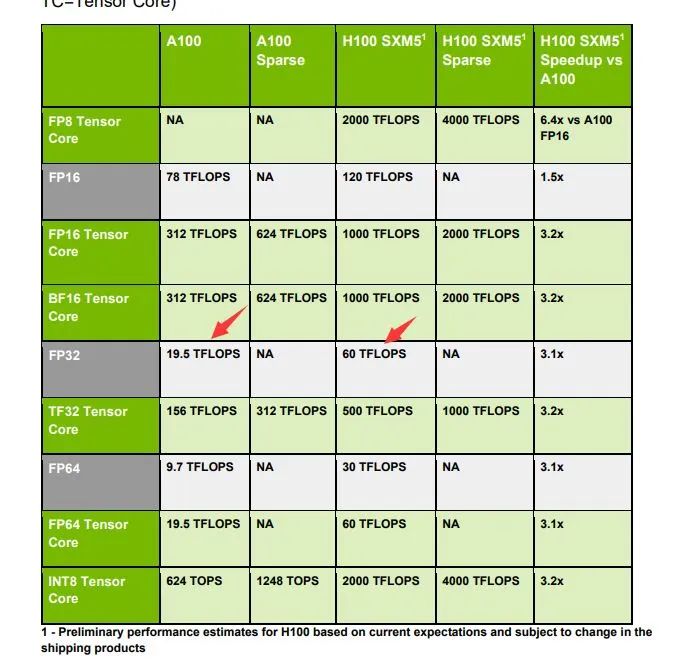
我们首先在这里看下之前一代的SM里面的究竟有64个SP还是有128个SP的问题。这点我们之前曾经说过,很多媒体也觉察到了这点,包括他们的"8.6的家用安培的1个SP可以当成0.7个上一代的SP"之类的说法。而本次Whitepaper里则配有比较明确的图,和文字说明:
(图,计算能力9.0的1/4 SM结构图)
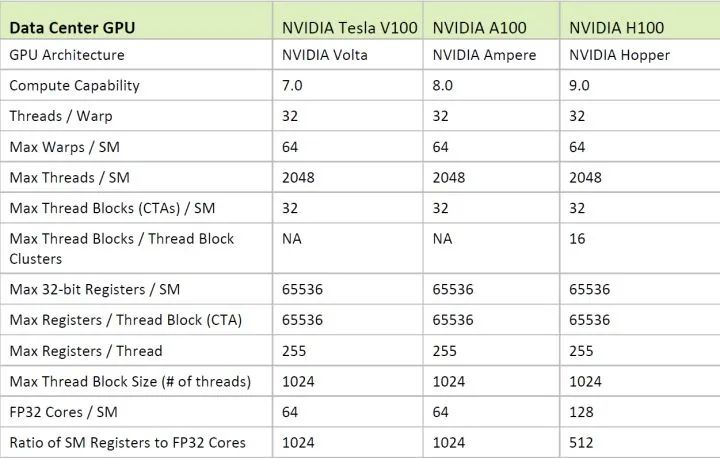
(图,尚未出现在编程指南手册中的预览版计算能力特性图)
结合这两个图看,我们首先可以看到(上图),完整的SM应当还是具有4个schedulers左右的。其次,在保持INT32单元为1个Port(16x4个=64个标量单元)的情况下,FP32单元翻倍成32x4 = 128个,而计算能力表格也里尽量使用了避免争议的FP32 Cores / SM = 128. 这样上一代的模糊的问题就比较清楚了。
同时我们也可以看出来NV比较坦率的指出了,依靠单纯的加倍FP32单元的做法(8.6,9.0)所得到的性能范围,实际上可用的资源(例如本表格的最后一行的ratio)是要减弱一半的。此时能否在削弱了一半的寄存器之类的资源的情况下,维持可以达到的性能,也将成为一个挑战;
以及,和在CUDA编程指南手册中对8.6指出的那样,如果依然维持4个scheduler,每个scheduler折算能发射给1个port/cycle,维持32x4或者说16x8的FP32单元,将占据所有的指令发射能力。占据所有的指令发射能力将意味着,理论上的峰值想要达到,只有在存放操作数的单元(主要是这减半的寄存器)能够够用,同时完全不存在shared memory读、写、原子操作,和访存/tex,和TensorCore之类的wmma操作的情况下,才有可能。
所以本次要么是Scheduler能力加倍,要么是依然像8.6的那样,这128个FP32单元,只有比较虚的存在着。但不管怎么样,NV毕竟为我们用尽量少的晶体管数量代价,换取来最大的性能提升,做出了努力。但是本次的一个亮点,对于经典CUDA方面来说,则是FP64单元提升到了64个/SM。用经典的INT32单元折算的话,等于是100%的Double性能了,而不在是1/2了。
所以本次手册指出的,SP的浮点性能翻倍(折算到单位SM, 同频下),不管从单精度还是双精度的角度看,大致还是可以认为是达标的。这样这代卡,对于无法上TensorCore的经典科学运算领域来说,可能是值得购买的。
然后我们继续看SM内部的其他传统CUDA相关方面的变化。刚才已经说过了,寄存器资源并没有提升(我们先不考虑uniform registers, 本次白皮书没说,对比A卡的情况来说,标量寄存器一般不会成为瓶颈),则一个比较惊喜的变化是shared memory + L1整体变成了256KB,这已经相当大了。
