观点 | 用几何学提升深度学习模型性能,是计算机视觉研究的未来
选自 Alexgkendall.com
作者:Alex Kendall
机器之心编译
参与:候韵楚、黄小天
深度学习使计算机视觉得以蜕变。如今,绝大多数问题的最佳解决方案是基于端到端的深度学习模型,尤其是当卷积神经网络倾向于开箱即用后便深受青睐。但这些模型主要为大型黑箱,其透明度很差。
尽管如此,我们仍旧在深度学习领域获得了显著成果,即研究人员能通过一些数据以及使用基本的深度学习 API 所编写的20 余行代码来获得大量容易得到的成果。虽然这些成果很有突破性,但我认为它们往往过于理想化,且缺乏原则性理解
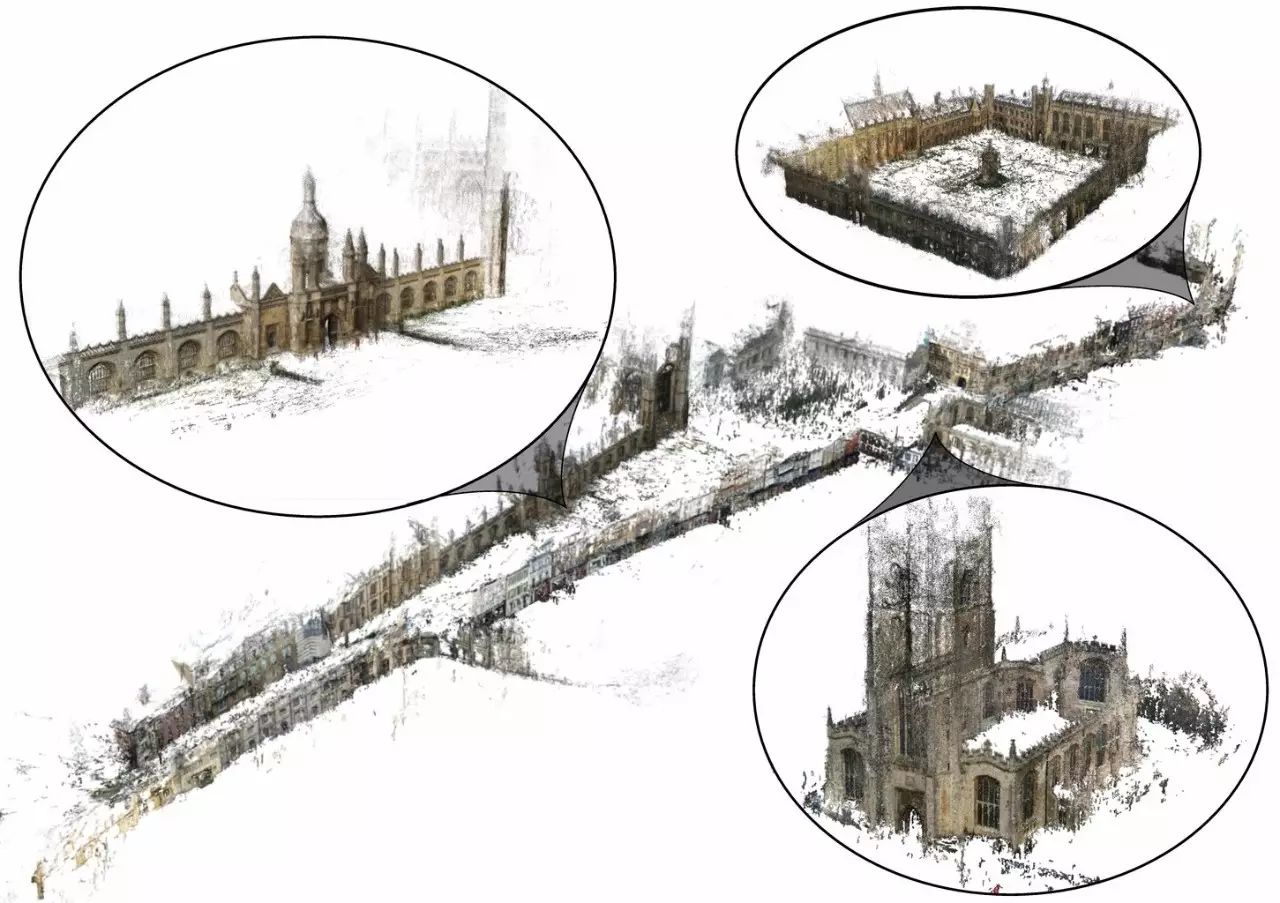
精选论文 | 三维视觉之点云识别【附PDF下载】
最近,由于自动驾驶,机器人等的发展,3d视觉逐渐引起了研究人员和工程师的关注。今天,两位主讲嘉宾从自己的角度为大家精选了近期处理3d 点云数据的几个代表性方法,和大家一起学习分享最新的研究成果。

