目录
Spark 运行模式
一、本地模式:Local Mode
二、集群模式:Cluster Mode
三、云服务:Kubernetes 模式
Spark 运行模式
Spark 框架编写的应用程序可以运行在本地模式(Local Mode)、集群模式(Cluster Mode)和云服务(Cloud),方便开发测试和生产部署。
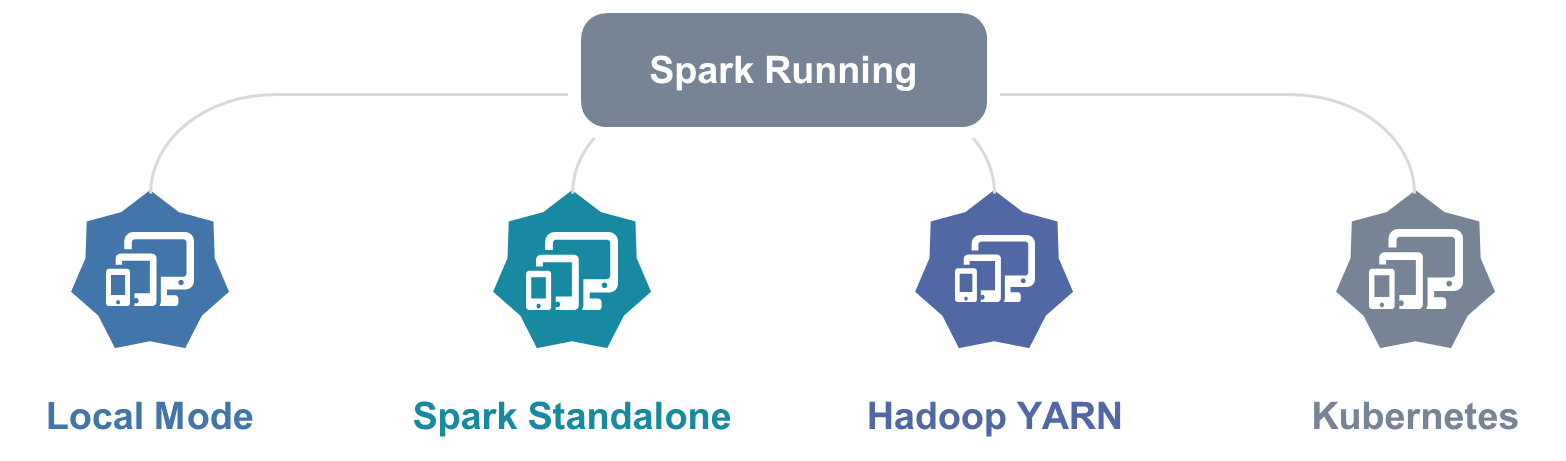
一、本地模式:Local Mode
将Spark 应用程序中任务Task运行在一个本地JVM Process进程中,通常开发测试使用。

二、集群模式:Cluster Mode
将Spark应用程序运行在集群上,比如Hadoop YARN集群,Spark 自身集群Standalone及Apache Mesos集群,网址:http://spark.apache.org/docs/2.4.3/
- Spark Standalone集群模式(开发测试及生成环境使用):类似Hadoop YARN架构,典型的Mater/Slaves模式,使用Zookeeper搭建高可用,避免Master是有单点故障的。
- Hadoop YARN集群模式(生产环境使用):运行在 yarn 集群之上,由 yarn 负责资源管理,Spark 负责任务调度和计算,好处:计算资源按需伸缩,集群利用率高,共享底层存储,避免数据跨集群迁移。
- Apache Mesos集群模式(国内使用较少):运行在 mesos 资源管理器框架之上,由 mesos 负责资源管理,Spark 负责任务调度和计算。
三、云服务:Kubernetes 模式
中小公司未来会更多的使用云服务,Spark 2.3开始支持将Spark 开发应用运行到K8s上。
云平台都提供了 EMR产品(弹性MapReduce计算)