而根据白皮书本次的说法,shared memory最多可以在让出32KB给L1 cache使用的情况下,用到剩下的256KB - 32KB = 224KB, 这点还是比较良心的。很多受限于shared memory容量应用现在可以考虑尽量的往GPU上迁移了。但是手册没有提到9.x的家用版本还能维持多少,一般会比这个数字小一点,但不应当小很多。
但是就算是小到128KB的shared memory,如果配上本次额外具有的新特性,则依然非常耀眼:本代的卡,能在GPC(最多16-18个SM的小组合)内部,拼接这10多个SM的shared memory资源成为一个更大的shared memory pool, 来使用。如果用224KB每SM的shared memory, 和16个SM/GPC的规模算,我们的新一代的CUDA应用,可以用上224KB * 16 = 3584 KB的巨型shared memory!!!这是本次的非常非常非常令人激动的特性,从最早的48KB的Shared memory限制走来的人,会一瞬间几乎有当年在DPMI下分配1MB的内存的激动人心的感觉。
而3584KB,也远远超过了1MB。如果用当年的歌词来说,则是"我还以为不可能的,不会不可能"(梁静茹)。白皮书上叫这个为distributed shared memory, 分布式的shared memory。而以前每代都存在的SM之上的GPC单位,也终于从graphics的角度,到CUDA计算的角度,有了新的用途了。分布式shared memory, 根据本次白皮书的内容看,支持完整的shared memory上的特性,例如读、写(普通shared memory, 自CUDA 1.0+), 和原子操作(普通shared memory,自CUDA 5.0+),这样用户用起来,分布式的shared memory和普通shared memory, 应当无本质上的区别,除了明显的容量变大了很多外,因为跨SM的shared memory的操作,是通过GPC内部的某种单元访问的,目前尚不清楚跨SM的时候,远程的shared memory, 和本地的SM内部的shared memory在带宽和延迟上的具体变化,应该会稍微慢和带宽低一点点,但依然比global memory好的多的多。等待到时候具体出来。
说到能拼凑的分布式的shared memory, 我们需要说到GPC为单位现在引入的新功能,但是我们先将SM内部说完。再回到SM内部,经典的tensor core本次有两个比较明显的变化。
一个变化是计算峰值的翻倍,这个应该没有太多可说的,应当是通过堆料(各种浮点计算单元)堆出来的,用户们只要掏钱买单,即可享受;
但是另外一个变化是增加了对之前呼声很高的8-bit的minifloat的支持,这样相比FP16, 8-bit进一步的翻倍了峰值性能,根据NV的说法,终于能单卡到PFlops级别了(大约是2PFlops,lady详情看手册),非常惊人。阅读者还曾经幻想在2015年的时候,能积攒100W人民币组合成性能过P的小集群(FP32),而现在只要单卡即可,虽然只是FP8.
