云原生Spark UI Service在腾讯云云原生数据湖产品DLC的实践
作者:余建涛,大数据平台产品中心高级工程师
摘要
Spark UI是查看Spark作业运行情况的重要窗口,用户经常需要根据UI上的信息来判断作业失败的原因或者分析作业如何优化。DLC团队实现了云原生的Spark UI Sevice,相较于开源的Spark History Server,存储成本降低80%,大规模作业UI加载速度提升70%。目前已在公有云多个地域上线,为DLC用户提供Spark UI服务。
背景
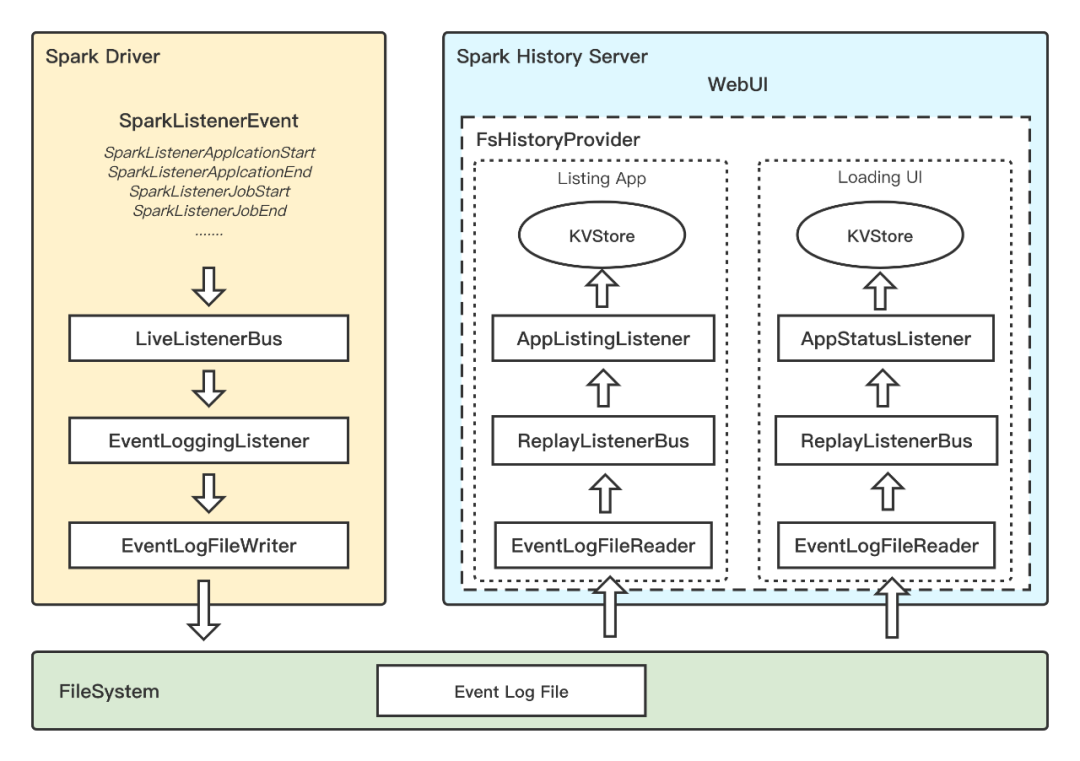
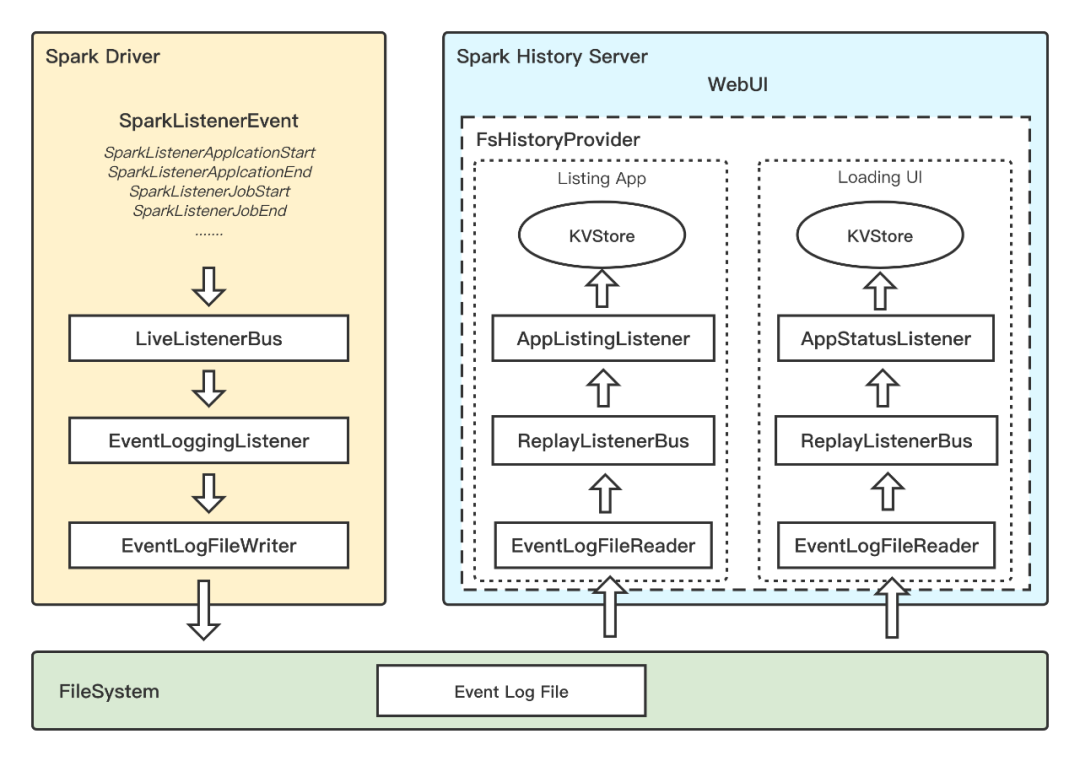
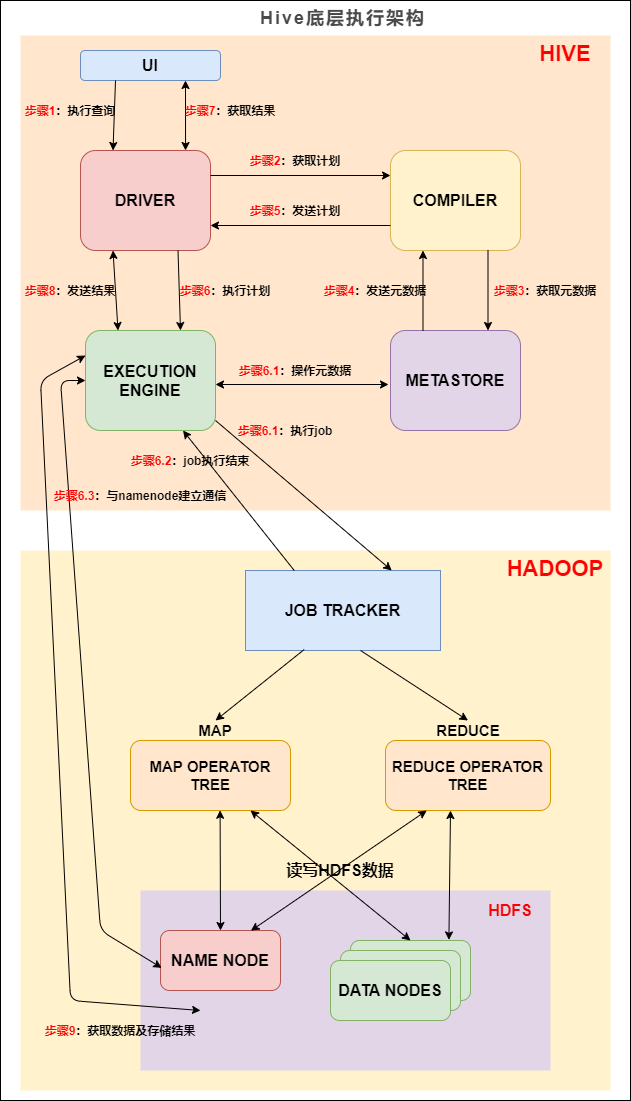
Spark History Server原理
Spark History Server(以下简称S
云原生Spark UI Service在腾讯云云原生数据湖产品DLC的实践
作者:余建涛,大数据平台产品中心高级工程师
