roc,腾讯高级工程师,Kubernetes Contributor,热爱开源,专注云原生领域。目前主要负责腾讯云TKE 的售中、售后的技术支持,根据客户需求输出合理技术方案与最佳实践,为客户业务保驾护航。
概述
本文介绍如何利用腾讯云容器服务 TKE 的日志功能对日志进行采集、存储与查询,分析各种功能用法与场景,给出一些最佳实践建议。
注: 本文仅适用于 TKE 集群。
如何快速上手 ?
TKE 的日志功能入口在 集群运维-日志规则,更多关于如何为 TKE 集群启用日志采集与基础用法,参考TKE日志采集产品文档: https://cloud.tencent.com/document/product/457/36771。
技术架构是怎样的 ?
TKE 集群开启日志采集后,tke-log-agent 作为 DaemonSet 部署在每个节点上,负责根据采集规则采集节点上容器的日志,然后上报到 CLS 日志服务,由 CLS 进行统一存储、检索与分析:

采集哪里的日志 ?
在 TKE 使用日志采集时,需要在 集群运维-日志规则 里新建日志采集规则,首先需要确定采集的目标数据源是什么,下面介绍支持的 3 种类型数据源及其各自使用场景与建议。
采集标准输出
最简单也是最推荐的方式是将 Pod 内容器的日志输出到标准输出,日志内容就会由容器运行时 (docker, containerd) 来管理,有以下几点好处:
- 不需要额外挂载 volume。
- 可以直接通过
kubectl logs查看日志内容。 - 业务不需要关心日志轮转,容器运行时会对日志进行存储和自动轮转,避免因个别 Pod 日志量大将磁盘写满。
- 不需要关心日志文件路径,可以使用比较统一的采集规则,用更少的采集规则数量覆盖更多的工作负载,减少运维复杂度。
采集配置示例:
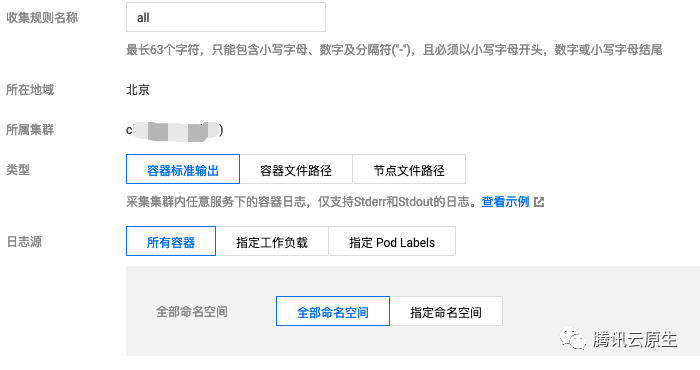
采集容器内的文件
很多时候业务通过写日志文件的方式来记录日志,使用容器跑业务时,日志文件被写到容器内:
- 如果日志文件所在路径没有挂载 volume,日志文件会被写入容器可写层,落盘到容器数据盘里,通常路径是
/var/lib/docker(建议给此路径挂盘,避免与系统盘混用),容器停止后日志会被清理。 - 如果日志文件所在路径挂载了 volume,日志文件会落盘到对应 volume 类型的后端存储;通常用 emptydir,容器停止后日志会被清理,运行期间日志文件会落盘到宿主机的
/var/lib/kubelet路径下,此路径通常没有单独挂盘,也就是会使用系统盘;由于使用了日志采集,有统一存储的能力,不推荐再挂载其它持久化存储来存日志文件(如云硬盘CBS, 对象存储COS, 共享存储CFS)。
许多开源日志采集器需要给 Pod 日志文件路径挂载 volume 才能采集,使用 TKE 的日志采集则不需要,所以如果将日志输出到容器内的文件里,不需要关心是否挂载 volume。
采集配置示例:

