上一节我们讲到了大数据的存储 : https://cloud.tencent.com/developer/article/1878422
我们可以使用云HDFS来存储我们的大数据。
接下来就是我们如何使用这么大的数据量的数据了。
这就是我们今天讲的第二步:
Step 2:如何去读取这些数据并做一些类似SQL的操作?
在一般量级的数据上,我们可以做一些简单的sql,以一种类似顺序查找的方式去控制这些数据,在数据量没那么大的情况耗时是可以接受。但是处理海量数据就不能简单这么操作,会非常慢。于是出现有了map reduce的概念。
MapReduce简单来说就是对所有数据操作都抽象为map和reduce两种方式的操作。
举个例子,现在如果要计算1+3+5+9+4+8+6+9+2这个式子,
map reduce的做法是(图片来自网络):
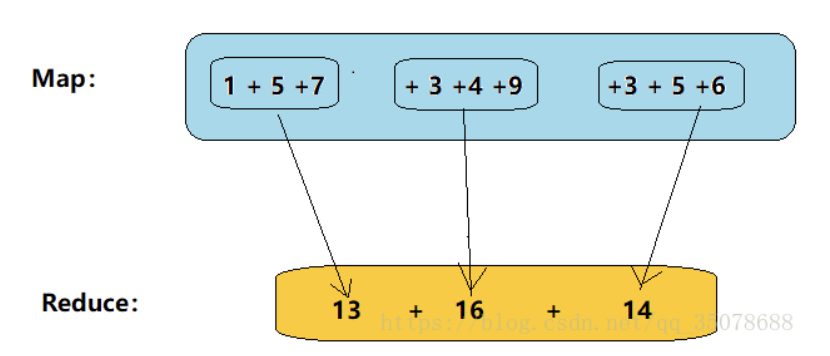
简单的来说就是一种分治的思想,通过这样的方式可以发挥机器大规模并行计算的能力,在数据量庞大的情况下提高计算效率。理论上所有的计算都可以通过map和reduce这两个方法的组合叠加来获得最后的结果。
最先实现之一点的就是Hadoop。
但是随时实践的进一步深入,大数据开发工程师发现仅仅通过map和reduce两种操作进行计算在某些场景下实在是太复杂了,于是就有了Apache Spark这个操作库更丰富的大规模计算引擎。他除了在map reduce基础上延伸出了flapmap等几十种新的复杂的操作,同时优化了计算性能以及其他方面的能力,更大程度提升了大数据计算的能力。
腾讯云这里也有相关的成熟组件:
弹性 MapReduce
弹性 MapReduce(EMR)结合云技术和 Hadoop、Hive、Spark、Hbase、Presto、Flink 、Druid、ClickHouse 等社区开源技术,提供安全、低成本、高可靠、可弹性伸缩的云端半托管泛Hadoop大数据架构。您可以在数分钟内创建安全可靠的专属泛 Hadoop 集群,以分析位于集群内数据节点或对象存储 COS 上的 PB 级海量数据。

组件链接 https://cloud.tencent.com/product/emr

欢迎大家申请使用。
这里讲了 如何通过MapReduce 快速的来查询数据。
今天先写到这里,
尽管使用MapReduce 快速的来查询数据,但是还是有他不方便的地方,你需要写一堆的MapReduce代码,
下一次我们会讲,利用新的工具来实现数据快速的查询。
see you !