来源:SPIE Optical Engineering + Applications,2021 主讲人:Davi Lazzarotto 内容整理:王炅昊 对点云编码,作者提出了基于学习的残差编码模块,实现高效可伸缩的编码。类似于此前几个基于学习的压缩方法,他们也在一个分层框架中实现了这个方法,并且使用了 G-PCC 标准中的两个几何压缩模块(即 Octree 和 TriSoup)对该算法进行比较评估。
目录
- 引言
- 层级式编码
- 点云残差编码器
- 分析模块
- 潜在特征空间模块
- 解码端
- 损失函数
- 数据集和实验
- 参考文献
引言
最近,沉浸式媒体的呈现模态受到越来越多的关注,点云是其中的重要代表。然而,点云时常包含超过数百万个点,这增加了对高效压缩解决方案的需求。近来,深度学习用于点云压缩被不断研究,并成为点云压缩的重要工具,尤其是其较好的结果引起了编码社区的兴趣。然而,迄今为止提出的大多数解决方案都不支持可伸缩编码。
为了满足这一需求,我们在这里提出了一个基于学习的残差编码模块,可以在任何层级式框架内实现,从而实现高效和可伸缩的编码。JPEG Pleno Point Cloud 等标准化委员会最近将可伸缩性确定为几个潜在用例的重要要求。在已经提出的基于学习的点云压缩的众多解决方案中,三项重要的研究已经实现了可伸缩压缩。此外,还有另一项研究提出了用于二维图像的学习残差编码的概念。他们的方法已经以分层混合框架的形式被整合到传统编码标准 VVC 中。
我们的工作受到这项解决方案的启发,并提出了一种用于点云压缩的残差编码方法。我们也在分层框架中实现了这个方法,并且使用 G-PCC 标准中的两个几何压缩模块(即 Octree 和 TriSoup)对其进行评估。
层级式编码
分层编码方法是可伸缩的,因为它们允许对比特流进行部分解压缩。比特流本身由两个或多个子部分组成。第一个子部分的解码,这里我们称之为基本比特流(base bitstream),产生较低质量的表示。对剩余子部分的解码则将逐步提高该表示的精度。在分层框架中,这些子部分中的每一个都由不同的编码层生成。