颠覆传统计算架构:光神经网络硬件登上Nature
光纤以光的形式传输数据,是现代远程通信网络的支柱。但在分析这种数据时,我们需要把光转换为电子,然后用电子方法进行处理。光学曾被认为是一种潜在计算技术的基础,但由于电子计算发展迅速,光学计算在这条赛道上跑得很吃力。
解读 | 2019 年 10 篇计算机视觉精选论文(下)
内容一览:2019 年已经接近尾声,在这一年里,计算机视觉(CV)领域又诞生了大量出色的论文,提出了许多新颖的架构和方法,进一步提高了视觉系统的感知和生成能力。我们精选了 2019 年十大 CV 研究论文,帮你了解该领域的最新趋势,继之前推出的上系列和中系列之后,这是该系列的最后一个部分。Enjoy~
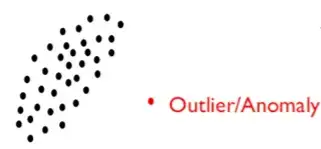
异常检测原理及其在计算机视觉中的应用
这篇文章涵盖了三件事,首先什么是视觉角度的异常检测?用于异常检测的技术有哪些?它在哪里使用?
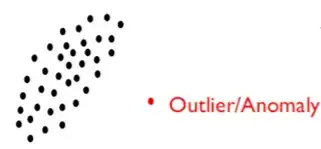
异常检测原理及其在计算机视觉中的应用
这篇文章涵盖了三件事,首先什么是视觉角度的异常检测?用于异常检测的技术有哪些?它在哪里使用?
人工智能、机器学习和认知计算入门指南
几千年来,人们就已经有了思考如何构建智能机器的想法。从那时开始,人工智能 (AI) 经历了起起落落,这证明了它的成功以及还未实现的潜能。如今,随时都能听到应用机器学习算法来解决新问题的新闻。从癌症检测和预测到图像理解和总结以及自然语言处理,AI 正在增强人们的能力和改变我们的世界。
WAIC AI开发者论坛:高性能计算、多模态交互、类脑计算全都有
2022 WAIC 世界人工智能大会已于近日在上海落幕。
9 月 3 日,在机器之心主办的 WAIC 2022·AI 开发者论坛上,2021 图灵奖得主为代表的全球最具影响力学术领袖、技术专家和企业高管发表主题演讲,演讲内容包括高性能计算、多模态交互、文本生成研究与应用、RPA、类脑计算等在内的最前沿议题。本次大会以「 AI 开发者所真正关注的」为主题,集中展示本年度人工智能领域最前沿技术成果和最新实践应用进展。
除了这些精彩的主题演讲,WAIC·AI 开发者论坛还揭晓了今年的 WAIC· 云帆奖得主,举

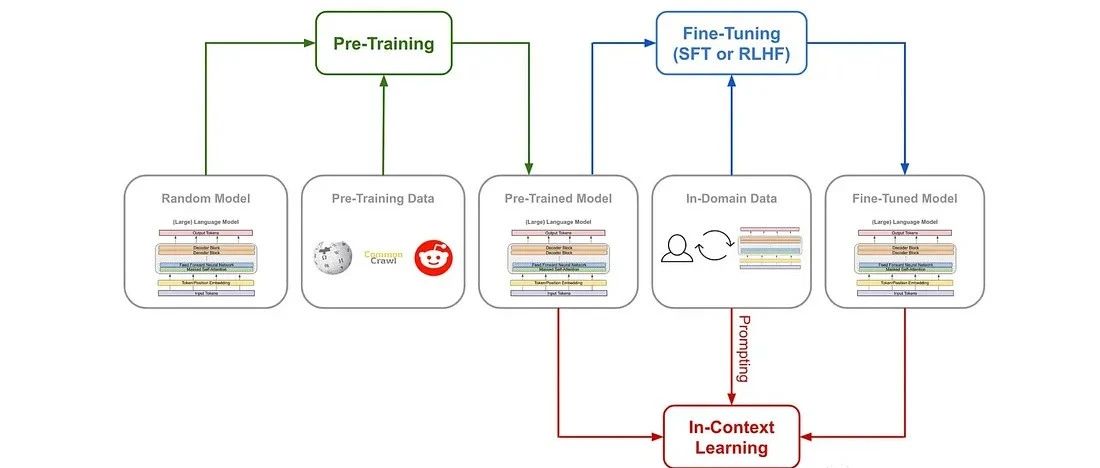
预训练、微调和上下文学习
最近语言模型在自然语言理解和生成方面取得了显著进展。这些模型通过预训练、微调和上下文学习的组合来学习。在本文中将深入研究这三种主要方法,了解它们之间的差异,并探讨它们如何有助于语言模型的学习过程。
软件开发|机器学习实践指南
你可能在各种应用中听说过机器学习machinelearning(ML),比如垃圾邮件过滤、光学字符识别(OCR)和计算机视觉。
机器学习笔记引言
从今天起就要开始认真的学习Machine Learning了。在网上查找了很多的资料,也大概看了下deeplearning.net上的一些教程。但是既没有一丝的学习基础,也没有过硬的python编程能力,而且英语阅读水平也跟不上,学起来真是相当的吃力。最后觉得刚上手的话还是跟着入门级的视频教程学比较好。搜索对比下来还是Andrew Ng的视频适合我这种基础差的人看,一方面学习门槛低,一方面又能学到不错的技术,更重要的是学习资源充足。在网上找到了中国海洋大学的黄同学整理翻译的Andrew Ng 2014年最新的视频和课件(重要的是有翻译。。),终于能够好好学学了。
Day6—江海一
百度/谷歌搜索“miniconda 清华”(是清华的conda镜像网站)进行下载。
我的一年AI算法工程师成长记
【导语】经常有朋友私信问,如何学python?如何敲代码?如何进入AI行业?正好回头看看自己这一年走过的路,进行一次经验总结。这是一篇关于如何成为一名AI算法工程师的长文,来看看你距离成为一名AI工程师还有多远吧。

