第一章 Hadoop MapReduce 是什么
Hadoop MapReduce / MR 是一个软件计算框架,可以轻松地编写应用程序,以可靠,容错的方式并行处理大型硬件集群(数千个节点)上的大量数据(多达TB数据集) 。
一 MapReduce 介绍
1. 基本介绍
MapReduce框架由一个主资源管理器,一个集群节点一个工作器NodeManager和每个应用程序MRAppMaster组成(请参阅YARN体系结构指南)。应用程序通过适当的接口和/或抽象类的实现来指定输入/输出位置和供应图,并减少功能。这些以及其他作业参数构成作业配置。然后,Hadoop 作业客户端将作业(jar /可执行文件等)和配置提交给ResourceManager,然后由ResourceManager负责将软件/配置分发给工作人员,安排任务并对其进行监视,为工作提供状态和诊断信息,客户。
计算节点和存储节点是相同的,也就是说,MapReduce框架和Hadoop分布式文件系统(HDFS)在同一组节点上运行。此配置使框架可以在已经存在数据的节点上有效地调度任务,从而在整个群集中产生很高的聚合带宽。
尽管Hadoop框架是用Java实现的,但MapReduce应用程序不必用Java编写。 Hadoop Streaming是一个实用程序,它允许用户使用任何可执行程序(例如Shell实用程序)作为映射器和/或reducer创建和运行作业。 MapReduce官方文档
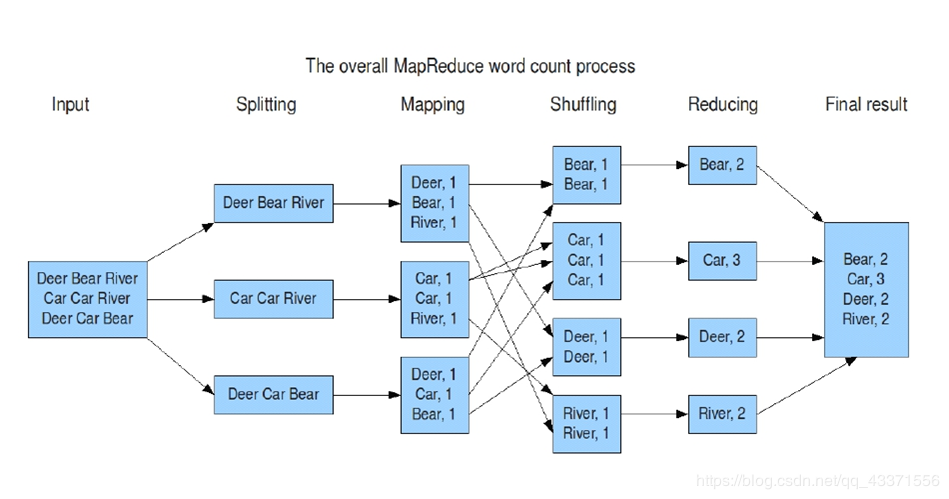
2. MR数据流程方向
输入(格式化k,v)数据集 -> map映射成一个中间数据集(k,v) -> reduce
3. MR 原语/ 核心思想( 重点记忆 )
相同的key为一组,调用一次reduce方法,方法内迭代这一组数据, 进行计算(sum count max min)
4. MR运行原理
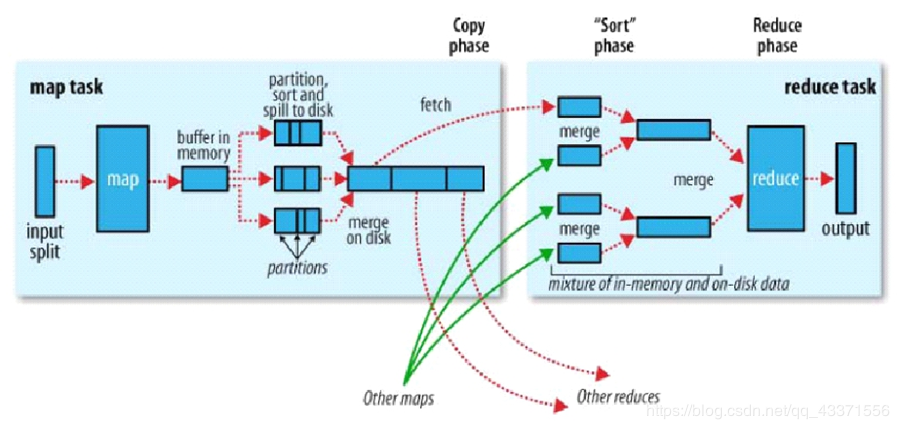
宏观角度
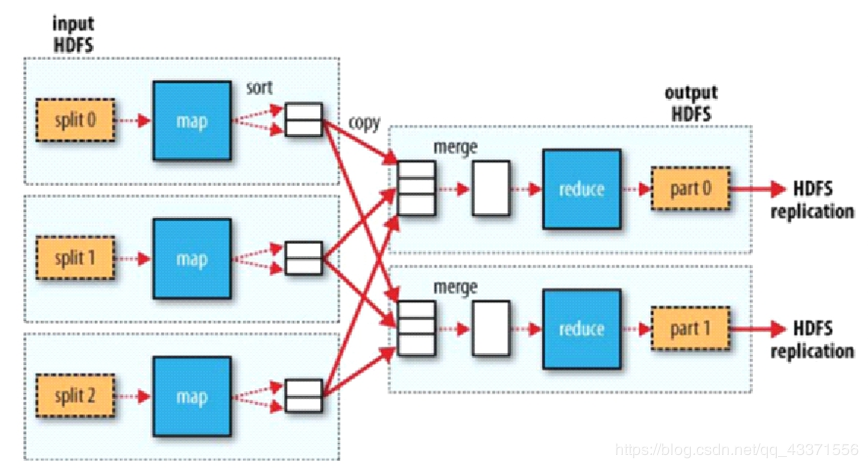
MapReduce 作业通常将输入数据集拆分为独立的块,这些任务由Map Task以完全并行的方式进行处理。框架对map的输出进行排序,然后将其输入到reduce任务。通常,作业的输入和输出都存储在文件系统中。该框架负责安排任务,监视任务并重新执行失败的任务。
注意 : 一个切片对应一个Map 切片以一条记录为单位调用一次Map map数量由切片决定的 , reduce 数据由人来决定的 左边矩形 Map Task( 块/block ) , 小矩形 map方法 右边矩形 Reduce Task( 分区/partition ) , 小矩形 Reduce 方法
微观角度
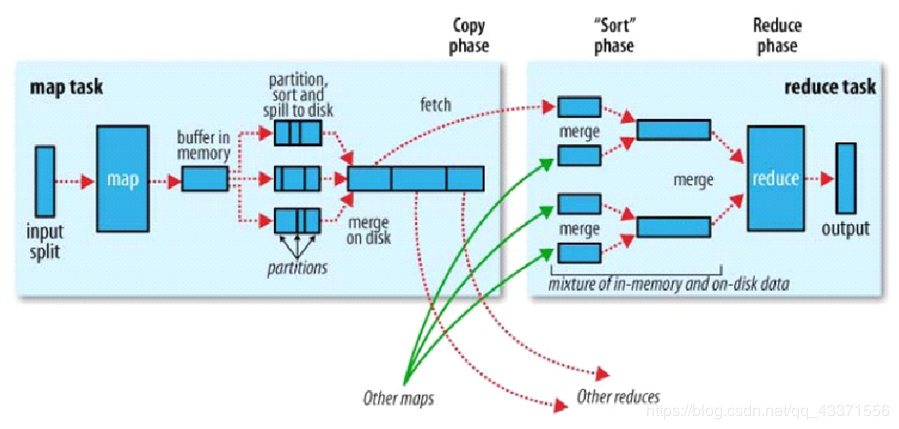
- Shuffler<洗牌>:框架内部实现机制(数据分发) 补充: 面试问如何理解shuffle?(在MapReduce环境下) 1.shuffle就是在reduce启动后 ,在map中拉回属于自己的数据的过程(动作角度) 2.如果面试官说不对,就说是从map输出完数据之后, 算出属于的分区号 /reduce开始 ,一直到拉取并计算数据这一整个过程(逻辑角度) shuffle :动作 :拷贝 ; 逻辑: 数据规划,整理,拉取
- 分布式计算节点数据流转:连接MapTask与 ReduceTask
- Reduce分组和排序强依赖 Map输出的结果: .Reduce没有排序的能力, 只是对map的结果做归并,
理解运行原理角色模型:
- Map: 读懂数据 映射为KV模型 并行分布式 计算向数据移动: / 移动计算
- Reduce: 数据全量/分量加工 Reduce中可以包含不同的key 相同的Key汇聚到一个Reduce中 相同的Key调用一次reduce方法 排序实现key的汇聚
- K,V使用自定义数据类型 作为参数传递,节省开发成本,提高程序自由度 Writable序列化:使能分布式程序数据交互 Comparable比较器:实现具体排序(字典序,数值序等)
5. 块 ,切片 , map ,reduce ,组 ,分区 ,输出文件之间的关系

6. 计算框架
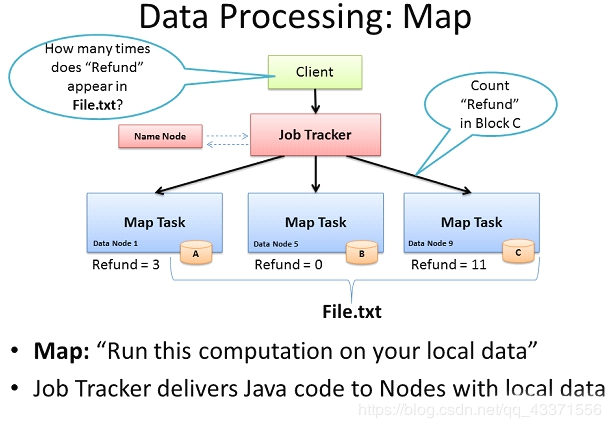
计算框架 Map
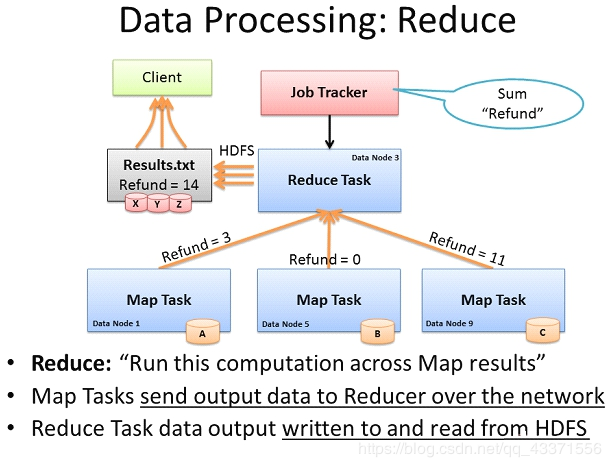
计算框架Reduce
计算框架MR图例演示
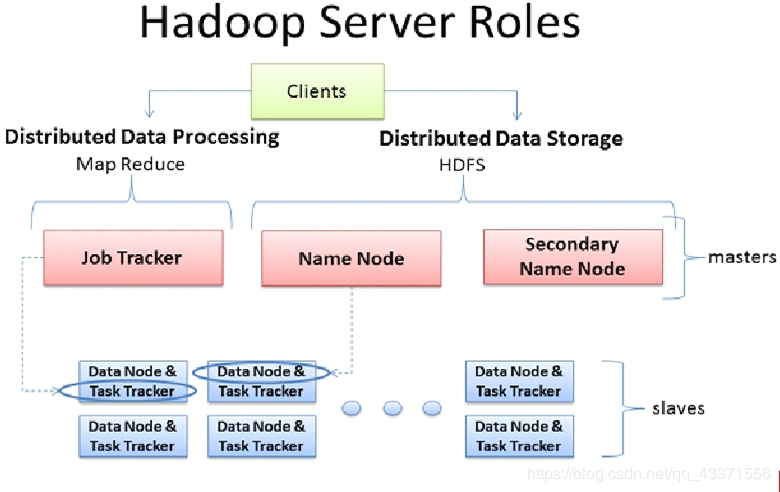
二 Hadoop 1.x-MapReduce
MRv1运行结构 (体现计算向数据移动)
架构图
- 客户端最核心的任务 : 算出切片清单 (因为切片清单可以很好的支持计算向数据移动)
- 将数据清单提交到HDFS , 因为运行在分布式/并行的环境, 需要将资源下载到本地 ,当做进程来跑
MRv1角色
- Client 作业为单位规划作业计算分布(计算切片,检查路径 ) 提交作业资源到HDFS 最终提交作业到JobTracker
- JobTracker 核心,主,单点 作业调度 监控整个集群的资源负载
- TaskTracker 从自身节点资源管理和JobTracker心跳 汇报资源 获取Task
弊端:
- JobTracker:负载过重,单点故障
- 资源管理与计算调度强耦合,其他计算框架需要重复实现资源管理
- 不同框架对资源不能全局管理
ps:
- 耦合: 度量一个软件系统各个模块之间互相连接的紧密程度。
- 内聚: 度量一个模块内各个元素彼此结合的紧密程度。
三 .Hadoop 2.x-MapReduce
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
Hadoop YARN
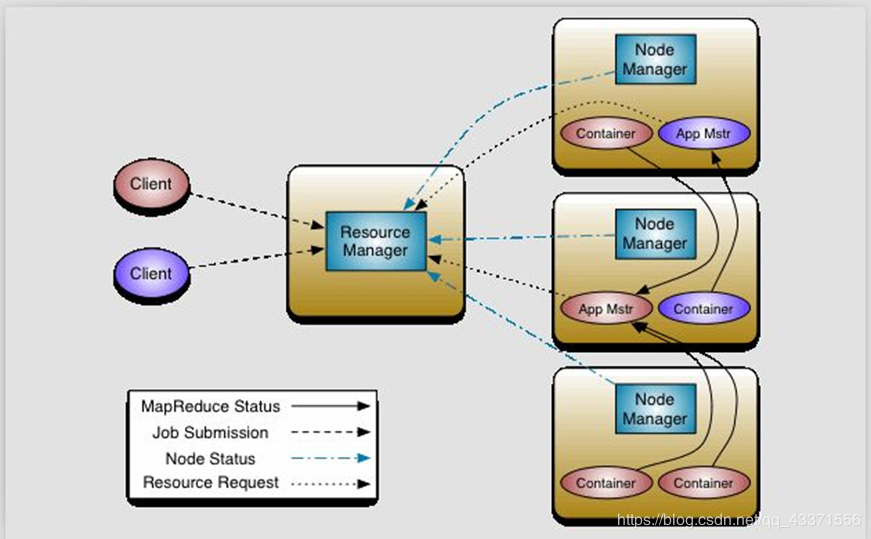
MRv2:On YARN
1.YARN:解耦资源与计算
- ResourceManager /RM 主,核心 集群节点资源管理
- NodeManager /NM 向RM汇报资源 管理Container生命周期 计算框架中的角色都以Container表示
- Container:【节点NM,CPU,MEM,I/O大小,启动命令】 默认NodeManager启动线程监控Container大小,超出申请资源额度,kill 支持Linux内核的Cgroup
2.MR :
- MR-ApplicationMaster-Container 作业为单位,避免单点故障,负载到不同的节点 创建Task需要和RM申请资源(Container)
- Task-Container
3. Client:
- RM-Client:请求资源创建AM
- AM-Client:与AM交互
YARN
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。 Hadoop 2.0新引入的资源管理系统,直接从MRv1演化而来的;
