作者简介
孙晓光,PingCAP Community Development 团队负责人,原知乎基础研发团队架构师,长期从事分布式系统相关研发工作,关注云原生技术。
本文来自孙晓光在 Apache Flink x TiDB Meetup · 北京站的演讲,主要分享了知乎在 TiDB x Flink 批流一体方面的部分工作,并以实际业务为例介绍如何充分利用两者的特点完成端对端实时计算的闭环交付。
背景

上图是非常典型的实时数仓链路上的各个组件和数据,可以看到在很多地方 TiDB 和 Flink 都可以结合在一起去解决我们的业务问题。比如 TiDB 的大本营是在线交易,所以 ODS 是可以利用 TiDB 的,后边的维表和应用数据存储等也都可以利用 TiDB。
实时业务场景
场景分析
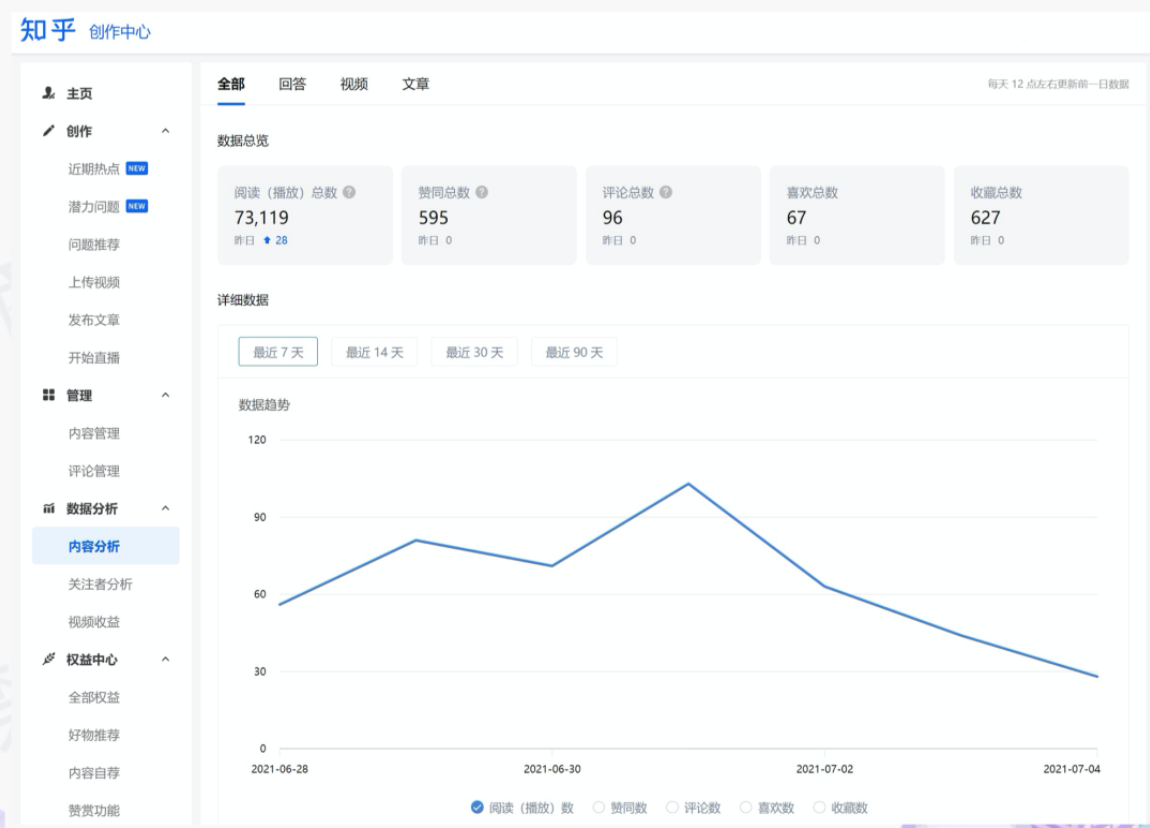
先看一下知乎这边一个实际的业务场景,知乎主站上的创作中心为创作者提供了内容交互数据的分析能力。创作者可以在这看到自己创作的内容所获得的赞同,评论,喜欢,收藏的数据以及过去一段时间内这些数据的变化。

这些数据可以帮助创作者更好地优化自己的创作。比如创作者对内容做了一些调整,然后发现交互数据开始发生显著的变化,创作者就可以基于这个信号对内容做相应的调整,去规避不好的或者进一步发扬光大好的策略,因此对创作者具有非常大的价值。另外,这个数据越即时,创作者的策略调整就能越即时。比如说创作者刚追更了一篇回答,希望立刻就可以看到相关的数据变化,如果数据变化是正向的,下次就可以做更多类似的调整。或者抽象出来过去好的调整都是什么,这样每次都可以基于之前的经验做出读者更喜欢的创作。
可惜对创作者这么有价值的数据目前仍然是不是实时的,大家可以在右上角看到数据更新的说明。这是我们在实时应用上还没有覆盖得足够好的一个证据,还是用传统的 T+1 的技术去实现的一个产品。
Flink 是我们把类似创作中心这样的应用场景实时化必然的选择,然而同大量使用 MySQL 的公司不同。知乎站上接近 40% 的 MySQL 数据库已经完成了到 TiDB 的迁移,所以我们必须将 TiDB 和 Flink 的实时计算能力做一个深入的整合。在未来当 TiDB 成为我们绝对主力数据库的时刻,能够获得更好的综合收益。
接下来我们探讨如何将内容交互数据的统计实时化,利用 TiDB 和 Flink 实现回答和文章这两种内容的喜欢、评论和赞同数据的实时计算。
业务数据模型分析
