本文中的部分示例基于如下场景:餐厅点菜,Dish为餐厅中可提供的菜品,Dish的定义如下:
1public class Dish {
2 /** 菜品名称 */
3 private final String name;
4 /** 是否是素食 */
5 private final boolean vegetarian;
6 /** 含卡路里 */
7 private final int calories;
8 /** 类型 */
9 private final Type type;
10
11 public Dish(String name, boolean vegetarian, int calories, Type type) {
12 this.name = name;
13 this.vegetarian = vegetarian;
14 this.calories = calories;
15 this.type = type;
16 }
17
18 public enum Type { MEAT, FISH, OTHER }
19
20 // 省略set get方法
21}菜单的数据如下:
1List<Dish> menu = Arrays.asList(
2new Dish("pork", false, 800, Dish.Type.MEAT),
3new Dish("beef", false, 700, Dish.Type.MEAT),
4new Dish("chicken", false, 400, Dish.Type.MEAT),
5new Dish("french fries", true, 530, Dish.Type.OTHER),
6new Dish("rice", true, 350, Dish.Type.OTHER),
7new Dish("season fruit", true, 120, Dish.Type.OTHER),
8new Dish("pizza", true, 550, Dish.Type.OTHER),
9new Dish("prawns", false, 300, Dish.Type.FISH),
10new Dish("salmon", false, 450, Dish.Type.FISH) );我们以一个简单的示例来引入流:从菜单列表中,查找出是素食的菜品,并打印其菜品的名称。
在Java8之前,我们通常是这样实现该需求的:
1List<String> dishNames = new ArrayList<>();
2for(Dish d menu) {
3 if(d.isVegetarian()) {
4 dishNames.add(d.getName());
5 }
6}
7//输出帅选出来的菜品的名称:
8for(String n : dishNames) {
9 System.out.println(n);
10}那在java8中,我们可以这样写:
1menu.streams() .filter( Dish::isVegetarian).map( Dish::getName) .forEach( a -> System.out.println(a) );其运行输出的结果:

怎么样,神奇吧!!!
在解释上面的代码之前,我们先对流做一个理论上的介绍。
流是什么?
流,就是数据流,是元素序列,在Java8中,流的接口定义在 java.util.stream.Stream包中,并且在Collection(集合)接口中新增一个方法:
1default Stream<E> stream() {
2 return StreamSupport.stream(spliterator(), false);
3}流的简短定义:从支持数据处理操作的源生成的元素序列。例如集合、数组都是支持数据操作的数据结构(容器),都可以做为流的创建源,该定义的核心要素如下:
- 源 流是从一个源创建来而来,而且这个源是支持数据处理的,例如集合、数组等。
- 元素序列 流代表一个元素序列(流水线),因为是从根据一个数据处理源而创建得来的。
- 数据处理操作 流的侧重点并不在数据存储,而在于数据处理,例如示例中的filter、map、forEach等。
- 迭代方式 流的迭代方式为内部迭代,而集合的迭代方式为外部迭代。例如我们遍历Collection接口需要用户去做迭代,例如for-each,然后在循环体中写对应的处理代码,这叫外部迭代。相反,Stream库使用内部迭代,我们只需要对流传入对应的函数即可,表示要做什么就行。
注意:流和迭代器Iterator一样,只能遍历一次,如果要多次遍历,请创建多个流。
接下来我们将重点先介绍流的常用操作方法。
流的常用操作
filter
filter函数的方法声明如下:
1java.util.stream.Stream#filter
2Stream<T> filter(Predicate<? super T> predicate);该方法接收一个谓词,返回一个流,即filter方法接收的lambda表达式需要满足 ( T -> Boolean )。
示例:从菜单中选出所有是素食的菜品:
1List<Dish> vegetarianDishs = menu.stream().filter( Dish::isVegetarian ) // 使用filter过滤流中的菜品。
2 .collect(toList()); // 将流转换成List,该方法将在后面介绍。温馨提示:流的操作可以分成中间件操作和终端操作。中间操作通常的返回结果还是流,并且在调用终端操作之前,并不会立即调用,等终端方法调用后,中间操作才会真正触发执行,该示例中的collect方法为终端方法。
我们类比一下数据库查询操作,除了基本的筛选动作外,还有去重,分页等功能,那java8的流API能支持这些操作吗? 答案当然是肯定。
distinct
distinct,类似于数据库中的排重函数,就是对结果集去重。 例如有一个数值numArr = [1,5,8,6,5,2,6],现在要输出该数值中的所有奇数并且不能重复输出,那该如何实现呢?
