作者:黄龙,腾讯 CSIG 高级工程师
数据时代,企业对技术创新和服务水准的要求不断提高,数据已成为企业极其重要的资产。无论是在在企业数据中台的建设,亦或者是打造一站式数据开发和数据治理的PASS平台。首先需要做的就是进行跨应用的数据融合计算,需要将数据从孤立的数据源中采集出来,汇集到可被计算平台高效访问的目的地。此过程称之为ETL。通常所说的同步大致分为离线全量ETL、离线增量+离线全量的ETL、实时增量+离线全量ETL、实时增量ETL4种方式。数据同步成为企业数据开发和使用一个绕不过去的技术需求。业内也存在大量的开源的解决方案。在数据集成技术选型中,我们需要考虑的因素有哪些?主流开源方案中各自的优缺点有哪些?目前备受瞩目和推崇 Flink CDC ETL 是否能作为线上主力同步工具之一,它的优势有哪些?原理是什么?本文主要围绕以上几个疑问,进行论述。
1. 如何做好数据集成技术选型
常见的数据同步常包含以下场景:
- 数据库的备份,容灾
- 业务系统经常会遇到需要更新数据到多个存储的需求
- 面向数仓/数据湖的ETL数据集成
在面对众多开源的数据同步产品工具时,我们如何做好技术选型,以及我们评判的标准或者说打分项有哪些?这里先按照通用的准则列举如下:
- 是否支持增量+全量的数据同步能力
- 同步的机制是什么?基于日志还是基于查询
- 是否支持分布式的数据接入能力
- 数据转换 / 数据清洗能力
- 数据一致性的保证
- 系统的复杂度,包含使用复杂度。
- 数据同步链路( 更长的链路一般意味着,风险增高以及监控成本增加 )
- 生态的丰富性
- 是否对线上生产环境产生大的影响
- 社区的活跃度,商业化的使用案例
基于以上的考量,再回到本文的想要表达的中心议题,我们想了解一下,Flink CDC 作为孵化才一年多的项目,为何在如此短的时间内受到如此多的关注以及如此迅猛发展 ?它是解决了数据同步场景的那些问题 ?有哪些优势 ?原理是什么?以及为何建议作为数据同步场景下的主力生产工具之一 ?
2. CDC 技术介绍
1. 定义
CDC 的全称是 Change Data Capture ,在广义的概念上,只要是能捕获数据变更的技术,我们都可以称之为 CDC。目前通常描述的 CDC 技术主要面向数据库的变更,是一种用于捕获数据库中数据变更的技术。CDC大体分为两种:侵入式和非侵入式。侵入式指 CDC 操作会给源系统带来性能影响,只要 CDC 操作以任何一种方式对源数据库执行了SQL 操作,就认为是侵入式的。一般基于查询的实现机制都归纳为入侵式,例如 DataX,Sqoop。基于日志的实现机制都归纳到非侵入式,典型的有 Canal,Debezium。
2. 主流的实现机制
CDC 的技术方案非常多,目前业界主流的实现机制可以分为两种:
- 基于查询的 CDC: 基于查询的 cdc 通常需要和调度系统搭配使用,常见的方式有基于时间戳的 CDC、基于触发器的 CDC、基于快照的 CDC。由于时效性比较差,而且在保证数据一致性方面具有天然的劣式(因为查询的过程中数据可能已经发生多次变更),数据的一致性须有整个调度链上下游一起辅助实现。所以一般离线的调度场景会用的会比较多。例如于调度查询作业,离线数仓等。
- 基于日志的 CDC: 在业务系统中添加系统日志,当业务数据发生变化时,更新维护日志内容,当 ETL 加载时,通过读日志表数据决定需要加载的数据及加载的方式。例如 MySQL 的 binlog 日志完整记录了数据库中的变更,可以把 binlog文件当作流的数据源,通过对 MySQL Binlog 进行实时采集,然后对接一些实时计算引擎或者 APP 进行消费后把数据传输入 OLAP 系统或者其他存储介质。 优点:整个链路可以做到实时增量的 ETL 处理,实效性有保证,这对于一些对时效性要求比较高的应用场景非常适合。同时在数据一致性方面也是更有保证,因为 binlog文件包含了所有历史变更明细,可以根据日志的位点信息进行回溯和重放操作。并且基于日志的 CDC 在增量同步阶段是非入侵式的,对系统的性能影响是比基于查询的 CDC 要好很多。
3. 常见的开源 CDC 方案对比
Flink CDC | Debezium | DataX | Canal | Sqoop | Kettle | Oracle Goldengate | |
|---|---|---|---|---|---|---|---|
实现机制 | 日志 | 日志 | 查询 | 日志 | 查询 | 查询 | 日志 |
全量同步 | ✔️ | ✔️ | ✔️ | ❌ | ✔️ | ✔️ | ✔️ |
增量同步 | ✔️ | ✔️ | ❌ | ✔️ | ✔️ | ❌ | ✔️ |
断点续传 | ✔️ | ✔️ | ❌ | ✔️ | ❌ | ❌ | ✔️ |
