大数据平台是否更应该容器化?
作者颜卫,腾讯高级后台开发工程师,专注于Kubernetes大规模集群管理和资源调度,有过万级集群的管理运维经验。目前负责腾讯云TKE大规模Kubernetes集群的大数据应用托管服务。
Hive计算引擎大PK,万字长文解析MapRuce、Tez、Spark三大引擎
Hive从2008年始于FaceBook工程师之手,经过10几年的发展至今保持强大的生命力。截止目前Hive已经更新至3.1.x版本,Hive从最开始的为人诟病的速度慢迅速发展,开始支持更多的计算引擎,计算速度大大提升。
Hive计算引擎大PK,万字长文解析MapRuce、Tez、Spark三大引擎
Hive从2008年始于FaceBook工程师之手,经过10几年的发展至今保持强大的生命力。截止目前Hive已经更新至3.1.x版本,Hive从最开始的为人诟病的速度慢迅速发展,开始支持更多的计算引擎,计算速度大大提升。
持续引领大数据行业发展,腾讯云发布全链路数据开发平台WeData
9月11日,在腾讯全球数字生态大会大数据专场上,腾讯云大数据产品副总经理雷小平重磅发布了全链路数据开发平台WeData,同时发布和升级了流计算服务、云数据仓库、ES、企业画像等6款核心产品,进一步优化和提升了腾讯云大数据的全托管能力,助力企业从基础设施层、场景开发层以及行业应用层快速构建一站式大数据平台能力。 「 借助WeData,企业数据开发门槛降低60%」 雷小平表示:“构建大数据开发平台是企业数字化转型的关键步骤,然而从数据集成到开发调度等涉及的模块众多,导致整个平台的维护和升级成本非常高
将Hadoop作为基于云的托管服务的优劣势分析
Apache Hadoop是一种开源软件框架,能够对分布式集群上的大数据集进行高吞吐量处理。Apache模块包括Hadoop Common,这是一组常见的实用工具,可以通过模块来运行。这些模块还包括:Hadoop分布式文件系统(HDFS)、用于任务调度和集群资源管理的 Hadoop YARN以及Hadoop MapReduce,后者是一种基于YARN的系统,能够并行处理庞大的数据集。
Apache还提供了另外的开源软件,可以在Hadoop上运行,比如分析引擎Spark(它也能独立运行)和编程语言Pig。
Hadoop 之所以广受欢迎,就是因为它为使用大众化硬件处理大数据提供了一种几乎没有限制的环境。添加节点是个简单的过程,对这个框架没有任何负面影响。 Hadoop具有高扩展性,能够从单单一台服务器灵活扩展到成千上万台服务器,每个集群运行自己的计算和存储资源。Hadoop在应用程序层面提供了高可用性,所以集群硬件可以是现成的。
实际的使用场合包括:在线旅游(Hadoop声称它是80%的网上旅游预订业务的可靠的大数据平台)、批量分析、社交媒体应用程序提供和分析、供应链优化、移动数据管理、医疗保健及更多场合。
它有什么缺点吗? Hadoop很复杂,需要大量的员工时间和扎实的专业知识,这就阻碍了它在缺少专业IT人员的公司企业的采用速度。由于需要专家级管理员,加上广泛分布的集群方面需要庞大的成本支出,从中获得商业价值也可能是个挑战。I
