引言
随着年轻人的社交需求不断增长,各种社交软件应运而生,这些社交软件通常都会有好友推荐功能,根据六度分离理论,理想情况下,每个人通过6个人就可以跟所有人产生关联,因此K-hop算法(K跳算法)被用于实现好友推荐,现在让我们来尝试使用GeaFlow在5分钟内实现K-hop算法吧!
K-hop(K跳)算法介绍
K-hop算法是一种基于图论的算法,用于寻找一个起点通过K次以内跳跃能够到达的节点,也就是从起点出发,找出K层内与之关联的节点。K-hop算法广泛应用于好友推荐、影响力预测和关系发现等场景。
K-hop算法本质上是一种广度优先搜索(BFS)算法,通过从起点开始不断向外扩散的方式来计算每一个节点到起点的跳跃数。算法流程如下:

GeaFlow实现K-hop算法
首先需要通过实现AlgorithmUserFunction接口来编写K-hop算法的UDGA,K-hop算法的参考实现如下:
package com.antfin.rayag.myUDF;import com.antgroup.geaflow.common.type.primitive.IntegerType;
import com.antgroup.geaflow.common.type.primitive.StringType;
import com.antgroup.geaflow.dsl.common.algo.AlgorithmRuntimeContext;
import com.antgroup.geaflow.dsl.common.algo.AlgorithmUserFunction;
import com.antgroup.geaflow.dsl.common.data.RowEdge;
import com.antgroup.geaflow.dsl.common.data.RowVertex;
import com.antgroup.geaflow.dsl.common.data.impl.ObjectRow;
import com.antgroup.geaflow.dsl.common.data.impl.types.IntVertex;
import com.antgroup.geaflow.dsl.common.function.Description;
import com.antgroup.geaflow.dsl.common.types.StructType;
import com.antgroup.geaflow.dsl.common.types.TableField;
import com.antgroup.geaflow.model.graph.edge.EdgeDirection;import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;@Description(name = "khop", description = "built-in udga for KHop")
public class KHop implements AlgorithmUserFunction<Object, Integer> {private AlgorithmRuntimeContext<Object, Integer> context; private int srcId = 1; private int k = 1; @Override public void init(AlgorithmRuntimeContext<Object, Integer> context, Object[] parameters) { this.context = context; if (parameters.length > 2) { throw new IllegalArgumentException( "Only support zero or more arguments, false arguments " + "usage: func([alpha, [convergence, [max_iteration]]])"); } if (parameters.length > 0) { srcId = Integer.parseInt(String.valueOf(parameters[0])); } if (parameters.length > 1) { k = Integer.parseInt(String.valueOf(parameters[1])); } } @Override public void process(RowVertex vertex, Iterator<Integer> messages) { List<RowEdge> outEdges = new ArrayList<>(context.loadEdges(EdgeDirection.OUT)); //第一轮迭代将所有顶点初始化,目标点的K值初始化为0,并向邻点发送消息,其他点的K值初始化为Integer.MAX_VALUE if (context.getCurrentIterationId() == 1L) { if(srcId == (int) vertex.getId()) { sendMessageToNeighbors(outEdges, 1); context.updateVertexValue(ObjectRow.create(0)); context.take(ObjectRow.create(vertex.getId(), 0)); }else{ context.updateVertexValue(ObjectRow.create(Integer.MAX_VALUE)); } } else