核心思想: 将MRv1中JobTracker的资源管理和任务调度两个功能分开,分别由ResourceManager和ApplicationMaster进程实现 ResourceManager: 负责整个集群的资源管理和调度 ApplicationMaster: 负责应用程序相关的事务,比如任务调度、任务监控和容错等 YARN的引入,使得多个计算框架可运行在一个集群中 ,每个应用程序对应一个ApplicationMaster 目前多个计算框架可以运行在YARN上,比如MapReduce、Spark、Storm等 YARN官方文档
MapReduce On YARN
MapReduce On YARN:MRv2
将MapReduce作业直接运行在YARN上,而不是由JobTracker和TaskTracker构建的MRv1系统中
- 基本功能模块 YARN:负责资源管理和调度 MRAppMaster:负责任务切分、任务调度、任务监控和容错等 MapTask/ReduceTask:任务驱动引擎,与MRv1一致
- 每个MapRduce作业对应一个MRAppMaster MRAppMaster任务调度 YARN将资源分配给MRAppMaster MRAppMaster进一步将资源分配给内部的任务
- MRAppMaster容错 失败后,由YARN重新启动 任务失败后,MRAppMaster重新申请资源
第三章 Hadoop MapReduce V2
一 环境搭建
前提 : 基于HDFS HA QJM,点击查看搭建过程

详细步骤
四个节点node1,2,3,4分别对应不同的虚拟机 node1最重要, 用于管理集群节点
# 0. node1启动上次配置好的zk,hdfs服务 zkServer.sh start #zk连接需要关闭防火墙 start-dfs.sh # 永久关闭防火墙 chkconfig iptables off1. 修改配置文件 (在hadoop的/etc/hadoop/目录下修改mapred-site.xml ,以及 yarn-site.xml )
本来是不需要在node1配置, 但是由于node1用于管理脚本 ,及时不使用这些配置也应该在node1.
[root@node1 ~]# cd /opt/chy/hadoop/etc/hadoop/
[root@node1 hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@node1 hadoop]# vim mapred-site.xml
-------------------------------------------------- mapred-site.xml-----------------------------------------------------------------
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
-------------------------------------------------- mapred-site.xml-----------------------------------------------------------------[root@node1 hadoop]# vim yarn-site.xml
-------------------------------------------------- yarn-site.xml -----------------------------------------------------------------
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node3</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node4</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node2:2181,node3:2181,node4:2181</value>
</property>
-------------------------------------------------- yarn-site.xml -----------------------------------------------------------------2.分发到其他节点
[root@node1 hadoop]# scp mapred-site.xml yarn-site.xml node2:
pwd
mapred-site.xml 100% 856 0.8KB/s 00:00
yarn-site.xml 100% 1372 1.3KB/s 00:00
[root@node1 hadoop]# scp mapred-site.xml yarn-site.xml node3:pwd
mapred-site.xml 100% 856 0.8KB/s 00:00
yarn-site.xml 100% 1372 1.3KB/s 00:00
[root@node1 hadoop]# scp mapred-site.xml yarn-site.xml node4:pwd
mapred-site.xml 100% 856 0.8KB/s 00:00
yarn-site.xml 100% 1372 1.3KB/s 00:003. 根据上图要求在node3,node4中启动资源管理器,并通过jps查看是否启动成功
yarn-daemon.sh start resourcemanager
[root@node3/4 ~]# jps
2285 ResourceManager4. 浏览器访问这两个资源管理器(图1)
http://node3:8088/
http://node4:8088/5. 利用hadoop下的MapReduce实例jar,进行简单操作(计算文本所占大小)
进入相关jar所在目录
cd /opt/chy/hadoop/share/hadoop/mapreduce/
执行wordcount 命令
hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /user/root/test-h.txt /data/wc/output
获取dhfs下的结果文件夹
hdfs dfs -get /data/wc/output
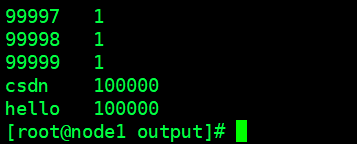
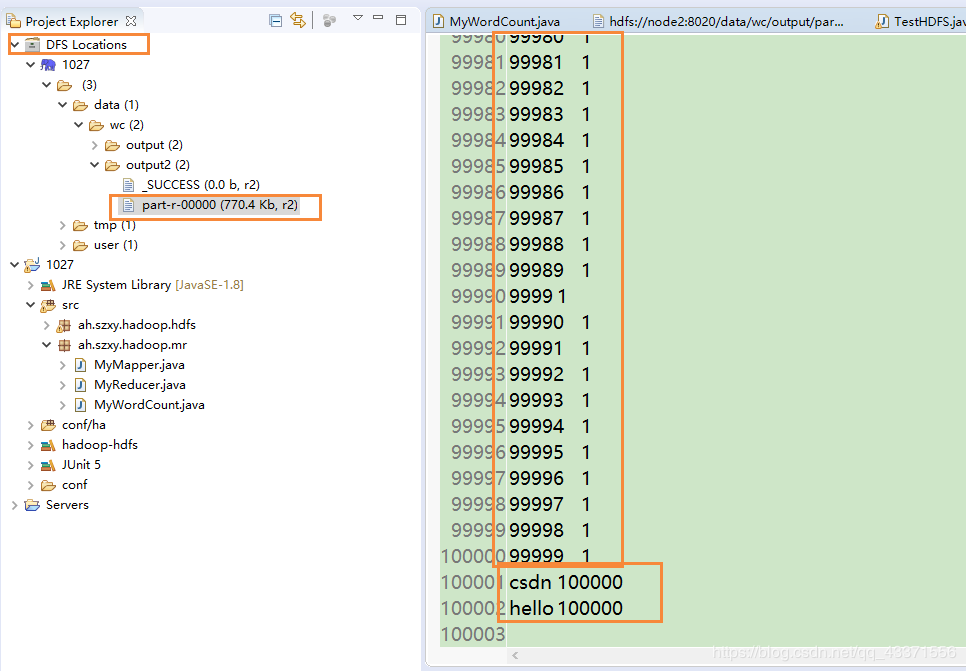
查看(图3, 可以看到出现的每个单词/数字都被统计了)
cat output/cat part-r-00000
图1
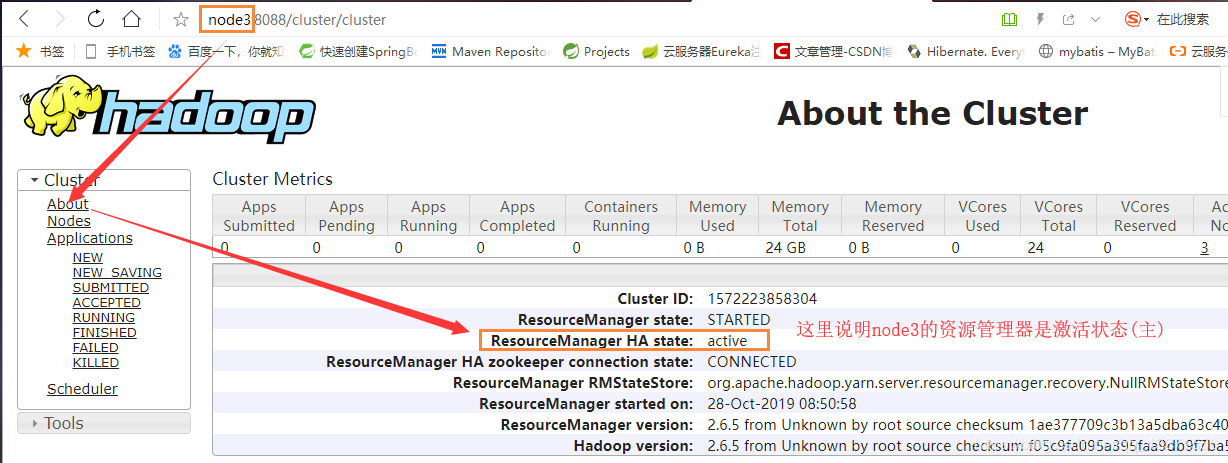
图2
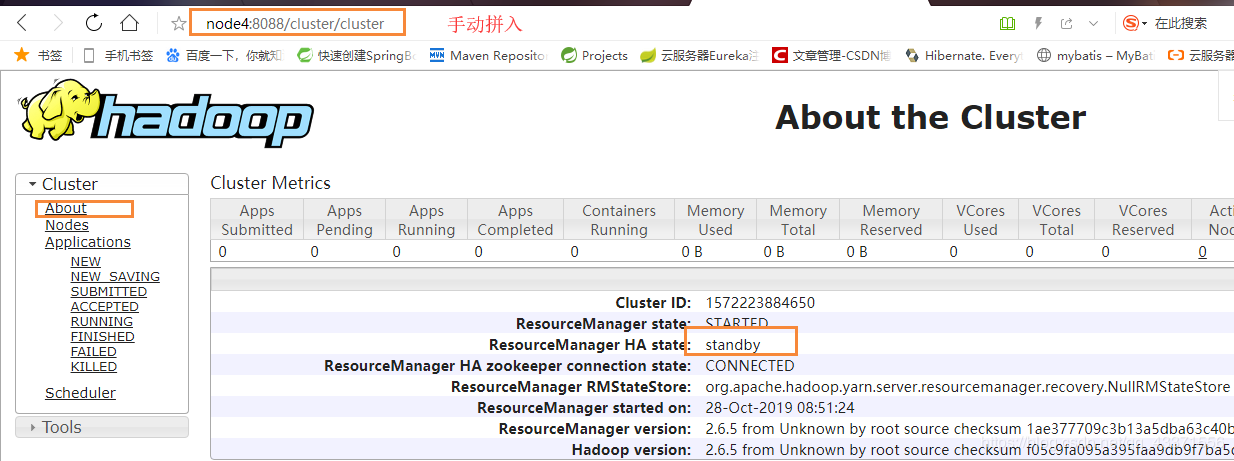
图3
启动顺序与初始化流程
# 至此所有环境部署完毕 # 以后启动顺序 ##启动zk , ##启动hdfs , ##启动resourcemanager yarn-daemon.sh start resourcemanager ##启动datanode start-yarn.sh重新搭建环境顺序
启动hdfs ,
格式化hdfs.