架构 | 分布式 | 单机 | 单机 | 单机 | 分布式 | 分布式 | 分布式 |
清洗/转换/聚合 | ⭐️⭐️⭐️ | ⭐️⭐️ | ⭐️⭐️ | ⭐️⭐️ | ⭐️⭐️ | ⭐️ | ⭐️ |
生态 | ⭐️⭐️⭐️ | ⭐️⭐️ | ⭐️⭐️ | ⭐️⭐️ | ⭐️ | ⭐️ | ⭐️⭐️ |
从上面表格的对比分析看,Flink CDC 的方案具有很大的优势。笔者认为这种优势主要来源有: 1.架构的先进行 2.集合了当下主流热门的技术优势 我们以腾讯云, 云上全托管流计算 Oceanus(Oceanus 是云上基于 Apache Flink 构建的高性能企业级实时大数据分析平台,并且采用的是云原生容器化部署模式) 为例来阐述一下 Flink CDC 方案的优越性。
4. Flink CDC 优势分析
4.1. Flink CDC 数据采集端的底层使用的是 Debezium
Flink 的应用程序结构,有 Source(源头)、Transformation(转换)、Sink(接收器)三个重要组成部分。Source 定义 Flink 从哪里加载数据,是以定义独立 Connector Jar 包通过 SPI方式和Flink 进行解耦。flink-cdc-connectors 就是自定义的 Source Connector 的插件化独立工程,其底层是用到了 Debezium 来对数据进行采集。 Debezium 是一个基于日志的 CDC 工具,将现有的数据库转换为事件流,可以捕捉到数据库中的每一个行级更改并立即做出响应,主要的特性有:
- 捕获所有数据更改(包括删除)
- 低延迟生成更改事件,同时避免增加频繁轮询的CPU使用量
- 可以捕获旧记录状态和其他元数据
- 不需要更改数据模型
- 变更事件可以序列化为不同的格式,例如 JSON 或 Apache Avro
Flink CDC 最终选择了 Debezium 作为 Flink CDC 的底层采集工具,除了Debezium 自生的特性外,主要还有下面两个原因 :
- 使用 Debezium 连接器的另一种方法是嵌入式引擎。在这种情况下,Debezium 不会通过 Kafka Connect 运行,而是作为一个嵌入到定制 Java应用程序中的库运行。这对于在应用程序内部使用更改事件非常有用,而不需要部署完整的 Kafka 和 Kafka 连接集群。这就使得 Debezium 成为 flink-cdc-connectors 项目底层的基础条件。
- Flink SQL 的内部数据结构 RowData 和 Debezium 的数据结构进行对比,可以发现两者是非常相似的。Flink SQL 的内部数据结构,每条 RowData 都有一个元数据 RowKind,包括 4 种类型, 分别是插入 (INSERT)、更新前镜像 (UPDATE_BEFORE)、更新后镜像 (UPDATE_AFTER)、删除 (DELETE),这四种类型和数据库里面的 binlog 概念保持一致 。而 Debezium 的数据结构,也有一个类似的元数据 op 字段, op 字段的取值也有四种,分别是 c、u、d、r,各自对应 create、update、delete、read。对于代表更新操作的 u,其数据部分同时包含了前镜像 (before) 和后镜像 (after) 。
两者相结合的模式,Flink CDC 的特性方面 即支持增量同步,也支持全量 + 增量的同步,非常灵活,同时基于日志的 CDC 技术使得提供 Exactly-Once 成为可能 。
4.2. Flink 自身特性加持
Flink 的特性很多,这里列举同步场景下关心的三个核心特性
4.2.1 Flink流处理的容错机制
Flink 通过流重放(streamreplay)和检查点机制(checkpoint)结合的方式实现了容错能力。检查点与每个输入流中的特定一点以及每个操作的相应状态相关。数据流可以从检查点恢复来保持一致性(exactly-once的语义),通过恢复操作的状态和从检查点开始重放事件。检查点间隔是对程序的容错能力与恢复时间(需要重发的事件数量)的平衡手段
4.2.2 Flink 集群的 HA 机制
flink standalone 模式下的 HA, 运行多个 JobManager,其中一个为 leader,其他为 standby,通过 Zookeeper 实现故障切换。
Flink on Yarn 模式下的高可用配置只需要一个 JobManager。当 JobManager 发生失败时,Yarn 负责将其重新启动。
Flink 1.12 之前只有一种基于 Zookeeper 的方案,1.12 版本中增加了一个基于 Kubernetes ConfigMap 的方案(仅用于使用Kubernetes 部署 Flink 的场景),该特性对应有一个 FLIP-144: Native Kubernetes HA for Flink,对设计细节有兴趣的可以看下。