1Arrays.stream(numArr).filter( a -> a % 2 == 0 ).distinict().forEach(System.out::println);limit
截断流,返回一个i不超过指定元素个数的流。 还是以上例举例,如果要输出的元素是偶数,不能重复输出,并且只输出1个元素,那又该如何实现呢?
1Arrays.stream(numArr).filter( a -> a % 2 == 0 ).distinict().limit(1).forEach(System.out::println);skip
跳过指定元素,返回剩余元素的流,与limit互补。
Map
还是类比数据库操作,我们通常可以只选择一个表中的某一列,java8流操作也提供了类似的方法。 例如,我们需要从菜单中提取所有菜品的名称,在java8中我们可以使用如下代码实现:
1版本1:List<String> dishNames = menu.stream().map( (Dish d) -> d.getName() ).collect(Collectors.toList());
2版本2:List<String> dishNames = menu.stream().map( d -> d.getName() ).collect(Collectors.toList());
3版本3:List<String> dishNames = menu.stream().map(Dish::getName).collect(Collectors.toList());文章的后续部分尽量使用最简洁的lambda表达式。
我们来看一下Stream关于map方法的声明:
1<R> Stream<R> map(Function<? super T, ? extends R> mapper)
2接受一个函数Function,其函数声明为:T -> R,接收一个T类型的对象,返回一个R类型的对象。
当然,java为了高效的处理基础数据类型(避免装箱、拆箱带来性能损耗)也定义了如下方法:
1IntStream mapToInt(ToIntFunction<? super T> mapper)
2LongStream mapToLong(ToLongFunction<? super T> mapper)
3DoubleStream mapToDouble(ToDoubleFunction<? super T> mapper)思考题:对于字符数值["Hello","World"] ,输出字符序列,并且去重。 第一次尝试:
1public static void test_flat_map() {
2 String[] strArr = new String[] {"hello", "world"};
3 List<String> strList = Arrays.asList(strArr);
4 strList.stream().map( s -> s.split(""))
5 .distinct().forEach(System.out::println);
6}输出结果:

为什么会返回两个String[]元素呢?因为map(s -> s.split()) 此时返回的流为Stream,那我们是不是可以继续对该Steam[String[]],把String[]转换为字符流,其代码如下:
1public static void test_flat_map() {
2 String[] strArr = new String[] {"hello", "world"};
3 List<String> strList = Arrays.asList(strArr);
4 strList.stream().map( s -> s.split(""))
5 .map(Arrays::stream)
6 .distinct().forEach(System.out::println);
7}其返回结果:

还是不符合预期,其实原因也很好理解,再次经过map(Arrays:stream)后,返回的结果为Stream,即包含两个元素,每一个元素为一个字符流,可以通过如下代码验证:
1public static void test_flat_map() {
2 String[] strArr = new String[] {"hello", "world"};
3 List<String> strList = Arrays.asList(strArr);
4 strList.stream().map( s -> s.split(""))
5 .map(Arrays::stream)
6 .forEach( (Stream<String> s) -> {
7 System.out.println("\n --start---");
8 s.forEach(a -> System.out.print(a + " "));
9 System.out.println("\n --end---");
10 } );
11}综合上述分析,之所以不符合预期,主要是原数组中的两个字符,经过map后返回的是两个独立的流,那有什么方法将这两个流合并成一个流,然后再进行disinic去重呢?