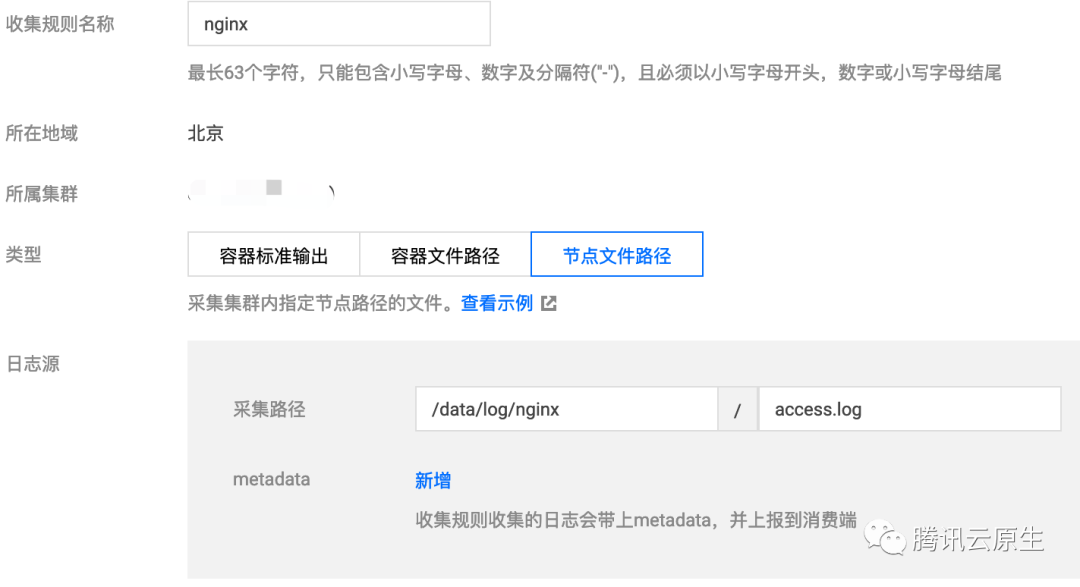
采集宿主机上的文件
如果业务将日志写入日志文件,但又想容器停止之后还能保留原始日志文件,好有个备份,避免采集异常时导致日志完全丢失,这时可以给日志文件路径挂载 hostPath,日志文件会落盘到宿主机指定目录,并且容器停止后不会清理日志文件。
由于不会自动清理日志文件,有同学就可能会担心日志会被重复采集,比如 Pod 调度走又调度回来,日志文件被写在之前相同路径。是否会重复采集,这里分两种情况:
- 文件名相同,比如固定文件路径
/data/log/nginx/access.log。此时不会重复采集,因为采集器会记住之前采集过的日志文件的位点,只采集增量部分。 - 文件名不同,通常是业务用的日志框架会按照一定时间周期自动进行日志轮转,一般是按天轮转,自动为旧日志文件进行重命名,加上时间戳后缀。如果采集规则里使用了 "*" 作为通配符匹配日志文件名,可能就会重复采集,因为日志框架对日志文件重命名后,采集器就会认为匹配到了新写入的日志文件,就又对其进行采集一次。
所以,一般不会重复采集,如果日志框架会对日志进行自动轮转,建议采集规则不要使用通配符 "*" 来匹配日志文件。
采集配置示例:
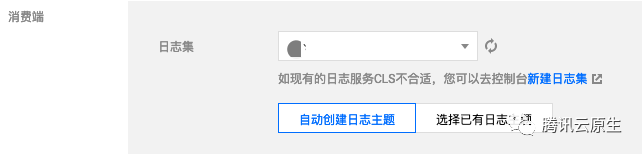
日志吐到哪里 ?
知道了采集哪里的数据之后,我们还需要知道采集到的日志往哪里存。根据前面讲的技术架构可以知道,TKE 日志采集与云上的 CLS 日志服务集成,日志数据也将统一上报到日志服务。日志服务通过日志集和日志主题来对日志进行管理,日志集是 CLS 的项目管理单元,可以包含多个日志主题;一般将同一个业务的日志放在一个同一日志集,同一业务中的同一类的应用或服务使用相同日志主题,在 TKE 中,日志采集规则与日志主题是一一对应的;TKE 创建日志采集规则时选择消费端,就需要指定日志集与日志主题,日志集通常提前创建好,日志主题通常选择自动创建:
创建好后可以根据情况对自动创建的日志主题进行重命名,方便后续检索时找到日志所在的日志主题:

如何配置日志格式解析 ?
有了日志的原始数据,我们还需要告诉日志服务如何去解析日志,以方便后续对其进行检索。在创建日志采集规则时,需要配置日志的解析格式,下面针对各项配置给出分析与建议。
使用哪种抓取模式 ?
首先,我们需要确定日志的抓取模式,支持 5 种:单行文本、JSON、分隔符、多行文本和完全正则。
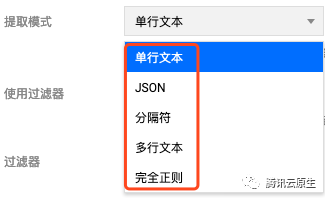
推荐使用 JSON,因为 JSON 格式本身就将日志给结构化了,日志服务可以提取 JSON 的 key 作为字段名,value 作为对应的字段值,不再需要根据业务日志输出格式配置复杂的匹配规则,日志示例:
{"remote_ip":"10.135.46.111","time_local":"22/Jan/2019:19:19:34 +0800","body_sent":23,"responsetime":0.232,"upstreamtime":"0.232","upstreamhost":"unix:/tmp/php-cgi.sock","http_host":"127.0.0.1","method":"POST","url":"/event/dispatch","request":"POST /event/dispatch HTTP/1.1","xff":"-","referer":"http://127.0.0.1/my/course/4","agent":"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:64.0) Gecko/20100101 Firefox/64.0","response_code":"200"}使用 JSON 抓取模式的前提是业务的日志本身是以 JSON 格式输出的,如果不是 JSON 格式,但切换到使用 JSON 格式输出成本不大,就建议进行切换,如果实在不好切换,再考虑其它抓取模式。
如果日志内容是以固定格式输出的单行文本,考虑使用 "分隔符" 或 "完全正则" 抓取模式。"分隔符" 适用简单格式,日志中每个字段值都以固定的字符串分隔开,比如用 ":::" 隔开,某一条日志内容是:
10.20.20.10 ::: [Tue Jan 22 14:49:45 CST 2019 +0800] ::: GET /online/sample HTTP/1.1 ::: 127.0.0.1 ::: 200 ::: 647 ::: 35 ::: http://127.0.0.1/可以配置 ":::" 自定义分隔符,并且为每个字段按顺序配置字段名,示例:

"完全正则" 适用复杂格式,使用正则表达式来匹配日志的格式。如日志内容为:
10.135.46.111 - - [22/Jan/2019:19:19:30 +0800] "GET /my/course/1 HTTP/1.1" 127.0.0.1 200 782 9703 "http://127.0.0.1/course/explore?filter%5Btype%5D=all&filter%5Bprice%5D=all&filter%5BcurrentLevelId%5D=all&orderBy=studentNum" "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:64.0) Gecko/20100101 Firefox/64.0" 0.354 0.354正则表达式就可以设置为:
(\S+)[^\[]+(\[[^:]+:\d+:\d+:\d+\s\S+)\s"(\w+)\s(\S+)\s([^"]+)"\s(\S+)\s(\d+)\s(\d+)\s(\d+)\s"([^"]+)"\s"([^"]+)"\s+(\S+)\s(\S+).*日志服务会使用 () 捕获组来区分每个字段,我们还需要为每个字段设置字段名,配置示例:
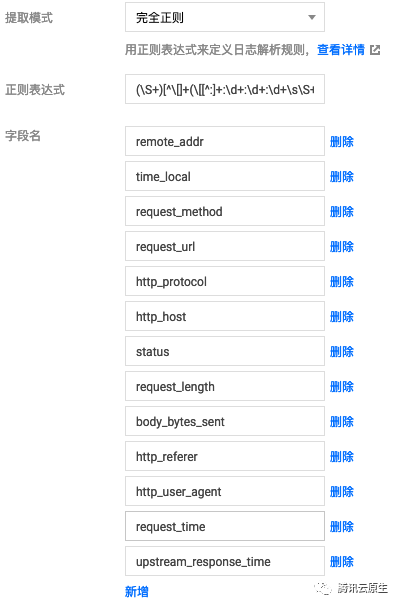
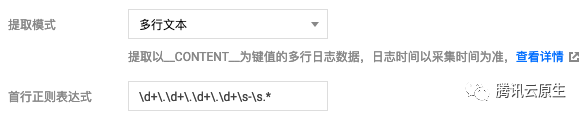
如果日志没有固定的输出格式,则考虑使用 "单行文本" 或 "多行文本" 的抓取模式。使用这两种模式,不会对日志内容本身进行结构化处理,不会提取日志字段,每条日志的时间戳也固定由日志采集的时间决定,检索的时候也只能进行简单的模糊查询。这两种模式的区别在于日志内容是单行还是多行,如果是单行最简单,不需要设置任何匹配条件,每行都是一条单独的日志;如果是多行则需要设置首行正则表达式,也就是匹配每条日志第一行的正则,当某行日志匹配上预先设置的首行正则表达式,就认为是一条日志的开头,而下一个行首出现作为该条日志的结束标识符。假如多行日志内容是:
10.20.20.10 - - [Tue Jan 22 14:24:03 CST 2019 +0800] GET /online/sample HTTP/1.1 127.0.0.1 200 628 35 http://127.0.0.1/group/1
Mozilla/5.0 (Windows NT 10.0; WOW64; rv:64.0) Gecko/20100101 Firefox/64.0 0.310 0.310那么首行正则表达式就可以设置为: \d+\.\d+\.\d+\.\d+\s-\s.*
如何过滤掉不需要的内容 ?
有些不重要或不关心的日志可以选择将其过滤掉,降低成本。
如果使用 "JSON"、"分隔符" 或 "完全正则" 的抓取模式,日志内容会进行结构化处理,可以通过指定字段来对要保留的日志进行正则匹配:

