公司在腾讯云有一个大数据集群,用hdp的ambari部署管理的,hdp面有hadoop、hive、spark等常用的大数据组件,公司的报表都从这里生成。
随着业务发展,历史数据量急速增加,半年已经过百TB,还在以每天几TB的数量增加着,删除太可惜了,要找个地方备份。于是想到了对象存储,看了下官方文档 https://cloud.tencent.com/document/product/436/6884, hadoop任务竟然可以直接跑在腾讯云对象存储上,太给力了!直接动手实践一下。
部署过程
部署配置过程,文档里还是写的很详细的,这里简单列下步骤:
1、在腾讯云存储新建一个bucket,注意bucket建的园区需要和你大数据cvm的园区相同,这样上传、下载都会走内网,不收钱的。如果建成了不同园区,下载会收流量费用。
2、有了bucket后,去文档里给的github地址(https://github.com/tencentyun/hadoop-cos/tree/master/dep)下载编译好的最新版本的两个lib,我的hadoop版本是2.7.3,所以下载 cos_hadoop_api-5.2.6.jar,hadoop-cos-2.7.3.jar(如果没有对应版本也可以下载源码自己编译)。这两个lib需要复制到跑hadoop任务的所有机器上去,都需要放到同一个路径下,后面会用到。
3、按照官网文档修改你的hadoop集群配置。这一步,有可能很多朋友现网环境配置不能随意变更,也可以针对对象存储,单独生成一份配置,在跑hadoop任务的时候通过参数指定 ,例如:hadoop fs -conf ./core-site.xml -libjars ./cos_hadoop_api-5.2.6.jar,./hadoop-cos-2.7.3.jar -ls / 。
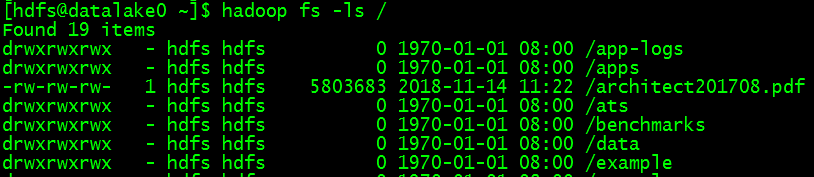
通过上面三步,大概不到半小时的时间,就部署好了。赶紧执行下 hadoop fs -ls / 试试效果,列出了我的bucket里的文件,so easy!
跑mr任务
不过,在执行hadoop的example里的MapReduce任务的时候 hadoop jar ./mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount cosn://example/mr/input cosn://example/mr/output,报错了 "Class org.apache.hadoop.fs.CosFileSystem not found"。
上网查了下,为了能够在云对象存储运行 MAPREDUCE 任务,还需更改hdp安装目录下/hdp/apps/2.6.xxxx/mapreduce/mapreduce.tar.gz包的内容,将 COSN 的两个lib放如上述压缩包,替换掉原来的文件,测试可用。不过这个方案有个缺点,就是hdp的ambari每次修改完配置重启的时候,都会把mapreduce.tar.gz
替换回系统自带的。该方案治标不治本。
不过上面的方案启发了我,应该是MapReduce任务的配置有点问题,导致找不到cos的lib,研究了下mapred-site.xml这个配置文件,在mapreduce.application.classpath里加上cosn的lib,就ok了。
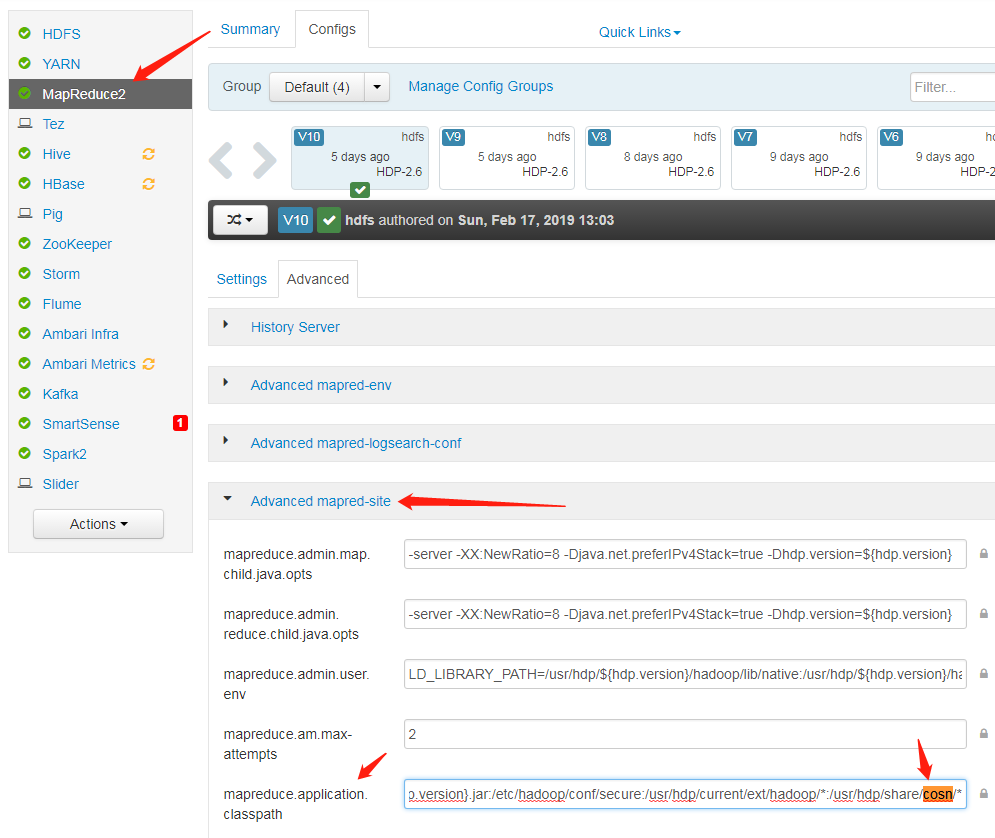
测试ok,即使修改集群配置、重启集群,都还能正常执行MapReduce任务:
[hdfs@hadoop01 ~]$ hadoop jar /usr/hdp/2.6.xxx/hadoop-mapreduce/hadoop-mapreduce-examples.jar wordcount cosn://testshhadoop-xxxxxxx/input/ cosn://testshhadoop-xxxxxxxx/example/output/
19/02/22 10:44:12 INFO client.RMProxy: Connecting to ResourceManager at hadoop03.cos.qcloud.com/xxxxxxx:8050
19/02/22 10:44:12 INFO client.AHSProxy: Connecting to Application History server at hadoop04.cos.qcloud.com/xxxxxxx:10200
19/02/22 10:44:13 INFO fs.CosNativeFileSystemStore: store file input stream md5 hash content length
19/02/22 10:44:13 INFO fs.CosFsDataOutputStream: OutputStream for key '/user/hdfs/.staging/job_1550379850904_0007/job.jar' upload complete
19/02/22 10:44:14 INFO input.FileInputFormat: Total input paths to process : 1
19/02/22 10:44:14 INFO fs.CosNativeFileSystemStore: store file input stream md5 hash content length
19/02/22 10:44:14 INFO fs.CosFsDataOutputStream: OutputStream for key '/user/hdfs/.staging/job_1550379850904_0007/job.split' upload complete
19/02/22 10:44:14 INFO fs.CosNativeFileSystemStore: store file input stream md5 hash content length