4.2.3 Flink 自定义函数
在数据转换 / 数据清洗能力上,Flink 本身内置了很对开箱即用的内置函数,大致分为比较函数,字符串处理函数,时间函数,逻辑函数,计算函数等几大类别,同时还支持自定义函数,通过扩展开发机制,可以用来在查询语句里调用难以用其他方式表达的频繁使用或自定义的逻辑。有标量函数( UDF ),聚合函数( UDAF ),表值函数( UDTF ) 三类。
可以看到在 Flink 自身特性的加持下,Flink HA-Master-Work 并行设计模式, 全局一致性快照容灾,丰富内置函数和自定义函数 在架构,断点续传,exactly-once 的语义,清洗/转换/聚合方面具有很好保证。
4.3. 云原生容器化部署模式稳定性增强
K8S 是业内最流行的容器编排工具,与 docker 容器技术结合,可以提供比 Yarn 与 Mesos 更强大的集群资源管理功能,对生产效能有着巨大的提升。Flink On K8S是目前最前沿实现方案。数据集成是对稳定性和安全性要求较高的场景,On K8s 至少带来以下几点的好处:
- 空间隔离 租户独占网络空间/计算资源/存储资源。
- 进程隔离 通过容器部署实现作业间资源隔离,运行更稳定。
- 基于角色的访问控制( Role-Based Access Control ) 提供了更加细粒度权限控制和安全保证
4.4. Flink 上下游生态

在生态方面,这里主要指的是下游的一些数据库或者数据源的支持。Flink CDC 下游有丰富的 Connector,例如写入到 Redis、MySQL、Es、HBase、Kafka、ClickHouse 等常见的一些系统,也支持各种自定义connector。
对于上游,可以利用 Flink SQL 双流 JOIN、维表 JOIN、UDTF 语法,对 CDC 和维表进行 JOIN 加工,加工后直接写入到下游数据库。通过一个 Flink SQL 作业就可完成了 CDC 的数据分析,加工和同步。
3. 传统的数据同步方案与 Flink CDC 解决方案对比
1. 传统 CDC 的 ETL 分析链路
传统的基于 CDC 的 ETL 分析中,数据采集工具是必须的,国外用户常用 Debezium,国内用户常用阿里开源的 Canal,采集工具负责采集数据库的增量数据,一些采集工具也支持同步全量数据。采集到的数据一般输出到消息中间件如Kafka,然后 Flink 或者 Spark 等计算引擎再去消费这一部分数据写入到目的端。目的端可以是各种 DB,数据湖,实时数仓和离线数仓。模型如下:
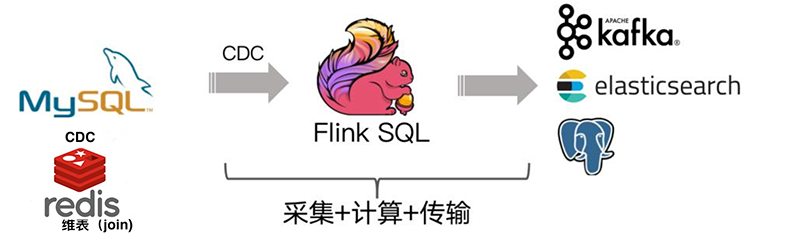
2. Flink CDC 的 ETL 分析链路
Flink CDC 去替换采集组件和消息队列,从而简化分析链路,降低维护成本, 数据不落地,减少存储成本。同时更少的组件也意味着数据时效性能够进一步提高。除了组件更少, 成本降低,维护更方便外,另一个优势是通过 Flink SQL极大地降低了用户使用门槛,这意味着只要会 SQL 的 BI,业务线同学都可以完成此类工作。与此同时,用户也可以利用 Flink SQL 提供的丰富语法进行数据清洗、分析、聚合。模型如下:
4. flink-cdc-connectors 各个版本的介绍
flink-cdc-connectors 从大版本来看的话,分为 1.0+ 和 2.0+ 两个大版本的迭代。1.0+ 目前开源的最高版本为 1.4 ,2.0+ 目前开源的最新版本为 2.1 。两个大版本之间的区别还是很多的,主要在于全量数据的同步阶段这部分架构上做了很大的调整,以下就从 1.X 的痛点问题和 2.X 改进优化方面做下阐述,这样我们在版本的选择上就会有一个比较清楚的认知。
1. 1.0+ 的痛点问题
1.X 版本社区反馈的问题比较多,生产实践中的踩坑比较常见,尤其是一些比较复杂和数据量体比较大的情况下。主要有:
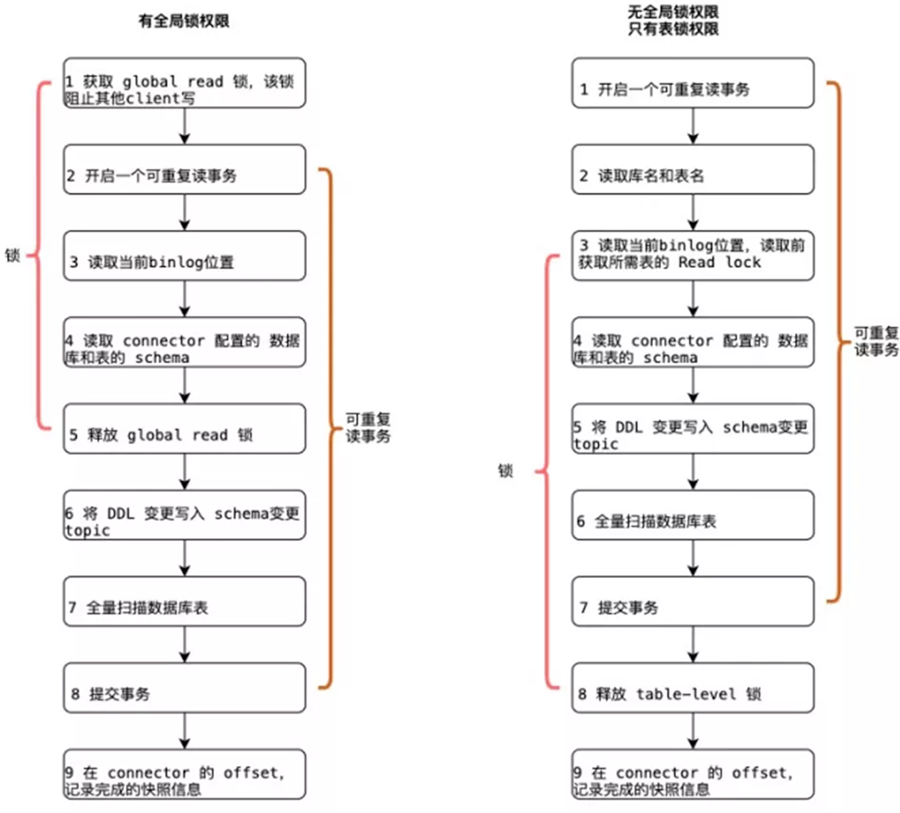
- 为保证同步数据的一致性,在同步全量数据阶段需要加锁,加锁的目的是目的是为了确定全量阶段的初始位点。在 Flink CDC 中有两个 Reader 一个是 SnapshotReader ,另一个是 BinlogReader 分别对应全量阶段同步和存量阶段同步。同步全量数据阶段需要加锁有两种锁: 全局锁(默认) 和表锁,我们分别看下两种锁的逻辑和危害:
- 全局锁:会锁住库,锁住之后开启一个可重复读的事务,这里锁住操作是读取 binlog 的起始位置和当前表的 schema( 这样做的目的是保证 binlog 的起始位置和读取到的当前 schema 是可以对应上的,因为Schema 具有可变性 ),随后释放锁。然后 SnapshotReader 会在这个可重复读的事务里面同步全量数据。全量同步完成交由 BinlogReader同步增量。虽然理论上,全局锁的时间很短,但是等待加锁的时间是不确定的,总之加锁在数据库层面上是一个十分高危的操作。
- 表锁:是全局锁的退化版,因为全局锁的权限会比较高,因此在某些场景,用户只有表锁。表锁锁的时间会更长,因为表锁有个特征:锁提前释放了可重复读的事务默认会提交,所以锁需要等到全量数据读完后才能释放。所以说加锁的事情对线上的业务影响是很大的,除非能够暂停线上业务,否者不建议尝试。
- 不支持水平扩展,因为 Flink CDC 底层是基于 Debezium,架构是单节点,所以 Flink CDC只支持单并发。在全量阶段读取阶段,用户不能通过增加资源去提升作业速度。按照实操的效果,全量数据在千万级别的,至少是几个小时起,单行字段数据很多的的,甚至可以达到以天单位,个人建议,使用 1.X 版本,全量数据最好保持在千万级别以下。
- 全量读取阶段不支持 checkpoint:CDC 读取分为两个阶段,1.X 全量读取阶段是不支持 checkpoint 的,因此会存在一个问题:当我们同步全量数据时,假设需要 5 个小时,当我们同步了 4小时的时候作业失败,这时候就需要重新开始,再读取 5 个小时。
- 稳定性问题,踩坑场景比较多的是在,集中在全量数据数据比较大的场景下,常出现比如内存上面经常出问题 TaskManager OOM, Yarn Container kill,容器化环境下的 OOMKilled,还有就是由于数据挤压,处理慢,带来的偶发性问题,比如说 链接超时断开,反压过高等等。
- 部分必要功能的缺失,比如说 MySQL 的数组,枚举类型的缺乏支持,不支持元数据字段,Debizium部分调参无法生效,如
snapshot.fetch.size。
总结来说,1.X 版本,能用但是不好用,在数据量不大(建议千万级以下)和线上业务对影响不敏感且业务不是很复杂的场景下,能够很好满足需求。
2. 2.0+ 的升级特性
2.0 的设计方案,核心要解决三个问题,即支持无锁、水平扩展、全量阶段 checkpoint。2.1 版本 的优化点在三个方面:
- 稳定性增强: 引入动态分片算法,支持超大规模表,引入连接池管理数据库连接,支持分库分表 schema 不一致时,缺失字段自动填充 NULL 值
- 功能增强:支持所有 MySQL 数据类型,支持并发读取的 DataStreamAPI,标准化连接器指标 FLIP-33 [1]
- 新增 Connector:Oracle CDC, MongoDB CDC
从线上新版本的实战应用效果来看, 目前使用效果还是比较不错的。无锁化减少了对线上业务的入侵,水平扩展极大提高了同步数据的效率,全量 checkpoint 降低了失败情况下的重启成本,2.1提升了稳定性和增强了功能,虽然在一些小场景下,也会有一些小 bug, 但是在社区也能找到资料,而且及时更新到开源项目中去。所以来讲总体的建议,还是在有条件的情况下,尽量使用新的版本作为线上生产版本。
5. 2.X 实现逻辑简单介绍
2.x 实现的最核心的三个功能是 支持无锁、水平扩展、全量阶段checkpoint。这里面的理论基础是 FLIP-27: Refactor Source Interface的新的数据源 API设计和 DBLog - 无锁算法论文,有兴趣的同学可以看一下。本文重点对 Flink CDC 2.0 的处理逻辑进行介绍,FLIP-27 和无锁算法的设计及 Debezium 的API 调用不做过多讲解。
1. 整体逻辑介绍
在全量阶段 Flink 使用快照记录读取 + binlog 数据修正的方式来保证数据的一致性。全量阶段切片数据读取完成后,增量阶段是读取全量阶段分片的起始偏移量为所有已完成的全量切片最小的 binlog 偏移量为起点,只有满足捕获的binlog 数据的偏移量 > 数据所属分片的 Binlog 的最大偏移量的条件,增量阶段的数据的才被下发到下游。
全量阶段数据读取方式为分布式读取,会先对当前表数据按主键划分成多个 Chunk,后续子任务读取 Chunk 区间内的数据。根据主键列是否为自增整数类型,对表数据划分为均匀分布的 Chunk 及非均匀分布的Chunk。在快照读取操作前、后执行 SHOW MASTER STATUS 查询 binlog 文件的当前偏移量,在快照读取完毕后,查询区间内的 binlog 数据并对读取的快照记录进行修正。
2. 新的数据源 API对全量阶段分布式读取的架构模型支持