对于 "单行文本" 和 "多行文本" 抓取模式,由于日志内容没有进行结构化处理,无法指定字段来过滤,通常直接使用正则来对要保留的完整日志内容进行模糊匹配:

需要注意的是,匹配内容一定记住是用正则而不是完整匹配,比如想只保留 a.test.com 域名的日志,匹配的表达式应该写 a\.test\.com 而不是 a.test.com。
日志时间戳如何自定义 ?
每条日志都需要有个时间戳,这个时间戳主要用于检索,在检索的时候可以选择时间范围。默认情况下,日志的时间戳由采集的时间决定,也可以进行自定义,选择某个字段作为时间戳,这样在某些情况下可能更精确些,比如在创建采集规则之前,服务已经运行了一段时间,如果不设置自定义时间格式,采集时会将之前的旧日志的时间戳设置为当前的时间,导致时间不准确。
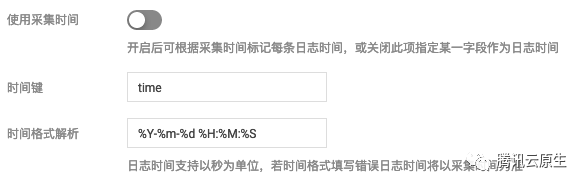
如何进行自定义呢?由于 "单行文本" 和 "多行文本" 抓取模式不会对日志内容进行结构化处理,也就没有字段可以指定为时间戳,无法自定义时间格式解析。其它的抓取模式都可以支持,具体做法是关闭 "使用采集时间",然后选取要作为时间戳的字段名称,并配置时间格式。
假如使用日志的 time 字段作为时间戳,其中一条日志 time 的值为 2020-09-22 18:18:18,时间格式就可以设置为 %Y-%m-%d %H:%M:%S, 示例:
更多时间格式配置参考日志服务官方文档 配置时间格式:https://cloud.tencent.com/document/product/614/38614。
需要注意的是,日志服务时间戳暂时只支持精确到秒,也就是如果业务日志的时间戳字段精确到了毫秒,将无法使用自定义时间戳,只能使用默认的采集时间作为时间戳,不过时间戳精确到毫秒后续将会得到支持。
如何查询日志 ?
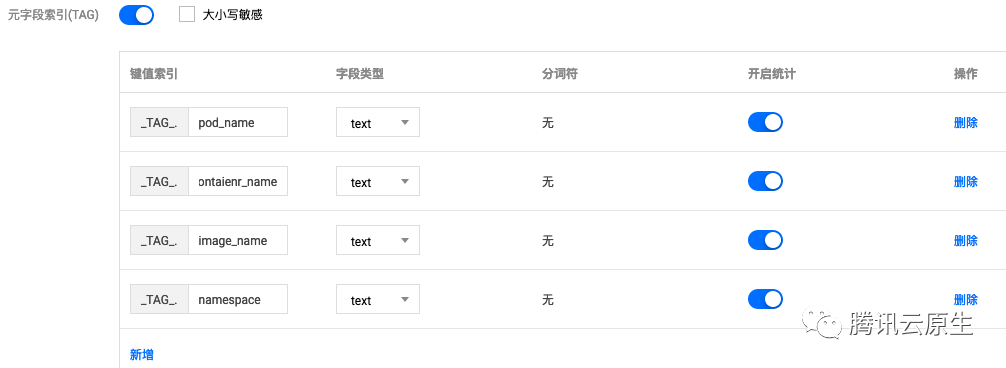
日志采集规则配好了,采集器就会自动开始采集日志并上报到日志服务,然后就可以在 日志服务-检索分析 中查询日志了,支持 Lucene 语法,但前提是需要开启索引,有以下 3 类索引:
- 全文索引。用于模糊搜索,不用指定字段。

