获取完整原文和代码,公众号回复:09110252876
论文地址: http://arxiv.org/pdf/2012.03762v1.pdf
代码: 公众号回复:09110252876
来源: 香港中文大学
论文名称:Sparse Single Sweep LiDAR Point Cloud Segmentation via Learning Contextual Shape Priors from Scene Completion
原文作者:Xu Yan
内容提要
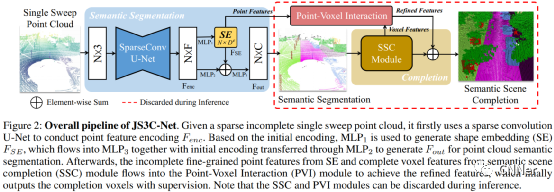
激光雷达点云分析是3D计算机视觉特别是自动驾驶的核心任务。然而,由于单扫描激光雷达点云存在严重的稀疏性和噪声干扰,实现准确的语义分割并非易事。在本文中,我们提出了一种新的稀疏激光雷达点云语义分割框架。在实际应用中,单个扫描点云的初始语义分割(SS)可以通过任何appealing网络实现,然后进入语义场景完成(SSC)模块作为输入。优化后的SSC模块通过合并激光雷达序列中的多帧作为监督,从序列激光雷达数据中学习上下文形状先验,完成稀疏单扫点云向密集单扫点云的转换。因此,它通过完全的端到端训练内在地改善了SS优化。此外,提出了点-体素交互(point - voxel Interaction, PVI)模块,进一步增强SS和SSC任务之间的知识融合,即促进点云不完整局部几何和完整体素全局结构的交互。大量的实验证明,我们的JS3CNet在SemanticKITTI和SemanticPOSS两种基准测试上都取得了优异的性能,分别提高了4%和3%。
主要框架及实验结果


声明:文章来自于网络,仅用于学习分享,版权归原作者所有,侵权请加上文微信联系删除。