在前一篇文章中《基于腾讯云对象存储跑hadoop任务实战一》介绍了如何部署和配置hadoop集群直接分析存储在腾讯云对象存储上的数据。这篇文章介绍一些性能优化的参数调优。
把core-site.xml里的fs.defaultFS替换为你的bucket的cosn根目录 cosn://testshhadoop-xxxxx(注意线上环境不要这么干,这么做仅仅是为了测试,除非你知道自己在做什么),重启hdfs、yarn、MapReduce服务,通过hadoop自带的hadoop jar hadoop-mapreduce/hadoop-mapreduce-client-jobclient-tests.jar TestDFSIO,可以测试cosn的上传、下载性能。我机器的配置,默认内网带宽限制是1.5Gbps,如果买更好的机型,内网带宽限制也会相应增大。

上传速度优化
用户COSN的默认配置,执行命令: time hadoop jar /usr/hdp/2.6.xxxx/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-tests.jar TestDFSIO -write -nrFiles 100 -size 500MB
会生成100个task任务,取决于yarn、MapReduce的每个task任务的资源限制配置,和机型的内存、cpu,每个yarn的node节点会并行跑若干个container,每个container执行一个task任务,即上传一个文件。
每个container上传文件的速度,取决于几个cosn参数配置:
1、fs.cosn.block.size 每个上传分块的大小,默认8MB
2、fs.cosn.buffer.size 上传总缓存大小,默认32MB,
3、fs.cosn.upload_thread_pool 并发上传的线程数,默认5*线程核心数
fs.cosn.block.size是每个线程每次上传一个分块的大小,这个分块大小也是实际存储在COS上的分块大小。这个数值设置太小,会导致上传速度打不满网卡,建议设置稍微大一点,8MB到128MB都是可以的选择。cos的一个对象最多有10000个分块,所以分块大小还决定了对象的最大值。例如:分块大小默认8MB,那么能够上传的最大对象大小为8MB * 10000 ≈ 80GB。
fs.cosn.buffer.size需要是fs.cosn.block.size 的整数倍,决定了上传池总缓存的大小,这个缓冲池是全局的,进程内唯一,所以根据机器内存大小,可以调整下这个值。如果内存缓存分配完,cosn会继续用硬盘来缓存上传分块。内存缓存肯定比硬盘缓存快,所以如果机器资源允许,这个值可以设置稍微大一点。
fs.cosn.upload_thread_pool是并发上传的线程数,因为上传主要消耗网络IO而不是CPU,所以线程数不需要太多,可以设置为机器核的1倍或者2倍。