- 键值索引。索引结构化处理过的日志内容,可以指定日志字段进行检索。

- 元字段索引。上报日志时额外自动附加的一些字段,比如 pod 名称、namespace 等,方便检索时指定这些字段进行检索。
查询示例:
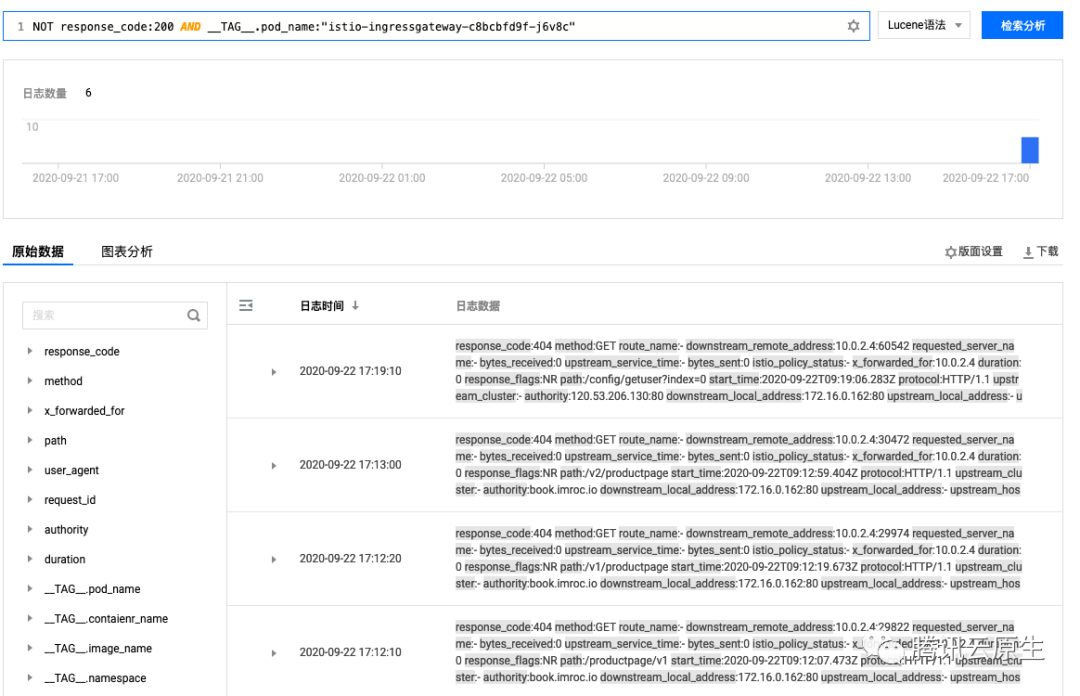
如何将日志投递到其它地方 ?
日志服务支持将日志投递到 COS 对象存储和 Ckafka (腾讯云托管的 Kafka),可以在日志主题里设置投递:

可以用在以下场景:
- 对日志数据进行长期归档存储。日志集默认存储 7 天的日志数据,可以调整时长,但数据量越大,成本就越高,通常只保留几天的数据,如果需要将日志存更长时间,可以投递到 COS 进行低成本存储。
- 需要对日志进行进一步处理 (如离线计算),可以投递到 COS 或 Ckafka,由其它程序消费来处理。
参考资料
- TKE 日志采集用法指引: https://cloud.tencent.com/document/product/457/36771
- 日志服务配置时间格式: https://cloud.tencent.com/document/product/614/38614
- 日志服务投递 COS: https://cloud.tencent.com/document/product/614/37908
- 日志服务投递 Ckafka: https://cloud.tencent.com/document/product/614/33342
回答问题拿礼物啦

当当当~首先恭喜翻到最后的小伙伴
今日学习任务圆满达成!!!

为了帮助你巩固本次学习
作者大大精心准备了以下几个问题
正在等待你的回答

留言板评论【问题编号+你的答案】
每个问题将会由作者评选出一名最佳答主
并送上QQ公仔一只

还等什么,快来挑个问题回答吧~
问题1:采集容器内的文件是否需要挂载 volume ? 问题2:如果要根据 Pod 名称过滤日志,需要在日志服务开启什么索引 ?
问题3:如果还需要将日志进行一些复杂的离线计算(分析统计),应该怎么做 ?
截止时间:2020年10月20日18点