HanLP《自然语言处理入门》笔记--9.关键词、关键句和短语提取
笔记转载于GitHub项目:https://github.com/NLP-LOVE/Introduction-NLP
盘点五大好用的学习网站——搜嗖工具箱
http://open.nlc.cn/onlineedu/client/index.htm
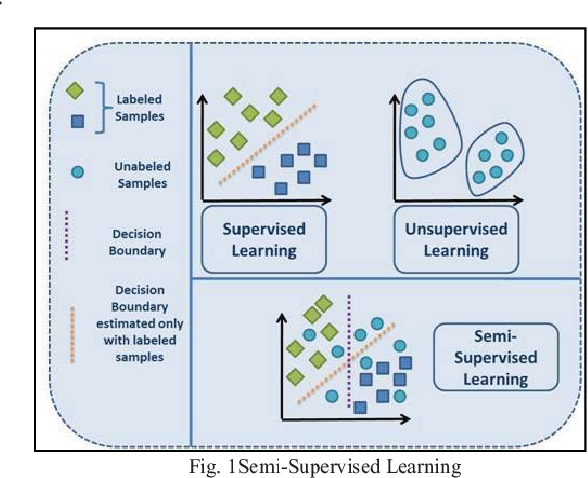
机器学习(二):有监督学习、无监督学习和半监督学习
3 学习(learning)
将很多数据丢给计算机分析,以此来训练该计算机,培养计算机给数据分类的能力。换句话说,学习指的就是找到特征与标签的映射(mapping)关系。这样当有特征而无标签的未知数据输入时,我们就可以通过已有的关系得到未知数据标签。
一份半监督学习的指南-伪标签学习
在ML中,有3种机器学习方法-监督学习、无监督学习和强化学习技术。 我们所知道的监督学习是指数据带有标签的情况, 无监督学习是仅存在数据而没有标签的情况,强化学习算法的思路非常简单,以游戏为例,如果在游戏中采取某种策略可以取得较高的得分,那么就进一步“强化”这种策略,以期继续取得较好的结果。
稀疏模型最新进展!马毅+LeCun强强联手:「白盒」非监督式学习|ICLR 2023
----
新智元报道
编辑:LRS
【新智元导读】白盒非监督学习模型性能再进一步!
最近马毅教授和图灵奖得主Yann LeCun联手在ICLR 2023上发表了一篇论文,描述了一种极简和可解释的非监督式学习方法,不需要求助于数据增强、超参数调整或其他工程设计,就可以实现接近 SOTA SSL 方法的性能。
论文链接:https://arxiv.org/abs/2209.15261
该方法利用了稀疏流形变换,将稀疏编码、流形学习和慢特征分析(slow feature analysis)相结合。
采

图灵奖得主Yann LeCun:AI要获得常识,自监督学习是那把钥匙
从婴儿时期的「物体恒存」开始,我们知道跟我们玩躲猫猫的大人其实并没有消失,他们就藏在某个地方,只是被某个东西挡住了。

Transformer预训练模型已经变革NLP领域,一文概览当前现状
在如今的 NLP 领域,几乎每项任务中都能看见「基于 Transformer 的预训练语言模型(T-PTLM)」成功的身影。这些模型的起点是 GPT 和 BERT。而这些模型的技术基础包括 Transformer、自监督学习和迁移学习。T-PTLM 可使用自监督学习从大规模文本数据学习普适性的语言表征,然后将学到的知识迁移到下游任务。这些模型能为下游任务提供优质的背景知识,从而可避免从头开始训练下游任务。
