本系列是由“MATRIX.矩阵之芯”精炼的AI快速入门系列,特色是内容简洁,学习快速。 相关要求:学员需要掌握Python编程基础,另外还需要有一定的线性代数、概率论基础
卷积神经网络(Convolutional Neural Network,CNN)是一种深度学习算法,常用于计算机视觉领域的图像分类、目标检测和图像分割任务中。它的核心思想是通过卷积运算从原始数据中提取特征,然后将这些特征传递给全连接层进行分类或回归。
在传统的图像分类任务中,我们需要手动提取图像的特征,例如边缘、纹理、颜色等。然而,这些特征的提取是非常困难的,因为它们通常是高度抽象和主观的。而卷积神经网络的卷积层可以自动学习图像的特征,大大简化了特征提取的过程。因此,它可以更好地适应不同的任务和数据集。
卷积神经网络由多个卷积层、池化层和全连接层组成。卷积层是卷积神经网络的核心,它包括多个卷积核,每个卷积核都可以提取图像中的一种特征。卷积操作可以理解为将卷积核在图像上滑动,将图像中每个像素与卷积核中的权重进行乘积,再将乘积相加得到一个新的像素值,最终得到一个新的特征图。通过多个卷积层的堆叠,可以得到越来越抽象的特征图,从而更好地区分不同的物体。
------------------------
卷积核(Convolution Kernel)是卷积运算中的一个重要概念,它是一个可学习的滤波器,用来提取输入数据的特征。卷积操作可以理解为用一个小的窗口在输入数据上滑动,对每个窗口内的数据进行加权求和,得到一个新的值作为输出。这个小的窗口就是卷积核。
卷积核的大小通常是正方形或矩形,可以根据需要自行指定大小。卷积核的参数值是由模型训练得到的,通过反向传播算法不断更新,使得模型能够逐渐学习到更好的特征和参数,从而提高模型的性能。
在卷积神经网络中,卷积核被用来提取输入数据的特征。在每一层中,都会有若干个卷积核进行卷积操作,每个卷积核提取的特征不同。这样就可以从不同的角度提取输入数据的特征,从而得到更加丰富的特征表示。
假设我们有一张灰度图像,大小为5x5像素,像素值表示为矩阵:
1 2 3 4 5
6 7 8 9 10
11 12 13 14 15
16 17 18 19 20
21 22 23 24 25我们可以定义一个2x2的卷积核(也称为过滤器),如下所示:
1 0
0 -1卷积操作将卷积核放置在图像上,以每个像素为中心进行乘法并对结果求和。例如,将卷积核放置在第一个像素位置(1)上,我们得到卷积操作的结果为:(1 * 1) + (2 * 0) + (6 * 0) + (7 * -1) = -6。
在将卷积核应用于整个图像时,我们将其向右移动一个像素,然后再次应用卷积。我们重复此过程,直到将卷积核应用于图像的每个位置。最后,我们得到一个新的图像,大小为4x4像素,像素值表示为矩阵:
-6 -8 -10 -4
-11 -13 -15 -9
-16 -18 -20 -14
-21 -23 -25 -19这个矩阵经过卷积操作后提取了图像的边缘特征。可以看到,经过卷积操作后,原始图像中的垂直边缘被突出了出来,而水平边缘则被抑制了。这是因为卷积核中的权重与垂直边缘的像素值较为接近,而与水平边缘的像素值差异较大,因此垂直边缘的特征得到了突出,水平边缘的特征则被抑制。
--------------------------------
池化层是为了减小特征图的尺寸和参数数量,通常在卷积层之间添加。它可以将特征图中的每个小区域(例如2x2)压缩成一个单独的像素值,从而减少计算量和内存占用。
最后是全连接层,它接收所有汇集在一起的特征图,并将它们转换为向量进行分类或回归。全连接层与传统神经网络中的层类似,但是由于它们需要处理大量的特征,因此在卷积神经网络中使用的全连接层通常比传统神经网络中使用的层更少。
卷积神经网络的训练通常使用反向传播算法。反向传播算法是一种基于梯度下降的优化算法,可以通过计算网络预测与实际标签之间的误差来更新网络参数。通过多次迭代,网络可以逐渐学习到更好的特征和参数,从而提高模型的性能。
这就相当于是网络通过不断地自我调整来适应数据的过程,从而提高了网络对数据的理解和分类能力。因此,卷积神经网络成为了许多计算机视觉、语音识别、自然语言处理等领域中最为流行的深度学习模型之一。
在卷积神经网络中,卷积层和池化层的使用可以减少参数数量和计算量,从而使网络更加高效。同时,通过加入更多的卷积层和池化层,网络可以逐渐提取出更加抽象的特征,从而提高网络的性能。