FLIP-27 引入的新的 Source API 在 Flink 1.11 中引入,flink-cdc-connectors 便是兼容并引用的新的 Source API,这样的好处在于,将数据采集部分,拆分为数据分片和数据处理两个阶段,分别跑在 JM 和 TM 上面,配合算法就能保证数据和一致性而且在全量阶段 checkPoint 成为可能。下面介绍一下 Flink 的数据源新 API及其背后的概念和架构。
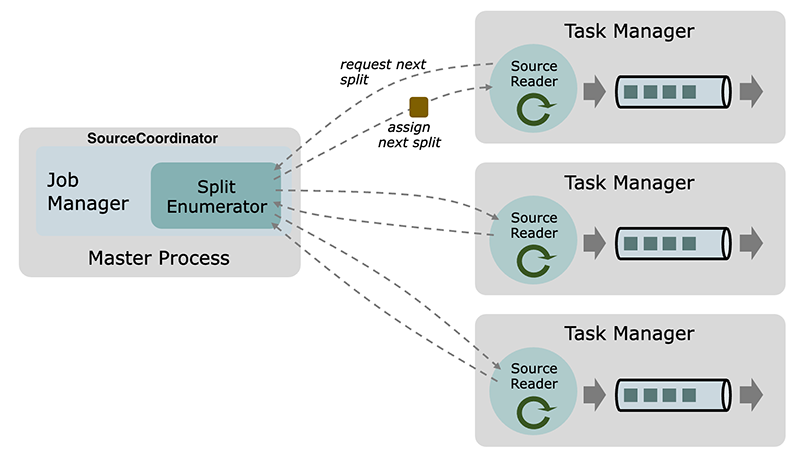
核心的组件:
Split是数据源所消耗的一部分数据,就像一个文件或一个日志分区。Split是源分配工作和并行读取数据的粒度。SourceReader请求Split并进行处理,例如读取Split所代表的文件或日志分区。SourceReader在SourceOperators的 Task Manager上并行运行,并产生事件/记录的并行流。SplitEnumerator生成Split并将它们分配给SourceReader。它作为单个实例在任务管理器上运行,负责维护待处理的Split的积压,并以平衡的方式将它们分配给读者。
SourceCoordinator 是一个独立的组件,以是运行在 JobMaster 上作为一个独立进程。SourceCoordinator (Enumerator)通过 RPC 通信。Split 分配通过 RPC 支持pull-based。SourceReader 需要向 SourceCoordinator 注册以及发送 split 请求携带负载信息。每个 job 至多有一个由 JobMaster 启动的 SourceCoordinator。一个job 可能有多个 Enumerator,因为可能有多个不同的 Source,所有的 Enumerator 都运行在这个 SourceCoordinator。
Split 分配需要满足 Checkpoint 模式语义。Enumerator 有自己的状态(Split 分配),他们是全局 Checkpoint 的一部分。当一个新的 Checkpoint被触发,CheckpointCoordinator 首先发送 barrier 到 SourceCoordinator。SourceCoordinator 保存所有 Enumerator 的快照状态。SourceCoordinator 通过RPC 发送 barrier 到 SourceReader。split 和 barrier 通过 RPC 是先进先出的,所以 Flink 可以自然地将 split 分配与 Checkpoint 对齐。
3. 核心代码逻辑走读
代码核心点标记,目的主要是标注方便在看源码的时候标记阅读顺序和逻辑,以及在定位问题和自定义逻辑时手方便定位。
3.1. MySqlSourceEnumerator 相关
3.1.1 MySqlParallelSource#createEnumerator 创建 MySqlSourceEnumerator 并调用 start 方法,做一些初始化工作。
@Overridepublic SplitEnumerator<MySqlSplit, PendingSplitsState> createEnumerator(SplitEnumeratorContext<MySqlSplit> enumContext){MySqlValidator validator=new MySqlValidator(config);
final MySqlSplitAssigner splitAssigner=startupMode.equals("initial")// 处理全量切片逻辑,通过 ChunkSplitter 生成切片,并存储到Iterator中。?new MySqlHybridSplitAssigner(config)// 增量数据切片器:new MySqlBinlogSplitAssigner(config);
return new MySqlSourceEnumerator(enumContext,splitAssigner,validator);}3.1.2 启动周期调度线程 MySqlSourceEnumerator#syncWithReaders,要求 SourceReader 向 SourceEnumerator 发送已完成但未发送 ACK 事件的切片信息
