推荐收藏:跨云数据仓库(data warehouse)环境搭建,这货特别干!
数据测试环境只有一套,平时只用于日常的数据需求测试,无法满足用户 UAT 要求,因此需要重新搭建一套数据测试系统,作为用户的 UAT 环境。
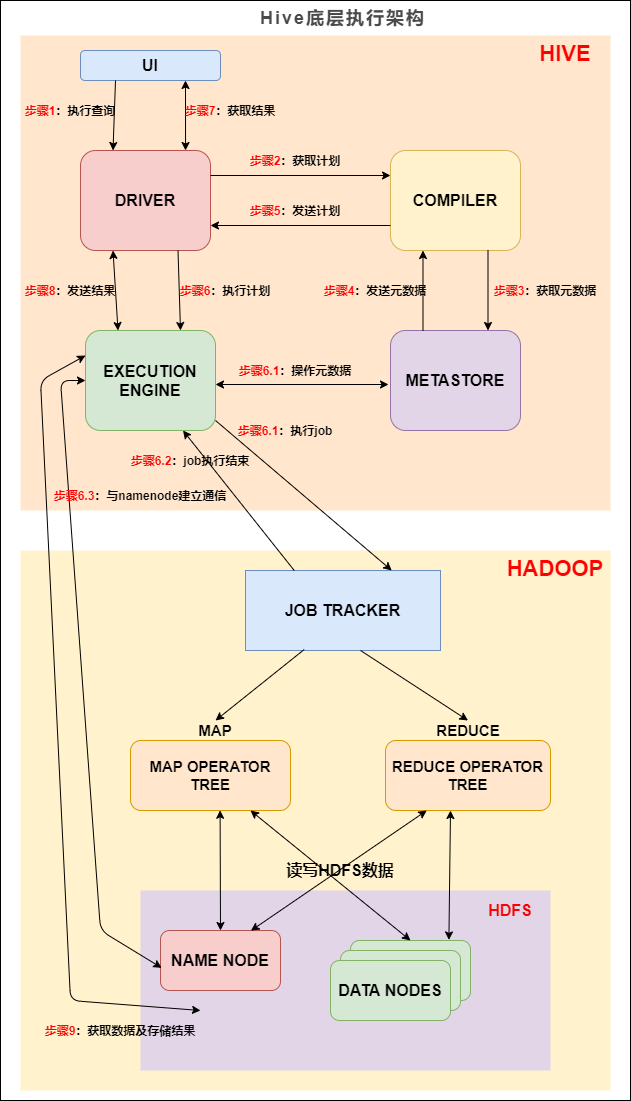
Hive计算引擎大PK,万字长文解析MapRuce、Tez、Spark三大引擎
Hive从2008年始于FaceBook工程师之手,经过10几年的发展至今保持强大的生命力。截止目前Hive已经更新至3.1.x版本,Hive从最开始的为人诟病的速度慢迅速发展,开始支持更多的计算引擎,计算速度大大提升。
Hive计算引擎大PK,万字长文解析MapRuce、Tez、Spark三大引擎
Hive从2008年始于FaceBook工程师之手,经过10几年的发展至今保持强大的生命力。截止目前Hive已经更新至3.1.x版本,Hive从最开始的为人诟病的速度慢迅速发展,开始支持更多的计算引擎,计算速度大大提升。
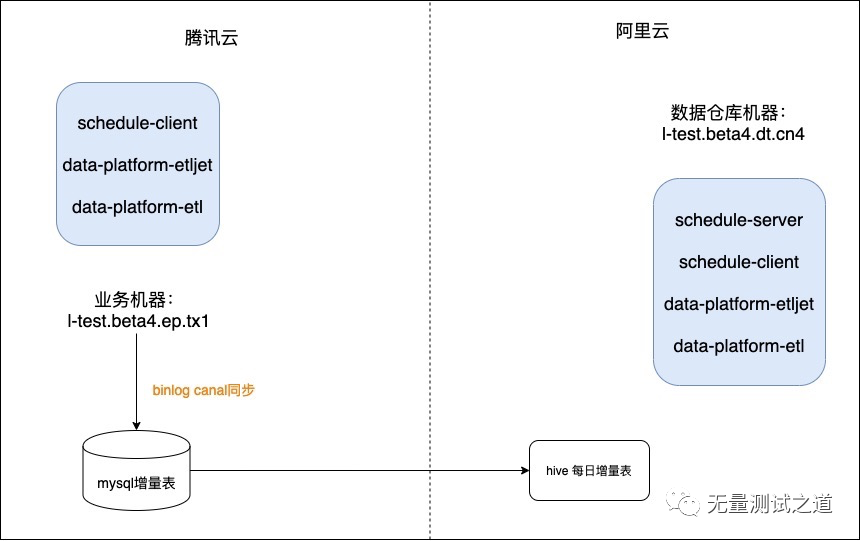
一面数据: Hadoop 迁移云上架构设计与实践
李阳良,一面数据大数据部门负责人,九年互联网工作经验,对后台开发、大数据技术接触比较多。
腾讯云EMR&Elasticsearch中使用ES-Hadoop之Spark篇
腾讯云EMR&Elasticsearch中使用ES-Hadoop之MR&Hive篇

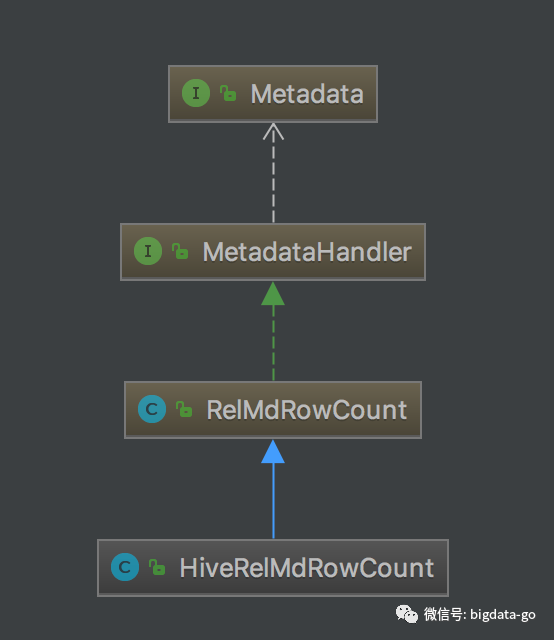
Hive优化器原理与源码解析系列--统计信息中间结果大小计算
