炎炎夏日,为自己的博客安装一台云空调吧!
感谢云游君提供的开源项目air-conditioner,如果GitHub抽风访问不了的话,可以在Gitee上拉取源码,我已经将大佬代码fork过来了。Gitee地址

Apache Hadoop 权限提升漏洞风险预警(CVE-2018-8029)| 安全情报
近日,腾讯云安全中心监测到Apache Hadoop 被爆存在本地提权漏洞(CVE-2018-8029),攻击者利用该漏洞可将能提升到 yarn 权限的帐户提升到 root 最高权限。 为避免您的业务受影响,腾讯云安全中心建议使用 Apache Hadoop 的用户及时开展安全自查,如在受影响范围,请您及时进行更新修复,避免被外部攻击者入侵。同时建议云上租户免费开通「安全运营中心」-安全情报,及时获取最新漏洞情报、修复方案及数据泄露情况,感知云上资产风险态势。 【风险等级】 官方评级:严重(Critica
2021年大数据Spark(四):三种常见的运行模式
Spark 框架编写的应用程序可以运行在本地模式(Local Mode)、集群模式(Cluster Mode)和云服务(Cloud),方便开发测试和生产部署。
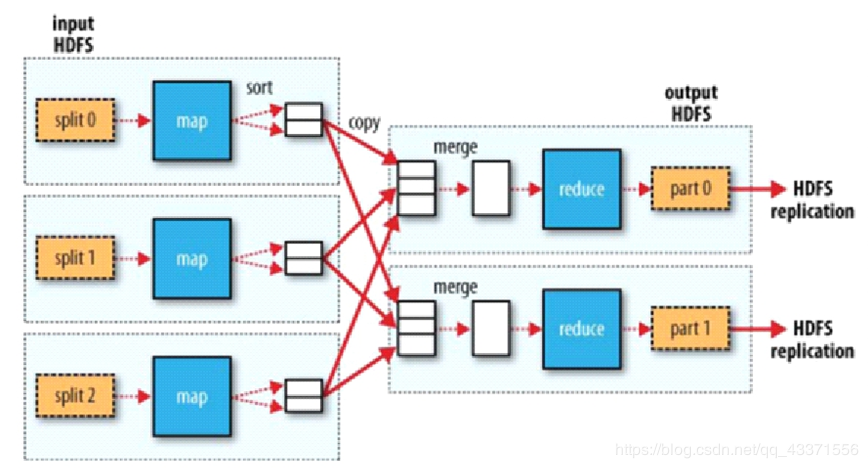
Hadoop技术(二)资源管理器YARN和分布式计算框架MapReduce
计算节点和存储节点是相同的,也就是说,MapReduce框架和Hadoop分布式文件系统(HDFS)在同一组节点上运行。此配置使框架可以在已经存在数据的节点上有效地调度任务,从而在整个群集中产生很高的聚合带宽。
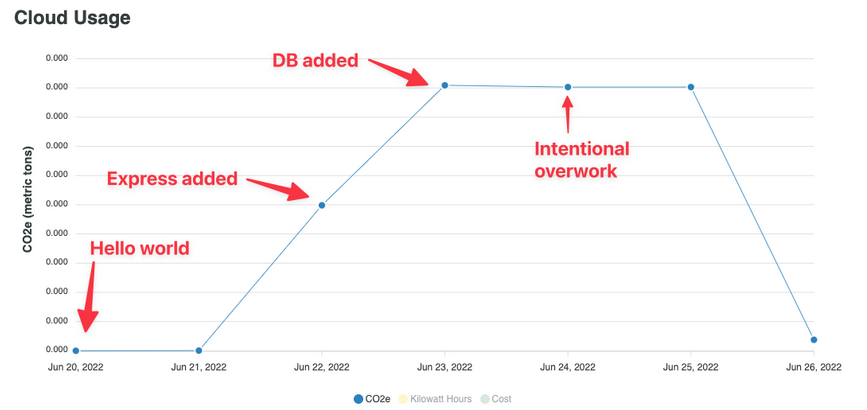
如何通过可观察性提高云原生可持续性
目前,由于一些不同的原因,云计算服务增长对成本的影响现在开始影响企业的预算,帮助估计、监控和简化成本的工具数量也在增长。
将Hadoop作为基于云的托管服务的优劣势分析
Apache Hadoop是一种开源软件框架,能够对分布式集群上的大数据集进行高吞吐量处理。Apache模块包括Hadoop Common,这是一组常见的实用工具,可以通过模块来运行。这些模块还包括:Hadoop分布式文件系统(HDFS)、用于任务调度和集群资源管理的 Hadoop YARN以及Hadoop MapReduce,后者是一种基于YARN的系统,能够并行处理庞大的数据集。
Apache还提供了另外的开源软件,可以在Hadoop上运行,比如分析引擎Spark(它也能独立运行)和编程语言Pig。
Hadoop 之所以广受欢迎,就是因为它为使用大众化硬件处理大数据提供了一种几乎没有限制的环境。添加节点是个简单的过程,对这个框架没有任何负面影响。 Hadoop具有高扩展性,能够从单单一台服务器灵活扩展到成千上万台服务器,每个集群运行自己的计算和存储资源。Hadoop在应用程序层面提供了高可用性,所以集群硬件可以是现成的。
实际的使用场合包括:在线旅游(Hadoop声称它是80%的网上旅游预订业务的可靠的大数据平台)、批量分析、社交媒体应用程序提供和分析、供应链优化、移动数据管理、医疗保健及更多场合。
它有什么缺点吗? Hadoop很复杂,需要大量的员工时间和扎实的专业知识,这就阻碍了它在缺少专业IT人员的公司企业的采用速度。由于需要专家级管理员,加上广泛分布的集群方面需要庞大的成本支出,从中获得商业价值也可能是个挑战。I
集群管理也可能颇为棘手。虽然Hadoop统一了分布式计算,但是配备和管理另外的数据中心、更不用说与远程员工打交道,增添了复杂性和成本。结果就是,Hadoop集群可能显得过于孤立。
将Hadoop作为基于云的托管服务的优劣势分析