删除/var/chy/hadoop/ha目录要进行初始化, 首先应该启动JN(node1,node2,node3)
hadoop-daemon.sh start journalnode
node1
hdfs namenode -format
node1启动namenode(主)
hadoop-daemon.sh start namenode
node2启动备用namenode
hdfs namenode -bootstrapStandby
node1格式化ZK
hdfs zkfc -formatZK
启动HDFS服务
start-dfs.sh
访问主NN和备NN的图形化界面
http://node1:50070/
http://node2:50070/启动RM
#启动resourcemanager
yarn-daemon.sh start resourcemanagerhdfs创建目录
hdfs dfs -mkdir -p /user/root
#dhfs 上传
hdfs dfs -put testhadoop.txt /user/root
cd /opt/chy/hadoop/share/hadoop/mapreduce/
hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /user/root/testhadoop.txt .txt /data/wc/output
二 第一个MapReduce程序——计算文件中单词数量
MyWordCount
可以根据提示写代码, 列如Job job = Job.getInstance();,可以点击Job查看案例代码来书写
package ah.szxy.hadoop.mr;import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;/**
- 我的第一个MapReduce程序-计算单词数量
- @author chy
*/
public class MyWordCount {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//读取配置文件
Configuration c=new Configuration(true);// 创建job对象 Job job = Job.getInstance(); job.setJarByClass(MyWordCount.class); // 设置job的name job.setJobName("myjob"); //设置输入路径 Path input =new Path("/user/root/testhadoop.txt"); FileInputFormat.addInputPath(job, input); // 设置输出路径 Path output=new Path("/data/wc/output2"); // 判断是否存在,存在则删除 if( output.getFileSystem(c).exists(output)) { output.getFileSystem(c).delete(output, true); } //导包: org.apache.hadoop.mapreduce.lib FileOutputFormat.setOutputPath(job, output); job.setMapperClass(MyMapper.class); //序列化 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setReducerClass(MyReducer.class); // Submit the job, then poll for progress until the job is complete job.waitForCompletion(true); }
}
MyMapper
package ah.szxy.hadoop.mr;import java.io.IOException;
import java.util.StringTokenizer;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;public class MyMapper extends Mapper<Object, Text, Text, IntWritable>{
//对int类型数据进行包装 ,以支持序列化和反序列化
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();/** * key: 偏移量 */ public void map(Object key, Text value, Context context) throws IOException, InterruptedException { // 被读取的文本 hello csdn 1-10 0000 ,StringTokenizer:切割字符 StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } }
}
MyReducer
/**
- Reducer
- Text, IntWritable: Map方法计算的文本 ,以及数量的初步统计
- Text, IntWritable: 输出类型,文本,单词出现的次数
- @author chy
*/
public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {private IntWritable result = new IntWritable(); /** * Reduce原语 :相同的key为一组,调用一次reduce方法,方法内迭代这一组数据, 进行计算(sum count max min) */ public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); }
}
打包,运行,测试
- 文件的生成
文件的生成(内容 hello csdn1-100000 ) for i in
seq 100000;do echo "hello csdn $i" >> testhadoop.txt;done # 文件的上传(到hdfs) hdfs dfs -mkdir -p /user/root hdfs dfs -put testhadoop.txt /user/root - 右击三个java程序所在包目录, 选择export 导成jar (图1,图2)
- 上传到虚拟机中 ,运行 # hadoop jar jar程序名 jar主程序的全限定路径 hadoop jar MyWordCount.jar ah.szxy.hadoop.mr.MyWordCount
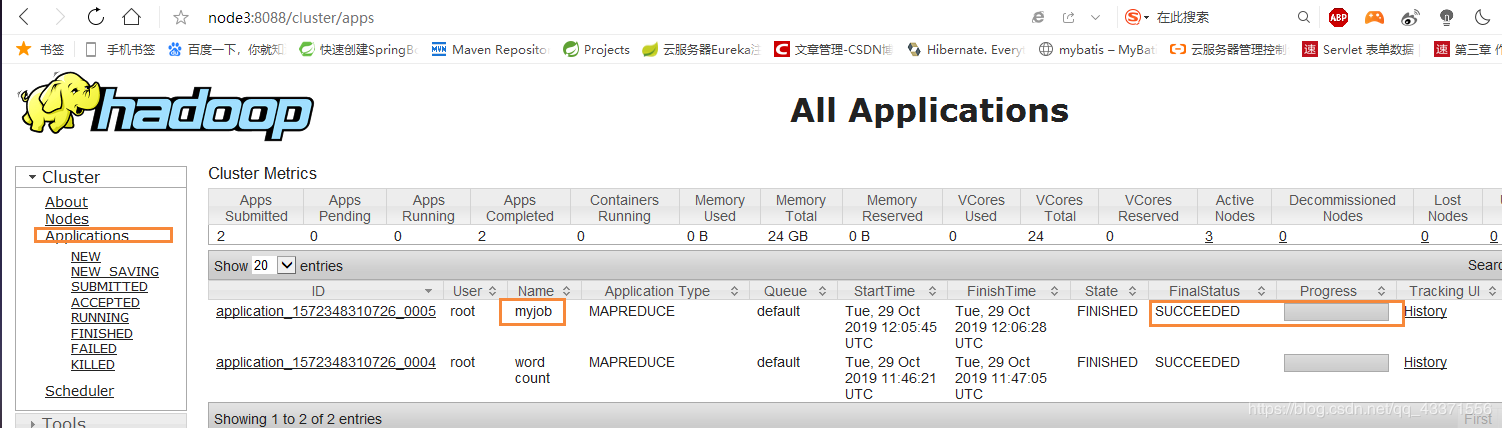
- 运行的时候可以访问resourcemanager的图形化界面
http://node3:8088,查看MapReduce程序执行状况 ( 图3 ) - 通过虚拟机相关指令查看,通过eclipse中的DFS Locations插件查看 ( 图5 ) 可以看到所有数字都出现一次,hello和csdn都出现了10 0000次
图1

图2
图3
三 源码分析
源码分析目的
- 了解框架工作大致流程
- 了解相关知识点及步骤
客户端
- 框架 / 输入格式化类默认实现类 TextInputFormat.class(文本输入格式化类)
- 切片包含的参数 : 所属文件 ,偏移量 ,大小 ,块的位置信息
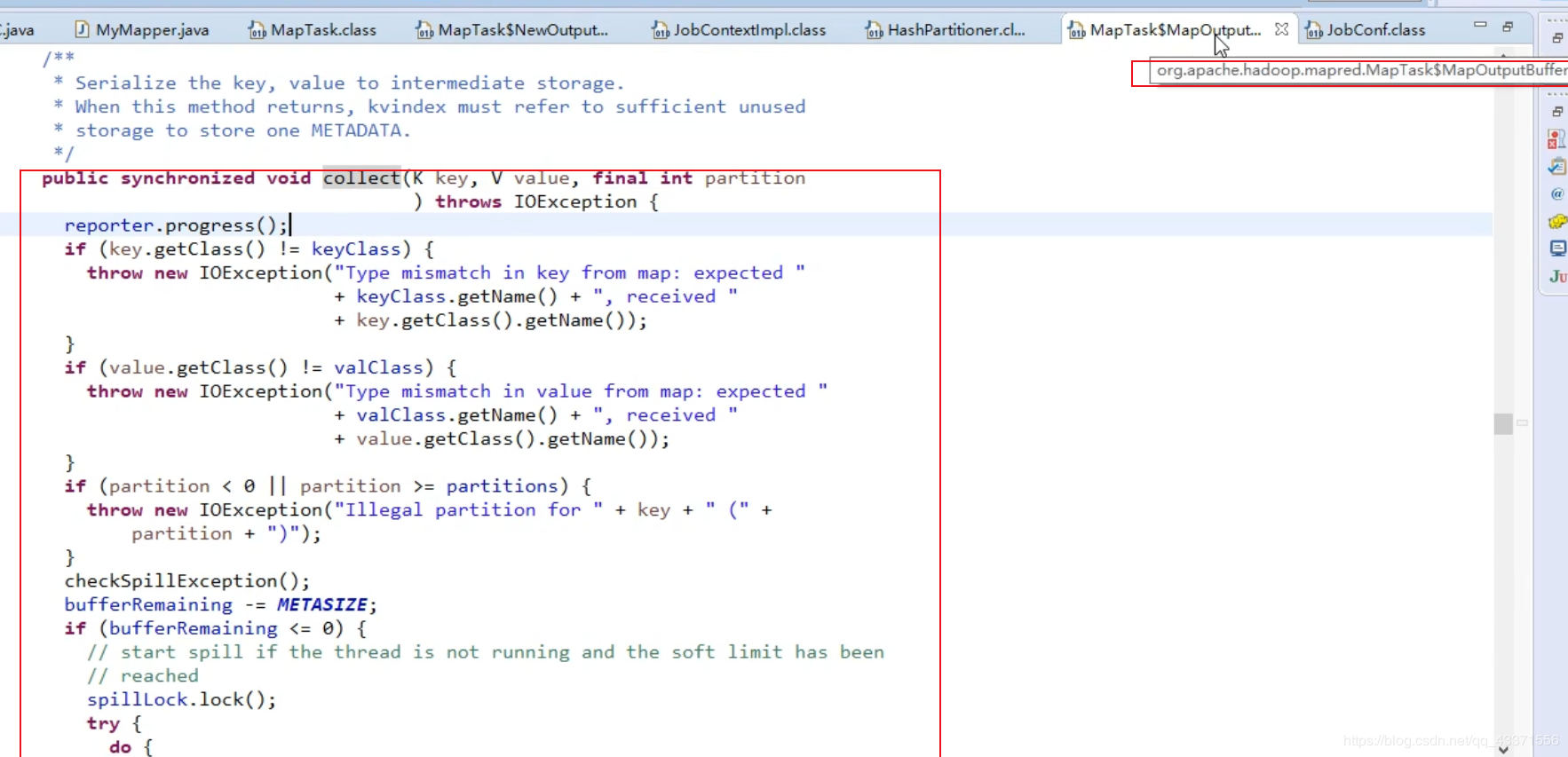
MapTask
1.MapInput
- NewTrackingRecordReader调用的是LineRecordReader, 进行初始化, 读写和判断
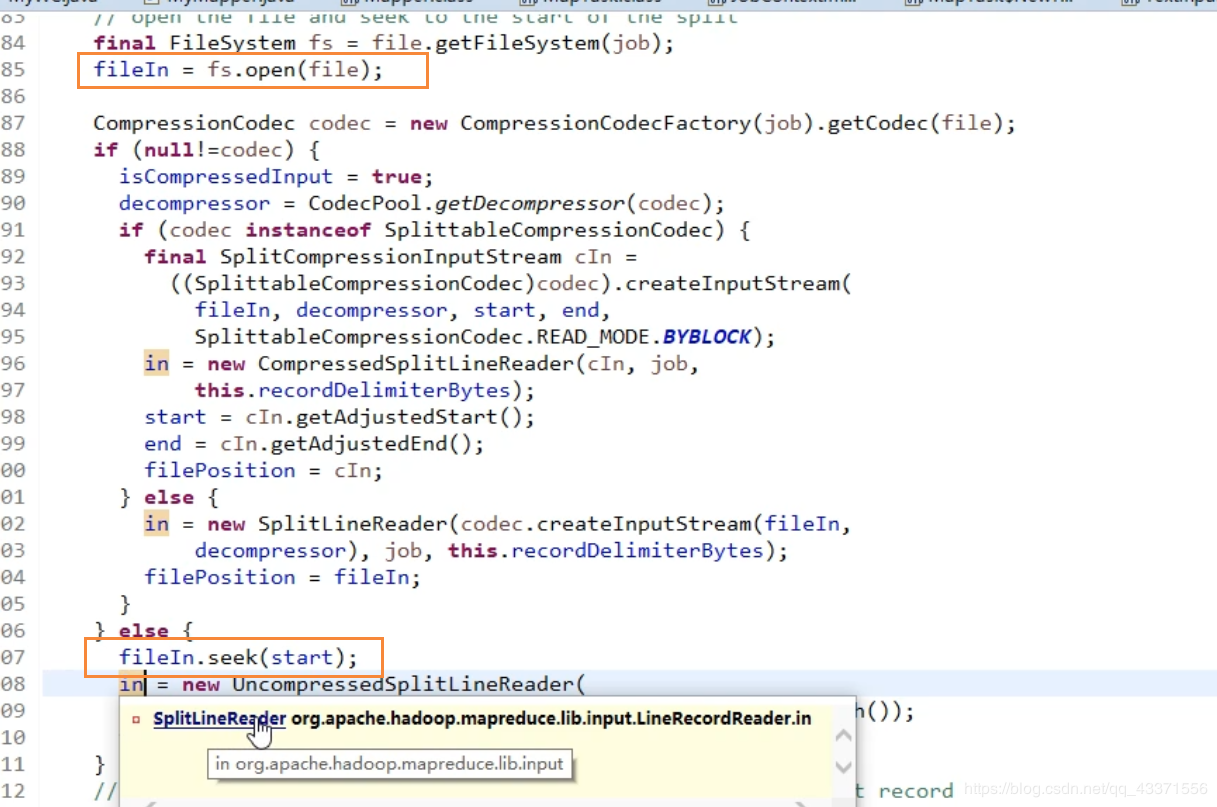
- 如下图所示 .源码中调用了hdfs的api 中的open()方法(调用IO流的读写操作) ,打开这个文件 ,作为输入流读取到文件系统中 ,同时每个节点会调用seek()方法 ,跳到自己需要读取的地方(所属分片)
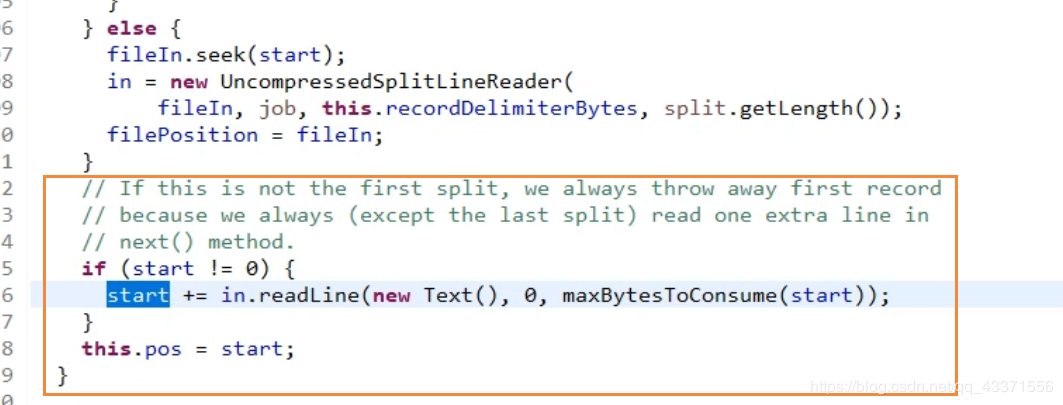
- 紧接上文 . 在读取每个切片时, 除了第一个切片 ,他们都会向下多读一行. 也就是说每个切片不只去取自己的切片, 还会读取下一个切片的第一行 . 因为在hdfs文件上传时 , 切片是按照字节去切 , 而不是按照单词去切 , 为了不破坏切片的完整性 ,每个切片在初始化时都会将偏移量下移一行
- 理想: 一个切片->一个块->一个map计算程序
- 现实: 一个map计算程序计算所属块自己的数据和下一个块起始行数据( 数据完整性考虑 )
- 注意 : 每个map程序计算的所属块肯定能够达到本地化, 但是被上一块所对应的map计算程序读取的那一行就不一定了 , 如果下一个块的第一行刚好在同一节点有一个副本, 那么就可以本地读 ; 如果本地没有第二个块的副本, 就会通过网络读取这个数据 ,但是拉取的是一个小量的数据, 不会占用过大的IO进行读写, 因此不会过多影响系统性能
- 一个map程序运行后 在输入的初始化时->准备输入流 (open) ->将偏移量seek到自己切片的位置(map流读自己切片的位置, 但是会调整块的偏移量, 向下读一行(new Text()匿名方法,不会处理,只会读一下,算字节数, 为的就是能够就自己的偏移量向下移动一行) 原因: 用来规避hdfs切割块时按字节切分导致两个块数据不完整的情况 ,导致Reduce方法读取到错误的数据
总结 读hdfs ->输入(run 方法拉取)-> 初始化(open.seek方法)-> key和value的赋值 输入(白话): 从hdfs拿流, 拿偏移量的位置 ,凑成一行然后输出
2.MapOutput

输出环节 :
- 用于输出的容器(MapOutPutCollector ) 在初始化时. 准备内存缓冲区(100MB大小,环形)->准备排序器->准备比较器->准备combiner(压缩数据) ->溢写线程
- 工作环节( 如下图 ),调用collect方法
总结 :
- 在map的输入阶段 :通过open方法调用IO流打开文件, 并行分步处理 ,每个切片调用seek, 为键值赋值并进行排序和比较 在map的输出阶段, 输出的是k-v-p(键-值-分区), 输出到环形缓冲区(默认100MB ,溢写阈值80%,达到后会溢写到磁盘,
- 在写之前会拿内存中的数据执行快速排序,这是整个框架的一次乱序到有序). 生成的小文件根据p分区,再根据key排序 ,所有小文件再进行归并排序
- 如果做了combiner ,在上一步时会判定小文件的数量, 大于默认值3, 触发combiner压缩数据 ,减小网络IO , 其核心目的让Reduce处理的更快 ,框架跑的更快(优化阶段)
大数据瓶颈->IO shuffle :磁盘IO,网络IO ,所有事情都必须考虑IO
ReduceTask
map比较器 : 排序(大于等于小于) reduce比较器 : 分组:(是, 不是)
- reduce方法迭代原理 : mapreduce 框架将从map输出的数据通过shuffle 机制拉取到reduce 方法的容器中, 而这个容器中会有海量的数据, reduce 方法中的迭代器能够取出这些数据, 在取的时候会有一个假的迭代器nextkeyissame 判定迭代是否结束( 下一组键值是否与本组键值相等,不一样则结束 ) , 结束后调用这个迭代器继续迭代下一组数据. 这样可以令reduce方法以组为单位来使用迭代器.

再次回顾: 面试问如何理解shuffle?(在MapReduce环境下) 1.shuffle就是在reduce启动后 ,在map中拉回属于自己的数据的过程(动作角度) 2.如果面试官说不对,就说是从map输出完数据之后, 算出属于的分区号 /reduce开始 ,一直到拉取并计算数据这一整个过程(逻辑角度) shuffle :动作 :拷贝 ; 逻辑: 数据规划,整理,拉取
第四章 Hadoop-MapReduce案例
一 MapReduce案例-天气
需求与编码
需求 : 找出每个月温度最高的两天
文本内容
1949-10-01 14:21:02 34c
1949-10-01 19:21:02 38c
1949-10-02 14:01:02 36c
1950-01-01 11:21:02 32c
1950-10-01 12:21:02 37c
1951-12-01 12:21:02 23c
1950-10-02 12:21:02 41c
1950-10-03 12:21:02 27c
1951-07-01 12:21:02 45c
1951-07-02 12:21:02 46c
1951-07-03 12:21:03 47c思路:
每年 每个月 最高 2天 1天多条记录进一步思考
年月分组
温度升序
key中要包含时间和温度呀!
MR原语:相同的key分到一组
通过GroupCompartor设置分组规则自定义数据类型Weather
包含时间
包含温度
自定义排序比较规则
自定义分组比较
年月相同被视为相同的key
那么reduce迭代时,相同年月的记录有可能是同一天的
reduce中需要判断是否同一天
注意OOM
数据量很大
全量数据可以切分成最少按一个月份的数据量进行判断
这种业务场景可以设置多个reduce
通过实现partition
代码实现:
1.客户端
思路(其他类都是在此基础上创建):
//1. 读取配置文件,获取任务实例,设置任务的jar名称
//2. 指定map类, 设置map输出key的类 ,设置map输出值的类
//3. 分区设置 : 指定分区类. 设置排序比较器类
//4. 设置分组比较器类
//5. 指定reduce类
