编者按:灯塔大数据将每周持续推出《从零开始学大数据算法》的连载,本书为哈尔滨工业大学著名教授王宏志老师的扛鼎力作,以对话的形式深入浅出的从何为大数据说到大数据算法再到大数据技术的应用,带我们在大数据技术的海洋里徜徉~每周五定期更新
上期回顾&查看方式
在上一期,我们学习了多机配置的相关内容。PS:了解了上期详细内容,请在自定义菜单栏中点击“灯塔数据”—“技术连载”进行查看;或者滑到文末【往期推荐】查看。
No.70
适于迭代并行计算的平台——Spark初探
Mr. 王 :在初步了解了并行平台 Hadoop 的使用之后,我们再来尝试使用一个超越MapReduce 的并行平台——Spark。
小可 :前面我好像听到过这个名字。
Mr. 王 :我们在讨论超越 MapReduce 并行计算时曾经提到过,在以 Hadoop 为代表的MapReduce 被提出时,在企业级别的应用上 MapReduce 的表现还是可圈可点的,但随着对大数据处理时间要求的不断苛刻和计算复杂程度的提升,人们逐渐地发现了 MapReduce 的各种缺陷,也在寻求着各种改进 MapReduce 的方法,或者提出一些新的模型。在 MapReduce 逐渐被研究人员放弃的时代,大量新平台的出现也让我们眼前一亮,像 Spark 和 Trinity 这样的新一代大数据并行计算平台就是这个时代的产物,它们各有特点,在各自着重注意的一些方面上,它们的表现要比 MapReduce 更加出色。
Apache Spark 官方网站
微软研究院 Trinity 官方网站
在这里我们就以非常友好、简单、易用的 Spark 平台为例,来了解一下如何使用新兴的并行大数据平台。Spark是一个开源的分布式计算平台系统,它存在的目的就是为了提升计算效率。
在 Spark 官方网站上,就展示了 Spark 的很多优点。
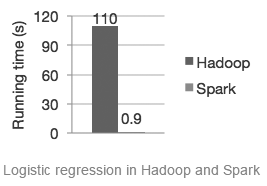
Spark 由于它的“DAG 处理引擎”和“in-memory”计算技术,号称在内存中运行可以比Hadoop 快 100 倍,即使在磁盘中,也可以达到 10 倍的处理速度。官网上的宣传图片中也表示,Hadoop 需要 110 秒的逻辑回归处理,Spark 只需要 0.9 秒的时间,可以看出在效率上其改进力度还是非常大的。这也体现了其“超越 MapReduce”并行计算之处。
Spark 的另一个特点就是它的易用性是非常好的。我们可以看出,在 Spark 上实现一个WordCount 的代码量也相对较大。Spark 由于其良好的封装和对易用性设计的重视,使用 Spark实现一些基本的操作非常容易。可以使用Scala、Python或者Java语言进行实现,非常方便、简洁。就拿Word Count来说,可能只需要3~5行代码就可以实现。用户和初学者使用起来非常的友好。
前面我们提到过,Hadoop 并行计算比较慢的一个重要原因就是它不擅长于迭代计算的处理。在每一轮的 MapReduce 开始时,输入数据都被存放在 HDFS 上,Mapper 要从 HDFS 上读取数据,处理后送给 Reduce,结果仍然会被保存在 HDFS 上。不过,如果这个过程要进行多个轮次,比如做图算法、数据挖掘算法等,那么迭代几十次甚至上百次都是非常正常的。在这种情况下,数据就会被频繁地从 HDFS 上取出,这个过程相当于磁盘读写中的读磁盘 ;也会被频繁地存储到 HDFS 上,这个过程相当于写磁盘。即使 MapReduce 的过程进行得再快,或者MapReduce 执行的操作再简单,也会被不断的磁盘 IO 拖慢平均运行速度,导致处理过程的平均效率大大下降。
Spark 则不然,Spark 的每一轮迭代之间的存取位置不再是 HDFS,而是内存。Spark 非常有效地利用多台计算机组成的机群中的所有内存空间进行有效的规划,从而使用内存来存储所有的中间结果。我们知道,内存的存取速度相比磁盘(HDFS)来讲是非常快的,如果能够有效地利用内存空间而不是磁盘作为中间结果的存储,那么整个迭代过程由于削减了巨大的磁盘开销,效率提升将会是非常明显的。
Spark 提出了一个非常核心的概念就是RDD(Resilient Distributed Datasets)。翻译过来就是弹性分布式数据集合。有了它,Spark 就可以实现 in-memory 的机群级别的并行数据处理。RDD 实现了对数据的分片,对于一个比较大的数据集合,Spark 会将它们分成具有固定大小的分片(就像磁盘中的盘块),这样更加有利于对数据的处理。而且对于每个分片,Spark 都会给出一个函数去处理它,这就相当于一个个小的数据节点,并且每个数据节点都会按照自己应该执行的动作去执行。而且这些数据分片可以根据一些关系进行变换成为新的 RDD。这些新兴的思想都使得 Spark 成为了一个非常成功的以内存存储中间结果的并行平台。
小可兴奋地说 :听起来还真是很吸引人啊,我要赶快下载试试。
Mr. 王 :Spark 的官方网站是http://spark.apache.org/,在这上面可以找到 Spark 的下载文件和相关文档。
在主页的右侧就有一个非常明显的 Spark 下载按钮。
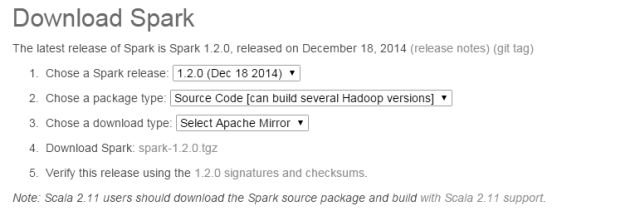
打开之后就有下载 Spark 的各种选项,我们可以选择 Spark 的各种发行版本。
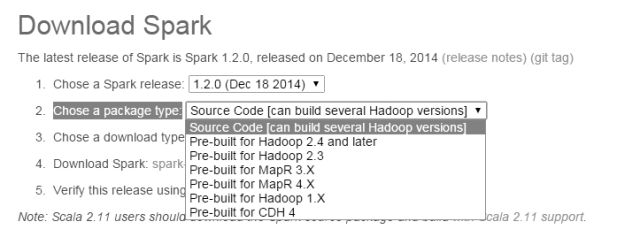
这里需要注意的一点是,在 Chose a package type: 选项后面,可以看到有很多的下载包选项。为了方便起见,这里选择使用它的预编译版本,也就是前面带有 Pre-built 的版本。如果你感兴趣的话,可以下载源代码版本,Spark 的源代码非常小,只有几十 MB,不过想要编译它们需要用到 Apache 的 Maven 工具,这里我就不赘述了。预编译好的版本相对要大一些,但下载之后就可以直接使用了,非常的方便。
下载时,我们可以根据自己计算机上安装的 Hadoop 版本来下载安装相应的预编译版本,在我们讨论的范围内,版本的影响不大。选好了之后,网站会向我们推荐下载源,也就是距离我们最近的镜像,跟着提示就可以完成下载。
小可 :下载好了,直接解压缩就可以了吧?
Mr. 王 :是的,在执行之前别忘了 Spark 的运行依然是需要 Java 运行环境的。
小可 :嗯,在学习 Hadoop 时,我的计算机里已经配置好了 Java 运行环境。
Mr. 王 :嗯,那么下一步我们就可以打开终端,尝试运行 Spark 的终端了。
首先进入解压缩好的 Spark 文件夹。