答案当然是可以的,flatMap方法闪亮登场:先看代码和显示结果:
1public static void test_flat_map() {
2 String[] strArr = new String[] {"hello", "world"};
3 List<String> strList = Arrays.asList(strArr);
4 strList.stream().map( s -> s.split(""))
5 .flatMap(Arrays::stream)
6 .distinct().forEach( a -> System.out.print(a +" "));
7}其输出结果:
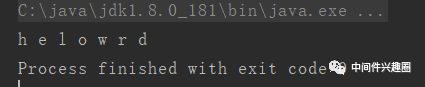
符合预期。一言以蔽之,flatMap可以把两个流合并成一个流进行操作。
查找和匹配
Stream API提供了allMatch、anyMatch、noneMatch、findFirst和findAny方法来实现对流中数据的匹配与查找。
allMatch
我们先看一下该方法的声明:
1boolean allMatch(Predicate<? super T> predicate);接收一个谓词函数(T->boolean),返回一个boolean值,是一个终端操作,用于判断流中的所有元素是否与Predicate相匹配,只要其中一个元素不复合,该表达式将返回false。 示例如下:例如存在这样一个List a,其中元素为 1,2,4,6,8。判断流中的元素是否都是偶数。
1boolean result = a.stream().allMatch( a -> a % 2 == 0 ); // 将返回false。anyMatch
该方法的函数声明如下:
1boolean anyMatch(Predicate<? super T> predicate)
2同样接收一个谓词Predicate( T -> boolean ),表示只要流中的元素至少一个匹配谓词,即返回真。
示例如下:例如存在这样一个List a,其中元素为 1,2,4,6,8。判断流中的元素是否包含偶数。
1boolean result = a.stream().anyMatch( a -> a % 2 == 0 ); // 将返回true。noneMatch
该方法的函数声明如下:
1boolean noneMatch(Predicate<? super T> predicate);同样接收一个谓词Predicate( T -> boolean ),表示只要流中的元素全部不匹配谓词表达式,则返回true。
示例如下:例如存在这样一个List a,其中元素为 2,4,6,8。判断流中的所有元素都不式奇数。
1boolean result = a.stream().noneMatch( a -> a % 2 == 1 ); // 将返回true。findFirst
查找流中的一个元素,其函数声明如下:
1Optional<T> findFirst();返回流中的一个元素。其返回值为Optional,这是jdk8中引入的一个类,俗称值容器类,其主要左右是用来避免值空指针,一种更加优雅的方式来处理null。该类的具体使用将在下一篇详细介绍。
1public static void test_find_first(List<Dish> menu) {
2 Optional<Dish> dish = menu.stream().findFirst();
3 // 这个方法表示,Optional中包含Dish对象,则执行里面的代码,否则什么事不干,是不是比判断是否为null更友好
4 dish.ifPresent(a -> System.out.println(a.getName()));
5}findAny
返回流中任意一个元素,其函数声明如下:
1Optional<T> findAny();reduce
reduce归约,看过大数据的人用过会非常敏感,目前的java8的流操作是不是有点map-reduce的味道,归约,就是对流中所有的元素进行统计分析,归约成一个数值。 首先我们看一下reduce的函数说明:
1T reduce(T identity, BinaryOperator<T> accumulator)- T identity:累积器的初始值。
- BinaryOperator< T> accumulator:累积函数。BinaryOperator< T> extend BiFunction。BinaryOperator的函数式表示,接受两个T类型的入参,返回T类型的返回值。
1Optional<T> reduce(BinaryOperator<T> accumulator);可以理解为没有初始值的归约,如果流为空,则会返回空,故其返回值使用了Optional类来优雅处理null值。
1<U> U reduce(U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator<U> combiner);首先,最后的返回值类型为U。
- U identity:累积函数的初始值。
- BiFunction accumulator:累积器函数,对流中的元素使用该累积器进行归约,在具体执行时accumulator.apply( identity, 第二个参数的类型不做限制 ),只要最终返回U即可。
- BinaryOperator< U> combiner:组合器。对累积器的结果进行组合,因为归约reduce,java流计算内部使用了fork-join框架,会对流的中的元素使用并行累积,每个线程处理流中一部分数据,最后对结果进行组合,得出最终的值。
温馨提示:对流API的学习,一个最最重点的就是要掌握这些函数式编程接口,然后掌握如何使用Lambda表达式进行行为参数化(lambda表达当成参数传入到函数中)。
接下来我们举例来展示如何使用reduce。 示例1:对集合中的元素求和
1List<Integer> goodsNumber = Arrays.asList( 3, 5, 8, 4, 2, 13 );
2java7之前的示例:
3int sum = 0;
4for(Integer i : goodsNumber) {
5sum += i;// sum = sum + i;
6}
7System.out.println("sum:" + sum);求和运算符: c = a + b,也就是接受2个参数,返回一个值,并且这三个值的类型一致。