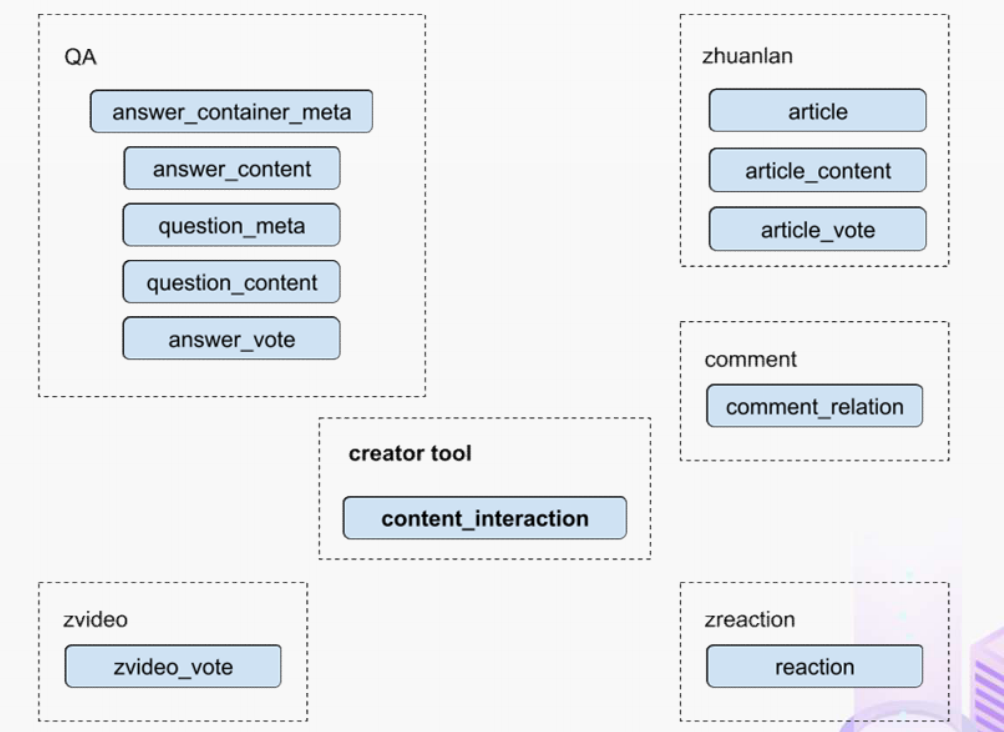
图中是对这些数据进行实时计算所需要关注的相关业务,这几个业务包括问答也就是左边的 QA,还有右边的专栏文章,以及评论、用户交互、视频回答。我们希望通过整合这些分散在不同业务里面的数据,得到创作者中心里的用户交互的统计数据,而且我们希望它是实时的。
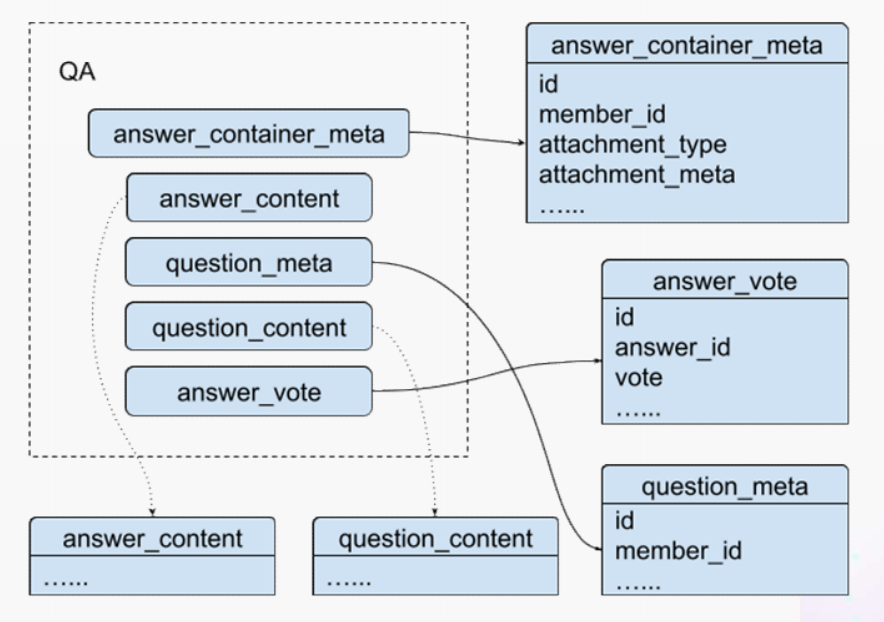
首先我们先放大一下问答业务,左边是 QA 业务里比较基础的几个基本表,实质上我们并不需要为计算交互信息了解到所有表所有的细节,只需要关注右边这几张表的部分字段就可以了。从这些表里我们只需要知道回答的 id,这个回答创作者的 member_id 还有被点赞的回答 id,就可以完整地计算某一个人的某一个回答有多少点赞。
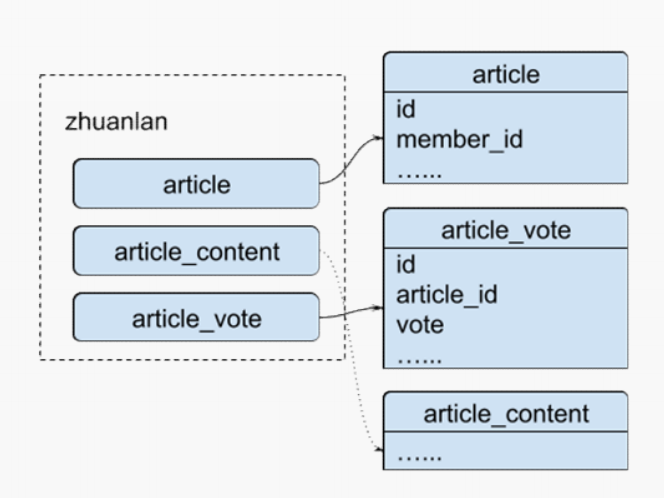
与此相似的是专栏文章,这边同样列出了一些基础表。如果要去做专栏文章的点赞这件事情的实时计算,我们关注 article 和 article_vote 这两张表,利用 member_id、id 和 vote 字段可以非常容易的计算得到文章的点赞数。
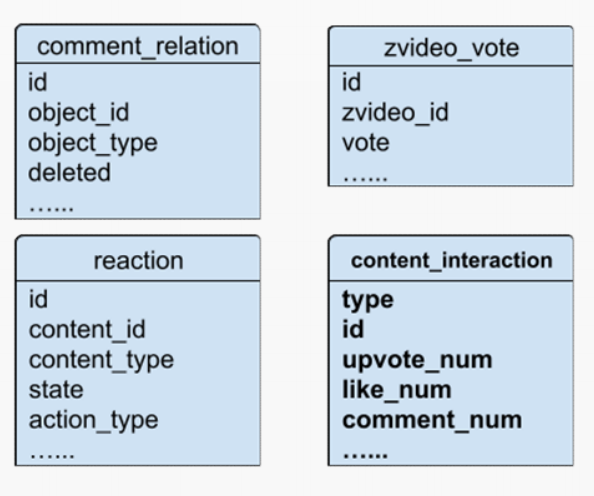
除了在业务系统内的点赞交互数据,其它类型的交互数据分散在多个不同的业务系统中。比如评论系统的 comment_relation 表,视频回答的 vote 表,还有其它交互的 reaction 表。基于这些用户的行为数据,再加上内容数据就能够计算得到用户创作的完整交互数据了。

从业务模型上可以得到交互数据计算的本质是把各种不同类型的内容和各种交互行为的数据作为源表,然后按照对这些数据以内容的 ID 分组进行聚合计算。比如说点赞就是一个 count 计算,因为表里一行数据就是一个点赞。如果说它是一个分值,那么这个数据的计算就是 sum。在拿到所有内容和所有交互聚合的结果后,再次同内容表做一个左连接就能拿到最后的计算结果了。
传统解决方案
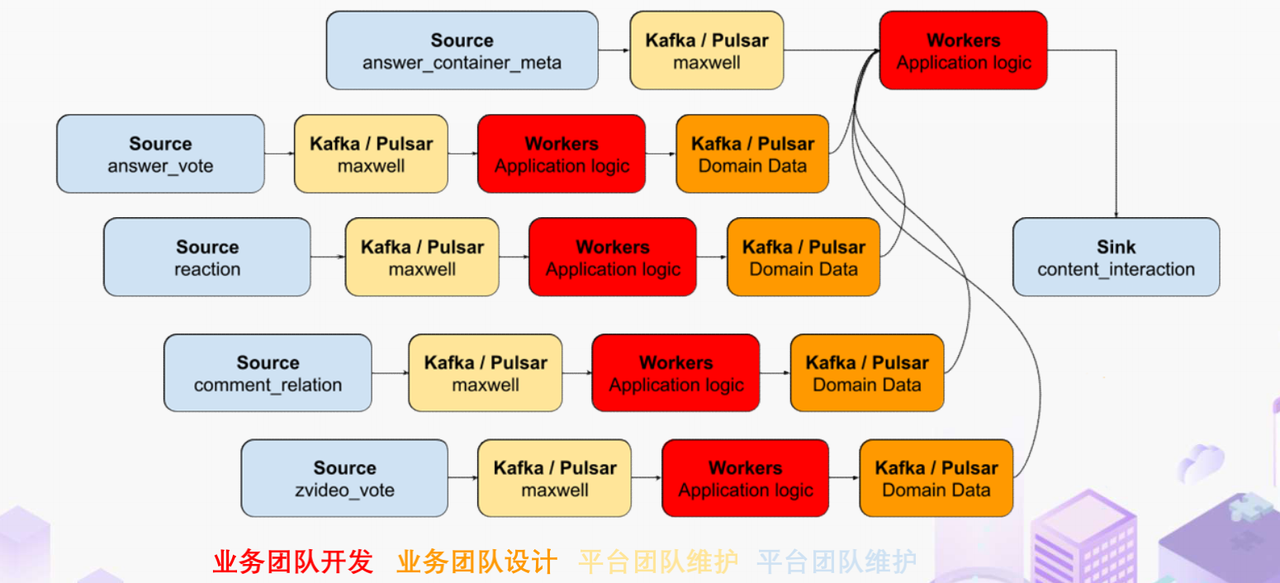
在开始讲 Flink 的计算之前,我们可以先看看没有 Flink,同样的实时应用是什么样的开发模式。知乎内部有一套自己过去积累的技术框架去做这样的事件驱动计算,如果用这样的技术做实时计算,开发的方式是上图这个样子。