我们具体回到SM里的TensorCore里的FP8新数据类型上看看,因为FP8尚未IEEE 754规范化,本次NV实际上提供的FP8,和wikipedia上的minifloat例子稍微有点结构上的差异。

(图,本次9.0提供的"两种"FP8新数据格式)
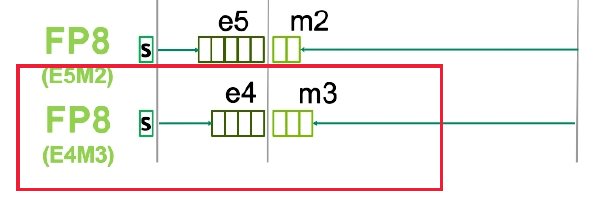
(图,本次9.0的两种格式)
注意这两种FP8格式里面的被红色框框,框出来的那种,是和wikipedia上有详细描述的minifloat格式一致的,有兴趣的读者可以深入阅读wikipedia上的相应文章,这文章说的很好。NV叫这种为E4M3格式,和E5M2格式。其中标准点的E4M3格式,具有4个浮点位,和3个(+1个隐含)的有效数字位。因为他一共才1个字节,所能表示的浮点数值,实际上一共只有离散的242种。但是根据NV的说法,在某些神经网络的应用中,虽然很小,但具有奇效。
另外一种minifloat的格式则更加不标准点了,是E5M2的,8-bit里面将5位分给了指数位,只有2位是有效数字。这种具有更低的有效分辨率了,但具有更广阔的动态范围,可能除了神经网络,暂时无更多的能用上的地方了,所能表达的浮点数,也要少于242个可能的离散值。但是考虑到之前的TensorCore有了binary neural network的数据类型支持(1-bit整数)(参考Yolo原作者文章),和本次的FP8的minifloat支持,NV表现出来了在深度学习领域的开拓的决心,我们继续看看时间的发展。
好了,到这里,我们就已经看完了9.0的SM里面的寄存器和Shared memory这两种主要的存储单元,和SP、TensorCore这两种主要的计算单元,但是事情还没完,光有数据在那里,和光有数据的计算,是不完备的。我们都知道公式:计算机 = 数据的移动 + 数据的变换。其中存储在移动和变换中都占据角色,但数据的移动还有其他方面。
我们的N卡一直是经典的RISC的以寄存器为中心的角色,具有经典的独立Load/Store,外加运算的ISA结构(除了计算能力1.x)。所有的运算,传统上,在进行之前,都需要用某种方式,将数据要么从global memory读取到寄存器中,要么从上一步运算作为结果操作数,放入到寄存器中。然后等到寄存器中数据好了后,才能执行下一步的操作。很多时候,像是为了单纯的将数据装入shared memory, 传统上必须经过两步走,先从global memory读取到 --> 寄存器,再从寄存器写入到--->shared memory, 浪费感情。从上一代开始增加了一条类似PIO风格的LDGSTS指令,该指令可以直接从global memory, 并以shared memory为目的地,直接载入。并且该指令已经导入到CUDA C/C++里面了,像是我们很多同学已经在RTX 30的家用卡上用上了,这样在该指令的进行过程中,warp还能继续执行提供操作,节省了很多没有必要的恋爱过程中的繁琐浪费步骤。但是本次9.0进一步的引入了嵌入在SM内部的微型DMA控制器(TMA单元),根据本次的白皮书,该单元相比基于指令的异步载入shared memory, 具有微小的劣势,和极大的优势。
说到优势和劣势之前,我们先说一些历代先人们都为了数据移动,设计出来哪些思路,这里我们就直接抄书了:大致可以分为3种——
1)是GPU/CPU所具有的指令集中的访问指令,可以按照指令中指定的地址、数据大小,进行非常灵活的最小单位的数据传输。这种灵活性最高;