故我们可以使用T reduce(T identity, BinaryOperator< T> accumulator)来实现我们的需求:
1public static void test_reduce() {
2 List<Integer> goodsNumber = Arrays.asList( 3, 5, 8, 4, 2, 13 );
3 int sum = goodsNumber.stream().reduce(0, (a,b) -> a + b);
4 //这里也可以写成这样:
5 // int sum = goodsNumber.stream().reduce(0, Integer::sum);
6 System.out.println(sum);
7}不知大家是否只读(a,b)这两个参数的来源,其实第一个参数为初始值T identity,第二个参数为流中的元素。
那三个参数的reduce函数主要用在什么场景下呢?接下来还是用求和的例子来展示其使用场景。在java多线程编程模型中,引入了fork-join框架,就是对一个大的任务进行先拆解,用多线程分别并行执行,最终再两两进行合并,得出最终的结果。reduce函数的第三个函数,就是组合这个动作,下面给出并行执行的流式处理示例代码如下:
1 public static void test_reduce_combiner() {
2
3 /** 初始化待操作的流 */
4 List<Integer> nums = new ArrayList<>();
5 int s = 0;
6 for(int i = 0; i < 200; i ++) {
7 nums.add(i);
8 s = s + i;
9 }
10
11 // 对流进行归并,求和,这里使用了流的并行执行版本 parallelStream,内部使用Fork-Join框架多线程并行执行,
12 // 关于流的内部高级特性,后续再进行深入,目前先以掌握其用法为主。
13 int sum2 = nums.parallelStream().reduce(0,Integer::sum, Integer::sum);
14 System.out.println("和为:" + sum2);
15
16 // 下面给出上述版本的debug版本。
17
18 // 累积器执行的次数
19 AtomicInteger accumulatorCount = new AtomicInteger(0);
20
21 // 组合器执行的次数(其实就是内部并行度)
22 AtomicInteger combinerCount = new AtomicInteger(0);
23
24 int sum = nums.parallelStream().reduce(0,(a,b) -> {
25 accumulatorCount.incrementAndGet();
26 return a + b;
27 }, (c,d) -> {
28 combinerCount.incrementAndGet();
29 return c+d;
30 });
31
32 System.out.println("accumulatorCount:" + accumulatorCount.get());
33 System.out.println("combinerCountCount:" + combinerCount.get());
34}从结果上可以看出,执行了100次累积动作,但只进行了15次合并。
流的基本操作就介绍到这里,在此总结一下,目前接触到的流操作:
1、filter
- 函数功能:过滤
- 操作类型:中间操作
- 返回类型:Stream
- 函数式接口:Predicate
- 函数描述符:T -> boolean
2、distinct
- 函数功能:去重
- 操作类型:中间操作
- 返回类型:Stream
3、skip
- 函数功能:跳过n个元素
- 操作类型:中间操作
- 返回类型:Stream
- 接受参数:long
4、limit
- 函数功能:截断流,值返回前n个元素的流
- 操作类型:中间操作
- 返回类型:Stream
- 接受参数:long
5、map
- 函数功能:映射
- 操作类型:中间操作
- 返回类型:Stream
- 函数式接口:Function
- 函数描述符:T -> R
6、flatMap
- 函数功能:扁平化流,将多个流合并成一个流
- 操作类型:中间操作
- 返回类型:Stream
- 函数式接口:Function>
- 函数描述符:T -> Stream
7、sorted
- 函数功能:排序
- 操作类型:中间操作
- 返回类型:Stream
- 函数式接口:Comparator
- 函数描述符:(T,T) -> int
8、anyMatch
- 函数功能:流中任意一个匹配则返回true
- 操作类型:终端操作
- 返回类型:boolean
- 函数式接口:Predicate
- 函数描述符:T -> boolean
9、allMatch
- 函数功能:流中全部元素匹配则返回true
- 操作类型:终端操作
- 返回类型:boolean
- 函数式接口:Predicate
- 函数描述符:T -> boolean
10、 noneMatch
- 函数功能:流中所有元素都不匹配则返回true
- 操作类型:终端操作
- 返回类型:boolean
- 函数式接口:Predicate
- 函数描述符:T -> boolean
11、findAny
- 函数功能:从流中任意返回一个元素
- 操作类型:终端操作
- 返回类型:Optional
12、findFirst
- 函数功能:返回流中第一个元素
- 操作类型:终端操作
- 返回类型:Optional
13、forEach
- 函数功能:遍历流
- 操作类型:终端操作
- 返回类型:void
- 函数式接口:Consumer
- 函数描述符:T -> void
14、collect
- 函数功能:将流进行转换
- 操作类型:终端操作
- 返回类型:R
- 函数式接口:Collector
15、reduce
- 函数功能:规约流
- 操作类型:终端操作
- 返回类型:Optional
- 函数式接口:BinaryOperator
- 函数描述符:(T,T) -> T
16、count
- 函数功能:返回流中总元素个数
- 操作类型:终端操作
- 返回类型:long
由于篇幅的原因,流的基本计算就介绍到这里了.