业务工程师需要用自己熟悉的语言和框架来开发中间红色的这些基于消息系统的 worker,对拿到的实时数据变化事件进行补数和聚合操作,再将计算得到的结果以预先约定好的格式发送到消息系统。最后用一个最终的 worker,将内容源表和多个上游 worker 的实时计算结果拼接在一起得到最终的计算结果并保存到下游。这样我们就可以基于比较传统的技术来实现实时应用。在这种开发方式下,业务工程师需要关注多个 worker 的实现,和不同系统之间数据传递的格式。数据库和消息系统由平台团队来维护,对于工程师来说没有额外的学习成本,学习成本低和易于理解是这种传统开发方式的优点。

这种开发方式存在着一些问题。比如上面图里有 5 个 worker,worker 程序首先是一个消息系统的 consumer,它需要根据业务需求对接收到的实时数据进行聚合计算,并填充必要的维度数据。在保证这些计算逻辑的正确性之后,还要把这些计算的结果正确的发送到消息系统的下游 topic 中。不夸张地讲这样的一个程序至少需要 1000 行的工作量,5 个这样的 worker 不论从管理还是开发甚至是维护方面的成本都是非常高的。另外,这些业务团队自行开发的 worker 程序需要由开发者自行解决规模扩展性问题,还需要独立地预留资源应对突发流量造成全局的资源浪费。难以在合理的成本下平衡弹性不足带来的系统规模问题。
Flink 解决方案
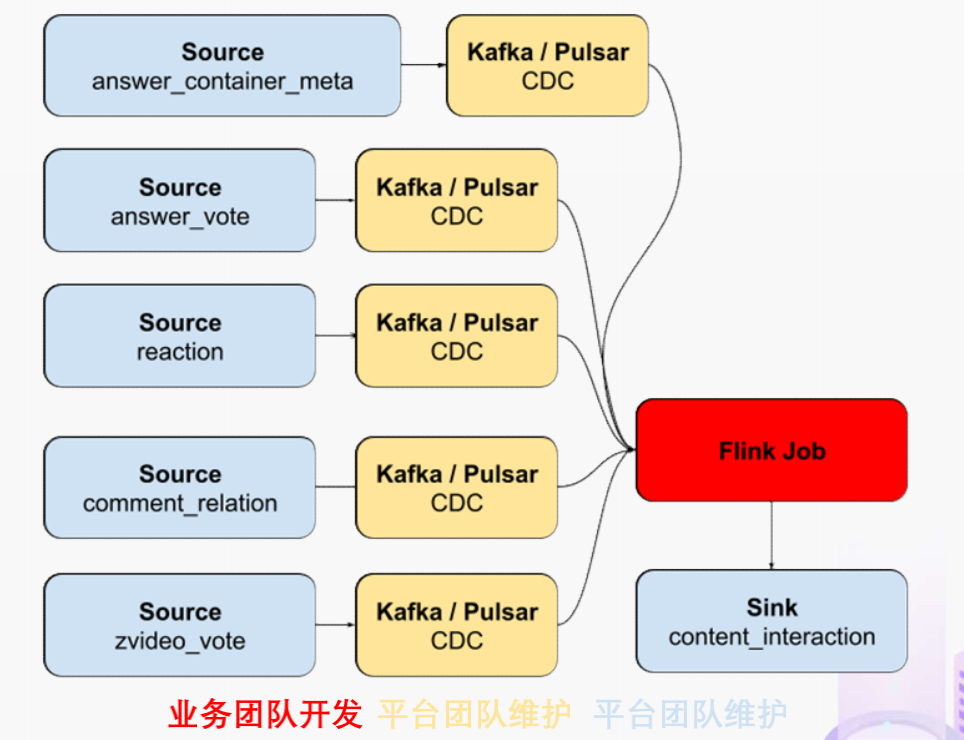
作为对比,如果用 Flink 去开发整个应用的结构会变得非常简单。当我们使用 SQL 来开发应用时,得益于更高的可维护性和可理解性,我们能够在不损失可维护性的情况下将这个应用的全部逻辑放在一个 job 里统一维护。不论从业务团队的开发成本还是是维护成本角度看都是更优的选择。
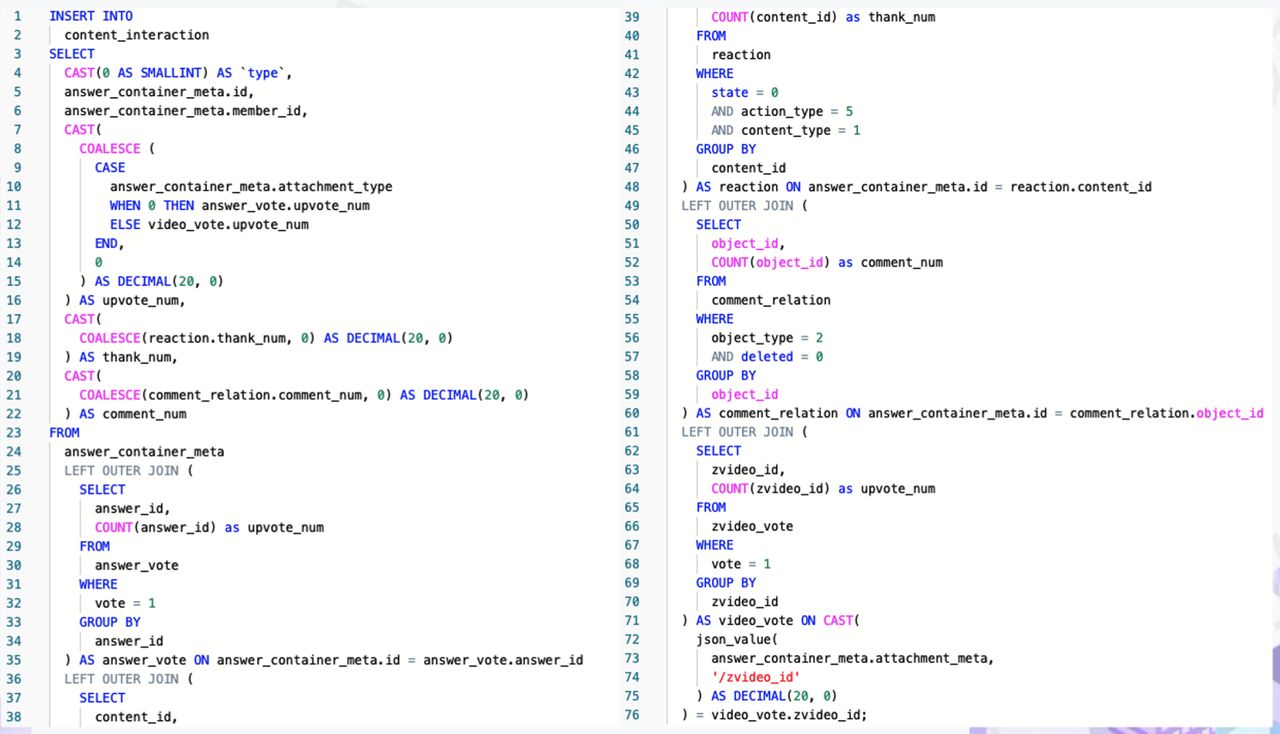
如上图所示,这是回答用户交互数据的实时计算逻辑用 Flink SQL 来开发,最后得到的 SQL 。利用 SQL 这种声明式的方式开发业务逻辑,非常容易地理解和验证它的正确性。

接下来看一下这种方式的优势:
首先,单一 SQL 开发可维护性高,组件数少,维护成本低。
其次,Flink 统一处理系统级问题,业务层无需关心扩展性、高可用、性能优化和正确性的问题,极大地降低了处理这些问题的负担。