摘要
Spark UI是查看Spark作业运行情况的重要窗口,用户经常需要根据UI上的信息来判断作业失败的原因或者分析作业如何优化。DLC团队实现了云原生的Spark UI Sevice,相较于开源的Spark History Server,存储成本降低80%,大规模作业UI加载速度提升70%。目前已在公有云多个地域上线,为DLC用户提供Spark UI服务。
背景
Spark History Server原理
Spark History Server(以下简称S
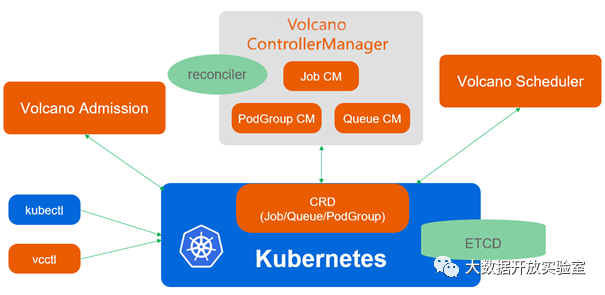
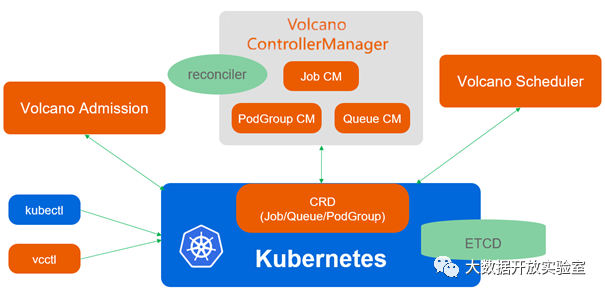
云原生架构下复杂工作负载混合调度的思考与实践
10月25日,第一届中国云计算基础架构开发者大会在长沙召开,星环科技与众多国内外厂商共同就“云原生”、“安全与容错”和“管理与优化”等云计算领域话题进行了深入交流和探讨。星环科技容器云研发工程师关于"基于Kubernetes的复杂工作负载混合调度器思考与实践"相关内容进行了分享,本文是对会议上内容的整理。
关于Spark运行流式计算程序中跑一段时间出现GC overhead limit exceeded
该文章讲述了在升级框架时遇到的一个流式计算程序出现GC overhead limit exceeded的问题。通过进行各种内存优化和控制变量定义在循环体外等方法进行调试,最终发现是内存不足导致的问题。通过手动添加unpersist进行内存释放,再上线,发现问题果然消失了。这个问题的根源是内存不足,而自动机制在流式计算中有点赶不上,导致出现错误。
云原生架构下复杂工作负载混合调度的思考与实践
10月25日,第一届中国云计算基础架构开发者大会在长沙召开,星环科技与众多国内外厂商共同就“云原生”、“安全与容错”和“管理与优化”等云计算领域话题进行了深入交流和探讨。星环科技容器云研发工程师关于"基于Kubernetes的复杂工作负载混合调度器思考与实践"相关内容进行了分享,本文是对会议上内容的整理。
存算分离下写性能提升10倍以上,EMR Spark引擎是如何做到的?