private void syncWithReaders(int[]subtaskIds,Throwable t){if(t!=null){throw new FlinkRuntimeException("Failed to list obtain registered readers due to:",t);}// when the SourceEnumerator restores or the communication failed between// SourceEnumerator and SourceReader, it may missed some notification event.// tell all SourceReader(s) to report there finished but unacked splits.if(splitAssigner.waitingForFinishedSplits()){for(int subtaskId:subtaskIds){context.sendEventToSourceReader(subtaskId,new FinishedSnapshotSplitsRequestEvent());}}}3.1.3 处理切片请求事件 MySqlSourceEnumerator#handleSplitRequest(MySqlSourceReader 启动时会向 MySqlSource Enumerator 发送请求RequestSplitEvent 事件),为请求的 Reader 分配切片,全量阶段 MySqlSnapshotSplit、增量阶段MySqlBinlogSplit。
@Overridepublic void handleSplitRequest(int subtaskId,@Nullable String requesterHostname){if(!context.registeredReaders().containsKey(subtaskId)){// reader failed between sending the request and now. skip this request.return;}// 将reader所属的subtaskId存储到TreeSet, 在处理binlog split时优先分配个task-0readersAwaitingSplit.add(subtaskId);// 分配切片assignSplits();}3.2. MySqlSourceReader 相关
3.2.1 SourceOperator 在初始化时,通过 MySqlParallelSource#createReader 创建 MySqlSourceReader。MySqlSourceReader 通过 SingleThreadFetcherManager 创建 Fetcher 拉取分片数据,数据以 MySql Records 格式写入到 elementsQueue。
@Overridepublic SourceReader<T, MySqlSplit> createReader(SourceReaderContext readerContext) throws Exception { FutureCompletingBlockingQueue<RecordsWithSplitIds<SourceRecord>> elementsQueue = new FutureCompletingBlockingQueue<>(); final MySqlRecordEmitter<T> tMySqlRecordEmitter = new MySqlRecordEmitter<>(deserializationSchema); RegistryMetric(readerContext.metricGroup(),tMySqlRecordEmitter); final Configuration readerConfiguration = getReaderConfig(readerContext); Supplier<MySqlSplitReader> splitReaderSupplier = () -> new MySqlSplitReader(readerConfiguration, readerContext.getIndexOfSubtask()); return new MySqlSourceReader<>( // 拉取数据先存储到对列 elementsQueue, // Split Reader 工厂类 splitReaderSupplier, // mysql Records 序列化 为Flink Row emitter 到下游 tMySqlRecordEmitter, readerConfiguration, readerContext);}....@Override public void start() { if (getNumberOfCurrentlyAssignedSplits() == 0) { // 启动时会向 MySqlSource Enumerator 发送请求 RequestSplitEvent 事件 context.sendSplitRequest(); } }3.2.2 将创建的 MySqlSourceReader 以事件的形式传递给 SourceCoordinator 进行注册。SourceCoordinator 接收到注册事件后,将reader 地址及索引进行保存