最后,SQL 开发几乎没有额外的学习成本。为什么说 “几乎”,这个业务是典型的在线工程师的工作领域,而在线工程师一定很熟悉 SQL。但他们日常工作中使用到的 SQL 范围和大数据工程师使用的 SQL 范围还存在着些许的不同。所以不能说 Flink SQL 没有学习成本,但这个成本非常低,学习曲线也非常平缓。
任何事情都有两面性,基于 Flink 开发实时应用也需要解决下面的这些问题:
首先,SQL 的表达力并不是无限的,一定会有一些业务逻辑和业务场景很难拿目前的 Flink SQL 完全覆盖。如果我们用 28 法则来看这个问题,SQL 加上一些 UDF 就能够解决其中 80% 标准 Flink SQL 无法覆盖的问题,最后还剩下无法解决的 20% 问题有 DataStream API 进行兜底,确保整个业务问题能够在一个 Flink 技术栈上全部解决。
另外,Flink SQL 开发简单,但 Flink 系统本身的复杂度并不低。这些复杂度对许多业务工程师来说是一个非常重的负担,他们并不希望理解 Flink 如何工作如何维护。他们更希望在一个可自助操作的平台上编写 SQL 解决自己的领域问题,避免关注运维 Flink 这样一个复杂的问题。对此我们需要以平台化的方式降低业务接入系统的成本,利用技术手段和规模效应把单个业务的成本降到合理水平。
所以问题虽然存在,但都有合适的办法解决。
POC Demo
,时长01:20
刚刚讲到的创作中心实时应用还处于 POC 过程,POC 使用知乎站上实际的表结构,大家可以从 POC Demo 感受业务工程师能够基于 Flink 实现什么,实现的效果,以及正确性是否有保障。
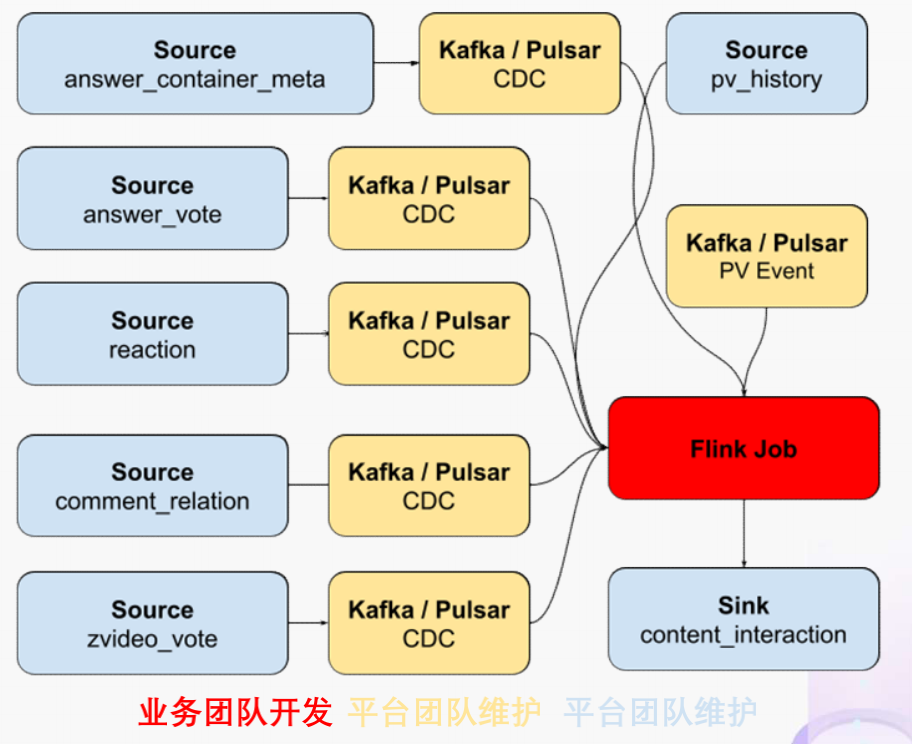
前面看到的部分只包括了在线业务的技术栈范围,也就是说源数据在 TiDB 上,经过 Flink 处理后的计算结果也存储在 TiDB,端到端的解决实时计算问题。如果需要在计算中引入离线产生的数据怎么办?比如我们想要在计算结果中包含每个内容的实时 PV,我们可以把大数据系统中的 PV history 的表和 PV 实时流进行一个 union 操作,再按照内容 ID sum 在一起,就可以得到实时的内容维度 PV 数据。传统方式的实现可能要写 1-2 个 worker,现在只需要在 Flink job 中加几行 SQL 代码就可以实现。
可能的疑问

如果不熟悉 Flink 不熟悉大数据的同学现在可能会有一些疑问,接下来我们 一一 看下这几大类疑问。
第一个就是计算到底怎么做的,在 TP 系统里面都是客户端请求触发计算,Flink 的计算是如何触发的呢?