集群管理也可能颇为棘手。虽然Hadoop统一了分布式计算,但是配备和管理另外的数据中心、更不用说与远程员工打交道,增添了复杂性和成本。结果就是,Hadoop集群可能显得过于孤立。
将Hadoop作为基于云的托管服务的优劣势分析
Apache Hadoop是一种开源软件框架,能够对分布式集群上的大数据集进行高吞吐量处理。Apache模块包括Hadoop Common,这是一组常见的实用工具,可以通过模块来运行。这些模块还包括:Hadoop分布式文件系统(HDFS)、用于任务调度和集群资源管理的 Hadoop YARN以及Hadoop MapReduce,后者是一种基于YARN的系统,能够并行处理庞大的数据集。
Apache还提供了另外的开源软件,可以在Hadoop上运行,比如分析引擎Spark(它也能独立运行)和编程语言Pig。
Hadoop 之所以广受欢迎,就是因为它为使用大众化硬件处理大数据提供了一种几乎没有限制的环境。添加节点是个简单的过程,对这个框架没有任何负面影响。 Hadoop具有高扩展性,能够从单单一台服务器灵活扩展到成千上万台服务器,每个集群运行自己的计算和存储资源。Hadoop在应用程序层面提供了高可用性,所以集群硬件可以是现成的。
实际的使用场合包括:在线旅游(Hadoop声称它是80%的网上旅游预订业务的可靠的大数据平台)、批量分析、社交媒体应用程序提供和分析、供应链优化、移动数据管理、医疗保健及更多场合。
它有什么缺点吗? Hadoop很复杂,需要大量的员工时间和扎实的专业知识,这就阻碍了它在缺少专业IT人员的公司企业的采用速度。由于需要专家级管理员,加上广泛分布的集群方面需要庞大的成本支出,从中获得商业价值也可能是个挑战。I
集群管理也可能颇为棘手。虽然Hadoop统一了分布式计算,但是配备和管理另外的数据中心、更不用说与远程员工打交道,增添了复杂性和成本。结果就是,Hadoop集群可能显得过于孤立。
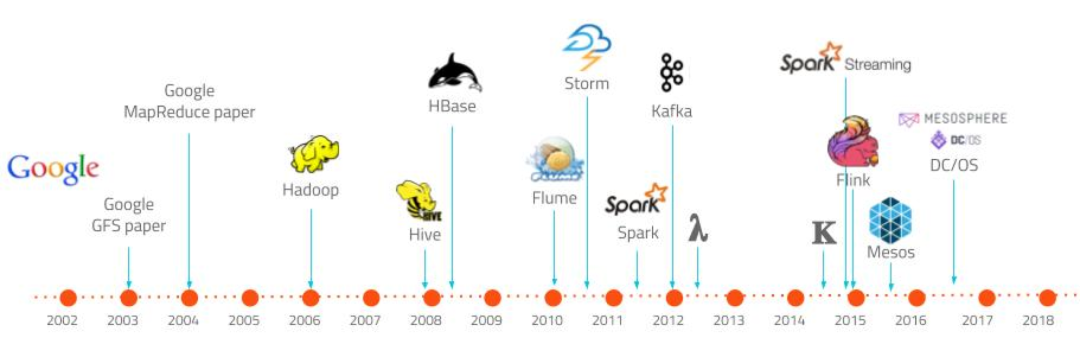
每周学点大数据 | No.70 适于迭代并行计算的平台——Spark初探
编者按:灯塔大数据将每周持续推出《从零开始学大数据算法》的连载,本书为哈尔滨工业大学著名教授王宏志老师的扛鼎力作,以对话的形式深入浅出的从何为大数据说到大数据算法再到大数据技术的应用,带我们在大数据技术的海洋里徜徉~每周五定期更新
上期回顾&查看方式
在上一期,我们学习了多机配置的相关内容。PS:了解了上期详细内容,请在自定义菜单栏中点击“灯塔数据”—“技术连载”进行查看;或者滑到文末【往期推荐】查看。
No.70
适于迭代并行计算的平台——Spark初探
Mr. 王 :在初步了解了并行平台 Hadoop

java8实战读书笔记:初识Stream、流的基本操作(流计算)
本文中的部分示例基于如下场景:餐厅点菜,Dish为餐厅中可提供的菜品,Dish的定义如下:

java8实战读书笔记:初识Stream、流的基本操作(流计算)
我们以一个简单的示例来引入流:从菜单列表中,查找出是素食的菜品,并打印其菜品的名称。
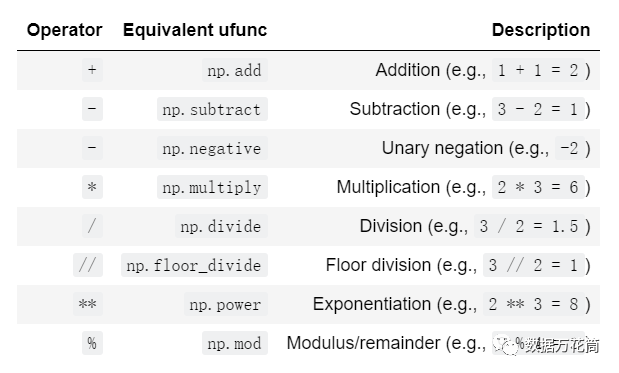
Python入门教程(三):史上最全的Numpy计算函数总结,建议收藏!