private void handleReaderRegistrationEvent(ReaderRegistrationEvent event){// SourceCoordinator 处理Reader 注册事件context.registerSourceReader(new ReaderInfo(event.subtaskId(),event.location()));enumerator.addReader(event.subtaskId());}3.2.3 MySqlSourceReader 接收到切片分配请求后,会为先创建一个 SplitFetcher 线程,向 taskQueue 添加、执行 AddSplitsTask 任务用来处理添加分片任务,接着执行 FetchTask 使用Debezium API 进行读取数据,读取的数据存储到 elementsQueue中,SourceReaderBase 会从该队列中获取数据,并下发给 MySqlRecordEmitter。
/**SingleThreadFetcherManager#addSplits **/@Overridepublic void addSplits(List<SplitT> splitsToAdd){SplitFetcher<E, SplitT> fetcher=getRunningFetcher();if(fetcher==null){fetcher=createSplitFetcher();// Add the splits to the fetchers.fetcher.addSplits(splitsToAdd);startFetcher(fetcher);}else{fetcher.addSplits(splitsToAdd);}}3.2.4 MySqlSplitReader 执行 fetch(),由 DebeziumReader 读取数据到事件队列,在对数据修正后以 MySqlRecords 格式返回。DebeziumReader包含全量切片读取、增量切片读取两个阶段,数据读取后存储到 ChangeEventQueue,执行 pollSplitRecords 时对数据进行修正
@Overridepublic RecordsWithSplitIds<SourceRecord> fetch()throws IOException{checkSplitOrStartNext();Iterator<SourceRecord> dataIt=null;try{// 对数据进行修正dataIt=currentReader.pollSplitRecords();}catch(InterruptedException e){LOG.warn("fetch data failed.",e);throw new IOException(e);}// 封装为 MySqlRecords 进行传输return dataIt==null?finishedSnapshotSplit():MySqlRecords.forRecords(currentSplitId,dataIt);}3.2.5 SourceReaderBase 从队列中获取切片读取的 DataChangeEvent 数据集合,将数据类型由 Debezium 的 DataChangeEvent 转换为 Flink 的 RowData 类型。
@Overridepublic InputStatus pollNext(ReaderOutput<T> output)throws Exception{// make sure we have a fetch we are working on, or move to the nextRecordsWithSplitIds<E> recordsWithSplitId=this.currentFetch;if(recordsWithSplitId==null){recordsWithSplitId=getNextFetch(output);if(recordsWithSplitId==null){return trace(finishedOrAvailableLater());}}