答案是在事件触发时进行计算,每产生一个 event 就会触发一次计算。对数据库里任何一行的变化都触发一次计算,触发的颗粒度可能太细导致成本过高。所以 Flink 里边有 mini batch 的优化,可以攒一批变化事件以批的模式驱动计算。如果是关于时间段内数据的计算,还可以用 window 机制,使用 Watermark/Trigger 来触发计算并获得结果。如果计算的过程中需要维护状态,那么 Flink runtime 会负责管理状态数据。
第二个问题是 window 在哪里?
并不是所有业务都必须要用 window,当计算和触发逻辑跟时间段没有关系的时候,就不需要使用 window。比如这里的 demo 场景计算逻辑由数据变更触发状态永久有效,整个逻辑中不需要使用 window。
如果需要用 window 的时候怎么处理迟到的事件?这里有 discard 和 retract 两个主要的策略处理迟到事件,当遇到迟到事件时开发者可以选择扔掉迟到的数据,也可以用 retract 机制去处理。除此以外我们还可以用自定义的逻辑来处理迟到事件。总之 window 的作用是协助用户以预置的窗口策略,将落在某一时间段内的数据攒在一起触发计算,在有超出窗口的延迟数据到达时,按照应用期望的方式进行处理。
第三是开发上手难度如何?
Streaming SQL 在标准 SQL 的基础上建立,它的学习过程是渐进性的、平缓的。再配合上易扩展的 UDF 能力,能够解决大多数单纯使用 Flink SQL 无法解决的问题,少数只适合用编写代码方式解决的问题仍然有 Flink 的 DataStream API 可以解决。
最后 TiDB 和 Flink 如何保证计算结果的正确性?
TiDB 是一个默认快照隔离级别的数据库,我们能够直接拿到某个时间点的静止全局快照状态。在 SI 隔离级别下保证整个数据流的正确性非常容易。我们只需要拿到一个时间戳,并读取这个时间戳时刻全部数据的静止快照,处理完快照数据后对接上 CDC 里所有时间戳之后发生的 CDC event。在 Flink 的角度这就是一个流批一体的动态表,Flink 自身的机制能够保证流入到系统中事件计算结果的正确性。
TiDB x Flink 批流一体
下面来了解在做 POC 过程中,我们在 TiDB 和 Flink 整合方面开展了哪些工作,以及这些整合工作带来的能力处于什么样的状态。
TiDB as MySQL
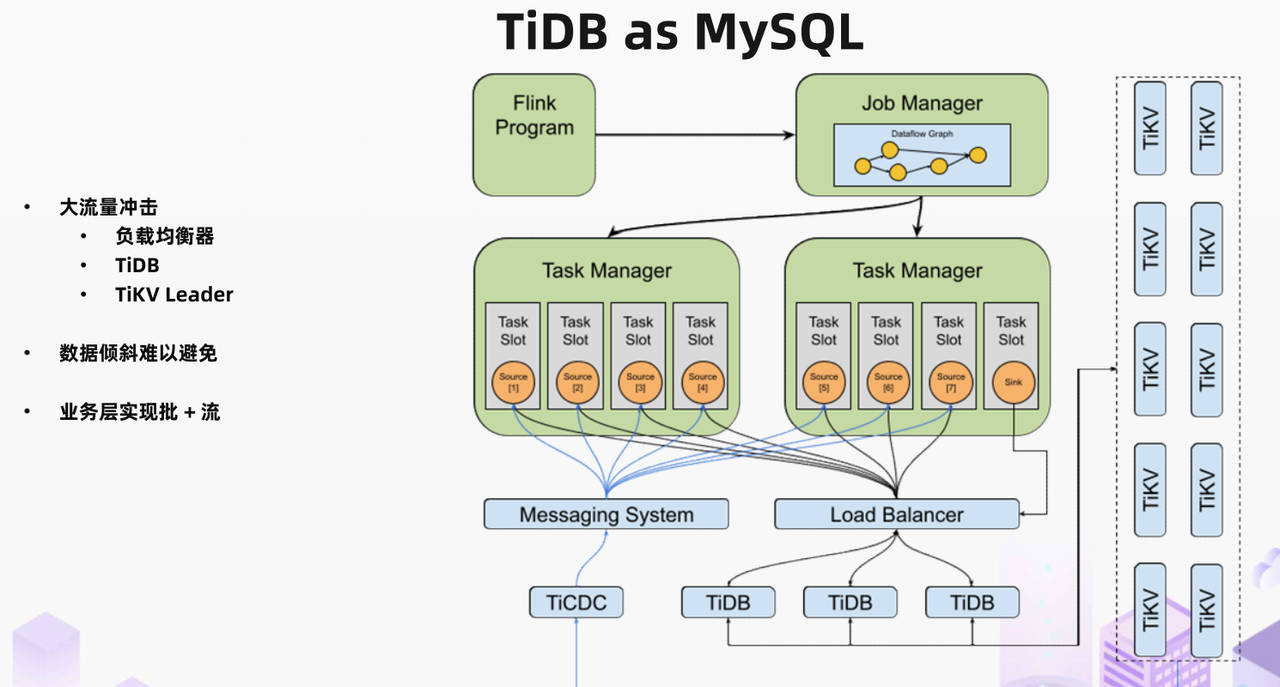
作为一款和 MySQL 兼容的分布式数据库,即便我们不做 TiDB 到 Flink 的原生整合,我们仍然能够以图示的方式把 TiDB 当作一个大号的 MySQL 和 Flink 配合在一起使用。这个架构下所有批任务流量都需要先过 LB ,然后再经过 TiDB 最后根据读取的数据范围访问相应的 TiKV 节点。而流任务流量是利用 TiCDC 从 TiKV 抓取数据变更事件,经由消息系统交付给 Flink 进行处理。