除了卷积层和池化层之外,卷积神经网络还有许多其他的层,例如全连接层、批标准化层、Dropout层等等。这些层的使用可以进一步提高网络的性能,并且可以避免网络出现过拟合等问题。
卷积神经网络是一种非常强大的深度学习模型,可以在计算机视觉、语音识别、自然语言处理等领域中取得非常优秀的成果。在未来,随着深度学习技术的不断发展和完善,卷积神经网络将会在更多的领域中发挥出更加重要的作用。
我们举一个例子:用Keras库来构建一个简单的卷积神经网络,并用它来对手写数字进行分类。
首先,我们需要准备数据集,这里我们使用MNIST手写数字数据集,它包含了60,000个训练样本和10,000个测试样本。可以在Keras中直接下载和加载这个数据集:
from keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
这个数据集中的图像都是28x28像素的灰度图像,像素值的范围是0到255。我们需要将这些图像转换成网络可以处理的形式,即将像素值缩放到0到1之间,并将其转换为4维张量,张量的形状为(样本数,高度,宽度,通道数)。
train_images = train_images.reshape((60000, 28, 28, 1))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000, 28, 28, 1))
test_images = test_images.astype('float32') / 255
接下来,我们构建一个简单的卷积神经网络模型。这个模型包含了两个卷积层,一个池化层和两个密集连接层。
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
最后,我们编译模型并开始训练。
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])model.fit(train_images, train_labels, epochs=5, batch_size=64)
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('test_acc:', test_acc)
通过训练,我们可以看到模型的准确率随着迭代次数的增加而不断提高。最后我们可以使用测试集对模型进行评估,并输出测试集的准确率。
这是一个简单的卷积神经网络的例子,它可以很好地完成手写数字的分类任务。在实际应用中,我们可以根据具体任务的需求来设计更加复杂的卷积神经网络。
以下是一个判断手写数字的小案例:
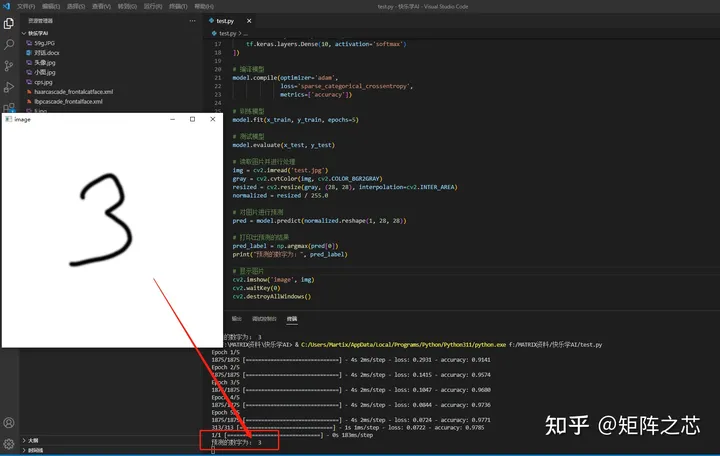
import tensorflow as tf
import numpy as np
import cv2加载MNIST数据集
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()归一化数据
x_train, x_test = x_train / 255.0, x_test / 255.0
构建模型
model = tf.keras.models.Sequential([
tf.keras.layers.Reshape((28, 28, 1), input_shape=(28, 28)),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])训练模型
model.fit(x_train, y_train, epochs=5)
测试模型
model.evaluate(x_test, y_test)
读取图片并进行处理
img = cv2.imread('test.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
resized = cv2.resize(gray, (28, 28), interpolation=cv2.INTER_AREA)
normalized = resized / 255.0对图片进行预测
pred = model.predict(normalized.reshape(1, 28, 28, 1))
打印出预测的结果
pred_label = np.argmax(pred[0])
print("预测的数字为:", pred_label)显示图片
cv2.imshow('image', img)
cv2.waitKey(0)
cv2.destroyAllWindows()