Numpy提供了灵活的、静态类型的、可编译的程序接口口来优化数组的计算,也被称作向量操作,因此在Python数据科学界Numpy显得尤为重要。Numpy的向量操作是通过通用函数实现的。今天小编会给大家较为全面地介绍下Numpy的通用函数。
腾讯云大数据技术介绍-数据查询弹性 MapReduce
上一节我们讲到了大数据的存储 : https://cloud.tencent.com/developer/article/1878422
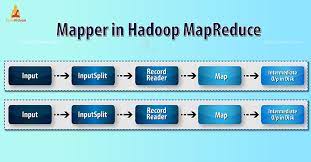
基于腾讯云对象存储跑hadoop任务实战一
公司在腾讯云有一个大数据集群,用hdp的ambari部署管理的,hdp面有hadoop、hive、spark等常用的大数据组件,公司的报表都从这里生成。
基于腾讯云对象存储跑hadoop任务实战一
公司在腾讯云有一个大数据集群,用hdp的ambari部署管理的,hdp面有hadoop、hive、spark等常用的大数据组件,公司的报表都从这里生成。
基于腾讯云对象存储跑hadoop任务实战二
在前一篇文章中《基于腾讯云对象存储跑hadoop任务实战一》介绍了如何部署和配置hadoop集群直接分析存储在腾讯云对象存储上的数据。这篇文章介绍一些性能优化的参数调优。
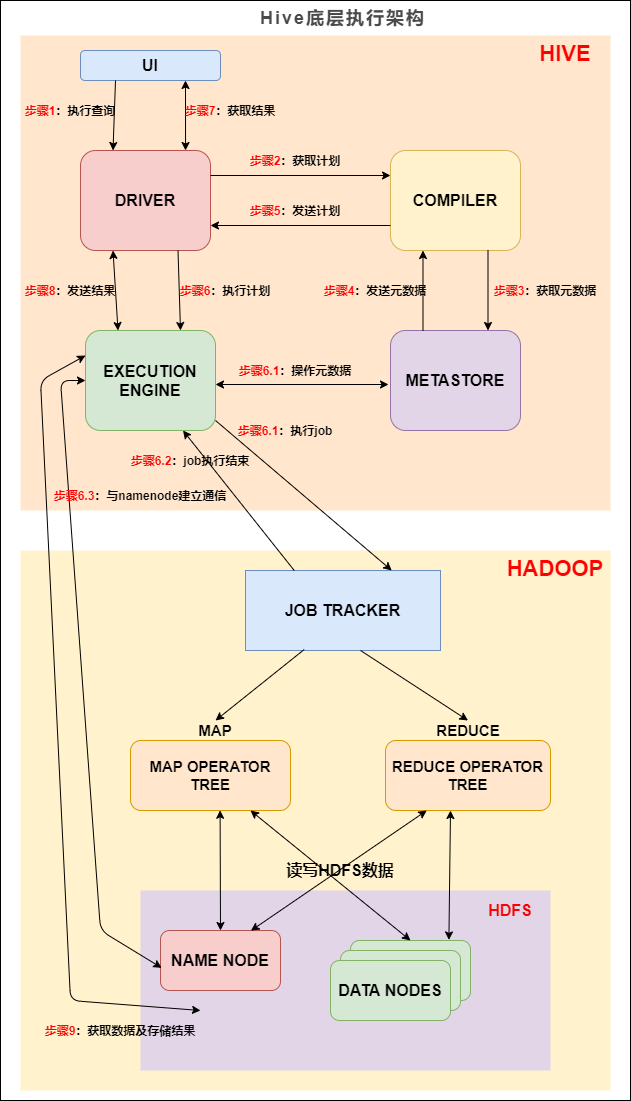
第一章 分布式计算框架与资源调度
在MapReduce程序的开发过程中,往往需要用到FileInputFormat与TextInputFormat,我们会发现TextInputFormat这个类继承自FileInputFormat,FileInputFormat这个类继承自InputFormat,InputFormat这个类会将文件file按照逻辑进行划分,划分成的每一个split切片将会被分配给一个Mapper任务,文件先被切分成split块,而后每一个split切片对应一个Mapper任务
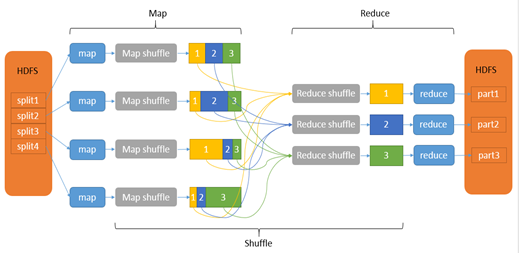
基于Alluxio优化大数据计算存储分离架构的最佳实践
近年来,随着大数据规模的增长,以及大数据应用的发展,大数据技术的架构也在持续演进。早期的技术架构是计算资源和存储资源高度融合,计算和存储资源一体化存在以下明显的挑战:
Spark Streaming——Spark第一代实时计算引擎
虽然SparkStreaming已经停止更新,Spark的重点也放到了 Structured Streaming ,但由于Spark版本过低或者其他技术选型问题,可能还是会选择SparkStreaming。 SparkStreaming对于时间窗口,事件时间虽然支撑较少,但还是可以满足部分的实时计算场景的,SparkStreaming资料较多,这里也做一个简单介绍。
进击大数据系列(六):Hadoop 分布式计算框架 MapReduce
MapReduce 是一种编程模型(没有集群的概念,会把任务提交到 yarn 集群上跑),用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。

EMR(弹性MapReduce)入门之计算引擎Spark、Tez、MapReduce区别(八)
Spark Core:包含Spark的基本功能;尤其是定义RDD的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和Spark Core之上的。
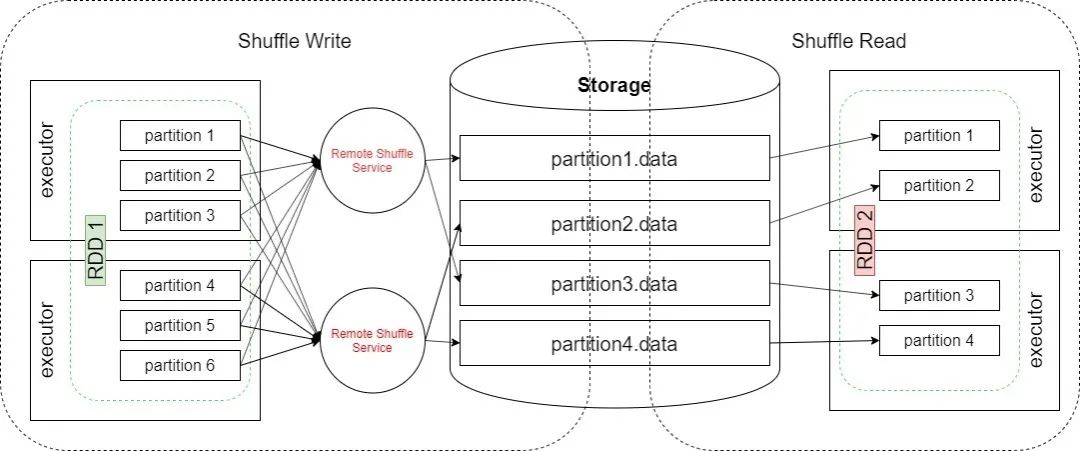
揭秘| 大数据计算引擎性能及稳定性提升神器!
本文讨论了京东Spark计算引擎研发团队关于自主研发并落地Remote Shuffle Service,助力京东大促场景的探索和实践。近年来,大数据技术在各行业的应用越来越广泛,Spark自UCBerkeley的AMP实验室诞生到如今3.0版本的发布,已有十年之久,俨然已经成为大数据计算领域名副其实的老将。虽然经过不断的迭代和优化,Spark功能日趋成熟与完善,但在性能及稳定性方面,仍然还有很多可以提升的地方。Shuffle过程作为MapReduce编程模型的性能瓶颈,就是其中的重点。我们希望在京东超大规模数据体量及复杂业务场景的背景下,通过自研并落地Remote Shuffle Service服务,解决External Shuffle Service中存在的现有问题,打造稳定高效的JDSpark计算引擎,助力京东大促过程中的一些应用实践,能够给大家提供一些思路和启发,同时也欢迎大家多多交流,给我们提出宝贵建议。