之前文章有写过关于基于Operator操作符Selectivity选择率和Predicate谓词的Selectivity选择率的讲解。这篇文章来讲一下基于每个Operator(TableScan、Project、Join、Union、Sort、Aggregate等等)返回记录数RowCount,即中间结果大小。Hive在估算每个Operator的返回结果RowCount,即中间结果大小,有的是使用元数据对象来进行估算的RowCount;有的使用RelNode自身实现方法估算的;有的是总行数乘以其选择率估算的等多种方法实现。
使用 Iceberg on Kubernetes 打造新一代云原生数据湖
作者徐蓓,腾讯云容器专家工程师,10年研发经验,7年云计算领域经验。负责腾讯云 TKE 大数据云原生、离在线混部、Serverless 架构与研发。 背景 大数据发展至今,按照 Google 2003年发布的《The Google File System》第一篇论文算起,已走过17个年头。可惜的是 Google 当时并没有开源其技术,“仅仅”是发表了三篇技术论文。所以回头看,只能算是揭开了大数据时代的帷幕。随着 Hadoop 的诞生,大数据进入了高速发展的时代,大数据的红利及商业价值也不断被释放。现今大数
天穹SuperSQL如何把腾讯 PB 级大数据计算做到秒级?
天穹SuperSQL是腾讯自研,基于统一的SQL语言模型,面向机器学习智能调优,提供虚拟化数据和开放式计算引擎的大数据智能融合平台。在开放融合的Data Cloud上,业务方可以消费完整的数据生命周期,从采集-存储-计算-分析-洞察。还能够满足位于不同数据中心、不同类型数据源的数据联合分析/即时查询的需求。 Presto在腾讯天穹SuperSQL大数据生态中,定位为实现秒级大数据计算的核心服务。主要面向即席查询、交互式分析等用户场景。Presto服务了腾讯内部的不同业务场景,包括微信支付、QQ、游戏等关键业
打造大数据平台底层计算存储引擎 | Apache孵化器迎来Linkis!
微众银行开源项目Linkis正式通过Apache软件基金会(ASF)的投票表决,全票通过进入ASF孵化器!
