
作者 | 卢冕,第四范式开源机器学习数据库 OpenMLDB PMC core member
策划 | 刘燕
在机器学习从开发到上线的闭环中,实时特征计算是其中的重要一环,用于完成数据的实时特征加工。由于其高时效性需求,数据科学家完成特征脚本离线开发以后,往往还需要工程化团队通过大量的优化才能完成上线。另一方面,由于存在离线开发和工程化上线两个流程,线上线下计算一致性验证成为一个必要步骤,并且会耗费大量的时间和人力。
本文将从以上两个痛点出发,描述实时特征计算系统架构的优化目标 - 开发即上线,以及针对此优化目标的架构设计原则。最后,将会基于开源实时特征计算解决方案 OpenMLDB,具体描述其在实践中的架构设计和优化。
背景介绍
机器学习闭环
今天,机器学习应用已经在各行各业积累了广泛的应用落地案例。归纳来说,机器学习从开发到上线的全生命周期闭环可以用下图(Figure-1)概括性描述。

Figure-1: 机器学习闭环
从 Figure-1 可以看到,从横向维度,机器学习全流程被划分成离线开发和线上服务两个相辅相成的流程。从纵向维度,信息价值承载的形式会经历从数据、特征、再到模型的转换过程。
- 数据:原始的数据信息,比如交易的流水信息,包含金额、时间、商户名称等。
- 特征:基于原始数据所生产计算的表达能力更为丰富的信息,有利于产出后续质量更高的模型,比如某客户在过去三个月内的消费平均金额等特征。本文即针对特征计算的工程化问题详细展开讨论。
- 模型:通过隐含的上万甚至上亿条基于特征生成的数据规则,从超高维度上来描述数据本质的规律,包含了基于数据预测行为的能力。今天,对于数据和模型,已经有了充分的讨论和事实上的工业界标准处理方式。但是对于特征,今天工业界还并没有形成统一的方法论和处理工具。这主要因为,在人工智能开始应用落地的初期,大家的关注点都在基于深度学习的感知类应用上,此类应用的特征工程流程相对标准。但今天,决策类场景(如风控、个性化推荐等)在大量企业级应用落地。
对于决策类场景,特征工程的处理逻辑相对灵活和复杂,因此在这一块目前尚未形成标准化的方法论和工具。这也正是本文所要聚焦的领域,通过从设计方法论和架构设计实践的阐述,让大家深刻理解实时特征计算系统及其典型使用流程。
实时特征计算
本文主要关注具有非常强时效性的实时特征计算,其查询计算的端到端延迟一般设定在几十毫秒的量级。实时特征的常见计算模式,是当事件发生时,基于从当前时间点往前推移的一个时间点,形成一个时间窗口,进行窗口内的相关聚合计算。
如下图 Figure-2 列举了一个典型的风控领域的实时特征计算场景,其产生了十天、一个小时、五分钟三个时间窗口,基于窗口进行了不同的聚合计算。

图片 Figure-2: 风控领域的典型实时特征计算举例
实时特征计算今天已经在越来越多的场景中体现出其重要性,其本质在于抓住最新时间段内的数据特征,为快速决策提供有力支撑。本文主要针对实时特征计算,来进行相关设计理念和架构的阐述。
线上线下计算一致性架构
痛点:两套开发流程和线上线下计算一致性校验
今天,在没有一套合适的方法论和工具链的情况下,如果需要开发上线一套实时特征计算逻辑,主要包含三个步骤,即离线特征脚本开发、在线特征代码重构、以及线上线下计算逻辑一致性校验。其三者的关系如下图 Figure-3 所示。

Figure-3: 在缺少合适的工具情况下的实时特征计算从开发到上线全流程
这三个步骤主要完成的任务以及参与者见下方表格 Table-1。从 Table-1 中可以看到几个关键信息:
- 由于数据科学家一般习惯使用 Python 等数据分析工具进行特征脚本开发,其开发的模型一般无法符合实时特征计算的上线需求,如低延迟、高吞吐、高可用等性能和运维指标均无法满足。
- 由于数据科学家和工程化团队是两个团队、两条工具链、两套系统的开发,因此两套系统之间的计算一致性校验就变得必不可少而且非常重要。
- 根据大量工程化落地案例,一致性校验由于需要牵涉到团队沟通、需求对齐、反复测试确认等,其花费的人力成本往往是三个步骤间最高的。


