
导语
文章整理了全球软件开发大会QCon《PB级数据秒级分析-腾讯云原生湖仓DLC架构揭秘》。大数据基于海量数据的分析,硬件、存储、计算资源尽量都可以用廉价的资源完成,如何在廉价资源上进行性能优化尤为重要。大数据是一种IO密集型负载,性能优化也首先着眼于IO优化。

开篇:云提供了便利的按需使用方式,最佳实践非常重要
主持人:过去几年,数据湖能力已经在腾讯内部包括微信视频号、小程序等多个业务大规模落地,数据规模达到 PB 至 EB 级别,在此基础上,腾讯自研业务也启动了云原生湖仓能力建设。云原生湖仓架构最大的挑战什么?腾讯云原生湖仓DLC从哪些方面着手解决问题?接下来掌声有请腾讯云大数据专家工程师于华丽为大家带来他的分享【PB 级数据秒级分析,腾讯云原生湖仓 DLC 架构揭秘】
于华丽:大家下午好,我是于华丽来自于腾讯大数据。相信已经听了4个专场专题的分享,收获颇丰,但是肯定也是比较累了,那我就先抛整个分享最核心的基础那就是“大数据是io密集型负载,性能优化优先考虑io”。非常荣幸代表腾讯云原生湖仓DLC团队来到qcon,分享DLC做到pb级数据秒级分析的背后的架构逻辑。