19/02/22 10:44:14 INFO fs.CosFsDataOutputStream: OutputStream for key '/user/hdfs/.staging/job_1550379850904_0007/job.splitmetainfo' upload complete
19/02/22 10:44:14 INFO mapreduce.JobSubmitter: number of splits:1
19/02/22 10:44:14 INFO fs.CosNativeFileSystemStore: store file input stream md5 hash content length
19/02/22 10:44:14 INFO fs.CosFsDataOutputStream: OutputStream for key '/user/hdfs/.staging/job_1550379850904_0007/job.xml' upload complete
19/02/22 10:44:14 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1550379850904_0007
19/02/22 10:44:14 INFO impl.YarnClientImpl: Submitted application application_1550379850904_0007
19/02/22 10:44:14 INFO mapreduce.Job: The url to track the job: http://hadoop03.cos.qcloud.com:8088/proxy/application_1550379850904_0007/
19/02/22 10:44:14 INFO mapreduce.Job: Running job: job_1550379850904_0007
19/02/22 10:44:20 INFO mapreduce.Job: Job job_1550379850904_0007 running in uber mode : false
19/02/22 10:44:20 INFO mapreduce.Job: map 0% reduce 0%
19/02/22 10:44:26 INFO mapreduce.Job: map 100% reduce 0%
19/02/22 10:44:31 INFO mapreduce.Job: map 100% reduce 100%
19/02/22 10:44:34 INFO mapreduce.Job: Job job_1550379850904_0007 completed successfully
19/02/22 10:44:34 INFO mapreduce.Job: Counters: 49
File System Counters
COSN: Number of bytes read=14408
COSN: Number of bytes written=55
COSN: Number of read operations=0
COSN: Number of large read operations=0
COSN: Number of write operations=0
FILE: Number of bytes read=89
FILE: Number of bytes written=303554
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Rack-local map tasks=1
Total time spent by all maps in occupied slots (ms)=9808
Total time spent by all reduces in occupied slots (ms)=5824
Total time spent by all map tasks (ms)=2452
Total time spent by all reduce tasks (ms)=2912
Total vcore-milliseconds taken by all map tasks=2452
Total vcore-milliseconds taken by all reduce tasks=2912
Total megabyte-milliseconds taken by all map tasks=10043392
Total megabyte-milliseconds taken by all reduce tasks=5963776
Map-Reduce Framework
Map input records=3
Map output records=9
Map output bytes=89
Map output materialized bytes=89
Input split bytes=117
Combine input records=9
Combine output records=7
Reduce input groups=7
Reduce shuffle bytes=89
Reduce input records=7
Reduce output records=7
Spilled Records=14
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=74
CPU time spent (ms)=1840
Physical memory (bytes) snapshot=593371136
Virtual memory (bytes) snapshot=9280081920
Total committed heap usage (bytes)=462946304
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=4994
File Output Format Counters
Bytes Written=55至此,就能通过hadoop自带的hadoop distcp任务,愉快地把我们公司的历史数据批量备份到腾讯云对象存储上了,并且想要对这些数据做分析,也不用把他们拉回本地hdfs,可以直接分析云上数据。