//6.设置文件输入路径 ,需要自己添加(重点)
//7.设置文件输出路径 ,需要自己设置判断是否存在(重点)
//8.设置Reduce数量
//9.等待任务完成
import java.io.IOException;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class MyTQ {
public static void main(String[] args) throws Exception {
//1. 读取配置文件,获取任务实例,设置任务的jar名称
Configuration conf=new Configuration(true);
Job job = Job.getInstance(conf);
job.setJarByClass(MyTQ.class);//-----------------------map环节--------------------------------- //2. 指定map类, 设置map输出key的类 ,设置map输出值的类 job.setMapperClass(TqMapper.class); job.setOutputKeyClass(TqOutputKey.class); job.setOutputValueClass(IntWritable.class); //3. 分区设置 : 指定分区类. 设置排序比较器类 job.setPartitionerClass(TqPartitioner.class); job.setSortComparatorClass(TqSortComparator.class); //-------------------------------------------------------- //-----------------------reduce环节--------------------------------- //4. 设置分组比较器类 job.setGroupingComparatorClass(TqGroupCompartor.class); //5. 指定reduce类 job.setReducerClass(TqReduce.class); //-------------------------------------------------------- //6.设置文件输入路径(重点) Path path=new Path("/data/tq/input"); FileInputFormat.addInputPath(job, path); //7.设置文件输出路径,判断是否存在(重点) Path output=new Path("/data/tq/output"); if (output.getFileSystem(conf).exists(output)) { output.getFileSystem(conf).delete(output, true);//递归删除 } FileOutputFormat.setOutputPath(job, output); //8.设置Reduce数量 job.setNumReduceTasks(2); //9.等待任务完成 job.waitForCompletion(true); }
}
2.map类
import java.io.IOException;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Calendar;
import java.util.Date;import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;/**
- 指定的map方法类
- Mapper<LongWritable, Text, TqOutputKey, IntWritable>
- 输入格式化类的方法LineRecordReader类型就是LongWritable,值为Text(TextInputFormat)
- 输出类型和客户端定义的一致
- @author chy
*/
public class TqMapper extends Mapper<LongWritable, Text, TqOutputKey, IntWritable> {//1.创建map的key,value属性 TqOutputKey mkey=new TqOutputKey(); IntWritable mval=new IntWritable(); @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, TqOutputKey, IntWritable>.Context context) throws IOException, InterruptedException { //1949-10-01 14:21:02 34c //1949-10-01+空格+14:21:02+制表符+34c try { //2. 将数据通过 "/t"分割(strs[0]年月日时间 .strs[1]: 34c ) ,获取年月日 String[] strs=StringUtils.split(value.toString(),'\t'); SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd"); Date date=sdf.parse(strs[0]); //将日期传到Calendar中,我们可以通过Calendar.获取指定的年月日等信息 Calendar cal=Calendar.getInstance(); cal.setTime(date); //3.设置map的key,value属性 mkey.setYear(cal.get(Calendar.YEAR)); mkey.setMounth(cal.get(Calendar.MONTH)+1);//MONTH取值为0-11 mkey.setDay(cal.get(Calendar.DAY_OF_MONTH)); //从34c中获取34(去除字符c) int wd=Integer.parseInt(strs[1].substring(0,strs[1].length()-1));//substring, index从0开始,包前不包后 mkey.setWd(wd); mval.set(wd); //4.输出 context.write(mkey, mval); } catch (ParseException e) { e.printStackTrace(); } }
}
3.设置map输出时key的类型
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;import org.apache.hadoop.io.WritableComparable;
/**
- 设置map输出时key的类型
- 实现可写接口WritableComparable(类型:自身)
- 可以根据WritableComparable中的提示书写下面代码
- @author chy
*/
public class TqOutputKey implements WritableComparable<TqOutputKey>{//1.定义输入的key的属性值,实现取值赋值方法 private int year; private int mounth; private int day; private int wd; public int getYear() { return year; } public void setYear(int year) { this.year = year; } public int getMounth() { return mounth; } public void setMounth(int mounth) { this.mounth = mounth; } public int getDay() { return day; } public void setDay(int day) { this.day = day; } public int getWd() { return wd; } public void setWd(int wd) { this.wd = wd; } @Override public void write(DataOutput out) throws IOException { //2. 设置序列化的相关属性 out.writeInt(this.year); out.writeInt(this.mounth); out.writeInt(this.day); out.writeInt(this.wd); } @Override public void readFields(DataInput in) throws IOException { //3. 设置反序列化的相关属性 this.year = in.readInt(); this.mounth=in.readInt(); this.day=in.readInt(); this.wd=in.readInt(); } @Override public int compareTo(TqOutputKey that) { //4. 设置比较器 // 约定俗成 : 日期正序 int c1=Integer.compare(this.year, that.getYear());//compareTo : 通过ascll码进行比较,结果为他们的差值,0代表相等 if(c1==0) { int c2=Integer.compare(this.mounth, that.getMounth()); if (c2==0) { int c3=Integer.compare(this.day, that.getDay()); return c3; } return c2; } return c1; }
}
4.分区设置
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Partitioner;
/**
- 设置分区
- @author chy
*/
public class TqPartitioner extends Partitioner<TqOutputKey, IntWritable>{@Override public int getPartition(TqOutputKey key, IntWritable value, int numPartitions) { //数据倾斜解决逻辑 : //1. 数据抽样 ,分析倾斜程度 ,将少的数据组放到一个reduce任务,大的单独放入一个reduce任务 //2. 数据做路由 ,有的数据能够进入分区 ,作为一个数据集 .剩下的放入其他分区作为另一个数据集 //return key.hashCode() % numPartitions; //;逻辑上没有效果,但是必须要有这一步 return key.getYear() % numPartitions; //以年为单位进行分区 }
}
5.排序比较器类
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;/**
- 排序比较器类
- RawComparator ->WritableComparator
- WritableComparator是一个类 ,区别WritableComparable<TqOutputKey>,是一个接口
- @author chy
*/
public class TqSortComparator extends WritableComparator{
//1.重写排序比较器的构造方法
public TqSortComparator() {
super(TqOutputKey.class,true);//引用父类的构造器 .true: 创建实例
}//2. 重写比较方法 @Override public int compare(WritableComparable a, WritableComparable b) { TqOutputKey t1=(TqOutputKey) a; TqOutputKey t2=(TqOutputKey) b; //年月+温度(倒序) int c1=Integer.compare(t1.getYear(), t2.getYear()); if (c1==0) { int c2=Integer.compare(t1.getMounth(), t2.getMounth()); if (c2==0) { int c3= -Integer.compare(t1.getWd(), t2.getWd()); return c3; } return c2; } return c1; }
}
6.分组比较器类
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;/**
- 分组比较器
- 编写方式大致同排序比较器
- @author chy
*/
public class TqGroupCompartor extends WritableComparator{// 1.重写构造器 public TqGroupCompartor(){ super(TqOutputKey.class,true); } //2.重写比较方法 ,比排序比机器少一个维度 @Override public int compare(WritableComparable a, WritableComparable b) { TqOutputKey t1=(TqOutputKey) a; TqOutputKey t2=(TqOutputKey) b; //年月 int c1=Integer.compare(t1.getYear(), t2.getYear()); if (c1==0) { int c2=Integer.compare(t1.getMounth(), t2.getMounth()); return c2; } return c1; }