if (context.getCurrentIterationId() <= k+1) { int currentK = (int) vertex.getValue().getField(0, IntegerType.INSTANCE); //如果当前顶点收到消息,并且K值为Integer.MAX_VALUE(没有被遍历到),则本轮应该修改K值,并向邻边发消息 if(messages.hasNext() && currentK == Integer.MAX_VALUE){ Integer currK = messages.next(); //将当前顶点写出 context.take(ObjectRow.create(vertex.getId(), currK)); //更新当前顶点的K值 context.updateVertexValue(ObjectRow.create(currK)); //向邻点发消息 sendMessageToNeighbors(outEdges, currK+1); } } } //设置输出类型 @Override public StructType getOutputType() { return new StructType( new TableField("id", IntegerType.INSTANCE, false), new TableField("k", IntegerType.INSTANCE, false) ); } private void sendMessageToNeighbors(List<RowEdge> outEdges, Integer message) { for (RowEdge rowEdge : outEdges) { context.sendMessage(rowEdge.getTargetId(), message); } }
}
Geaflow运行K-hop算法实战
将KHop类打包成UDGA
新建一个maven工程,将KHop类放/src/main/java目录下,pom文件中需要添加如下依赖:
<dependency>
<groupId>com.antgroup.tugraph</groupId>
<artifactId>geaflow-dsl-common</artifactId>
<version>0.1</version>
</dependency>将UDGA上传至geaflow-console平台
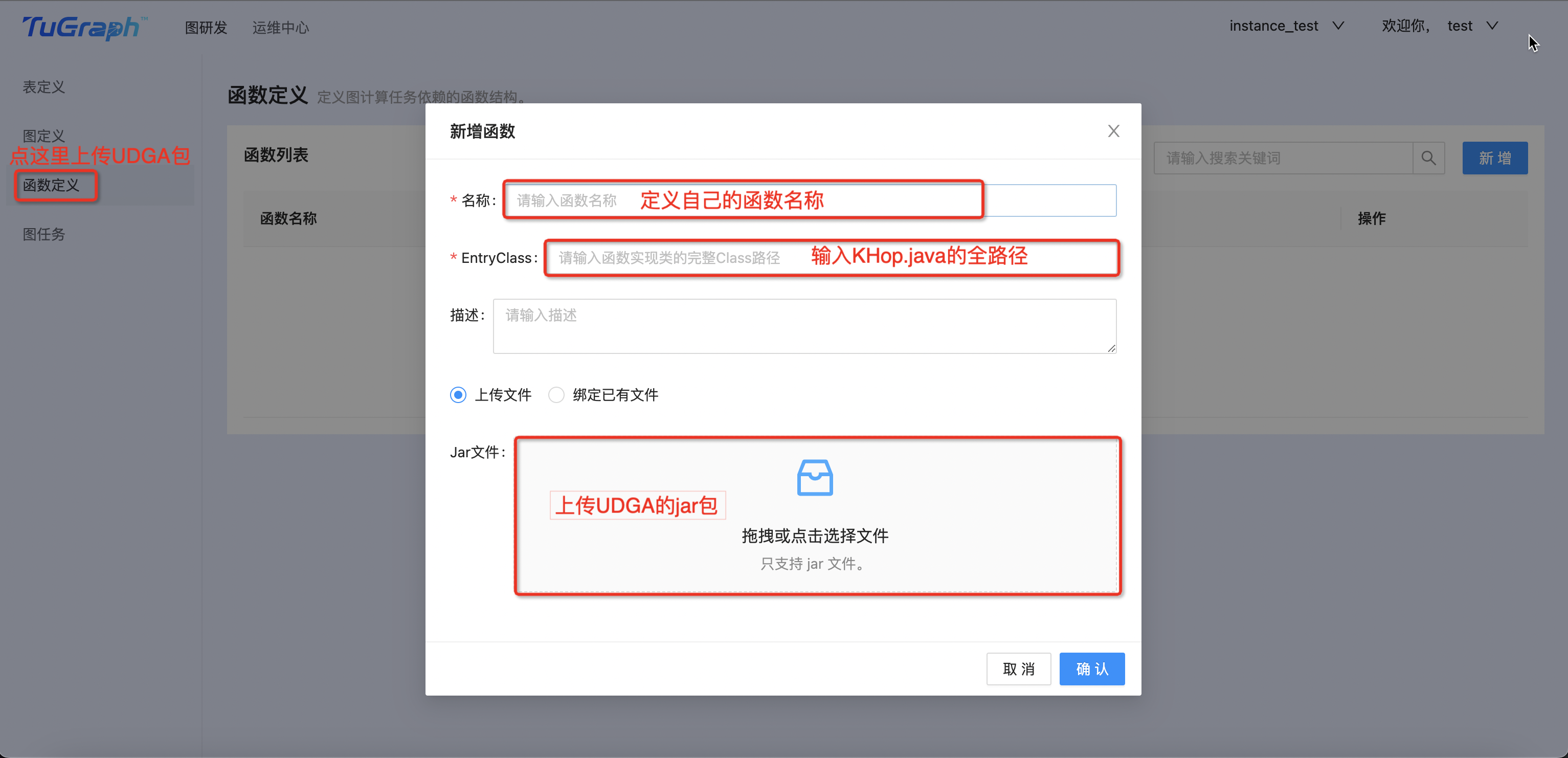
注册khop函数,并在DSL中使用
set geaflow.dsl.window.size = -1;
set geaflow.dsl.ignore.exception = true;CREATE GRAPH IF NOT EXISTS g (
Vertex v (
vid int ID,
vvalue int
),
Edge e (
srcId int SOURCE ID,
targetId int DESTINATION ID
)
) WITH (
storeType='rocksdb',
shardCount = 1
);CREATE TABLE IF NOT EXISTS v_source (
v_id int,
v_value int
) WITH (
type='file',
//vertex文件中保存了点的信息,文件放在与KHop类目录下的resources目录下,此处可以换成其他数据源
geaflow.dsl.file.path = 'resource:///input/vertex'
);CREATE TABLE IF NOT EXISTS e_source (
src_id int,
dst_id int
) WITH (
type='file',
//edge文件中保存了边的信息,文件放在与KHop类目录下的resources目录下,此处可以换成其他数据源
geaflow.dsl.file.path = 'resource:///input/edge'
);//定义结果表
CREATE TABLE IF NOT EXISTS tbl_result (
v_id int,
k_value int
) WITH (
type='file',
geaflow.dsl.file.path = '/tmp/result'
);USE GRAPH g;
INSERT INTO g.v(vid, vvalue)
SELECT
v_id, v_value
FROM v_source;INSERT INTO g.e(srcId, targetId)
SELECT
src_id, dst_id
FROM e_source;//注册khop函数
CREATE Function khop AS 'com.antfin.rayag.myUDF.KHop';
INSERT INTO tbl_result(v_id, k_value)
//调用khop函数,并返回结果
CALL khop(1,2) YIELD (vid, kValue)
RETURN vid, kValue
;
运行结果
输入数据如下
//vertex文件内容:
1,1
2,1
3,1
4,1
5,1
6,1
//edge文件内容:
1,3
1,5
1,6
2,3
3,4
4,1
4,6
5,4
5,6
在container的/tmp/result文件中可以得到结果如下
1,0
3,1
5,1
6,1
4,2至此,我们就成功使用Geaflow实现并运行了K-hop算法了!是不是超简单!快来试一试吧!