CDP私有云基础版7.1.6的新功能是什么?
根据IDG的说法,当客户考虑更新到产品的最新版本时,他们期望新功能、增强的安全性和更好的性能,但越来越希望拥有更简化的升级过程。伴随着CDP私有云的每个新版本,我们正在努力提供这些内容。伴随着许多新功能,我们正在尽可能简化升级过程。在此博客中,我们将介绍7.1.6版本中的新功能以及从HDP进行的新的就地升级,从而完全消除了替换基础架构和数据迁移的麻烦。
CDP私有云基础版7.1.6的新功能是什么?
根据IDG的说法,当客户考虑更新到产品的最新版本时,他们期望新功能、增强的安全性和更好的性能,但越来越希望拥有更简化的升级过程。伴随着CDP私有云的每个新版本,我们正在努力提供这些内容。伴随着许多新功能,我们正在尽可能简化升级过程。在此博客中,我们将介绍7.1.6版本中的新功能以及从HDP进行的新的就地升级,从而完全消除了替换基础架构和数据迁移的麻烦。
0870-CDP公有云发布Iceberg技术预览版
在过去的十年中,我们的客户成功部署的大规模数据集群已成为推动需求的大数据飞轮,它可以引入更多的数据,应用更复杂的分析,并成就了从业务分析师到数据科学家的许多新数据从业者。这种前所未有的大数据工作负载并非没有挑战。数据架构层就是这样一个领域,不断增长的数据集已经突破了可扩展性和性能的极限。数据爆炸必须用新的解决方案来应对,这就是为什么我们很高兴在Cloudera Data Platform (CDP)引入专为大规模数据集设计的下一代表格式(table format) - Apache Iceberg。今天,我
数据分析EPHS(5)-使用Hive SQL计算数列统计值
http://archive.ics.uci.edu/ml/datasets/Iris
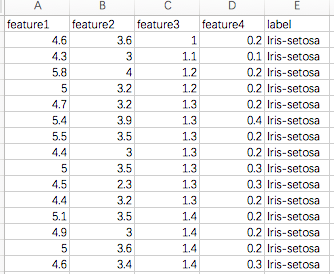
数据分析EPHS(5)-使用Hive SQL计算数列统计值
http://archive.ics.uci.edu/ml/datasets/Iris
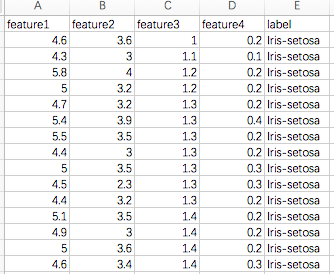
开箱即用,腾讯数据湖计算为海量数据分析赋能