Table 1: 在缺少合适工具情况下的实时特征计算从开发到上线的主要步骤
造成线上线下计算逻辑不一致的原因有很多种,比如:
- 工具能力不对等。现在,Python 是大部分数据科学家的首选工具;相反,工程化团队一般会首先尝试使用一些高性能数据库去翻译 Python 脚本。因此两个工具在表达能力上并不对等。当 SQL 的表达能力无法满足需求时,就可能会出现计算逻辑上的妥协或者使用 C/C++ 等高性能编程语言去补充相关能力。
- 需求沟通的认知差。数据科学家以及工程化团队对于数据的定义和处理方式的认知可能会不一致。美国的一家线上银行 Varo Bank 描述了一个他们在没有合适工具的情况下,实时特征上线时碰到的一个不一致场景(具体可以参照他们工程化团队的博客 Feature Store: Challenges and Considerations)。在上线环境中,工程化团队很自然的认为“账户余额”的定义应该就是实时的账户里的余额;但对于数据科学家来说,通过离线的数据去构建“实时账户余额”其实是一件相当复杂的事情,因此数据科学家使用了一个更加简单的定义,即昨天结束的时候的账户的余额。很明显,两者对于账户余额的认知差,直接造成了线上线下计算逻辑的不一致性。线上线下计算逻辑一致性校验的必要性,以及所需要花费的巨大人力成本,使我们有必要重新审视特征计算从开发到上线的全流程。需要一套更为合理的生命周期方法论,以及相应的架构设计,来高效支撑今天急速增长的机器学习落地场景数量和规模。
目标:开发即上线
我们已经认识到,线上线下计算一致性校验是整个系统实现和实施的瓶颈。那么理想中,如果需要改进整体流程,我们期望有一套开发即上线的高效流程。其如下图 Figure-4 所示。
在此套优化过的流程中,数据科学家的脚本可以即刻部署上线,而不需要再经过二次代码重构,也不需要额外的线上线下一致性校验。如果基于此流程的方法论可以实现,将会极大地提高实时特征从开发到上线的整体流程,其人力成本也将会从过去的一共 8 人 月大幅缩短到 1 人 月。
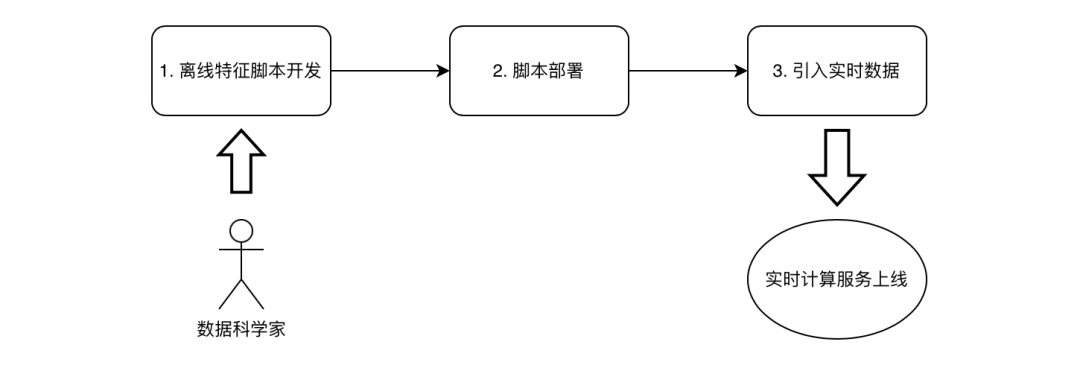
图片 Figure-4: 实时特征计算开发周期的优化目标:开发即上线流程
2.3. 技术需求
如果为了达到开发即上线的优化目标,同时要保证实时计算的高性能,可以总结出整套架构需要满足如下的技术需求:
- 需求一:在线实时特征计算的低延迟、高并发。如果我们期望在优化后的流程中(Figure-4),数据科学家的脚本可以直接上线,那么我们必须要非常小心的处理好在线计算的一系列工程化问题。其最主要的需求是满足低延迟、高并发的实时计算需求;此外,如可靠性、可扩展性、灾备、运维等问题亦是在企业生产环境中实际落地需要特别关注的特性。很显然,如果仅仅依靠数据科学教使用 Python 写的特征计算脚本来直接上线,是不能满足这些条件的。
- 需求二:线上线下统一的编程接口。为了降低整体开发到上线的成本,我们期望在对外用户的视角来看,整个系统需要一个统一的对外编程接口,而不是如 Table-1 中所示,对外暴露了两套不同的编程接口。基于统一的编程接口,那么不再需要通过代码重构来进行脚本上线。
- 需求三:线上线下计算一致性保证。我们的优化目标是不再需要额外的高成本的线上线下一致性校验。那么,如何在系统内部保证好线上线下的计算一致性,是必须要解决的问题。
抽象架构

Figure-5: 开发即上线的实时特征平台的抽象架构
为了满足在章节 2.3 里提到的三个技术需求,我们构建出了如上 Figure-5 的抽象架构。可以看到,在这个抽象架构图里有三大模块,分别对应去解决我们所面临的的技术挑战。
以下表格列出了模块的功能要点以及所解决的技术需求。