引言 随着大数据技术架构的演进,存储与计算分离的架构能更好的满足用户对降低数据存储成本,按需调度计算资源的诉求,正在成为越来越多人的选择。相较 HDFS,数据存储在对象存储上可以节约存储成本,但与此同时,对象存储对海量文件的写性能也会差很多。 腾讯云弹性 MapReduce(EMR) 是腾讯云的一个云端托管的弹性开源泛 Hadoop 服务,支持 Spark、Hbase、Presto、Flink、Druid 等大数据框架。 近期,在支持一位 EMR 客户时,遇到典型的存储计算分离应用场景。客户使用了 EMR
一份数据满足所有数据场景?腾讯云数据湖解决方案及DLC内核技术介绍
摘要 OLAP数据库/引擎日新月异,不断推陈出新,在各种场景下有不同引擎的价值:flink擅长于实时数据集成/实时计算;spark批处理、tb级以上、hive生态、复杂join的数据分析、以及机器学习;presto联邦分析、较简单join、tb级以下hive生态udf数据分析;clickhouse 大宽表聚合操作、无数据更新、尽量无join、没有复杂udf的亚秒级分析,tensorflow深度学习等等 即使相同的引擎,考虑资源隔离、成本分摊、数仓研发/使用周期(test,adhoc,prod,backfil

QCon大会实录:PB级数据秒级分析-腾讯云原生湖仓DLC架构揭秘
导语
文章整理了全球软件开发大会QCon《PB级数据秒级分析-腾讯云原生湖仓DLC架构揭秘》。大数据基于海量数据的分析,硬件、存储、计算资源尽量都可以用廉价的资源完成,如何在廉价资源上进行性能优化尤为重要。大数据是一种IO密集型负载,性能优化也首先着眼于IO优化。
开篇:云提供了便利的按需使用方式,最佳实践非常重要
主持人:过去几年,数据湖能力已经在腾讯内部包括微信视频号、小程序等多个业务大规模落地,数据规模达到 PB 至 EB 级别,在此基础上,腾讯自研业务也启动了云原生湖仓能力建设

2021年大数据Spark(四):三种常见的运行模式
Spark 框架编写的应用程序可以运行在本地模式(Local Mode)、集群模式(Cluster Mode)和云服务(Cloud),方便开发测试和生产部署。
Flink被阿里巴巴买后,果然还是废了
Flink Forward Asia 2022最近在开,有关Flink的讨论,又开始在国内热闹起来。从技术上来说,Flink当然已经是streaming processing的一个标杆了。
Hive计算引擎大PK,万字长文解析MapRuce、Tez、Spark三大引擎
Hive从2008年始于FaceBook工程师之手,经过10几年的发展至今保持强大的生命力。截止目前Hive已经更新至3.1.x版本,Hive从最开始的为人诟病的速度慢迅速发展,开始支持更多的计算引擎,计算速度大大提升。
Hive计算引擎大PK,万字长文解析MapRuce、Tez、Spark三大引擎
Hive从2008年始于FaceBook工程师之手,经过10几年的发展至今保持强大的生命力。截止目前Hive已经更新至3.1.x版本,Hive从最开始的为人诟病的速度慢迅速发展,开始支持更多的计算引擎,计算速度大大提升。
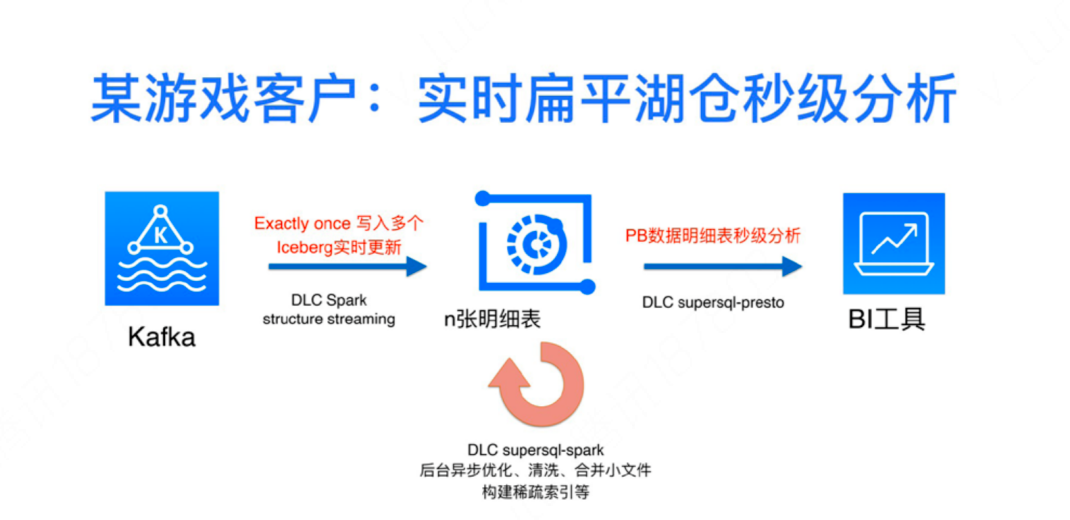
PB 级数据秒级分析:腾讯云原生湖仓DLC 架构揭秘
导读|过去几年,数据湖能力已经在腾讯内部包括微信视频号、小程序等多个业务大规模落地,数据规模达到 PB至 EB 级别。在此基础上,腾讯自研业务也启动了云原生湖仓能力建设。云原生湖仓架构最大的挑战什么?腾讯云原生湖仓 DLC 从哪些方面着手解决问题?接下来由腾讯云大数据专家工程师于华丽带来相关分享。