}
7.reduce类
import java.io.IOException;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;/**
- Reduce方法
- 继承Reducer
- @author chy
*/
public class TqReduce extends Reducer<TqOutputKey, IntWritable, Text, IntWritable>{//1.创建reduce的key,value属性 Text rkey=new Text(); IntWritable rval=new IntWritable(); //2.重写reduce方法 @Override protected void reduce(TqOutputKey key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException { //mr原语 : 相同的key为一组 ,调用一个reduce方法 ,方法内迭代这一组数据 //2019 11 01 20 20 //2019 11 11 11 11 //... int flag=0; int day=0; // 遍历数据 ,为reduce的key,value属性赋值,取温度最高的;两天 for (IntWritable v : values) { //温度第一高的 if (flag==0) { //key: 2019-11-11:11 value:11 rkey.set(key.getYear()+"-"+key.getMounth()+"-"+key.getDay()+":"+key.getWd()); rval.set(key.getWd()); flag++; day=key.getDay(); context.write(rkey, rval);//将键值输出 } //温度第二高的 if (flag!=0 && day!=key.getDay()) { //key: 2019-11-11:11 value:11 rkey.set(key.getYear()+"-"+key.getMounth()+"-"+key.getDay()+":"+key.getWd()); rval.set(key.getWd()); context.write(rkey, rval);//将键值输出 break; } } }
}
运行与测试
- 将该包下的代码打包成jar文件,上传到hdfs服务器中
- 在hdfs中创建输入文件所在目录 hdfs dfs -mkdir -p /data/tq/input
- 运行MapReduce程序 hadoop jar MyTQ.jar ah.szxy.hadoop.mr.tq.MyTQ
- 运行结束后将结果文件拉取到本地查看(或者通过eclipse中的DFS Loader插件查看) hdfs dfs -get /data/tq/output/* ./
- 查看排序结果
Bug记录
1. 在使用hadoop jar MyTQ.jar ah.szxy.hadoop.mr.tq.MyTQ 命令运行MapReduce程序时 ,发现程序卡住不动
原因是NodeManager没有在hdfs启动时被同时启动 ,通过图形化界面可以查看到
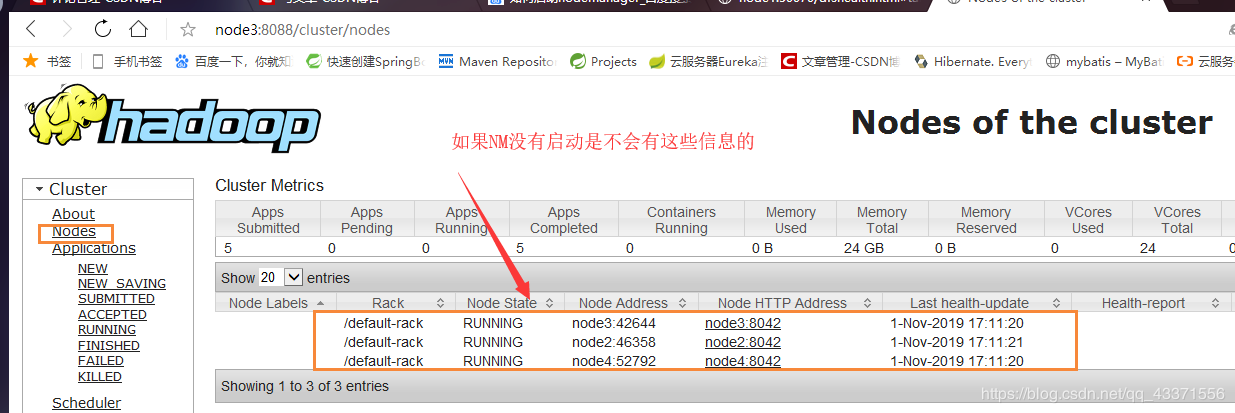
解决方案 : 在node1使用start-yarn.sh 启动所有 NM即可
2. 运行后 ,发现结果文件中 ,月份全部都减了1
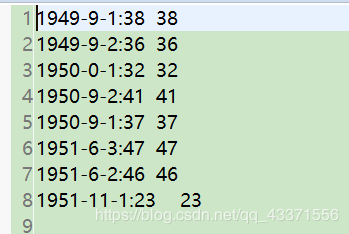
解决方案 :定位到map类中相关代码 .Calendar.MONTH的取值为0-11,所以应该在结果上+1
//3.设置map的key,value属性
mkey.setYear(cal.get(Calendar.YEAR));
//mkey.setMounth(cal.get(Calendar.MONTH));//MONTH的取值为0-11,所以应该在结果上+1
mkey.setMounth(cal.get(Calendar.MONTH)+1)
mkey.setDay(cal.get(Calendar.DAY_OF_MONTH));3. 我们可以看到下图的结果文件中 ,结果数据都存放在一个文件( 产生了数据倾斜 )
原因是在分区设置(代码块4)中的return key.hashCode() % numPartitions; //;逻辑上没有效果,但是必须要有这一步
map是在map方法分区外实现的(代码块2),所以输出的只有一个key ,因此上方代码的值时固定的,会导致结果只在一个分区输出
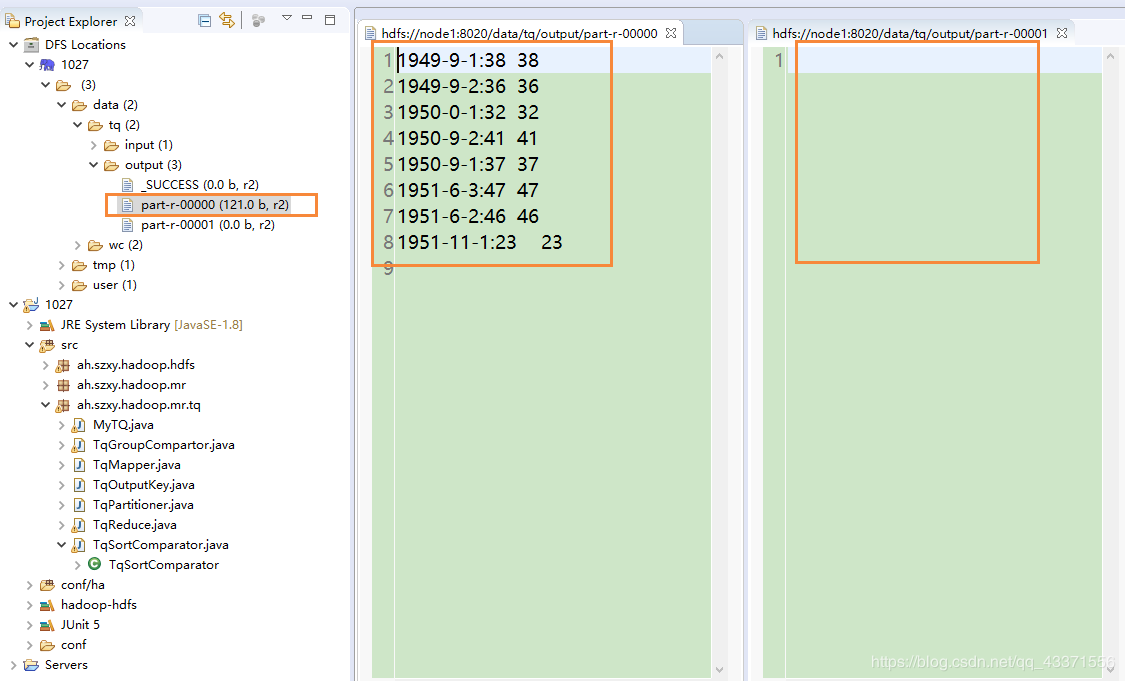
解决方法: return key.getYear() % numPartitions; //以年为单位进行分区
二 MapReduce案例-好友推荐
需求及编码
需求: 推荐好友的好友 共同好友越多 ,建立好友关系的成功率越高
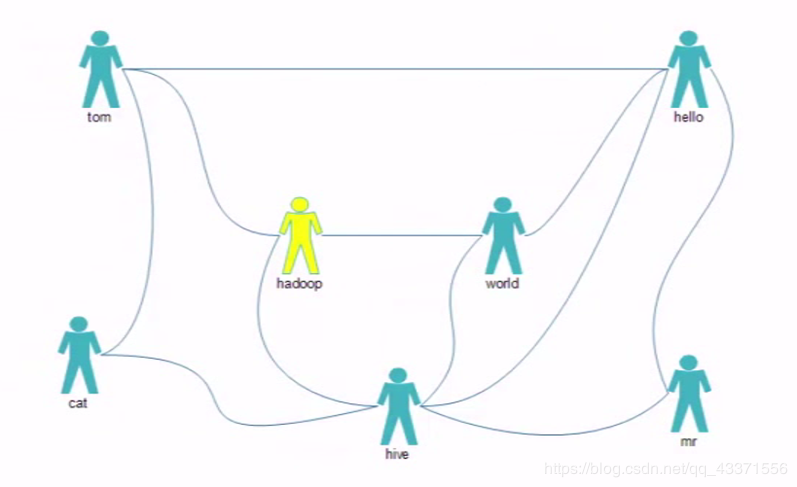
文本内容
tom hello hadoop cat
world hadoop hello hive
cat tom hive
mr hive hello
hive cat hadoop world hello mr
hadoop tom hive world
hello tom world hive mr思考:

思路: 推荐者与被推荐者一定有一个或多个相同的好友 全局去寻找好友列表中两两关系 去除直接好友 统计两两关系出现次数API:
map:按好友列表输出两两关系
reduce:sum两两关系
再设计一个MR
生成详细报表
reduce:来自于map
原语:“相同”的key为一组,调用一次reduce方法,方法内迭代这组数据
map端会做排序:sortcomparator
数据以多大的宽度为一组:groupingcomparator
bj,hd
bj,hd
sh,sj
bj,dx
!分组比较强依赖排序
reduce底层迭代原理:nextkeyissame
代码实现
1.客户端类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;/**
- 客户端类
- @author chy
*/
public class MyFoF {
public static void main(String[] args) throws Exception {
//1. 读取配置文件,获取任务实例,设置任务的jar名称
Configuration conf=new Configuration(true);Job job=Job.getInstance(conf); job.setJarByClass(MyFoF.class); //2. 指定map类, 设置map输出key的类 ,设置map输出值的类 job.setMapperClass(FofMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //3. 分区设置 : 指定分区类. 设置排序比较器类 //4. 设置分组比较器类 //5. 指定reduce类 job.setReducerClass(FofReduce.class); //6.设置文件输入路径(重点) Path path=new Path("/data/fof/input"); FileInputFormat.addInputPath(job, path);//org.apache.hadoop.mapreduce.lib //7.设置文件输出路径,判断是否存在(重点) Path outputDir=new Path("/data/fof/output"); if (outputDir.getFileSystem(conf).exists(outputDir)) { outputDir.getFileSystem(conf).delete(outputDir, true); } FileOutputFormat.setOutputPath(job, outputDir); //8.设置Reduce数量 //9.等待任务完成 job.waitForCompletion(true); }
}
2.map类
import java.io.IOException;import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;/**
- map类
- 继承Mapper接口<LongWritable, Text, Text, IntWritable>
- @author chy
*/
public class FofMapper extends Mapper<LongWritable, Text, Text, IntWritable>{//0.创建map的key与value Text mkey=new Text(); IntWritable mval=new IntWritable(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //tom hello hadoop cat //1.分割字符串 String[] strs=StringUtils.split(value.toString(),' ' ); //2.遍历设置key,value for (int i = 1; i < strs.length; i++) { //strs[0]+strs[i] :将每一行第一个字符串与第i(>1)个字符串组合,并且按照ascll码从小到大排序 mkey.set(getFof(strs[0], strs[1]) ); mval.set(0); //循环输出 context.write(mkey, mval); //外层循环拼接: 直接关系, 内层循环拼接: 间接关系 for (int j = i+1; j < strs.length; j++) { mkey.set(getFof(strs[i], strs[j]) ); mval.set(1);//1代表间接关系 context.write(mkey, mval); } } } //作用: 按照ascll码从小到大排序 //保证读取数据时,永远是一个顺序(防止a:b 与b:a 同时出现) public static String getFof(String s1, String s2) { if (s1.compareTo(s2)<0) { return s1+":"+s2; } return s2+":"+s1; }
}
3,reduce类
import java.io.IOException;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;/**
- reduce类
- 继承Reducer<Text, IntWritable, Text, IntWritable>
- @author chy
*/
public class FofReduce extends Reducer<Text, IntWritable, Text, IntWritable>{//hello:hadoop 0 //hello:hadoop 1 //hello:hadoop 0 //1. 设置reduce的value, key可以复用 IntWritable rval=new IntWritable(); //2.重写reduce方法 @Override protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException { // 迭代求和 ,输出真正存在间接关系的数据 int flag=0; int sum=0; for (IntWritable v : values) { if (v.get()==0) { flag=1; } sum+=v.get(); } if (flag==0) { rval.set(sum); context.write(key, rval); } }
}
运行与测试
- 将该包下的代码打包成jar文件,上传到hdfs服务器中
- 在hdfs中创建输入文件所在目录 hdfs dfs -mkdir -p /data/fof/input
- 运行MapReduce程序 hadoop jar MyFoF.jar ah.szxy.hadoop.mr.fof.MyFoF
- 运行结束后将结果文件拉取到本地查看(或者通过eclipse中的DFS Locations插件查看) hdfs dfs -get /data/fof/output/* ./
- 查看排序结果

三 MapReduce案例-PageRank
要求尽量掌握思维以及编码, 最大限度的将这些知识融入到自己的知识体系中
PageRank算法介绍
1.什么是pagerank
PageRank是Google提出的算法,用于衡量特定网页相对于搜索引擎索引中的其他网页而言的重要程度。 是Google创始人拉里·佩奇和谢尔盖·布林于1997年创造的 PageRank实现了将链接价值概念作为排名因素。
2.计算环境
沿用之前的环境: Hadoop-2.6.5 四台主机node1,2,3,4 两台NN的HA 两台RM的HA 离线计算框架MapReduce
3.PageRank算法原理
- 思考超链接在互联网中的作用? 连接多个静态网页
- 入链 ==投票 PageRank让链接来“投票“,到一个页面的超链接相当于对该页投一票。