简单做一个自我介绍,我是腾讯DLC内核研发负责人,毕业于复旦大学数学系,接近十年公有云大数据经验,AWS、阿里云、腾讯云基本上这些公有云的厂商都有非常深入的一些合作,踩坑真的是无数,基本上对每一家云厂商特性、问题如数家珍。
总结十年公有云大数据经验来说,公有云用的好可以又快又稳又省钱,用错了可能就是灾难性的,最佳实践非常重要,最佳实践能够落地成全托管saas产品,屏蔽底层复杂逻辑,也就非常有价值了,传统自己idc购买机器流程那么复杂,但是公有云上可能就是填几个数字,填错了可能就是一大笔账单,尤其是有的国外厂商是后付费,绑信用卡,账单一来那真的是一言难尽。
第一部分:云原生湖仓的诞生背景、价值、挑战
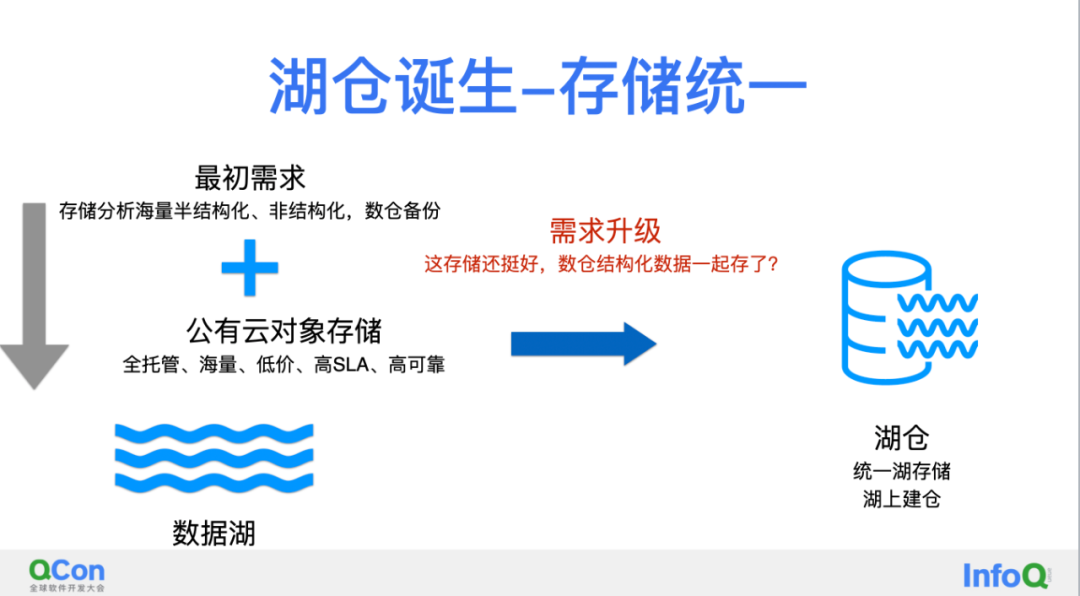
首先介绍湖仓到底是什么东西?我相信大家其实对于这个词已经不算陌生了,数据湖,数据仓,湖仓一系列的名词,我用最直白、最狭义方式去解释它的话,是数据湖跟数仓存储架构统一。
数据湖最初的需求是,要存储和分析海量的半结构化非结构化的数据,数据仓备份和温冷数据存储。在公有云找到了对象存储,海量、低价、高SLA和高可靠性这样一个全托管的存储产品,成本方面对象存储对比客户HDFS自建大概有10:1的性价比,还是非常的有吸引力。
这个存储系统看起来这么好,有没有可能把数仓一起解决,结构化数据是不是存在这里,这个需求的升级,就是现代湖仓架构的基础了。
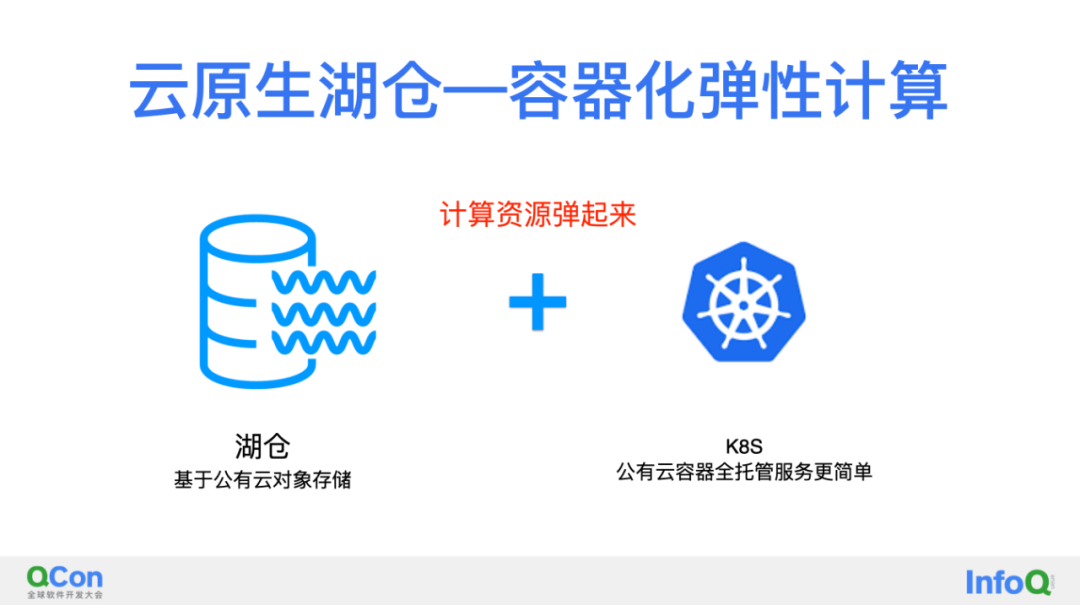
云原生湖仓是什么东西呢?最狭义的理解,就是容器化的计算,把k8s加上了。更加广义的理解应该长在云上,更多的使用云上已有的全托管产品,比如利用对象存储、本身服务也应该云原生化。