2)是所谓的DMA控制器,这是一种高度功能专一化的重型数据传输单元,这种可以根据预先设定好的从源指针,到目的指针,进行某些预定数据传输。这种灵活性最低,但往往最省电和能更好的干本职工作。
3)则是所谓的IOP, IO Processor, 相当于DMA控制器,配上了一点点的弱化的运算功能。介于两者之前。
本次9.0在每个SM内部所引入的TMA这种单元,属于第二种专用的DMA控制器。他具有典型的常见的DMA控制功能,例如需要使用特定的数据struct来描述一次传输任务,即本次的白皮书中所说的TMA的descriptor。这种每个SM内部所嵌入的小DMA控制器,极大的减轻了SM本身的,基于特定指令的PIO方式的逐条载入。例如说,每条指令中灵活指定的地址,无需通过LSU之类的单元合并成较为宏观上的地址范围,和传输大小,因为TMA作为DMA控制器,本身可以直接从较为宏观的任务角度,去接受和处理传输任务,而无需从较低的指令层次,“综合”出来任务是什么。这样减轻了SM内部,包括scheduler和LSU在内的多个单元。这样有利于这些单元去完成他们本来应该干的事情,例如,去更好的压FP32单元,发挥潜在的峰值性能.。
不仅仅如此,根据本次的白皮书,TMA只所以叫Tensor的Memory Accelerator,是因为它还支持包括范例的block transfern能力,能够处理宽度和stride不一致、边界等多种情况:
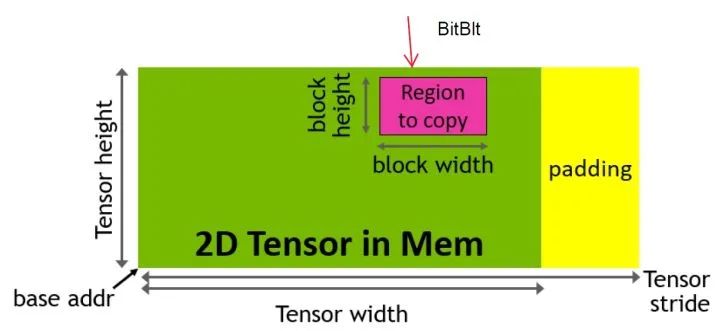
(图:TMA的块传输功能演示)
我们尚不清楚这种操作,在深度学习中的用途是否广泛,但是NV所没有说到是,这种操作,在2D的graphics操作中,叫做bitblt操作,90年代开始的显卡加速器的这些年的发展,是从2D的加速器开始的。在很多2D图像或者场景的处理中,这是唯一需要加速的运算。这样,就算该TMA单元不在深度学习之类的场景有用,作为通用的shared memory <--- global memory的通用专用载入器,如前文所说,它极大的解放了SM中的其他单元,并且可能在多种通用的图像图形操作场景中有用。
同时,根据NV的潜台词(在白皮书中),该DMA单元并不会引入非常突兀的接口,在CUDA C/C++, 而是可能依然会可能以8.X中的async的异步memcpy的老面孔出现,顶多有轻微改动。这样还是很方便的。很多手写过各种单片机上的DMA控制器的,或者Intel CPU里内嵌的IOAT的DMA控制器的同学,知道手写任务表述struct的list,和调用高层库函数或者自动生成相应操作的函数调用,编码的方便程度还是截然不同的。不仅仅如此,本次SM内部引入的DMA控制器,比前一代的基于PIO的异步载入指令,还多了反向操作,例如可以从shared memory直接写入global memory,功能增强不少。
不仅仅如此,TMA和Shared memory一起,走出SM的疆界,跨入到GPC的范畴:
其中shared memory我们上文已经说过,可以在大约16-18个SM左右的1个GPC中的SM间拼凑共享;而TMA根据白皮书,也可以服务于这GPC间的shared memory们,用他们作为数据来源或者目的地。但具体的细节,白皮书并没有告诉我们很多,但对于这功能的描述,我们还是知道了很多值得憧憬的幻想,和满怀激动的期待的。
不仅仅如此,跨越多个SM,在1个GPC间上的多个SM里,9.0还让我们现在总是可以,协作式的拼凑blocks,能确定性地在这多个SM上同时驻留多个blocks,构成一个叫cluster的单位。