随后作者展示了一个层级式编码的案例。从图中可以看出,红色的基本码流由基本层进行解码,得到相对粗糙的点云;随后,黄色的残差码流由残差层编码,在基本码流的基础上获得了更精细的点云数据。

层级式编码案例
作者在这个例子中展示的这个框架只有两层,但一个分层的框架理论上可以很多个层,以及多个对应的残差比特流。在这种情况下,每个残差比特流都会为之前解码的点云增加精细程度和质量。这种网络的整体架构如下图所示:
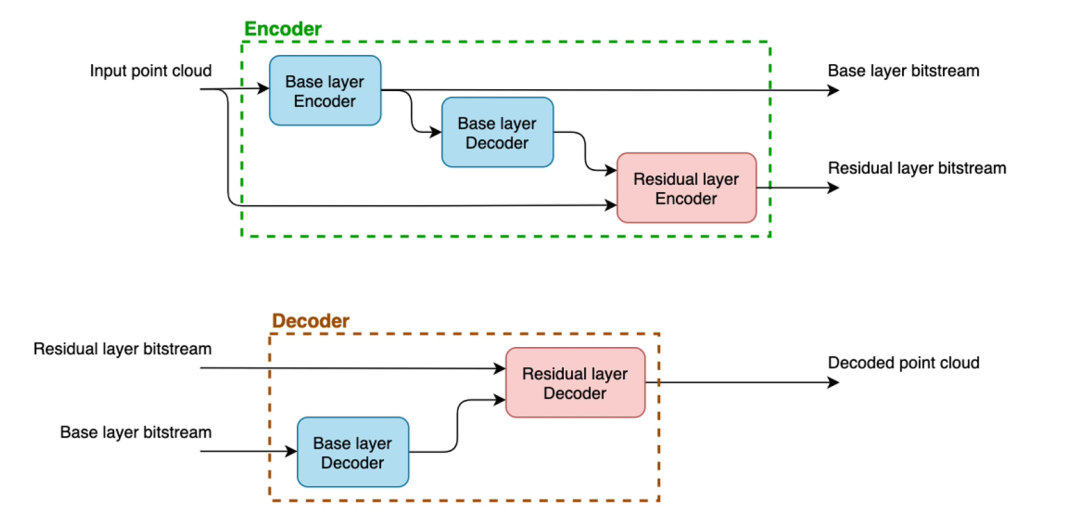
层级式编码结构
其中,在编码端,点云与基础层一起编码,生成基础层比特流。然后这个比特流在编码器站点被解码。残差层编码一个比特流,代表输入点云和之前解码的点云之间的差异。在解码器阶段,基础层解码基础比特流的第一个子部分,然后残差层接收解码后的较低质量表示以及残差压缩表示并对其进行进一步解码,生成最终的点云。
点云残差编码器
作者提出的方案扮演了分层框架中的残差层的角色。从理论上讲,它可以包含在任何框架中,包括具有两层的框架,更多具有多层的框架。在作者的研究中,我们使用两个不同标准中的编解码器作为两层框架中的基础层来实现。作者使用了来自 G-PCC 标准的 TriSoup 和 Octree 模块进行点云压缩,而他们的残差模块则依赖于具有 3D 卷积层的自动编码器架构。作者还提到,由于内存限制,他们无法将完整的高分辨率的点云作为输入,而是不得不将他们分块送入网络进行编解码。
作者提出的完整的残差编码器结构如下图所示:
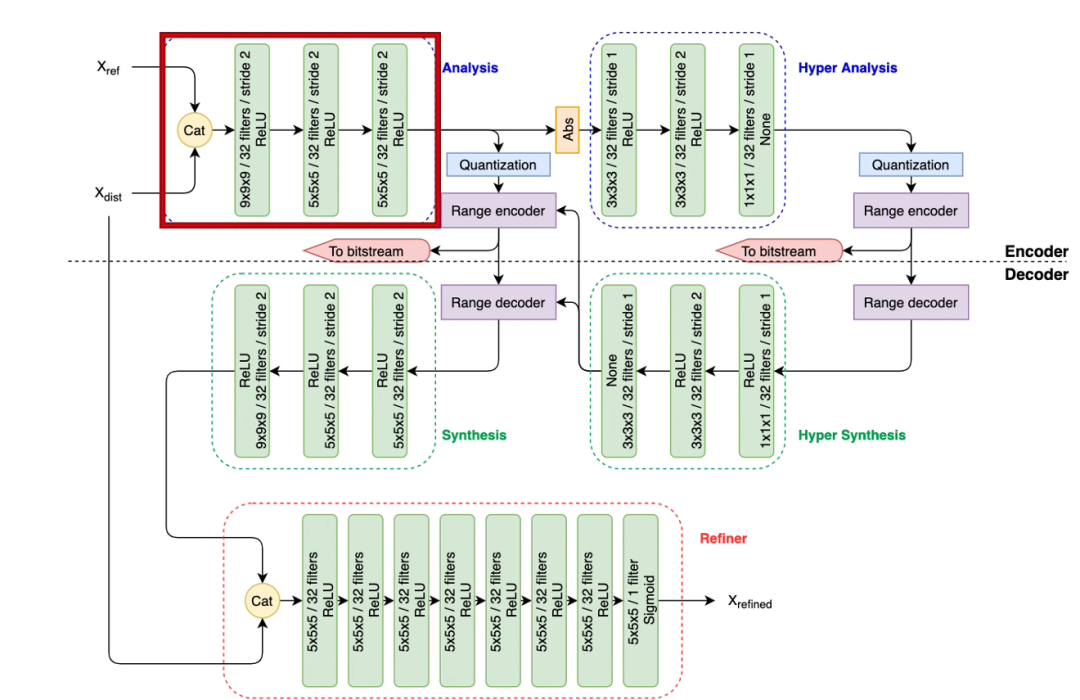
残差编码器的结构
分析模块
编码器的第一个模块是分析模块,他以原始的点云
和编码后的点云
的拼接作为输入,经过三层步长为 2 的神经网络层,将点云模块缩小到原来的 1/8。
潜在特征空间模块
接下来潜在特征空间块经过另一个自动编码器,在潜在空间中对其进行分析,用于计算他们的统计方差。该架构被称为超分析(Hyper Analysis)以及超合成(Hyper Synthesis),他们生成了一个超先验并被编码为额外信息(Side Information)。这个超先验同时用于量化主要特征块的熵编码和解码,它本身也是基于训练期间估计的分解概率分布的熵编码。解码器中的超级合成块,需要计算用于主要特征块的熵编码的比例索引,因此必须同时存在于编码和解码阶段。