Table-2: 实时特征计算平台架构的核心模块和功能
OpenMLDB 的架构设计实践
基于如上分析的 Figure-5 的抽象架构,以及 Table-2 所列举的核心模块功能,我们在此介绍一下 OpenMLDB 的架构实践。
OpenMLDB (https://github.com/4paradigm/OpenMLDB) 是一款开源机器学习数据库,主要面向特征计算场景构建高效解决方案。
OpenMLDB 的架构设计上秉承了 Figure-5 所列的抽象架构,通过基于现有开源软件优化或者自研,来实现具体的功能。其具象化以后的架构如下图 Figure-6 所示。

图片 Figure-6: OpenMLDB 整体架构
从架构图 Figure-6 上可以看到,OpenMLDB 有几个关键模块,说明如下:
- SQL(+):OpenMLDB 对外暴露 SQL 作为统一的使用接口。由于标准 SQL 并没有对特征计算相关的操作做优化(如时序窗口相关操作),因此其在标准 SQL 的基础上做了功能扩展,支持了更多对于特征计算友好的语法功能。
- 一致性执行计划生成器:这是保障线上线下计算逻辑一致性的核心模块。里面主要包含了 SQL 语法树解析以及基于 LLVM 的执行计划生成模块。其中,统一的执行计划生成模块,对于给定的 SQL,可以翻译成针对线上和线下分别优化的不同的执行计划,但是同时保证两者的计算一致性。
- 分布式批处理 SQL 引擎 Spark(+):对于面向离线开发的批处理 SQL 引擎,OpenMLDB 基于 Spark 进行了源代码级别的二次优化开发,高效支持 SQL 中对于特征计算的扩展语法。注意,由于批处理引擎实质上并没有任何数据的存储需求,所以这里在逻辑上并不包含一个专用的存储引擎,只需从离线数据源上去读取数据进行计算即可。
- 分布式时序数据库:核心的实时计算功能主要由存储引擎和实时 SQL 引擎这两个核心模块承载,共同组成了一个分布式的高性能时序数据库。其中,SQL 引擎为开发团队自研的基于 C++ 编写的高性能内核;数据存储引擎主要为了存储特征计算所需要的最新的窗口数据(即 Figure-2 中的物料数据)。注意,此处的时序数据库有一个数据生存周期的概念(TTL, Time-To-Live),假设我们的特征计算逻辑只需要最近三个月的数据,那么超过三个月的旧数据会自动被清除。存储引擎有两种选择:
一是,开发团队自研的内存存储引擎(built-in):OpenMLDB 为了优化在线处理的延迟和吞吐,默认采用了基于内存的存储方案,构建了双层跳表(double-layered skip list)的索引结构。此种数据结构特别适合快速找到某个 key 下面的一个按照时间戳排序的数据。此种内存索引结构在时序数据的查找延迟上可以达到毫秒级别 [1],并且性能远好于商业版的内存数据库;二是,基于 RocksDB 的外存存储引擎:如果用户对于性能不太敏感,但是希望降低内存用成本,用户亦可以选择基于 RocksDB 的外存存储引擎。通过以上核心组件的串联,OpenMLDB 可以实现开发即上线的最终优化目标。
下图 Figure-7 总结了 OpenMLDB 从离线开发到部署上线的整体使用流程。对照 Figure-4 所对应的优化流程目标,我们可以发现,通过 OpenMLDB,从特征开发到上线,很好地践行了开发即上线的核心思想。

图片 Figure-7: OpenMLDB 使用流程
关于 OpenMLDB 的详细信息可以参考以下内容:
- 官网:https://openmldb.ai/
- GitHub: https://github.com/4paradigm/OpenMLDB
- Docs: https://openmldb.ai/docs/zh/
总 结
本文总结了构建实时特征计算平台所面临的工程化挑战,以及工业界所期望的从离线开发到上线的优化目标。基于目标,展开描述了架构设计的方法论和原则。最后介绍了从优化目标出发,基于设计方法论实践的开源解决方案 OpenMLDB 的整体架构。
参考:
[1] Cheng Chen, Jun Yang, Mian Lu, Taize Wang, Zhao Zheng, Yuqiang Chen, Wenyuan Dai, Bingsheng He, Weng-Fai Wong, Guoan Wu, Yuping Zhao, and Andy Rudoff. Optimizing in-memory database engine for AI-powered on-line decision augmentation using persistent memory. International Conference on Very Large Data Bases (VLDB) 2021.
作者介绍:
卢冕,博士毕业于香港科技大学计算机系;现为 OpenMLDB 社区 PMC core member;就职于第四范式,是数据库团队以及高性能计算团队的 Tech Lead。