By 超神经
内容一览:2019 年已经接近尾声,在这一年里,计算机视觉(CV)领域又诞生了大量出色的论文,提出了许多新颖的架构和方法,进一步提高了视觉系统的感知和生成能力。我们精选了 2019 年十大 CV 研究论文,帮你了解该领域的最新趋势,继之前推出的上系列和中系列之后,这是该系列的最后一个部分。Enjoy~
关键词:计算机视觉 精选论文 解读
近年来,计算机视觉(CV)系统已经逐渐成功地应用在医疗保健,安防,运输,零售,银行,农业等领域,也正在逐渐改变整个行业的面貌。
今年,CV 领域依然硕果累累,在各个顶尖会议中诞生了多篇优秀论文。我们从中精选了 10 篇论文以供大家参考、学习。限于篇幅,我们将解读分为了上、中、下三个篇章分期进行推送。
以下是这 10 篇论文完整的目录:
1. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
EfficientNet:卷积神经网络模型缩放的反思
2. Learning the Depths of Moving People by Watching Frozen People
通过观看静止的人来学习移动的人的深度
3. Reinforced Cross-Modal Matching and Self-Supervised Imitation Learning for Vision-Language Navigation
增强的跨模态匹配和自我监督的模仿学习,用于视觉语言导航
4. A Theory of Fermat Paths for Non-Line-of-Sight Shape Reconstruction
非视线形状重构的费马路径理论
5. Reasoning-RCNN: Unifying Adaptive Global Reasoning into Large-scale Object Detection
Reasoning-RCNN:将自适应全局推理统一到大规模目标检测中
6. Fixing the Train-Test Resolution Discrepancy
修复训练测试分辨率差异
7. SinGAN: Learning a Generative Model from a Single Natural Image
SinGAN:从单个自然图像中学习生成模型
8. Local Aggregation for Unsupervised Learning of Visual Embeddings
视觉聚合的无监督学习的局部聚合
9. Robust Change Captioning
强大的更改字幕
10. HYPE: A Benchmark for Human eYe Perceptual Evaluation of Generative Models
HYPE:人类对生成模型的 eYe 感知评估的基准
本文是序号 8-10 的详细解读,前面的内容请查看往期内容:
解读 | 2019 年 10 篇计算机视觉精选论文(上)
解读 | 2019 年 10 篇计算机视觉精选论文(中)
8

论文摘要
神经网络中的无监督学习方法对于促进 AI 的发展具有重大的意义,一方面是因为这种方法,不需要进行大量的标记,就可进行网络训练,另一方面,它们将是人为部署中,更好的通用模型。
但是,无监督的网络的性能长期落后于有监督网络,尤其是在大规模视觉识别领域。但最近有一种新的方法,可以弥补这一差距,它是通过训练深度卷积嵌入,以最大化非参数去进行实例分割和聚类。
这篇论文中,描述了一种训练嵌入函数以最大化局部聚合度量的方法,该方法可让相似的数据实例在嵌入空间中相互靠近,同时允许不同实例分开。该聚合指标是动态的,允许不同规模的软聚类产生。
该模型在几个大型视觉识别数据集上进行了评估,在 ImageNet 中的对象识别,Places 205 中的场景识别,以及 PASCAL VOC 中的对象检测方面,均实现了最先进的无监督转移学习性能。
核心思想
本文介绍了一种新颖的无监督学习算法,该算法可在潜在特征空间中对相似图像进行局部非参数聚合。
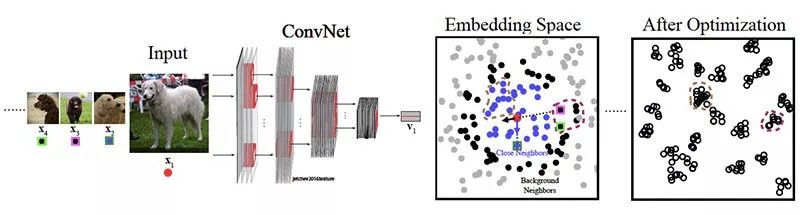
所提出的本地聚合( Local Aggregation,LA)过程的总体目标,是学习一种嵌入功能,该功能将图像映射到表示空间中的特征,在该表达空间中,相似的图像分组在一起,而不同的图像则会分开:
- 对于每个输入图像,使用深度神经网络将图像嵌入到低维空间中。
- 然后,该模型识别嵌入相似的近邻和背景近邻,这些特征用于设置判断邻近度的距离尺度。
- 通过优化,当前嵌入向量被推到更靠近其近邻,并进一步远离其背景近邻。
引入的过程产生的表示形式支持下游计算机视觉任务。
关键成就
在以下方面,本地聚合明显优于其他架构:
目标识别:经过 LA 培训的 ResNet-50 在 ImageNet 上,达到了 60.2% 的 top-1准确性,高于直接在监督任务上进行训练的 AlexNet ;
场景分类: LA 训练的 ResNet-50 在 Places 数据集,达到了 50.1% 的精度,展现了其强大的迁移学习性能。
目标检测:在 PASCAL 检测任务的无监督转移学习中,取得了最先进的性能(在ResNet-50 上的平均精度为 69.1%)。