在对超先验块和主特征块进行熵编码后生成的两个比特流,分别和一个字节串联在一起,每个字节表示它们各自的长度。它们同时还封装表示块在点云中位置的三个索引序列。最后,在将点云中所有块都压缩完了之后,他们对应的比特流将被连接在一起以构成整个点云模型的表示。
解码端
在解码器阶段,对压缩后的超先验进行熵解码,并用于获得主要特征块。然后,该块经过三个转置卷积层,生成具有 32 个通道且与输入
和
维度相同的潜在残差表示。该残差块在精炼器处与失真块
连接,在那里它使用 ReLU 激活函数提供七个卷积层的序列,最终输出优化后的块
。优化器(refiner)的最后一层异常地仅由一个过滤器组成,并使用 sigmoid 激活函数,以生成通道数与输入相同,并且值介于 0 和 1 之间的块。它对应于该位置体素被占用的概率。然后使用 0.5 作为阈值将这些概率值四舍五入为0或1,并且最终将获得的“占用块”转换回他们对应的坐标列表。在对所有块运行残差模块的解码器后,所有块将被按照比特流中包含的、他们对应的索引,整合到一个完整的点云中。
损失函数
由于作者提出的压缩方法是加法,因此需要一种率失真优化方法,这种优化则体现在网络的损失函数中。这个损失函数由一个拉格朗日乘数
来控制率和失真之间的权衡。

整体损失函数
值得注意的是,为了允许使用梯度下降法进行优化,在训练期间量化算子被加性均匀噪声代替。对于失真项的计算,作者将占用概率估计视为对每个体素单独求解的分类问题,然后使用 focal loss[1] 来估计每个体素的分类误差:

失真项 focal loss 的计算
其中
表示计算的占用概率,
表示体素的真实值。由于空体素通常比被占用体素更丰富,超参数
则惩罚被占用体素的错分类比空体素的错分类更多这种情况,来补偿这种类别不平衡。参数
则反过来负责纠正错误分类的体素,而不是最小化准确估计的误差。为了计算最终的
项,所有单个体素的 focal loss 通过加法操作并除以该块占用的体素数完成池化。
数据集和实验