这种非原生对接的使用方式虽然能工作,但是在许多场景下无法充分利用 TiDB 架构的特点做更极致的成本优化和价值放大。比如在流量波动大的应用场景,由于所有的流量要在整个路径上,从 LB 到 TiDB 到 TiKV 的每一层走一遍。而流量会对每一个进程产生全量的冲击,为了保证在峰值流量冲击下的业务表现,我们不得不按照峰值流量去预备所有的资源,造成了极大的资源浪费。
还有大数据场景经常遇到的数据倾斜问题。在没有业务知识的前提下,面对业务各种各样的表结构设计和业务数据分布特征,我们很难以统一的方式自动化地解决所有的数据倾斜问题。实际上在目前版本的 Flink JDBC connector 上,如果表主键不是整数类型且不存在分区表,那么 Flink 的 source 就只能以 1 个并行度去处理全部数据。这在面对 TiDB 上海量存储业务数据的场景是非常困难的。
最后,我们无法直接利用为 MySQL 设计的 flink-cdc-connector 项目为 TiDB 提供流和批一体的 connector。那么在许多需要这个能力的应用场景中,业务方就需要自己去关注批和流数据统一处理的问题。
TiDB 适配
为了解决在 Flink 中使用非原生 TiDB 支持遇到的这些缺陷,我们充分利用了 TiDB 架构的特点,为 TiDB 开发了原生的 Flink Connector,更好地服务于 Flink 的广泛计算场景。
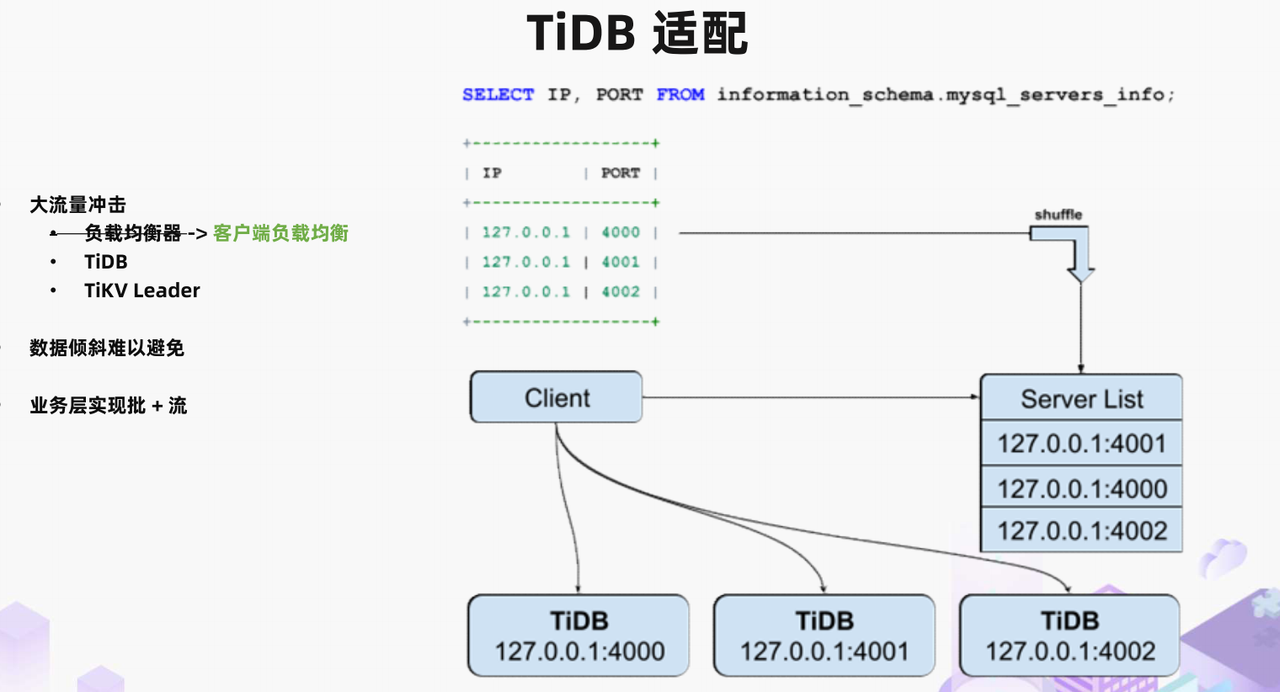
首先是针对大流量冲击场景的资源优化。在 TiDB 中有系统表可以得知整个集群所有 TiDB 服务器的地址和端口。我们实现了一个非常薄的代理到原生 MySQL JDBC driver 的 JDBC driver,利用系统表中的集群拓扑信息直接在客户端实现了负载均衡。通过直连 TiDB-server 的方式我们实现了负载均衡器的流量绕行,只有初次和后续定期更新集群信息的小数据量请求会经过负载均衡器,真正的大流量数据读写请求都通过到 TiDB 的直接连接来承载。
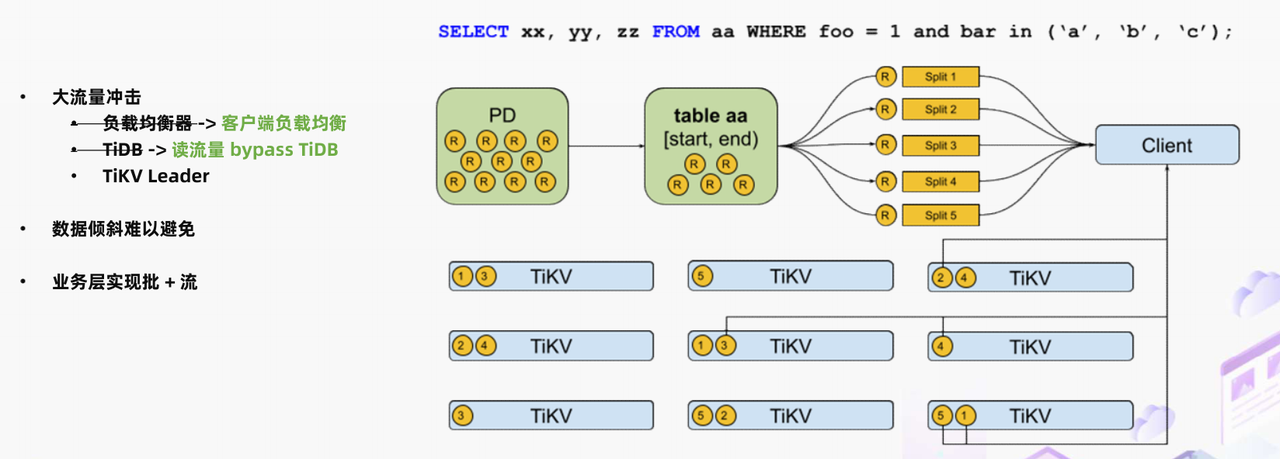
接下来是避免 TiDB-server 的流量冲击。在对 TiDB 上的数据进行读取操作时,我们能够让客户端从 PD 上获取到需要读取数据范围内的所有 region 信息。通过直接连接 region 背后 TiKV 节点的方式,我们能够将所有读的流量绕行 TiDB,极大地降低 TiDB 层负载,节约硬件资源成本。在实现 TiDB 绕行方案时,我们实现了同 TiDB 一致的 predicate 下推和 projection 下推能力,TiDB connector 对 TiKV 产生的压力同真正的 TiDB 非常接近,不会对 TiKV 产生额外的负担。

下一个是利用 placement rules 让一批物理隔离的 TiKV 节点只承载 follower 角色的数据副本,再配合 follower read 能力我们能够在没有付出额外服务器成本的情况下将实时计算的大流量负载,同在线的业务负载物理隔离开。让大家能够放心的在一个 TiDB 集群上同时支撑在线业务和大数据业务。