- 入链数量 ;如果一个页面节点接收到的其他网页指向的入链数量越多,那么这个页面越重要。
- 入链质量 : 指向页面A的入链质量不同,质量高的页面会通过链接向其他页面传递更多的权重。所以越是质量高的页面指向页面A,则页面A越重要。
- 初始值 Google的每个页面设置相同的PR值 ,pagerank算法给每个页面的PR初始值为1。
- 迭代计算(收敛) Google不断的重复计算每个页面的PageRank。那么经过不断的重复计算,这些页面的PR值会趋向于稳定,也就是收敛的状态。
- 在具体企业应用中怎么样确定收敛标准? 1、每个页面的PR值和上一次计算的PR相等 2、设定一个差值指标(0.0001)。当所有页面和上一次计算的PR差值平均小于该标准时,则收敛。 3、设定一个百分比(99%),当99%的页面和上一次计算的PR相等
- 站在互联网的角度: 只出,不入:PR会为0 只入,不出:PR会很高 直接访问网页
- 修正PageRank计算公式:增加阻尼系数 在简单公式的基础上增加了阻尼系数(damping factor)d 一般取值d=0.85。
- 完整PageRank计算公式
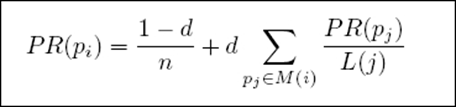
d:阻尼系数 M(i):指向i的页面集合 L(j):页面的出链数 PR(pj):j页面的PR值 n:所有页面数
4,pageRank计算/PR值的计算
- 站在A的角度: 需要将自己的PR值分给B,D
- 站在B的角度: 收到来自A,C,D的PR值
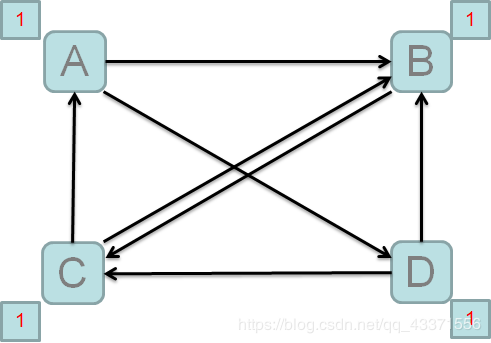
- PR需要迭代计算
- 其PR值会趋于稳定
- PR值计算 : 每个节点页面访问当前节点数(入链数)占该节点总访问数比之和
- 每个节点页面初始PR值为1
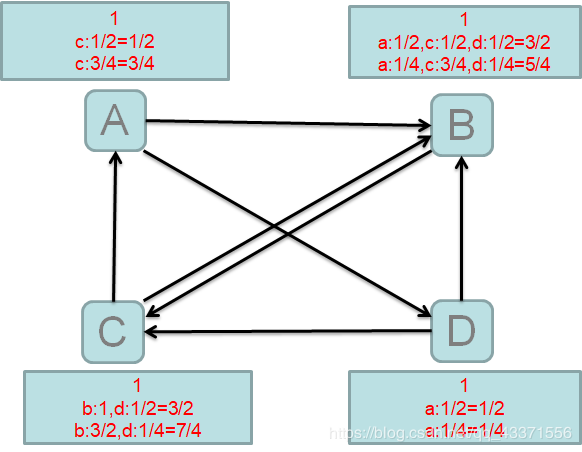
pr值的计算
第一次
访问统计 | pr值 |
|---|---|
A: 收到C的访问 1/2 | 1/2 |
B: 收到A,C,D的访问 A:1/2 C:1/2 D:1/2 | 3/2 |
C: 收到B,D的访问 B:1 D:1/2 | 3/2 |
D : 收到A的访问 1/2 | 1/2 |
第二次( 利用访问统计值与第一次pr值相乘 )
访问统计 | pr值 |
|---|---|
A: 收到C的访问 1/2 | 1/2x3/2=3/4 |
B: 收到A,C,D的访问 A:1/2 C:1/2 D:1/2 | 1/2x1/2+1/2x3/2+1/21/2=4/5 |
C: 收到B,D的访问 B:1 D:1/2 | 3/2+1/2x1/2=7/4 |
D : 收到A的访问 1/2 | 1/2x1/2=1/4 |
往复如此,我们可以看到访问量高的(B)不一定pr值也高 ,在筛选出一定访问量的同时也对质量作出筛选 这样得出来的pr值高的网页( C )既保证了数量有保证了质量
需求与实现(Windows环境下运行)
上面案例都是打成jar ,然后在虚拟机上通过 hadoop jar 命令运行
- 需求 : 根据PageRank算法对网页进行排序
- 思路 MR原语不被破坏 PR计算是一个迭代的过程,首先考虑一次计算
- 思考: 页面包含超链接 每次迭代将pr值除以链接数后得到的值传递给所链接的页面 so:每次迭代都要包含页面链接关系和该页面的pr值 mr:相同的key为一组的特征 map: 1 读懂数据:第一次附加初始pr值 2 映射k:v 传递页面链接关系,key为该页面,value为页面链接关系 计算链接的pr值,key为所链接的页面,value为pr值 reduce: 1.按页面分组 2.两类value分别处理 3.最终合并为一条数据输出:key为页面新的pr值,value为链接关系
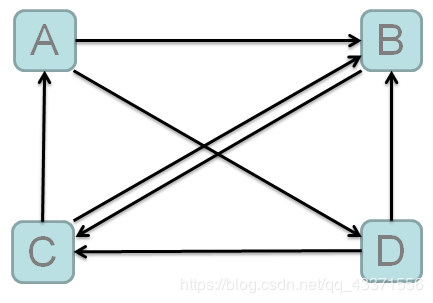
内容数据 xx.txt(名称随意)
A B D
B C
C A B
D B C关系图
代码实现
1.客户端类.map类,reduce类
/** * 客户端类 * */ public class RunJob {public static enum Mycounter { my } public static void main(String[] args) { Configuration conf = new Configuration(true); conf.set("mapreduce.app-submission.corss-paltform", "true");//开启Windows系统对客户端程序支持 //如果分布式运行,必须打jar包 //且,client在集群外非hadoop jar 这种方式启动,client中必须配置jar的位置 conf.set("mapreduce.framework.name", "local"); //这个配置,只属于,切换分布式到本地单进程模拟运行的配置 //这种方式不是分布式,所以不用打jar包 double d = 0.001;//如果想要增加精度.可以将小数点后移,增加运算次数 int i = 0; while (true) {//pr迭代运算 i++; try { conf.setInt("runCount", i); FileSystem fs = FileSystem.get(conf); Job job = Job.getInstance(conf); job.setJarByClass(RunJob.class); job.setJobName("pr" + i); job.setMapperClass(PageRankMapper.class); job.setReducerClass(PageRankReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); //使用了新的输入格式化类 : 会使用制表符去切数据.制表符前面是key,后面是value job.setInputFormatClass(KeyValueTextInputFormat.class); Path inputPath = new Path("/data/pagerank/input/"); if (i > 1) { inputPath = new Path("/data/pagerank/output/pr" + (i - 1)); } FileInputFormat.addInputPath(job, inputPath); Path outpath = new Path("/data/pagerank/output/pr" + i); if (fs.exists(outpath)) { fs.delete(outpath, true); } FileOutputFormat.setOutputPath(job, outpath); boolean f = job.waitForCompletion(true); if (f) { System.out.println("success."); long sum = job.getCounters().findCounter(Mycounter.my).getValue(); System.out.println(sum); //过程中将页面的差值放大到1000倍,四个页面,所以要在这里除以4000 double avgd = sum / 4000.0; //如果平均值小于0.0000001,跳出迭代 if (avgd < d) { break; } } } catch (Exception e) { e.printStackTrace(); } } } /** * map类 * */ static class PageRankMapper extends Mapper<Text, Text, Text, Text> { protected void map(Text key, Text value, Context context) throws IOException, InterruptedException { int runCount = context.getConfiguration().getInt("runCount", 1); //A B D //A B D 0.3 //K:A //V:B D //K:A //V:0.3 B D String page = key.toString(); Node node = null; if (runCount == 1) {//V:B D node = Node.fromMR("1.0" , value.toString()); } else {//V:0.3 B D node = Node.fromMR(value.toString()); } // A 1.0 B D 传递老的pr值和对应的页面关系 context.write(new Text(page), new Text(node.toString())); if (node.containsAdjacentNodes()) { double outValue = node.getPageRank() / node.getAdjacentNodeNames().length; for (int i = 0; i < node.getAdjacentNodeNames().length; i++) { String outPage = node.getAdjacentNodeNames()[i]; // B:0.5 // D:0.5 页面A投给谁,谁作为key,val是票面值,票面值为:A的pr值除以超链接数量 context.write(new Text(outPage), new Text(outValue + "")); } } } } /** * Reduce类 * */ static class PageRankReducer extends Reducer<Text, Text, Text, Text> { protected void reduce(Text key, Iterable<Text> iterable, Context context) throws IOException, InterruptedException { //相同的key为一组 //key:页面名称比如B //包含两类数据 //B:1.0 C //页面对应关系及老的pr值 //B:0.5 //投票值 //B:0.5 double sum = 0.0; Node sourceNode = null; for (Text i : iterable) { Node node = Node.fromMR(i.toString()); if (node.containsAdjacentNodes()) { sourceNode = node; } else { sum = sum + node.getPageRank(); } } // 4为页面总数 double newPR = (0.15 / 4.0) + (0.85 * sum); System.out.println("*********** new pageRank value is " + newPR); // 把新的pr值和计算之前的pr比较 double d = newPR - sourceNode.getPageRank(); int j = (int) (d * 1000.0);//放大1000倍 j = Math.abs(j); System.out.println(j + "___________"); context.getCounter(Mycounter.my).increment(j); sourceNode.setPageRank(newPR); context.write(key, new Text(sourceNode.toString())); } }
}
2.数据模型类
mport java.io.IOException;
import java.util.Arrays;import org.apache.commons.lang.StringUtils;
/**
- 数据模型
*作用:
*1.将页面投票节点放入adjacentNodeNames (包装属性信息)
*2.作投票对象的封装
*/