Apache Hadoop是一种开源软件框架,能够对分布式集群上的大数据集进行高吞吐量处理。Apache模块包括Hadoop Common,这是一组常见的实用工具,可以通过模块来运行。这些模块还包括:Hadoop分布式文件系统(HDFS)、用于任务调度和集群资源管理的 Hadoop YARN以及Hadoop MapReduce,后者是一种基于YARN的系统,能够并行处理庞大的数据集。
Apache还提供了另外的开源软件,可以在Hadoop上运行,比如分析引擎Spark(它也能独立运行)和编程语言Pig。
Hadoop 之所以广受欢迎,就是因为它为使用大众化硬件处理大数据提供了一种几乎没有限制的环境。添加节点是个简单的过程,对这个框架没有任何负面影响。 Hadoop具有高扩展性,能够从单单一台服务器灵活扩展到成千上万台服务器,每个集群运行自己的计算和存储资源。Hadoop在应用程序层面提供了高可用性,所以集群硬件可以是现成的。
实际的使用场合包括:在线旅游(Hadoop声称它是80%的网上旅游预订业务的可靠的大数据平台)、批量分析、社交媒体应用程序提供和分析、供应链优化、移动数据管理、医疗保健及更多场合。
它有什么缺点吗? Hadoop很复杂,需要大量的员工时间和扎实的专业知识,这就阻碍了它在缺少专业IT人员的公司企业的采用速度。由于需要专家级管理员,加上广泛分布的集群方面需要庞大的成本支出,从中获得商业价值也可能是个挑战。I
集群管理也可能颇为棘手。虽然Hadoop统一了分布式计算,但是配备和管理另外的数据中心、更不用说与远程员工打交道,增添了复杂性和成本。结果就是,Hadoop集群可能显得过于孤立。
连夺双奖,腾讯云大数据云原生究竟凭什么?
300+参评项目,100+入围项目,10000+开发者公开票选,20+专家评审,10+主编团打分,历经数月打磨,由 InfoQ 发起组织的【 2020 中国技术力量年度榜单评选】结果揭晓: 腾讯云大数据云原生技术脱颖而出,荣获 2020年度十大云原生创新技术 早前,在2020年7月可信云大会上 腾讯云大数据云原生已荣获评年度技术最佳实践 那么腾讯云大数据云原生究竟凭什么能连续拿走两座大奖呢? 大数据云原生作为当前行业内热门的钻研话题,未来发展前景及趋势均不可小觑。各大云厂商、大型互联网企业都在尝试
连夺双奖,腾讯云大数据云原生究竟凭什么?
300+参评项目,100+入围项目,10000+开发者公开票选,20+专家评审,10+主编团打分,历经数月打磨,由 InfoQ 发起组织的【 2020 中国技术力量年度榜单评选】结果揭晓: 腾讯云大数据云原生技术脱颖而出,荣获 2020年度十大云原生创新技术 早前,在2020年7月可信云大会上 腾讯云大数据云原生已荣获评年度技术最佳实践 那么腾讯云大数据云原生究竟凭什么能连续拿走两座大奖呢? 大数据云原生作为当前行业内热门的钻研话题,未来发展前景及趋势均不可小觑。各大云厂商、大型互联网企业都在尝试
在单台云主机搭伪分布式hadoop环境
Hadoop是大数据的基础框架模型,处理大数据,不应只谈偏向业务环境的大数据(如超市买婴儿尿不湿同时还应该推荐啤酒的经典案例),作为解决方案经理,技术是不能缺少的,否则存在忽游的嫌疑。:) 做解决方案经理,技术+业务,个人理解,技术应占到60%,业务占到40%,说到业务其实客户比我们更懂,因此技术非常重要。前面我们讲到过大数据的环境搭建,今天我们用单台云主机(或自建vmware虚机)进行Hadoop所有组件的实际应用,再次加深大数据的技术底蕴。

hadoop-4:hadoop-flink实时计算集群生产级优化
1./app/3rd/hadoop-3.3.1/etc/hadoop/capacity-scheduler.xml 优化项
Hadoop3.3新版本发布【整合了腾讯云】
问题导读
1.Hadoop3.3支持JDK哪个版本?
