快乐学AI系列——计算机视觉(4.篇外)什么是“卷积神经网络”
卷积神经网络(Convolutional Neural Network,CNN)是一种深度学习算法,常用于计算机视觉领域的图像分类、目标检测和图像分割任务中。它的核心思想是通过卷积运算从原始数据中提取特征,然后将这些特征传递给全连接层进行分类或回归。

快乐学AI系列——计算机视觉(4.篇外)什么是“卷积神经网络”
卷积神经网络(Convolutional Neural Network,CNN)是一种深度学习算法,常用于计算机视觉领域的图像分类、目标检测和图像分割任务中。它的核心思想是通过卷积运算从原始数据中提取特征,然后将这些特征传递给全连接层进行分类或回归。

快乐学AI系列——计算机视觉(4.篇外)什么是“卷积神经网络”
卷积神经网络(Convolutional Neural Network,CNN)是一种深度学习算法,常用于计算机视觉领域的图像分类、目标检测和图像分割任务中。它的核心思想是通过卷积运算从原始数据中提取特征,然后将这些特征传递给全连接层进行分类或回归。

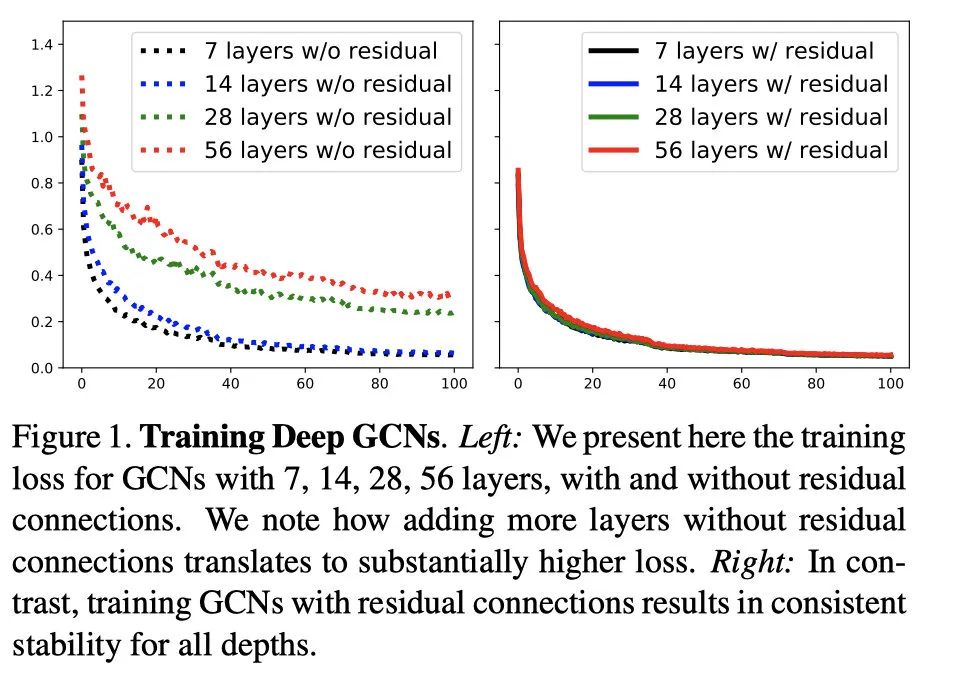
ICCV19开源论文 DeepGCNs: Can GCNs Go as Deep as CNNs?
GCN与CNN有很多相似之处。GCN的卷积思想也是基于CNN卷积的优秀表现所提出的,。GCN由于其表达形式和卷积方法特殊性,在节点分类任务(引文网络)中,只有简单的3-4层可以把任务完成的很好。但是对于一些其他的的任务,可能浅层的网络模型没有办法很好的处理数据。但是当把GCN的层数增多之后,会出现梯度消失和over-smoothing的问题,与当时CNN的层数加深出现的问题相似,因此自然想到了应用在CNN上的方法迁移到GCN上。
计算机视觉这一年:这是最全的一份CV技术报告
选自The M tank
机器之心编译
参与:蒋思源、刘晓坤
The M Tank 编辑了一份报告《A Year in Computer Vision》,记录了 2016 至 2017 年计算机视觉领域的研究成果,对开发者和研究人员来说是不可多得的一份详细材料。该材料共包括四大部分,在本文中机器之心对第一部分做了编译介绍,后续会放出其他部分内容。
内容目录
简介
第一部分
分类/定位
目标检测
目标追踪
第二部分
分割
超分辨率、风格迁移、着色
动作识别
第三部分
3D 目标
人体姿势估计
3D 重建
Assignment 2 | 斯坦福CS231n-深度学习与计算机视觉课程
该笔记是以斯坦福cs231n课程的python编程任务为主线,展开对该课程主要内容的理解和部分数学推导。这篇文章是第二篇。
CS231n简介
CS231n的全称是CS231n: Convolution

计算机视觉这一年:这是最全的一份CV技术报告
选自The M tank
机器之心编译
参与:蒋思源、刘晓坤
The M Tank 编辑了一份报告《A Year in Computer Vision》,记录了 2016 至 2017 年计算机视觉领域的研究成果,对开发者和研究人员来说是不可多得的一份详细材料。该材料共包括四大部分,在本文中机器之心对第一部分做了编译介绍,后续会放出其他部分内容。
内容目录
简介
第一部分
分类/定位
目标检测
目标追踪
第二部分
分割
超分辨率、风格迁移、着色
动作识别
第三部分
3D 目标
人体姿势估计
3D 重建
2020年计算机视觉技术最新学习路线总结 (含时间分配建议)
如今有大量的资源可以用来学习计算机视觉技术,那我们如何从众多教程中进行选择呢?哪个值得我们去投入时间呢?