在云原生湖仓架构下,会面临很大的挑战就是“性能”。为什么有“性能”的挑战?第一:对象存储有很好的成本的优势,但是引入对象存储之后变成了存算分离的架构,损失了本地计算,性能损失30%以上。其次弹性计算跟分析性能是矛盾的变量,scaleup需要时间,甚至有可能弹不出来,没有文件缓存,弹性会引起数据倾斜。最后是敏捷分析,海量明细数据直接分析也是很直接的需求。
第二部分:腾讯云原生湖仓产品DLC是如何应对挑战的
DLC产品定位
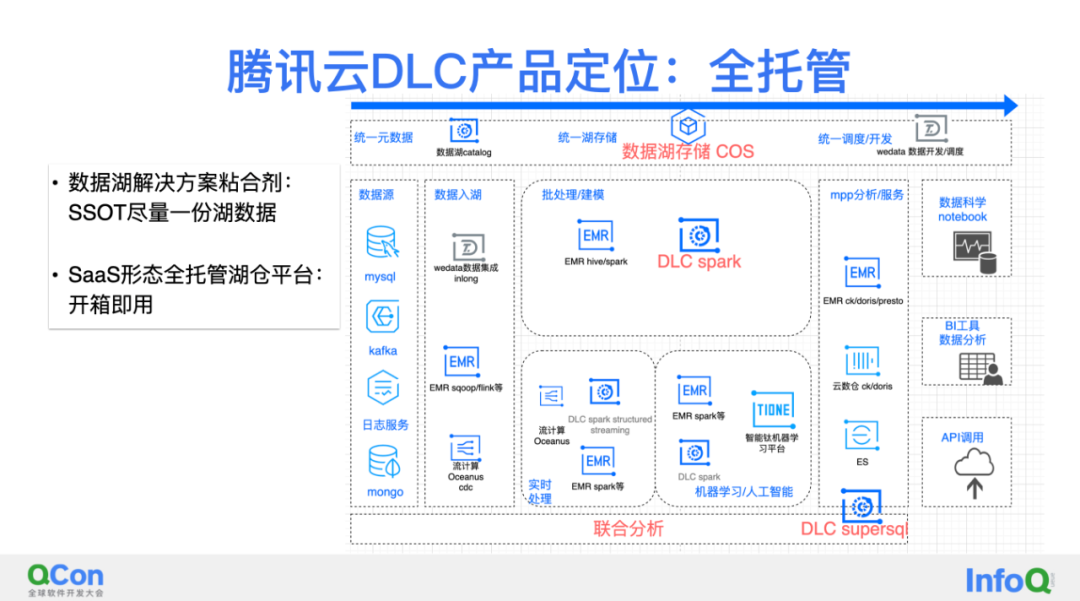
接下来看DLC是如何应对云原生湖仓的挑战的,具体分享怎么做之前,简单介绍一下DLC 的产品,简单三个字“全托管”,不同于EMR,DLC是开箱即用的,例如交互界面、元数据、安全、spark ddl server、spark history服务等都是全托管的免搭建,而且有很多都是免费提供的。
第二个特点,DLC是腾讯云数据湖解决方案的粘合剂,不同产品能够用一份湖仓数据,带给用户低成本,低维护成本的价值。
DLC架构理念
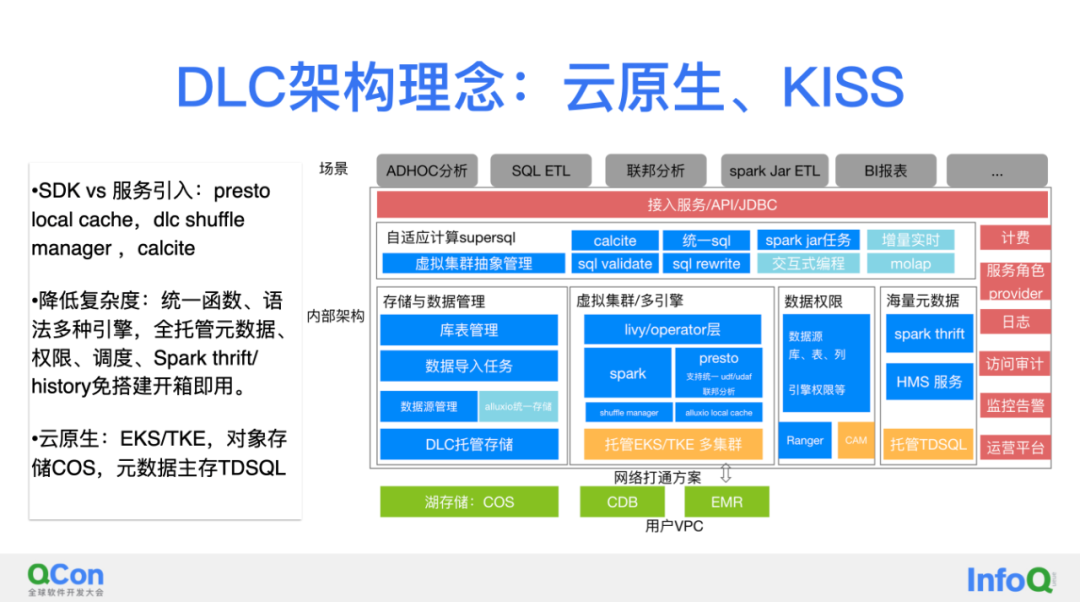
接下来讲DLC 的架构理念,DLC 是腾讯大数据自研能力的上云,但是并不是简单平移部署,产品形态是最大的差异,DLC是多租户的全托管产品,我们秉持两大原则:1.保持简单KISS;2.云原生。
保持简单上我们是非常执着的,从两个点去体现两方面:
- 对于服务引用非常保守,服务能少则少,取而代之的是sdk的接入,例如右边图的presto的local cache就不会引入alluxio cluster,spark这儿不引入rss服务而是轻量简单的shuffle manager等等;
- 降低使用复杂度,DLC集成了腾讯自研supersql,去实现统一函数和语法来去两个引擎无缝切换。另外右边这个图大部分服务都是托管的,如元数据、调度、权限、DDL服务、spark history等这些服务都是用户免搭建,开箱即用。而且大部分都是免费的,免费额度,正确使用也是完全够用的。
云原生原则:狭义的说,DLC都是基于容器的,包括计算引擎和各种服务容器化。广义的说,云原生更应该“长在云上”,DLC直接用云上的对象存储、云数据库、云KAFKA、TDSQL等等全托管的SaaS服务。
DLC实现PB级数据秒级分析