导读 / Introduction 数据湖解决了海量异构数据的入湖和存储需求。通过对海量数据的分析挖掘,提升对数据的洞察,助力数字化决策,进而促进业务发展,是每个企业构建数据湖的根本目的所在。随着业务迭代的不断加速,企业对数据时效性和数据分析敏捷性提出了更高的要求。为此,腾讯云推出了数据湖计算(Data Lake Compute,DLC)。DLC采用存储和计算分离的架构,结合腾讯云对象存储COS和弹性容器服务EKS,打造了一个开箱即用、弹性扩展、按量付费的交互式分析服务。 图1 DLC架构图 高性
Hive优化器原理与源码解析—统计信息Parallelism并行度计算
Parallelism是有关RelNode关系表达式的并行度以及如何将其Opeartor运算符分配给具有独立资源池的进程的元数据。同一个Operator操作符,并行执行和串性执行相比,在成本优化器CBO看来,并行执行的成本更低。
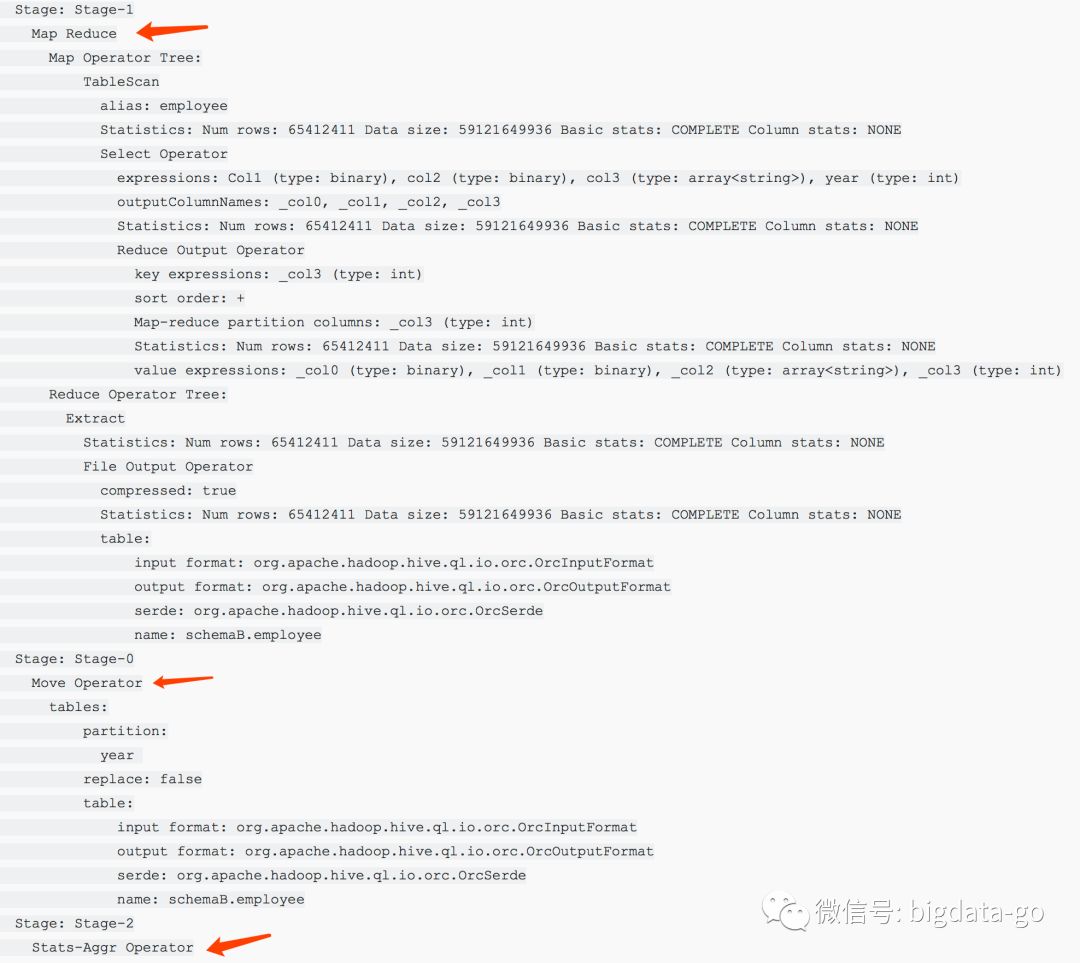
CDP私有云基础版审计信息到外部系统
Cloudera得到世界各地受管制的行业和政府组织的信任,可以存储和分析有关人、医疗保健数据、财务数据或仅对客户本身敏感的专有信息的PB级别的高度敏感或机密的信息。
数据湖实践 | Iceberg 在网易云音乐的实践
本文将从另一个角度为大家介绍 iceberg(结合之前推送的Iceberg快速入门,可以更深入的理解),然后分享 iceberg 在网易云音乐的一些实践,希望对大家能有所帮助。

impala + kudu | 大数据实时计算踩坑优化指南
一开始需要全量导入kudu,这时候我们先用sqoop把关系数据库数据导入临时表,再用impala从临时表导入kudu目标表
由于sqoop从关系型数据直接以parquet格式导入hive会有问题,这里默认hive的表都是text格式;每次导完到临时表,需要做invalidate metadata 表操作,不然后面直接导入kudu的时候会查不到数据.
除了查询,建议所有impala操作都在impala-shell而不在hue上面执行
impala并发写入kudu的时候,数据量比较大的时候
这时候kudu配
升级到 CDP 私有云基础 - 分步指南
我们最近的博客讨论了从传统平台到 CDP 私有云基础的四种途径。在本博客和随附的视频中,我们将深入探讨运行从 CDH5 或 CDH6 到 CDP 私有云基础的就地升级的机制。整体升级遵循如下所示的七个步骤。