然后在 Spark 目录下使用 ls 命令来看看里面的内容。

Spark 的执行文件在 bin 中,我们可以使用下面的命令来执行它。


小可 :屏幕上出现了大量的提示信息,是在提示 Spark 启动过程中的执行情况吧。中间还有一个 Spark 的 logo !
Mr. 王 :最后会出现 scala>,这是提示用户输入 Spark 常用的 scala 命令或者程序。如果出现了这个提示符,就说明基本配置已经成功了。
现在很多高校的计算机学科已经以 Python 语言作为高级语言教学了,如果你比较擅长Python 的话,也可以用 Spark 提供以 Python 为基础语言的终端。使用命令 :
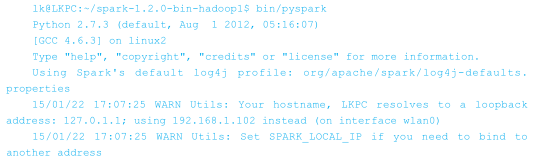

如果最后出现了“>>>”符号,则说明 Python 终端已经顺利启动了。
下期精彩预告
经过学习,我们研究了一个超越MapReduce 的并行平台——Spark涉及到的一些具体问题。在下一期中,我们将进一步了解单词出现行计数的相关内容。更多精彩内容,敬请关注灯塔大数据,每周五不见不散呦!
文章作者:王宏志
文章编辑:天天