回到最开始的问题“高性能”,PB级数据秒级分析该怎么去做,从三个大维度展开。
在开篇就跟大家铺垫了一个背景,海量数据而且要廉价资源,大数据是I0密集型的负载。我们从三个层面出发讲,大部分都是从IO优化的层面去讲,第一个:多维的Cache的角度出发,包括文件缓存,中间结果缓存等;第二:从弹性模型讲;第三:从三维filter的模型:分区、列、文件。
多维cache

多维Cache分了三个角度:1.文件缓存;2.Fragment结果缓存,中间结果缓存;3.元数据的缓存,重点说说前两个。
文件缓存
文件缓存,在DLC上线了Alluxio Local Cache。优点是没有单独的alluxio集群,也不占用计算资源,免运维。当然也会有需要优化的地方,文件级别/split级别,跨租户Cache缓存数据安全,缓存一致性、考虑弹性影响、监控、黑名单一系列需要优化考虑的地方,这些DLC都会帮客户完成。在一些情况下,访问cos的性能有3—10倍的提升。
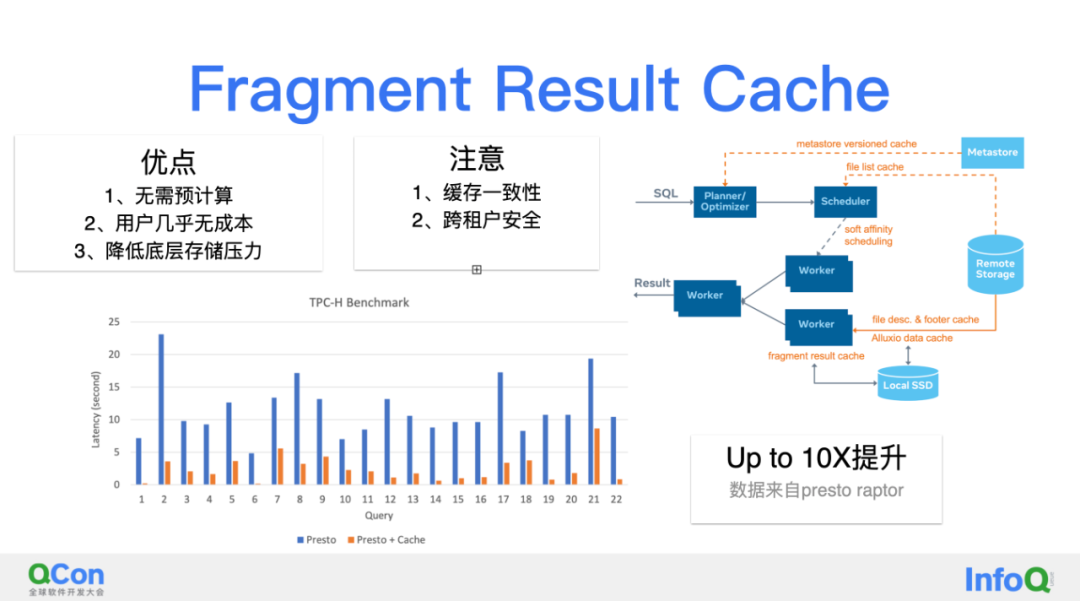
Fragment 结果缓存
其次是中间的结果缓存,优点是不需要预计算,我们知道物化视图也非常流行,但是物化视图的利用率往往不好量化,事实上通常很低。而根据访问行为缓存下来的是用户行为肯定的。另外是用户几乎没有什么成本,同时也很大程度上降低底层存储的压力。同样还会涉及到一些问题需要大家注意,例如缓存一致性,跨租户的安全。性能看来自presto社区的数据,raptorx有接近10X的性能提升。
虚拟集群弹性模型