// we need to loop here, because we may have to go across splitswhile(true){// Process one record.final E record=recordsWithSplitId.nextRecordFromSplit();if(record!=null){// emit the record.recordEmitter.emitRecord(record,currentSplitOutput,currentSplitContext.state);LOG.trace("Emitted record: {}",record);return trace(InputStatus.MORE_AVAILABLE);}else if(!moveToNextSplit(recordsWithSplitId,output)){// The fetch is done and we just discovered that and have not emitted anything, yet.// We need to move to the next fetch. As a shortcut, we call pollNext() here again,// rather than emitting nothing and waiting for the caller to call us again.return pollNext(output);}// else fall through the loop}}3.2.6 MySqlSourceReader 处理完一个全量切片后,会向 MySqlSourceEnumerator 发送已完成的切片信息。全量阶段所有分片读取完毕后,MySqlHybrid SplitAssigner 会创建BinlogSplit 进行后续增量读取,在创建 BinlogSplit 会从全部已完成的全量切片中筛选最小BinlogOffset。
@Overrideprotected void onSplitFinished(Map<String, MySqlSplitState> finishedSplitIds){ for(MySqlSplitState mySqlSplitState:finishedSplitIds.values()){ MySqlSplit mySqlSplit=mySqlSplitState.toMySqlSplit(); checkState( mySqlSplit.isSnapshotSplit(), String.format( "Only snapshot split could finish, but the actual split is binlog split %s", mySqlSplit)); finishedUnackedSplits.put(mySqlSplit.splitId(),mySqlSplit.asSnapshotSplit()); } reportFinishedSnapshotSplitsIfNeed(); context.sendSplitRequest(); }
...
private MySqlBinlogSplit createBinlogSplit( SnapshotSplitChangeEventSourceContextImpl sourceContext){ return new MySqlBinlogSplit( currentSnapshotSplit.splitId(), currentSnapshotSplit.getSplitKeyType(), sourceContext.getLowWatermark(), sourceContext.getHighWatermark(), new ArrayList<>(), currentSnapshotSplit.getTableSchemas()); }6. 场景和最佳实践
在场景和最佳实践方面,这里引用一下云+ 社区 腾讯云流计算 Oceanus 专栏文章 。这里可以找到关于 CDC的当下热门的应用场景和最佳实践,而且定时更新,极具参考价值。这里就不做过多的介绍了。
7. 总结
本文通过数据集成技术选型问题入手,先后介绍了 CDC 技术,日志型和查询型各自的实现原理,各大主流的 CDC 技术实现方案。并突出介绍 Flink CDC 作为新的解决方案的优势以及传统的数据同步方案与 Flink CDC 解决方案对比。同时也是进一步的的描述了 Flink CDC ETL 在使用上的版本选择和 2.X 版本的原理介绍。抛转引玉,希望通过本文的介绍,有更多的人了解和关注 Flink CDC ETL ,体验新的方案带来的便捷性和生产能效的提高。同时希望大家多关注云+ 社区 腾讯云流计算 Oceanus,多多交流,相互学习,共同进步。
流计算 Oceanus 限量秒杀专享活动火爆进行中↓↓

点击文末「阅读原文」,了解腾讯云流计算 Oceanus 更多信息~
腾讯云大数据

长按二维码 关注我们