所获荣誉
该论文在计算机视觉领域顶级会议 ICCV 2019 中,收获了最佳论文奖。
后续研究
探索使用基于非局部流形学习的先验检测相似性的可能性。
通过分析学习的多个步骤中的代表变化来改善差异检测。
将 LA 目标应用于其他领域,比如视频和音频。
将 LA 程序与生物视觉系统进行对比。
应用场景
这项研究对于计算机视觉研究而言,是将无监督学习用于现实世界中的重要一步,且使物体检测和对象识别系统,能够在不花费昂贵的注释费用的情况下正常运行。
代码获得
在 GitHub 上提供了 Local Aggregation 算法的 TensorFlow 实现。
地址:https://github.com/neuroailab/LocalAggregation
9

论文摘要
描述场景中发生的变化是一项重要的工作,但前提是生成的文本只关注语义相关的内容。因此,需要将干扰因素(例如视点变化)与相关变化(例如物体移动)区进行区分。
此文提出一种新颖的双重动态注意力模型(DUDA),以执行强大的变化文本描述。该模型学会了将干扰因素与语义变化区分开,通过对前后图像进行双重关注来定位变化,并通过自适应地关注必要的视觉输入(例如「之前」),通过动态扬声器准确地用自然语言描述它们。(或之后的图片)。
为了进一步探究此问题,我们收集了基于 CLEVR 引擎的 CLEVR-Change 数据集,其中包含 5 种类型的场景变更。我们以数据集为基准,并系统地研究了不同的变化类型和干扰因素的鲁棒性。在描述变化和本地化方面都展示了 DUDA 模型的优越性。
结果表明此方法是通用的,它在没有干扰因素的 Spot-the-Diff 数据集上,获得了最先进的性能。