刚才讲两种缓存效果接近10倍的性能提升,对弹性模型就有了很高的要求,因为缓存的命中是很依赖集群拓扑的稳定的。另外资源启动要时间,新拉容器和镜像最快也要1—2分钟;最后client预热很重要,包括各种服务都是lazy加载的module等等,这也都是需要30秒甚至1分钟这样的时间,这跟我们要求的秒级分析就差太远了。
那DLC 是如何设计这个问题的,我们是采用虚拟集群架构去解决这个问题。虚拟集群以子集群为最小单位去横向弹子集群,这样子集群拓扑稳定,资源跟client都有很好预热。而且因为子集群的query隔离,子集群也是很容易缩容的。
多维Filter过滤

继续说性能提升,还是IO优化,技术也是比较成熟的,只是还不怎么普及。先看第二个,列存parquet/orc,结合引擎project的下推;这样只是关心的列才会被扫描。第三个分区/分桶也是比较常规了,但是最新业界的新特性比如dynamic partition puning,可以很好的加速分区需要推断的场景。右边两个不仔细展开,下面仔细说说稀疏索引,Bloomfilter、zordering本质逻辑上是类似的,需要结合引擎的谓词下推减少io扫描,加速分析。
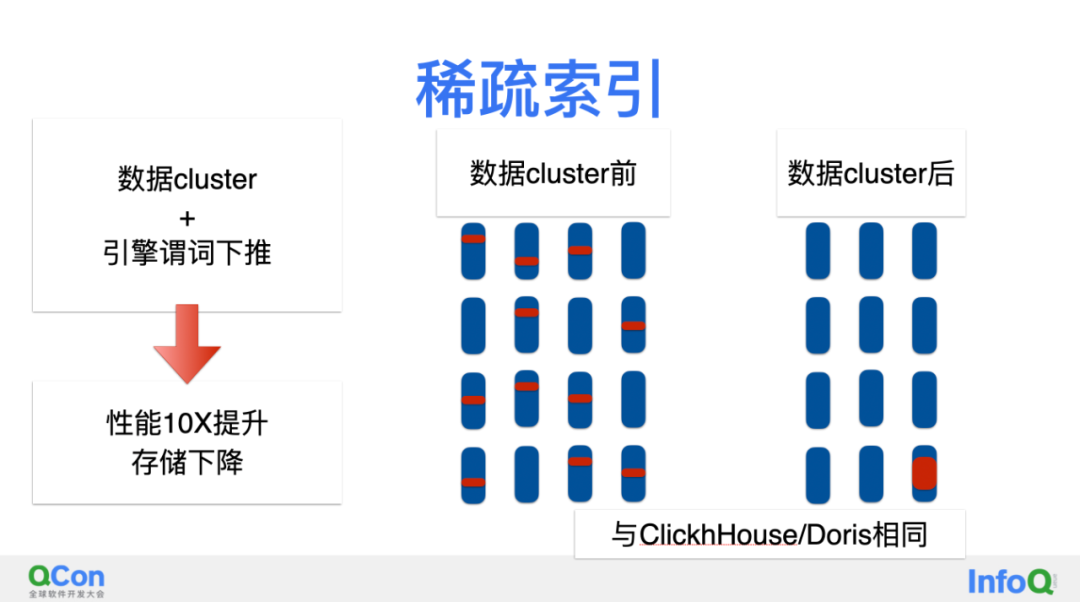
稀疏索引
在大数据的海量低成本要求下,稀疏索引可以做到降低存储成本并且加速分析性能,通过减少数据扫描量达到性能提升。具体分两步:第一步数据要进行cluster,类似的数聚在一起,结合引擎谓词下推,性能达到10X以上的提升。同时也能带来存储的下降,这个原理其实很容易理解,类似的数据在一起了,encodin压缩能起到更好的效果。
这个也是大数据引擎,比如说像CK、Doris很重要的性能加速模型。
稳定性
稳定性也是大数据很重要的诉求,前面看到像索引的构建都需要进行大规模的数据ETL。稳定性相关有很多努力,包括虚拟集群弹性模型本身减少了弹性引擎的数据倾斜、iceberg减少底层list、rename导致任务失败等等问题。这里我们主要分享下DLC 的spark shuffle manager架构。
我们知道腾讯开源了RSS的服务Filestorm,在全托管云原生的场景下我们做了简化和改造,原理是:优先使用本地磁盘,不足的时候spill到cos,下面是业界几种典型的思路,DLC的做法秉持着减少服务引入保持简单,降低用户成本、减少用户/服务的运维出发。效果也很明显,大部分任务/task都会以原有的性能完成任务,少量数据倾斜的任务/task会有损失一定性能稳定的完成。
低成本、易用