2020年计算机视觉技术最新学习路线总结 (含时间分配建议)
如今有大量的资源可以用来学习计算机视觉技术,那我们如何从众多教程中进行选择呢?哪个值得我们去投入时间呢?

吕乐:面向医学图像计算的深度学习与卷积神经网络(65ppt)
【新智元导读】本文是美国国家研究院健康临床中心(NIH-CC)吕乐在GTC DC上的演讲整理,主题有关利用深度学习和深度神经网络进行医学影像分析。
放射医学中的深度神经网络:预防和精确医学的角度
深度

专访 | 潜心30年,知网知识系统如何从概念层次上计算自然语言
机器之心原创
作者:思源
近日,机器之心采访了语知科技的首席科学家董强先生,董强向我们详细介绍了一种基于 Common-sense 知识库体系从概念层次进行自然语言处理的技术。语知自然语言理解技术平台
内存计算显著降低,平均7倍实测加速,MIT提出高效、硬件友好的三维深度学习方法
随着传感器技术的发展和大量新兴应用场景(AR/VR/自动驾驶)的出现,三维深度学习成为了近期的研究热点。三维数据往往以点云的方式存储,近年来,研究人员抑或是选择先将点云离散化成结构化的、规整的栅格形式(voxels,可以类比 2D 的像素 pixels),再利用体素卷积神经网络(volumetric CNNs,可以看作 2D CNN 的三维推广)对栅格数据进行处理;抑或是选择直接在点云数据上进行卷积计算。

CNN太牛!微软计算机视觉在ImageNet挑战中首超人类视觉
Yann LeCun曾说,深度卷积神经网络(CNN)会“解决”ImageNet。但我们没想到进步会这么快。根据微软公司公布的信息,由于prelu激活函数和更好的初始化,微软亚洲研究院视觉计算组所开发的基于CNN的计算机视觉系统,在ImageNet 1000 挑战中首次超越了人类进行对象识别分类的能力。
微软研究团队在题为“Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification”的论
谷歌大脑深度学习从入门到精通视频课程[9.8]:计算机视觉——例子分析
AI100 已经引入 Hugo Larochelle 教授的深度学习课程,会在公众号中推送,并且对视频中的 PPT 进行讲解。课后,我们会设计一系列的问题来巩固课程中的知识。本节课是 Hugo La
Nature子刊研究颠覆常识:视网膜计算使眼睛先于大脑产生视觉信息
今天,我们可以看到计算机视觉(CV)系统在医疗保健,安全,运输,零售,银行,农业等领域的成功应用,已经深刻地改变了整个行业。

动态 | HCP Lab 12篇论文入选世界顶级计算机视觉会议CVPR 2019
全球计算机视觉三大顶会之一 CVPR 2019 (IEEE Conference on Computer Visionand Pattern Recognition) 于 6月 16~20日 在美国洛杉矶如期举办。

微软亚洲研究院:计算机看懂视频的步骤及未来努力方向
对于人类来说,看懂视频似乎是再简单不过的事情了。从出生就开始拥有视觉,人眼所看到的世界就是连贯动态的影像。视野中每一个动态的形象都被我们轻易的识别和捕捉。但这对于计算机来说就没那么容易了。对于计算机来说,画面内容的识别,动作的捕捉,都要经过复杂的计算才能得出。当计算机从视频中识别出一些关键词后,由于语义和句子结构的复杂性,还要涉及词汇的词性、时态、单复数等表达,要让计算机将单个的词汇组成通顺准确的句子也是难上加难。
那么让计算机看懂视频都要经过哪几步呢?
首先,识别视频里的内容。目前的图像识别研究大多基于C
谷歌大脑深度学习从入门到精通视频课程[9.8]:计算机视觉——例子分析
AI100 已经引入 Hugo Larochelle 教授的深度学习课程,会在公众号中推送,并且对视频中的 PPT 进行讲解。课后,我们会设计一系列的问题来巩固课程中的知识。本节课是 Hugo La
Nature子刊研究颠覆常识:视网膜计算使眼睛先于大脑产生视觉信息
今天,我们可以看到计算机视觉(CV)系统在医疗保健,安全,运输,零售,银行,农业等领域的成功应用,已经深刻地改变了整个行业。

动态 | HCP Lab 12篇论文入选世界顶级计算机视觉会议CVPR 2019
全球计算机视觉三大顶会之一 CVPR 2019 (IEEE Conference on Computer Visionand Pattern Recognition) 于 6月 16~20日 在美国洛杉矶如期举办。