public class Node {private double pageRank = 1.0; private String[] adjacentNodeNames; public static final char fieldSeparator = '\t'; public double getPageRank() { return pageRank; } public Node setPageRank(double pageRank) { this.pageRank = pageRank; return this; } public String[] getAdjacentNodeNames() { return adjacentNodeNames; } public Node setAdjacentNodeNames(String[] adjacentNodeNames) { this.adjacentNodeNames = adjacentNodeNames; return this; } public boolean containsAdjacentNodes() { return adjacentNodeNames != null && adjacentNodeNames.length > 0; } @Override public String toString() { StringBuilder sb = new StringBuilder(); sb.append(pageRank); if (getAdjacentNodeNames() != null) { sb.append(fieldSeparator).append( StringUtils.join(getAdjacentNodeNames(), fieldSeparator)); } return sb.toString(); } // value =1.0 B D public static Node fromMR(String value) throws IOException { String[] parts = StringUtils.splitPreserveAllTokens(value, fieldSeparator); if (parts.length < 1) { throw new IOException("Expected 1 or more parts but received " + parts.length); } Node node = new Node().setPageRank(Double.valueOf(parts[0])); if (parts.length > 1) { node.setAdjacentNodeNames(Arrays .copyOfRange(parts, 1, parts.length)); } return node; } public static Node fromMR(String v1,String v2) throws IOException { return fromMR(v1+fieldSeparator+v2); //1.0 B D }
}
运行与测试
客户端程序如下代码用于开启Windows系统对MapReduce程序支持
conf.set("mapreduce.app-submission.corss-paltform", "true");
conf.set("mapreduce.framework.name", "local");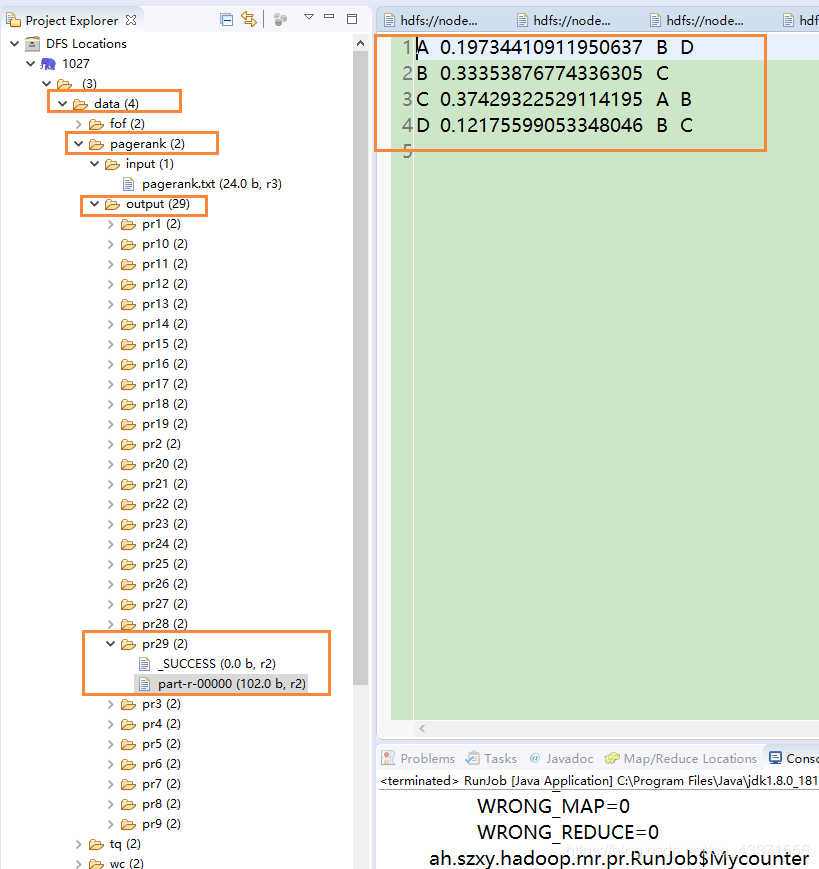
Bug记录
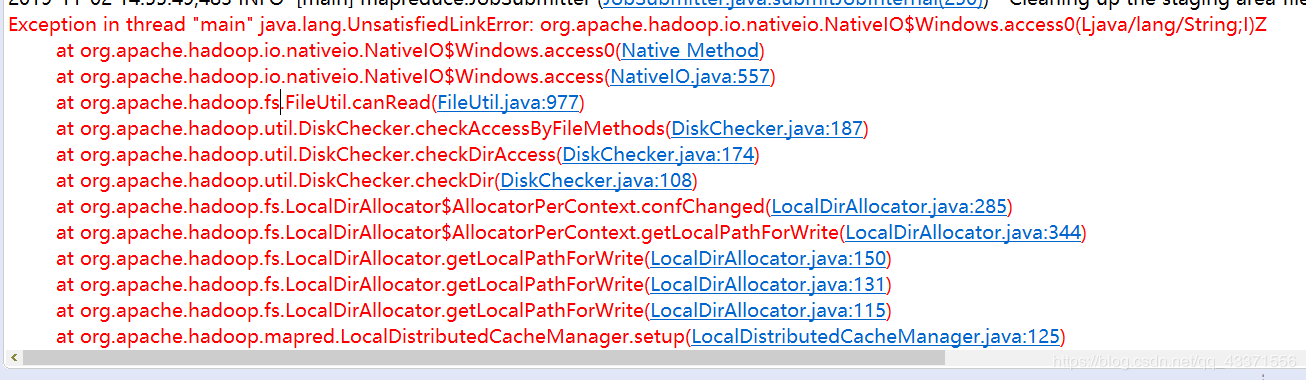
初次在Windows环境运行MapReduce程序报错"main"java.lang.UnsatisfiedLinkError
错误信息
org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z图示
解决步骤 :
- C:\Windows\System32下缺少hadoop.dll,把这个文件拷贝到C:\Windows\System32下面。
- 以管理员身份运行自己的eclipse (亲测有效)
注意: 虽然是在Windows环境下运行MapReduce程序, 但是仍需要有hdfs文件系统支持,所以集群仍需要打开 Hadoop其他相关异常及解决方案: https://blog.csdn.net/congcong68/article/details/42043093
四 MapReduce案例-TFIDF
TFIDF技术介绍
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与资讯探勘的常用加权技术。
- TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。 字词的重要性随着它在文件中出现的次数成正比增加 但同时会随着它在语料库中出现的频率成反比下降
- TF-IDF加权的各种形式常被搜寻引擎应用 作为文件与用户查询之间相关程度的度量或评级。 除了TF-IDF以外,因特网上的搜寻引擎还会使用基于链接分析的评级方法,以确定文件在搜寻结果中出现顺序:PR技术

1.词频 (term frequency, TF)
指的是某一个给定的词语在一份给定的文件中出现的次数。这个数字通常会被归一化(分子一般小于分母 区别于IDF),以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否。)
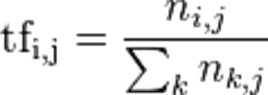
公式中: ni,j是该词在文件dj中的出现次数,而分母则是在文件dj中所有字词的出现次数之和。
2.逆向文件频率 (inverse document frequency, IDF)
是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。
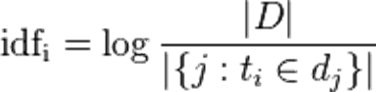

3.TF-IDF:
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。 因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
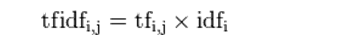
TF-IDF的主要思想: 如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现, 则认为此词或者短语具有很好的类别区分能力,适合用来分类。
需求与实现
需求 利用MapReduce技术实现对微博数据的TF-IDF统计
思路
第一次:词频统计+文本总数统计
- map: 词频:key:字词+文本,value:1 文本总数:key:count,value:1
- partition:4个reduce 0~2号reduce并行计算词频 3号reduce计算文本总数
- reduce: 0~2:sum 3:count:sum
第二次:字词集合统计:逆向文件频率
- map: key:字词,value:1
- reduce: sum
第三次:取1,2次结果最终计算出字词的TF-IDF
- map:输入数据为第一步的tf setup:加载:a,DF;b,文本总数 计算TF-IDF key:文本,value:字词+TF-IDF
- reduce: 按文本(key)生成该文本的字词+TF-IDF值列表
实现
第一个job
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * 第一个mr程序 * * 统计出:每个账号的关键词以及词频 * @author chy * */ public class FirstJob {public static void main(String[] args) { Configuration conf = new Configuration(); conf.set("mapreduce.app-submission.coress-paltform", "true"); conf.set("mapreduce.framework.name", "local");//Windows运行单机 try { FileSystem fs = FileSystem.get(conf); Job job = Job.getInstance(conf); job.setJarByClass(FirstJob.class); job.setJobName("weibo1"); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setNumReduceTasks(4); job.setPartitionerClass(FirstPartition.class); job.setMapperClass(FirstMapper.class); job.setCombinerClass(FirstReduce.class); job.setReducerClass(FirstReduce.class); FileInputFormat.addInputPath(job, new Path("/data/tfidf/input/")); Path path = new Path("/data/tfidf/output/weibo1"); if (fs.exists(path)) { fs.delete(path, true); } FileOutputFormat.setOutputPath(job, path); boolean f = job.waitForCompletion(true); if (f) { } } catch (Exception e) { e.printStackTrace(); } }
}
import java.io.IOException;
import java.io.StringReader;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.wltea.analyzer.core.IKSegmenter;
import org.wltea.analyzer.core.Lexeme;
/**
- 第一个MR,计算TF和计算N(微博总数)
- @author root
*/
public class FirstMapper extends Mapper<LongWritable, Text, Text, IntWritable> {protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //3823890210294392 今天我约了豆浆,油条 String[] v = value.toString().trim().split("\t"); if (v.length >= 2) { String id = v[0].trim(); String content = v[1].trim(); StringReader sr = new StringReader(content); IKSegmenter ikSegmenter = new IKSegmenter(sr, true); Lexeme word = null; while ((word = ikSegmenter.next()) != null) { String w = word.getLexemeText(); context.write(new Text(w + "_" + id), new IntWritable(1)); //今天_3823890210294392 1 } context.write(new Text("count"), new IntWritable(1)); //count 1 } else { System.out.println(value.toString() + "-------------"); } }
}
/**
- 设置分片
*数据的路由分发
*/
public class FirstPartition extends HashPartitioner<Text, IntWritable>{public int getPartition(Text key, IntWritable value, int reduceCount) { if(key.equals(new Text("count")))//如果出现count就去第四个分区 return 3;//第四个分区 else//否则被3模,取0,1,2 return super.getPartition(key, value, reduceCount-1); }
}
/**
- 第一个reduce
- c1_001,2 c2_001,1 count,10000
- @author chy
*/
public class FirstReduce extends Reducer<Text, IntWritable, Text, IntWritable> {protected void reduce(Text key, Iterable<IntWritable> iterable, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable i : iterable) { sum = sum + i.get(); } if (key.equals(new Text("count"))) { System.out.println(key.toString() + "___________" + sum); } context.write(key, new IntWritable(sum)); }
}
第二个job程序
public class TwoJob {public static void main(String[] args) { Configuration conf =new Configuration(); conf.set("mapreduce.app-submission.coress-paltform", "true"); conf.set("mapreduce.framework.name", "local"); try { Job job =Job.getInstance(conf); job.setJarByClass(TwoJob.class); job.setJobName("weibo2"); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setMapperClass(TwoMapper.class); job.setCombinerClass(TwoReduce.class); job.setReducerClass(TwoReduce.class); //mr运行时的输入数据从hdfs的哪个目录中获取 FileInputFormat.addInputPath(job, new Path("/data/tfidf/output/weibo1")); FileOutputFormat.setOutputPath(job, new Path("/data/tfidf/output/weibo2")); boolean f= job.waitForCompletion(true); if(f){ System.out.println("执行job成功"); } } catch (Exception e) { e.printStackTrace(); } }}