DLC作为全托管的产品,还是要强调一下低成本和易用的特性。基于COS湖存储VS自建HDFS其实80%以上节省,这里主要是EC,以及HDFS要预留资源,以及COS有各种冷热分层策略进一步降低成本。基于EKS或者TKE弹性资源,对比固定资源50%以上的成本,如果是交互式分析场景,周六周日两天成本就是节省的,晚上也是节省的。离线是类似的。
最后DLC是全托管的免运维的一个产品,统一的SQL在两个引擎平滑迁移,SaaS的元数据、DDL服务、权限、调度、SaaS级别的Spark history保障了用户开箱即用,而且这些公共服务大部分免费,有的是有免费额度的,正确使用都完全够用。
第三部分:湖仓背景下的建模新思路

接下来一起看下,在云原生湖仓架构下,建模有有哪些新思路:
第一个,扁平湖仓架构,核心是不再维护复杂的数仓分层,而是把明细层的数据能够直接高性能分析;第二个是离线增量;第三个,现在业界比较时髦的新方向实时增量湖仓。

仔细讲一下扁平湖仓的结构,要解释为什么需要扁平湖仓建模,首先要看一下为什么要一层层去做分层建模,首先是在传统的数仓架构下,明细数据的分析的性能不够高,被迫去进行的预计算,同时因为多个结果可能会重复利用一部分公共数据,进行了etl抽取。但是在PB级数据秒级分析的能力下,这些几乎都是不必要的。
层层建模的问题:第一是模式是固定的,不够敏捷。响应需求,从需求对接、历史数据刷新、测试验收,一两个周就过去了;其次是计算利用率往往是低的,尤其Cube。Cube虽然命中很快,单cube的利用率往往是个大大的问号,从我们的经验来看其实利用率是非常低的;以及分层离线更新是比较慢的而现在特别火的实时增量更新并不是成熟和稳定,即使做落地了,对于存储和计算硬件的需求往往也是很高的。
那结合第二段云原生湖仓做性能提升各种收手段,启动在明细致层直接分析的扁平湖仓架构的时代。当然最好能结合BI工具的时序结果的缓存,这样BI层都可以省去。

介绍下游戏客户案例:实时扁平湖仓秒级分析
逻辑架构非常简单直接,数据都是在Kafka,通过DLC spark去做实时数据的接入到几百张iceberg明细表,并且能够保证幂等,这儿有一个特点就是一个Kafka里面有很多张表的数据,这儿保证幂等也有一些比较有意思的逻辑。入到明细表之后,开启明细表背后的一些优化,用DLC supersql—spark,进行清洗、合并小文件、以及稀疏索引构建等,最后达到的效果直接用DCL supersql-presto 去做秒级的分析,最后去对接BI的工具,达到一个非常好的分析性能,架构简单明了,扁平湖仓没有各种建模。
推荐阅读



关注腾讯云大数据公众号
邀您探索数据的无限可能

点击“阅读原文”,了解相关产品最新动态
↓↓↓