要知道我们的CUDA的海量线程们,被约束成了几个级别:线程(或者warp) ---> block ---> grid,其中grid就是一次kernel的启动。以往我们需要多个blocks之间进行协作的时候,只能用技巧或者用限制多多的cooperative launch(限制本次启动的grid必须能同时驻留在GPU的多个SM上,限制非Windows的WDDM驱动)。而且为了方便的照顾你知道你是否能成功的启动这么多blocks进行协作,NV还提供了occupancy API, 辅助你判定究竟多大的grid能cooperative的launch成功。但是,历尽千辛万苦启动成功了,本次启动的grid里的所有blocks之间想进行通讯,还必须走global memory,虽说有L2 cache在尽力的缓冲,但总感觉忧虑多多。
现在,虽然本次GPC单位的正式作为CUDA运算的中间单位出现,这两个问题得到了很大程度上的解决。因为现在(可能是可选的,根据本次白皮书的暗示),一次kernel启动分成了4级单位(仅限launch with clusters的时候):线程(或者warps)--->blocks---->clusters---->grid,允许blocks成组的构成一个又一个的cluster了。这样如果NV在整个9.X产品线上维持最低的GPU规模不少于16个SM(1个GPC大约),那么几乎总是会存在1个cluster的资源的,不用再费心的担心是否grid级别的重型协作启动能否成功(特别是再Windows上的WDDM驱动上,试图占据完整个GPU的资源来进行一次协作式启动,不让的)。同时该cluster内部,因为是在1个GPC内部,现在总是可以高速的通讯了,并且有巨大的on-chip的shared memory可用了。
而且根据本次白皮书的说法,巨大的结合起来的shared memory采用generic addressing/UVA,不用在因为CUDA的历史传统(从计算能力1.x引入的segment的address space),而纠结为何有时候NULL在Shared memory上是有效的指针的坑爹问题了(注意每个block的逻辑shared memory从0开始,也有它的好处,但是我们这里没说)。
总结
好了。这样我们已经回顾了SM的内部改进,性能的提升,容量的变化,SM外部的GPC单位的引入和给予他的3大功能(分布式的shared memory拼凑,TMA专用传输单元,协作式的grid启动中的cluster)。以及,还有TensorCore的性能翻倍和新的数据格式 。
说明一下,本次还有个贯穿整个9.X的transactional barrier, 我们尚未明确这个的精确理解,这里先就不做解释。
从整个GPU的角度看,GPU内,负责和片外接触的L2,也应当是一个重点;
外部的本次的HBM3显存,也应当是一个重点(但可能不会出现再家用产品线上);
从PCI-E 4.0到5.0的提升(单向最高64GB/s传输)也应当是一个重点。
但是因为时间的关系,和最后这些显然不会在我们的Jetson产品线上出现的缘故,我们就暂时不提到他们。而已经提到的内容已经足够让你激动,并且完成你以前不能完成的内容了。
需要说明的是,本次SM内部增加了一些动态规划的扩展指令(DPX, Dynamic Programming Extensions), 并且本次NV在白皮书的最后,单独用章节对其进行了介绍,并且画图描述了特定应用的Smith-Waterman算法:

(图:计算能力9.0的DPX扩展指令,对史密斯.沃特曼算法上的应用讲解)
最后的DPX应当是非常重要的章节,但是因为本次COI的缘故,我们无法详细为你展开这里(虽然我们非常非常想展开)。