2.SCM是什么?
3.YARN应用程序做了哪些改进?
4.整合腾讯云实现了什么文件系统?
1.支持ARM
这是第一个支持ARM的版本。
2.Protobuf从2.5.0升级到新版本
Protobuf从2.5.0升级到3.7.1
3.支持Java11
支持Java11
4.支持模拟AuthenticationFilter过滤器
外部服务或YARN服务可能需要根据使用Web协议的用户行为来调用WebHDFS或YARN REST API。最好在AuthenticationFilter或类似的扩展中支持模拟机制。
CDP私有云基础版7.1.6的新功能是什么?
根据IDG的说法,当客户考虑更新到产品的最新版本时,他们期望新功能、增强的安全性和更好的性能,但越来越希望拥有更简化的升级过程。伴随着CDP私有云的每个新版本,我们正在努力提供这些内容。伴随着许多新功能,我们正在尽可能简化升级过程。在此博客中,我们将介绍7.1.6版本中的新功能以及从HDP进行的新的就地升级,从而完全消除了替换基础架构和数据迁移的麻烦。
CDP私有云基础版7.1.6的新功能是什么?
根据IDG的说法,当客户考虑更新到产品的最新版本时,他们期望新功能、增强的安全性和更好的性能,但越来越希望拥有更简化的升级过程。伴随着CDP私有云的每个新版本,我们正在努力提供这些内容。伴随着许多新功能,我们正在尽可能简化升级过程。在此博客中,我们将介绍7.1.6版本中的新功能以及从HDP进行的新的就地升级,从而完全消除了替换基础架构和数据迁移的麻烦。
基于腾讯云对象存储跑hadoop任务实战二
在前一篇文章中《基于腾讯云对象存储跑hadoop任务实战一》介绍了如何部署和配置hadoop集群直接分析存储在腾讯云对象存储上的数据。这篇文章介绍一些性能优化的参数调优。
CDP私有云基础版7.1.6版本概要
Cloudera于2021年3月宣布发布Cloudera Data Platform(CDP)私有云(PvC)基本版本7.1.6和Cloudera Manager版本7.3.1。这些版本引入了从HDP 3到CDP私有云基础版的直接升级路径,同时添加了许多增强功能以简化从CDH 5和HDP 2的升级和迁移路径,并汇总了先前版本中的所有先前维护增强功能。
flink教程-flink 1.11 集成zeppelin实现简易实时计算平台
随着flink的蓬勃发展,zeppelin社区也大力推进flink与zeppelin的集成.zeppelin的定位是一种使用sql或者scala等语言的一个交互式的分析查询分析工具。
大数据平台如何进行云原生改造
如今,企业都面临着日益增长的数据量、各种类型数据的实时化和智能化处理的需求。此时,云原生大数据平台的高弹性扩展、多租户资源管理、海量存储、异构数据类型处理及低成本计算分析的能力,受到了大家的欢迎。但企业应该如何做好大数据平台的云原生改造和升级呢?
flink实战-实时计算平台通过api停止流任务
今天我们主要讲一下如何通过api的方式来停止一个通过per job模式部署在yarn集群上的任务。
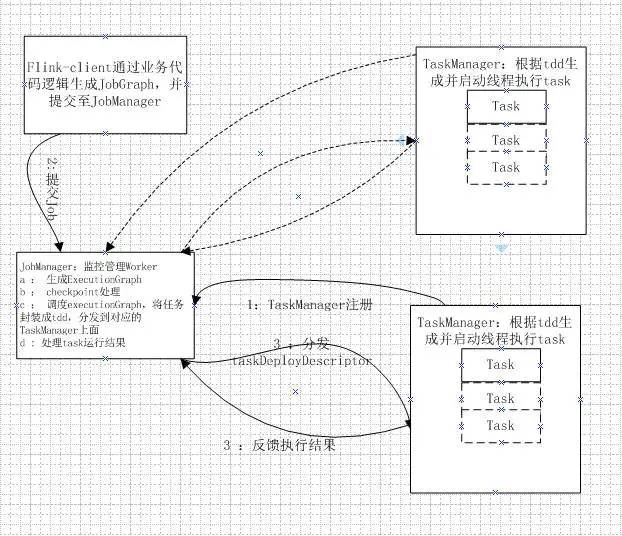
实时计算双星-Flink VS Spark 部署模式对比
本文主要对Flink和Spark集群的standalone模式及on yarn模式进行分析对比。Flink与Spark的应用调度和执行的核心区别是Flink不同的job在执行时,其task同时运行在同一个进程TaskManager进程中;Spark的不同job的task执行时,会启动不同的executor来调度执行,job之间是隔离的。