核心思想
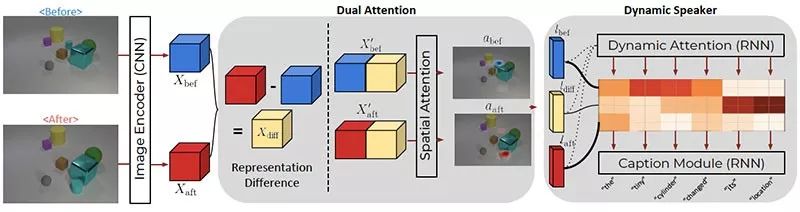
研究团队提出了用于变化检测和字幕说明的双重动态注意力模型(DUDA):
- 该模型包括用于更改本地化的 Dual Attention 组件,和用于生成更改描述的 Dynamic Speaker 组件。
- 这两个神经网络都是使用字幕级监督进行联合训练的,并且没有有关更改位置的信息。
- 给出「之前」和「之后」图像后,模型将检测场景是否已更改;如果已改变,它将在两个图像上定位变化,然后生成一个描述变化的句子,该句子是基于图像对在空间和时间上的信息。
本文还介绍了一个新的 CLEVR-Change 数据集,该数据集:
- 包含 8 万个「之前 /之后」图像对;
- 涵盖 5 种场景变化类型,例如颜色或材质变化,添加,放置或移动对象;
- 包括仅具有干扰因素的图像对(即照明/视点变化)和具有干扰因素和语义相关场景变化的图像。
关键成就
引入新的 CLEVR-Change 基准测试,可以帮助研究团体训练新模型,以用于:
- 当视点移动时,局部场景发生的变化;
- 正确引用复杂场景中的物体;
- 定义视点移动时物体之间的对应关系。
提出一个更改文字描述的 DUDA 模型,当在 CLEVR-Change 数据集上进行评估时,该模型在以下方面优于所有场景更改类型的基准:
- 总体句子流利度和与真实性的相似度(BLEU-4,METEOR,CIDEr 和 SPICE 度量);
- 更改本地化(指向游戏评估)。
所获荣誉
该论文被计算机视觉领域顶级会议 ICCV 2019 ,提名为最佳论文奖。
后续研究
收集来自真实图像的「之前 /之后」图像对数据集,并包含语义上的显着变化和干扰因素变化。
应用场景
DUDA 模型可以协助各种实际应用,包括:更改医学图像中的跟踪;设施监控;航空摄影。
10

论文摘要
生成模型通常使用人工评估来评价其输出的感知质量。自动化指标是嘈杂的间接代理,因为它们依赖于启发式方法或预训练的嵌入。然而直到现在,直接的人类评估策略都是临时的,既没有标准化也没有经过验证。
论文里进行的工作,是为生成现实的判断建立了一套黄金标准的人类方法。我们构建了人类 eYe 感知评估(HYPE)基准。
该基准是(1)基于感知的心理物理学研究;(2)在模型的随机采样输出的不同集合之间是可靠的;(3)能够产生可分离的模型性能;以及(4)在成本和时间上具有很高的效益。
我们介绍了两种变量:一种在自适应时间约束下测量视觉感知,以确定模型输出呈现真实阈值(例如 250ms),另一个代价更小的变量,它在没有时间限制的情况下,可以在假的和真实图像上,测量人为错误率。
我们使用 CelebA,FFHQ,CIFAR-10 和 ImageNet 这四个数据集,通过六个最先进的生成对抗网络和两种采样技术,对有条件和无条件图像生成进行 HYPE 测试。我们发现 HYPE 可以跟踪训练期间的模型改进,并且通过引导抽样验证了 HYPE 排名是一致且可重复的。

核心思想
由于自动度量标准在高维问题上不准确,并且人工评估不可靠且过度依赖任务设计,因此需要用于评估生成模型的系统性黄金标准基准。
为了解决这个问题,研究人员介绍了基准 Human eYe Perceptual Evaluation(HYPE),以及评估的方法有两种:
- 计算一个人需要多少时间来区分特定模型生成的真实图像和伪图像:花费的时间越长,模型越好。
- 测量不受时间限制的人为错误率:得分高于 50% 表示生成的伪图像看起来比真实图像更真实。
关键成就
引入用于评估生成模型的黄金基准:
- 依据于心理物理学研究;
- 可靠而且一致性好;
- 能够针对不同模型产生统计上可分离的结果;
- 在成本和时间上具有高效率。
所获荣誉
该论文被选做人工智能顶级会议 NeurIPS 2019 的口头报告。
后续研究
将 HYPE 扩展到其他生成任务,包括文本,音乐和视频生成。
代码获得
作者已经在线部署了 HYPE,任何研究人员都可以使用 Mechanical Turk 上载模型并检索 HYPE 分数。地址:https://hype.stanford.edu/
参考资料:https://www.topbots.com/top-ai-vision-research-papers-2019/
—— 完 ——