云原生湖仓的诞生背景、价值、挑战
当前这个阶段,相信大家对于数据湖,数据仓,湖仓一系列的名词已经不算陌生了,我用最直白、最狭义方式去解释“湖仓”的话,就是数据湖跟数仓存储架构统一。
数据湖最初的需求是,要存储和

PB 级数据秒级分析:腾讯云原生湖仓DLC 架构揭秘
导读|过去几年,数据湖能力已经在腾讯内部包括微信视频号、小程序等多个业务大规模落地,数据规模达到 PB至 EB 级别。在此基础上,腾讯自研业务也启动了云原生湖仓能力建设。云原生湖仓架构最大的挑战什么?腾讯云原生湖仓 DLC 从哪些方面着手解决问题?接下来由腾讯云大数据专家工程师于华丽带来相关分享。
云原生湖仓的诞生背景、价值、挑战
当前这个阶段,相信大家对于数据湖,数据仓,湖仓一系列的名词已经不算陌生了,我用最直白、最狭义方式去解释“湖仓”的话,就是数据湖跟数仓存储架构统一。
数据湖最初的需求是,要存储和
geotrellis使用(十七)使用缓冲区分析的方式解决单瓦片计算边缘值问题
Geotrellis系列文章链接地址http://www.cnblogs.com/shoufengwei/p/5619419.html
目录
前言
需求分析
实现方案
总结
一、前言
最近真的是日理千机,但是再忙也要抽出时间进行总结。上一篇文章讲了使用缓冲区分析的方式解决投影变换中边缘数据值计算的问题(见geotrellis使用(十六)使用缓冲区分析的方式解决投影变换中边缘数据值计算的问题)。实际中往往还有一种需求就是对单个瓦片进行操作,比如求坡度等,如果这时候直接计算,同样会出现边缘值计算
Flink or Spark?实时计算框架在K12场景的应用实践
如今,越来越多的业务场景要求 OLTP 系统能及时得到业务数据计算、分析后的结果,这就需要实时的流式计算如Flink等来保障。例如,在 TB 级别数据量的数据库中,通过 SQL 语句或相关 API直接对原始数据进行大规模关联、聚合操作,是无法做到在极短的时间内通过接口反馈到前端进行展示的。若想实现大规模数据的“即席查询”,就须用实时计算框架构建实时数仓来实现。
Flink or Spark?实时计算框架在K12场景的应用实践
如今,越来越多的业务场景要求 OLTP 系统能及时得到业务数据计算、分析后的结果,这就需要实时的流式计算如Flink等来保障。例如,在 TB 级别数据量的数据库中,通过 SQL 语句或相关 API直接对原始数据进行大规模关联、聚合操作,是无法做到在极短的时间内通过接口反馈到前端进行展示的。若想实现大规模数据的“即席查询”,就须用实时计算框架构建实时数仓来实现。
大巧不工,袋鼠云正式开源大数据任务调度平台——Taier(太阿)
2022年2月22日,在今天这个特殊的日子里,历经多年持续迭代和千万周期实例并发调度考验的Taier(太阿)终于开源了!

腾讯云EMR&Elasticsearch中使用ES-Hadoop之Spark篇
腾讯云EMR&Elasticsearch中使用ES-Hadoop之MR&Hive篇

每周学点大数据 | No.70 适于迭代并行计算的平台——Spark初探
编者按:灯塔大数据将每周持续推出《从零开始学大数据算法》的连载,本书为哈尔滨工业大学著名教授王宏志老师的扛鼎力作,以对话的形式深入浅出的从何为大数据说到大数据算法再到大数据技术的应用,带我们在大数据技术的海洋里徜徉~每周五定期更新
上期回顾&查看方式
在上一期,我们学习了多机配置的相关内容。PS:了解了上期详细内容,请在自定义菜单栏中点击“灯塔数据”—“技术连载”进行查看;或者滑到文末【往期推荐】查看。
No.70
适于迭代并行计算的平台——Spark初探
Mr. 王 :在初步了解了并行平台 Hadoop