作者使用了 HighResGC[2] 数据集,这个数据集由 50 个高分辨率的点云模型构成,作者使用其中 44 个作为训练集,剩余的 6 个作为测试集,并且他们都被以 9 或者 10 的位深度进行体素化。
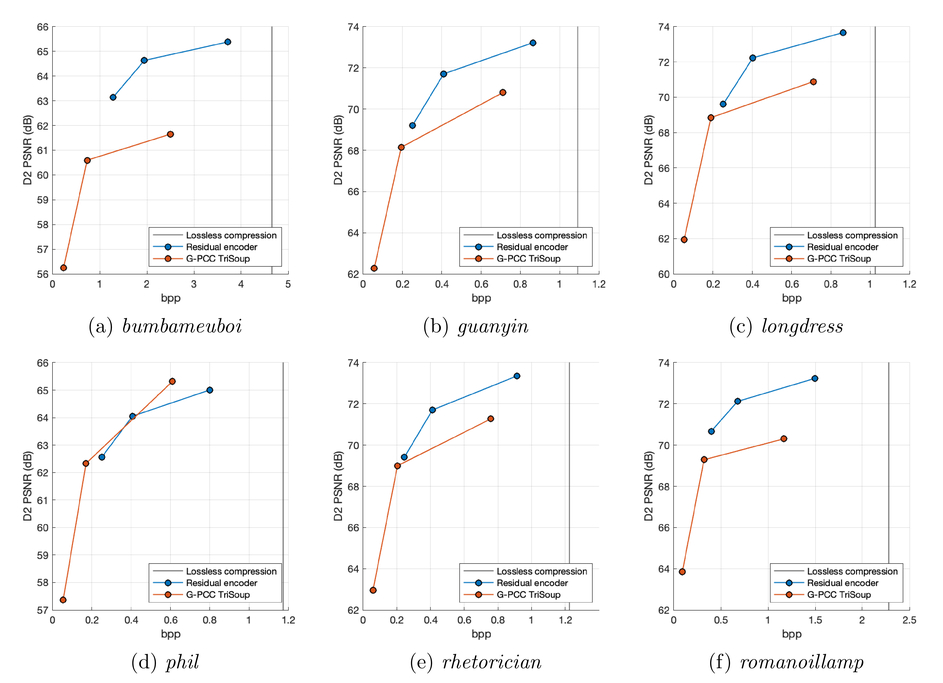
客观效果
由上图我们可以观察到,在大多数评估点上,提出的残差模块能够以增加比特率为代价来提高质量,当使用压缩级别 R3 和前两个
值时。除了 Phil 数据之外,对于测试集的所有其他模型,添加我们的残差结果会在等效甚至更低的比特率水平下减少失真。例如,值得一提的是,对于除 phil 之外的所有测试集,我们的模块在
= 10 和压缩级别 R2 下训练产生比基础层 R3 级别更高的 D2 PSNR 级别,并且比特率较低。然而,我们观察到一些用
= 50 和
= 100 训练的模块导致比特率超过无损阈值,使所提出的方法的所有优势无效。为了避免这种情况,他们为每个压缩级别选择一个
值。具体而言,他们为 R1,R2,R3 分别选择了
= 5, 10 和 25。其相应的率失真图如下所示:
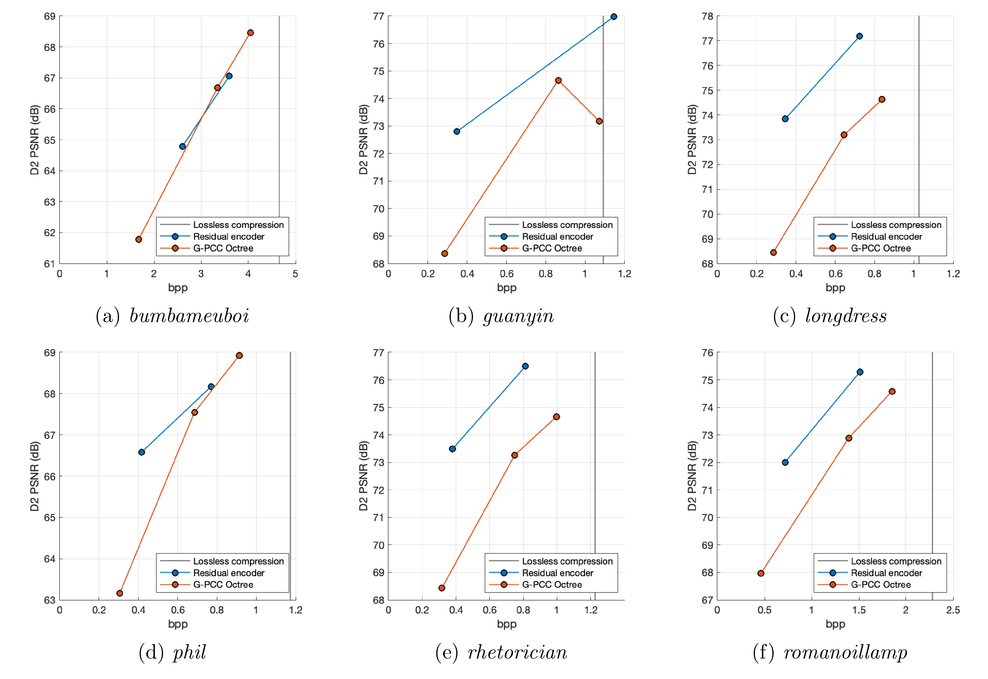
设置
的客观效果
他们同时展示了在几个点云模型上的主观结果,可以看到他们的模型在平均较低的码率下,主观上比其他的编解码方法看更加精细。

主观效果展示
附上演讲视频:
参考文献
[1] Lin, T., Goyal, P., Girshick, R., He, K., and Dollar, P., “Focal loss for dense object detection,” in 2017 IEEE International Conference on Computer Vision (ICCV), (2017). [2] Alexiou, E., Tung, K., and Ebrahimi, T., “Towards neural network approaches for point cloud compression,” Applications of Digital Image Processing XLIII, 4 (2020)