实际测试,采用默认配置的时候,可以用满1.5Gbps内网限制。如果跑不满,可以尝试增加上面三个参数的数值。
下载速度优化
测试读的命令为:time hadoop jar /usr/hdp/2.6.xxxx/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-tests.jar TestDFSIO -read -nrFiles 100 -size 500MB
会生成100个task任务,取决于yarn、MapReduce的每个task任务的资源限制配置,和机型的内存、cpu,每个yarn的node节点会并行跑若干个container,每个container执行一个task任务,即下载一个文件。
每个container下载文件的速度,取决于几个cosn参数配置:
1、fs.cosn.read.ahead.block.size 下载预读每个分块大小(注意这个分块和上传分块、cos存储分块大小都无关),默认512KB
2、fs.cosn.read.ahead.queue.size 下载预读队列长度,默认10个
3、每个下载文件的stream流并发下载最大线程数,这个没有单独的配置,采用的是 fs.cosn.read.ahead.queue.size值
实际测试,采用默认配置的时候,1.5Gbps内网只能用到800Mbps左右。因为默认下载预读块512KB有点小,这个数决定了每次range下载文件部分内容的请求大小,设置到8MB的时候,可以跑满1.5Gbps。
内存占用优化
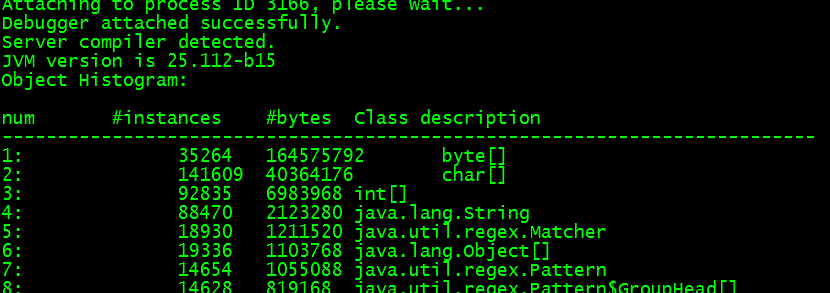
除了MapReduce框架,程序能够控制的主要就是上传、下载的缓存。但是测试发现,每个container占用的初始内存都比较大。通过jmap -histo打印出堆文件的内存使用:
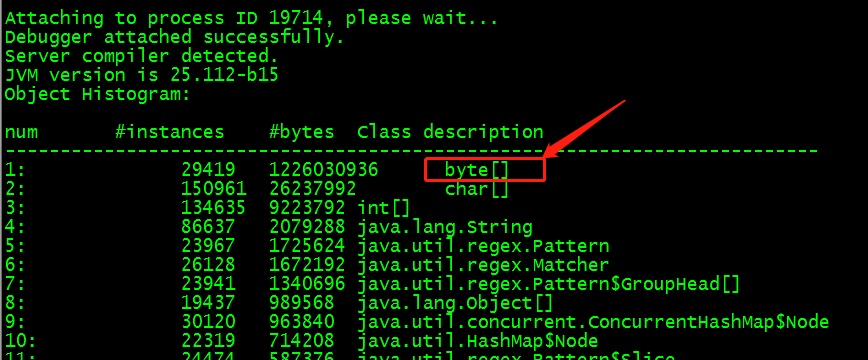
发现消耗内存最多的竟然是byte[]数组。大小达到了1.2GB,远大于cosn默认的上传缓存池大小32MB + 每个read流下载预读缓存大小5MB*read流个数。这个内存到底是哪里消耗的呢?
通过jmap -F -dump:format=b,file=jmap.binary.log pid,把一个map task的进程的堆内存dump为一个二进制文件。再通过eclipse的MAT插件打开分析一下:
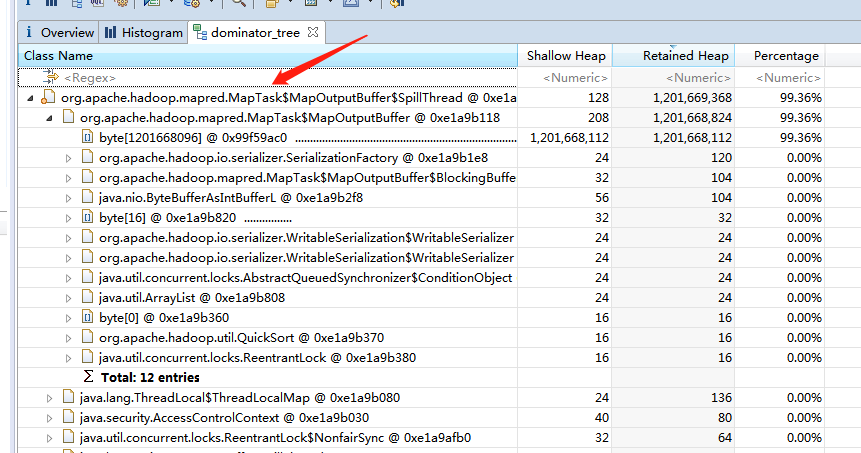
这些bypte数组都是MapReduce框架分配的,查了下源码,map任务会根据mapreduce.task.io.sort.mb 参数,设置一个byte数组的缓存,来缓存中间结果,避免map任务的中间结果频繁写回hdfs。如果map task是一个纯上传、下载任务,并没有什么中间结果,可以在启动任务的时候通过-D设置这个参数小一点,来减小无用内存分配。设置这个参数为128MB,再通过jmap查看map task进程的堆内存,果然降下来了。