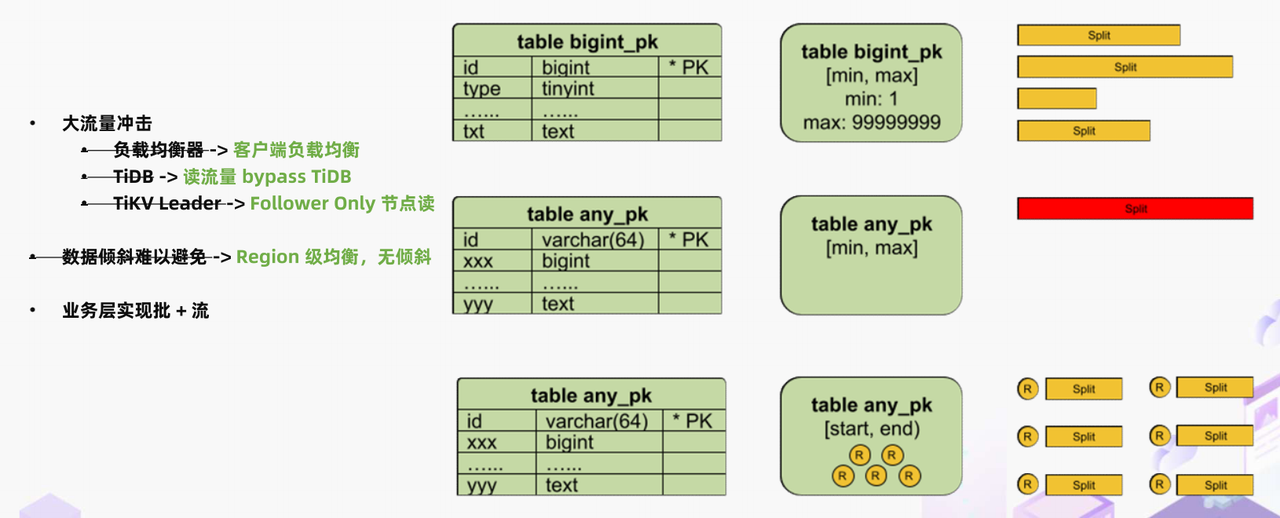
接下来是业务无关的数据均衡能力。如前面所讲,在没有业务层领域知识和数据分布信息的情况下,JDBC 方式只能对整数主键的数据进行近似均衡的拆分,而对于非整数其它类型主键的非分区表就只能序列化的处理所有的数据。在 TiDB 这种海量数据存储的情况下,不论是单并发还是不均衡都会导致任务执行效率低的问题。而前面介绍 TiDB 绕行的时候大家也看到了,TiDB connector 的任务拆分粒度是 region 级别。而 region 尺寸是由 TiKV 按照一个最优的尺寸去自动保持的,所以对于任意一个表结构,我们都能够做到任务单元的均衡性,在无任何业务知识的情况下完全避免数据倾斜问题。
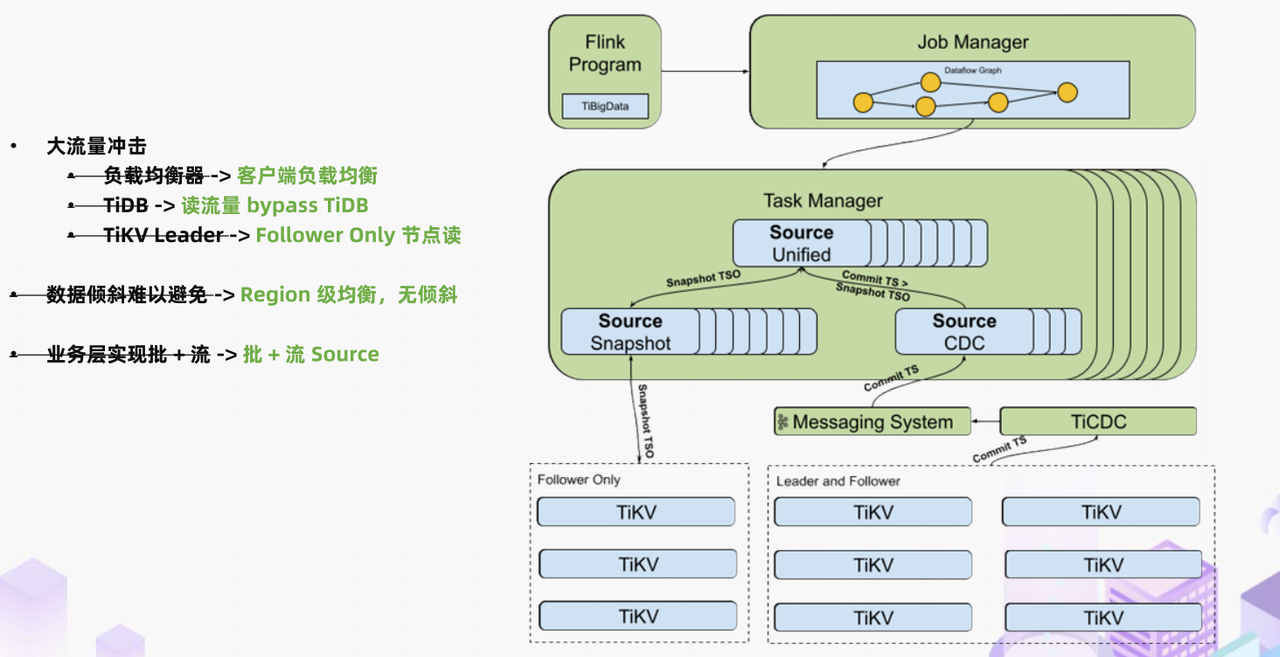
接下来是 TiDB connector 原生实现的批流一体能力。它的原理是利用 TiDB 的快照隔离级别拿到一个数据的全局快照,在处理完这个快照数据后,再接入所有 commit 版本号大于快照版本号的 CDC 事件。通过这个内嵌的流批一体能力,在数据处理工作得到极大简化的同时,还能确保整个实时计算流水线的绝对正确性。

最后为了进一步优化 TiDB 大流量写能力带来的 CDC 流量冲击。我们还对 TiCDC 的数据编解码格式做了二进制编码优化。大家经常在 TiCDC 中使用的 canel json 和 open protocol 都是 JSON 的格式,然而这些以 JSON 为物理格式的协议都倾向于尺寸更大和编解码 CPU 消耗过大的问题。而全新设计的 binary protocol 充分利用了 CDC 数据的一些特点,在典型场景下能够将数据尺寸压缩到 open protocol 的 42%,同时提升 encode 速度到接近原来的 6 倍,decode 速度到接近原来的 10 倍。
以上就是我们在 TiDB 和 Flink 原生整合方面所做的工作,这些工作很好地解决了利用 TiDB 和 Flink 实现端到端实时计算时所遇到的一些问题。
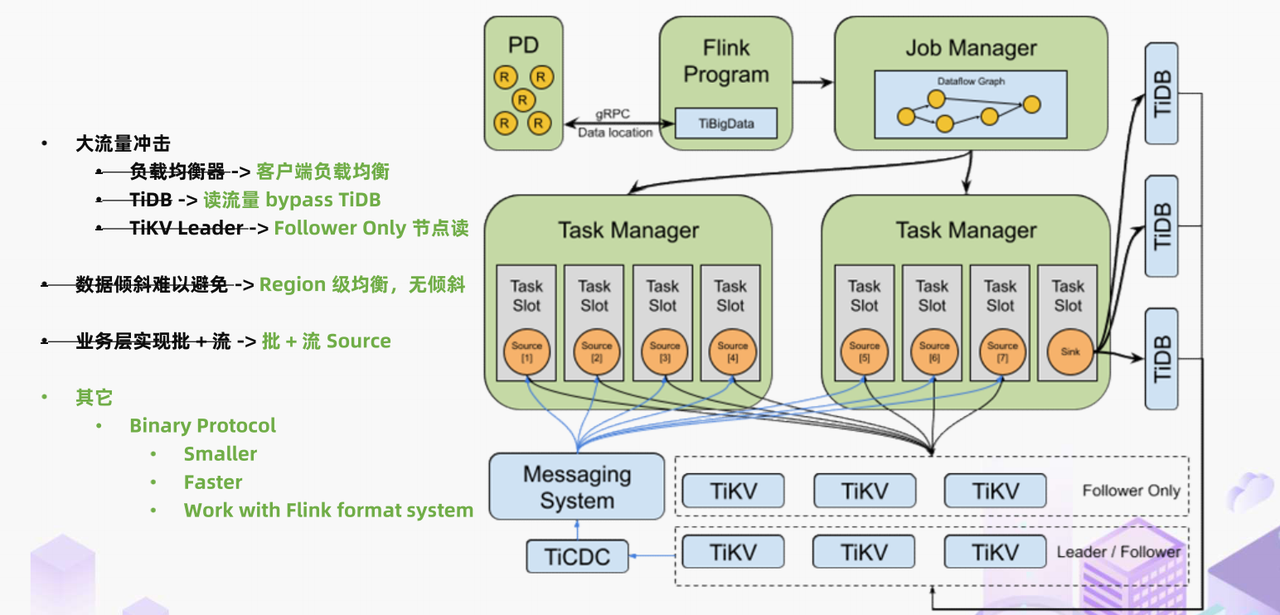
在 TiDB connector 的帮助下,TiDB 和 Flink 配合的方式变成图上的这个样子。读的流量绕行负载均衡和 tidb-server,直接请求 TiKV 的 follower 节点上。写的流量目前是借助 JDBC 实现,但在客户端负载均衡能力的帮助下,我们仍然能够绕行负载均衡器,降低负载均衡器的成本。
当前 Flink 已经在知乎拥有许多落地的应用场景了。我们基于 Flink 建设了数据集成平台,并利用 TiDB connector 提供了 TiDB to Hive 和 Hive to TiDB 的能力,解决了 ODS 层数据同步以及离线计算的数据在线提供服务的同步问题。在数据集成平台之外还有许其他的实时应用,比如商业团队的点击数据处理程序。再比如搜索里的时效性分析,还有关键指标的实时数仓。最后还有一些业务利用 Flink 将实时行为数据落到 TiDB 供在线查询。
