- 背景
- zeppelin不提供per job模式
- 实时平台开发周期长
- 基于zeppelin开发一个简易实时平台
- 开发zeppelin Interpreter
- 提交sql任务
- 提交jar任务
背景
随着flink的蓬勃发展,zeppelin社区也大力推进flink与zeppelin的集成.zeppelin的定位是一种使用sql或者scala等语言的一个交互式的分析查询分析工具。
Web-based notebook that enables data-driven,
interactive data analytics and collaborative documents with SQL, Scala and more.所以zeppelin与flink或者是其他的解释器集成的时候,就会有这么一个架构的特点,我需要启动一个处理数据的服务,相关的任务都提交到这个上面,拿flink来说,就是需要启动一个flink的集群,比如local、remote、session模式的集群。当我们执行一些flink sql的时候,都是提交到这个集群来执行的。
zeppelin不提供per job模式
但是我们在生产环境中,对于一些flink的流式任务,我们一般会采用per job的模式提交任务,主要是为了任务资源的隔离,每个任务互不影响。目前zeppelin是不支持这种模式的。所以很多公司都会开发一个自己的实时流式任务计算平台,可以实现使用sql或者jar的方式通过平台来提交任务到集群,避免了底层一些复杂的操作,使一些只会sql的人也能开发flink任务。
实时平台开发周期长
但是开发一个实时计算平台其实是相对比较复杂的,它需要有前端的写sql的页面,后端的提交逻辑,以及前后端的交互等等。所以我的想法是既然zeppelin已经提供了我们做一个实时平台的很多的功能,比如写sql的页面、前后端交互、提交任务、获取任务的状态等等,那么我们是不是可以用zeppelin来开发一个简化版的实时计算平台呢。
基于zeppelin开发一个简易实时平台
今天我们谈谈怎么通过zeppelin来实现一个简易的实时平台,目的是可以把flink的sql和jar的流式任务以per job的方式提交到yarn集群。
我们简单的看下zeppelin中flink 解释器的源码,他底层是使用了flink scala shell,具体相关内容可以参考 Flink Scala REPL :https://ci.apache.org/projects/flink/flink-docs-stable/ops/scala_shell.html.
zeppelin在提交flink的任务的时候,会判断下集群是否启动,如果没有启动flink集群,会根据设置的模式(local、yarn)先启动一个非隔离模式的flink集群(remote模式需要提前启动好一个集群),然后客户端保持着和服务器的连接,后续有用户提交的任务,就把任务提交到刚起启动的集群。我研究了一下代码觉得在这个上面加一个per job模式的话可能会破坏原来的架构,改动还会比较大,所以后来想自己做一个zepplin的解释器,功能就是通过sql或者jar的方式专门用来提交flink的流式任务。
开发zeppelin Interpreter
具体zeppelin的Interpreter的开发可以参考这篇文章。
https://zeppelin.apache.org/docs/0.9.0-preview1/development/writing_zeppelin_interpreter.html
核心的代码就是继承抽象类Interpreter,实现其中的几个方法,我们简单来讲讲。
public abstract class Interpreter {/**
- 初始化的时候调用,可以在这个里面加一些系统初始化的工作,这个方法只调用一次。
- 写过flink自定义source和sink的同学应该不会陌生。
*/
@ZeppelinApi
public abstract void open() throws InterpreterException;/**
- 释放Interpreter资源,也只会被调用一次。
*/
@ZeppelinApi
public abstract void close() throws InterpreterException;/**
- 异步的运行输入框里面的代码并返回结果。.
- @param st 就是页面那个框里你输入的东西
*/
@ZeppelinApi
public abstract InterpreterResult interpret(String st,
InterpreterContext context)
throws InterpreterException;
}
除了上面列出来的这几个,还有其他的几个,我这里就不罗列代码了,大家有兴趣的可以自己看下。
底层我使用的是flink application模式来提交的任务,在open里面做一些提交flink初始化的工作,比如构造配置文件,启动yarnClient等等。在interpret方法解析内容,执行提交任务的工作。
最终我们实现了可以通过jar包和sql的方式来提交任务到yarn集群。
提交sql任务
我们可以指定一些任务的参数,比如jobname,并行度、checkpoint间隔等等,页面大概长这个样子,提交任务之后,可以在yarn集群看到相关的任务。
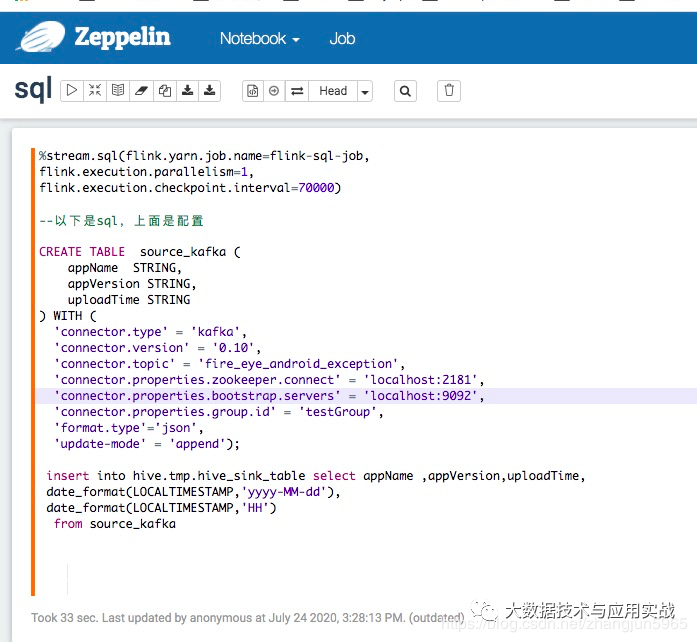
在这里插入图片描述
提交jar任务
首先把相应的jar上传到hdfs相关路径,然后提交任务之前,指定jar的路径,以及jobname、并行度等等,正文就不需要写什么了,然后把这个任务提交到yarn集群。
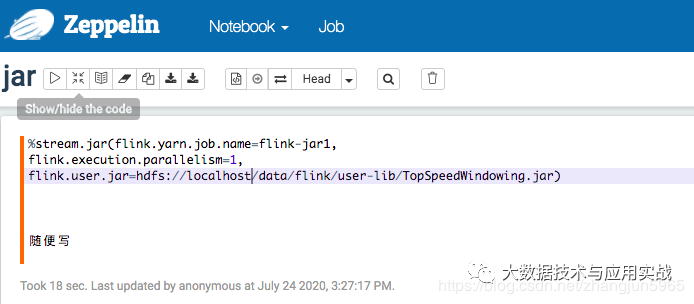
在这里插入图片描述
目前只是实现了一些核心的功能,还有一些其他的功能需要后续完善。