展望
除了以上提到的这些进展,我们还有许多可以改善的方面,为 TiDB 和 Flink 的用户创造更多的价值。接下来就让我们看下未来还有哪些可以继续挖掘价值的方向。
TiDB x Flink 核心能力增强
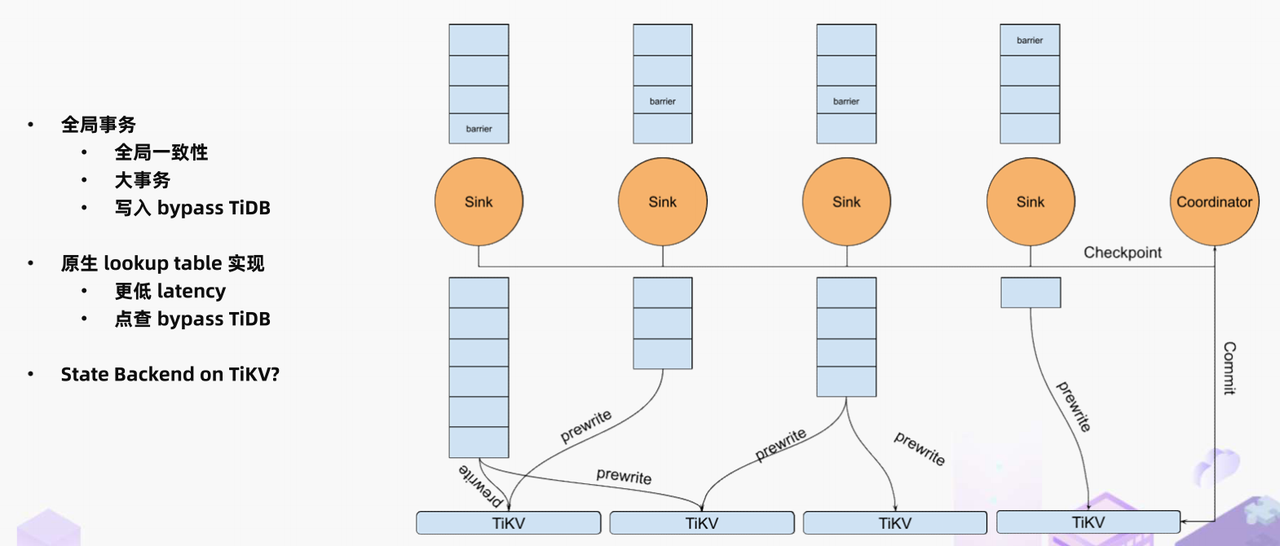
首先是全局事务支持。目前基于 JDBC 实现的 Flink sink 存在同 JDBC connector 一样的局限,无法实现分布式的全局事务。此外使用 JDBC 连接 TiDB 的同时也带来了 TiDB 最大事务尺寸的限制,无法支持超大事务的写入。当我们遇到有全局可见性要求或类似银行跑批任务的需求时,目前的 TiDB connector 仍然无法提供理想的能力。我们希望接下来实现原生的写入能力,直接以分布式的方式向 TiKV 上进行两步提交,从而实现全局大事务写入能力。全局事务不仅仅能带来事务隔离和大事务的收益,我们还可以通过将所有大流量的请求绕行 TiDB 的方式,彻底释放 tidb-server 的压力,彻底杜绝没必要的资源浪费。
还有一个改进方向是原生 lookup table 的支持,目前这一块儿也是基于 JDBC connector 实现的。虽然维表查询的吞吐通常不会特别大,但 bypass TiDB 仍然能够获得 latency 上的额外收益。而这个提升能够为流计算系统计算吞吐的提升和避免事件积压起到非常关键的正面作用。
最后还有一个尚未明确收益的改进方向是基于 TiKV 的 state backend,可能会解决一些场景下 checkpoint 慢的问题。
更多应用场景

在拥有了 TiDB 原生支持具备了许多新的能力之后,我们可以畅想未来 TiDB x Flink 能够支撑更多的应用场景。
比如当前的数据集成平台只支持批模式的数据抽取任务,在 TiDB 流批一体能力的帮助下,我们能够配合 Hudi 或 Iceberg 以非常低的成本完成所有 ODS 层数据的实时化。如果所有 ODS 层数据具备了实时的能力,数仓同学在考虑实时数仓的建设路径时就没有太多的前置依赖了。配合常见的实时埋点数据和实时 ODS 数据,完全按照业务价值的高低去安排数仓的实时化建设。
在实时数仓之外,随着技术的成熟还会有更多的实时应用场景诞生。比如我们能够以极低的成本从站上现有内容产出实时的内容池。再比如搜索引擎的实时索引更新,当然还有 demo 的内容交互数据实时统计等等。相信在知乎的 Flink SQL 平台建设完成后,一定会产生越来越多基于 TiDB x Flink 端到端的技术体系覆盖的应用场景。
最后如果大家对 TiDB x Flink 的生态整合或者 TiDB 在整个大数据生态的能力,可以在 GitHub 上关注 TiBigData 项目。首先欢迎大家在实际场景中尝试使用这个项目,如果在使用中遇到问题或有意见建议可以随时给项目提 issue。最后也希望有更多的开发者参与到这个项目的开发,我们一起让它为 TiDB 在大数据领域提供成熟完善的一站式解决方案。