//统计df:词在多少个微博中出现过。
public class TwoMapper extends Mapper<LongWritable, Text, Text, IntWritable> {protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 获取当前 mapper task的数据片段(split) FileSplit fs = (FileSplit) context.getInputSplit(); if (!fs.getPath().getName().contains("part-r-00003")) { //豆浆_3823890201582094 3 String[] v = value.toString().trim().split("\t"); if (v.length >= 2) { String[] ss = v[0].split("_"); if (ss.length >= 2) { String w = ss[0]; context.write(new Text(w), new IntWritable(1)); } } else { System.out.println(value.toString() + "-------------"); } } }}
public class TwoReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
protected void reduce(Text key, Iterable<IntWritable> arg1, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable i : arg1) { sum = sum + i.get(); } context.write(key, new IntWritable(sum)); }
}
第三个job程序
public class LastJob {public static void main(String[] args) { Configuration conf =new Configuration();// conf.set("mapred.jar", "C:\Users\root\Desktop\tfidf.jar");
// conf.set("mapreduce.job.jar", "C:\Users\root\Desktop\tfidf.jar");conf.set("mapreduce.app-submission.cross-platform", "true"); try { FileSystem fs =FileSystem.get(conf); Job job =Job.getInstance(conf); job.setJarByClass(LastJob.class); job.setJobName("weibo3");// job.setJar("C:\Users\root\Desktop\tfidf.jar");
job.setJar("C:\Users\root\Desktop\tfidf.jar");//2.5 //把微博总数加载到 job.addCacheFile(new Path("/data/tfidf/output/weibo1/part-r-00003").toUri()); //把df加载到 job.addCacheFile(new Path("/data/tfidf/output/weibo2/part-r-00000").toUri()); //设置map任务的输出key类型、value类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); job.setMapperClass(LastMapper.class); job.setReducerClass(LastReduce.class); //mr运行时的输入数据从hdfs的哪个目录中获取 FileInputFormat.addInputPath(job, new Path("/data/tfidf/output/weibo1")); Path outpath =new Path("/data/tfidf/output/weibo3"); if(fs.exists(outpath)){ fs.delete(outpath, true); } FileOutputFormat.setOutputPath(job,outpath ); boolean f= job.waitForCompletion(true); if(f){ System.out.println("执行job成功"); } } catch (Exception e) { e.printStackTrace(); } }}
public class LastMapper extends Mapper<LongWritable, Text, Text, Text> {
// 存放微博总数
public static Map<String, Integer> cmap = null;
// 存放df
public static Map<String, Integer> df = null;// 在map方法执行之前 protected void setup(Context context) throws IOException, InterruptedException { System.out.println("******************"); if (cmap == null || cmap.size() == 0 || df == null || df.size() == 0) { URI[] ss = context.getCacheFiles(); if (ss != null) { for (int i = 0; i < ss.length; i++) { URI uri = ss[i]; if (uri.getPath().endsWith("part-r-00003")) {// 微博总数 Path path = new Path(uri.getPath()); // FileSystem fs // =FileSystem.get(context.getConfiguration()); // fs.open(path); BufferedReader br = new BufferedReader(new FileReader(path.getName())); String line = br.readLine(); if (line.startsWith("count")) { String[] ls = line.split("\t"); cmap = new HashMap<String, Integer>(); cmap.put(ls[0], Integer.parseInt(ls[1].trim())); } br.close(); } else if (uri.getPath().endsWith("part-r-00000")) {// 词条的DF df = new HashMap<String, Integer>(); Path path = new Path(uri.getPath()); BufferedReader br = new BufferedReader(new FileReader(path.getName())); String line; while ((line = br.readLine()) != null) { String[] ls = line.split("\t"); df.put(ls[0], Integer.parseInt(ls[1].trim())); } br.close(); } } } } } protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { FileSplit fs = (FileSplit) context.getInputSplit(); // System.out.println("--------------------"); if (!fs.getPath().getName().contains("part-r-00003")) { //豆浆_3823930429533207 2 String[] v = value.toString().trim().split("\t"); if (v.length >= 2) { int tf = Integer.parseInt(v[1].trim());// tf值 String[] ss = v[0].split("_"); if (ss.length >= 2) { String w = ss[0]; String id = ss[1]; double s = tf * Math.log(cmap.get("count") / df.get(w)); NumberFormat nf = NumberFormat.getInstance(); nf.setMaximumFractionDigits(5); context.write(new Text(id), new Text(w + ":" + nf.format(s))); } } else { System.out.println(value.toString() + "-------------"); } } }}
public class LastReduce extends Reducer<Text, Text, Text, Text> {
//key 微博ID, iterable(value): 词+tfitf
protected void reduce(Text key, Iterable<Text> iterable, Context context)
throws IOException, InterruptedException {StringBuffer sb = new StringBuffer(); for (Text i : iterable) { sb.append(i.toString() + "\t"); } context.write(key, new Text(sb.toString())); }
}
运行与测试
- 第一个job,第二个job中含有如下代码,因此是在windows上运行且为单机运行
conf.set("mapreduce.app-submission.coress-paltform", "true"); conf.set("mapreduce.framework.name", "local");//Windows运行单机
而第三个job 使用的如下代码, 因此是在windows上运行且为集群运行(需要将代码打成jar放在桌面, 但是是通过eclipse运行第三个job程序)
conf.set("mapreduce.app-submission.cross-platform", "true"); job.setJar("C:\Users\root\Desktop\tfidf.jar"); - 第一个job运行结果 第1-3个分片(编号0-2)格式 : 计算TF和计算N( 关键词 微博id 出现频率 ) 第3个分片(编号3): 计算微博总数

- 第2个job运行结果 : 统计的是逆向文件频率(词集合 出现的频率)
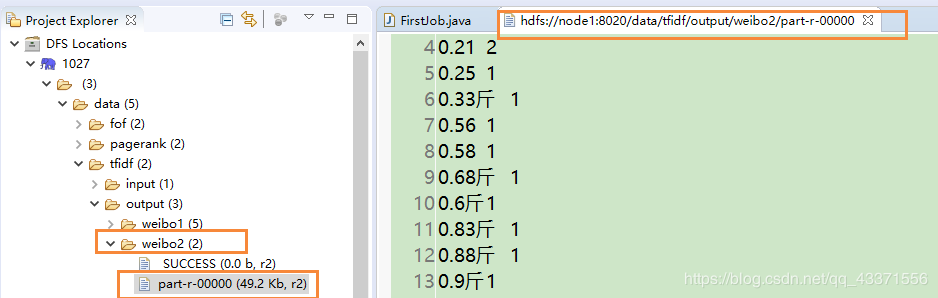
4.第3个job运行结果 分片文件显示的内容是取第1,2job运算结果运算出TF-IDF 数据分析师可以根据这些数据,分析内在联系,挖掘出有价值的数据或者数据间的内在联系 例如啤酒尿不湿的案例

五 MapReduce案例-ItemCF
推荐系统——协同过滤(Collaborative Filtering)算法
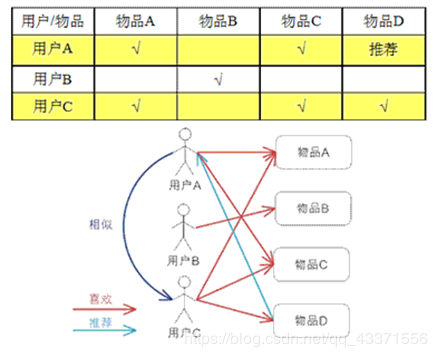
- UserCF : 基于用户的协同过滤,通过不同用户对物品的评分来评测用户之间的相似性,基于用户之间的相似性做出推荐。 简单来讲就是:给用户推荐和他兴趣相似的其他用户喜欢的物品。
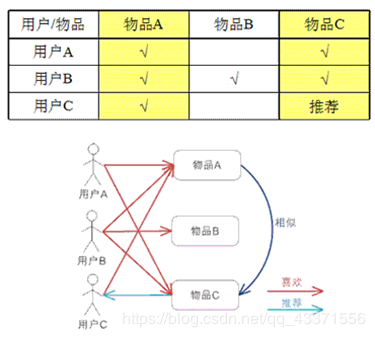
- ItemCF 基于item的协同过滤,通过用户对不同item的评分来评测item之间的相似性,基于item之间的相似性做出推荐。 简单来讲就是:给用户推荐和他之前喜欢的物品相似的物品。
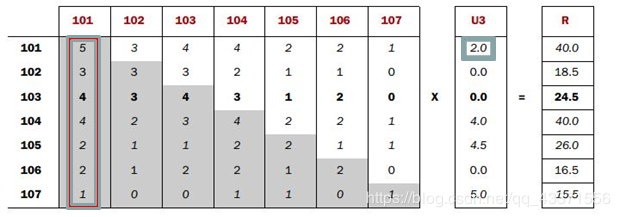
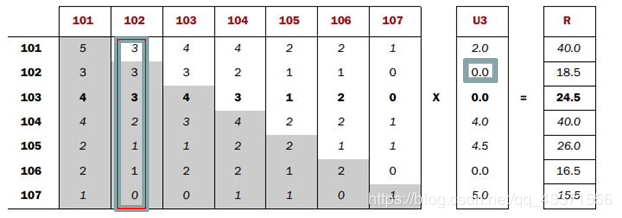
- Co-occurrence Matrix(同现矩阵)和User Preference Vector(用户评分向量)相乘得到的这个Recommended Vector(推荐向量)
- 基于全量数据的统计,产生同现矩阵 体现商品间的关联性 每件商品都有自己对其他全部商品的关联性(每件商品的特征)
- 用户评分向量体现的是用户对一些商品的评分
- 任一商品需要: 用户评分向量乘以基于该商品的其他商品关联值 求和得出针对该商品的推荐向量 排序取TopN即可
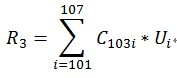
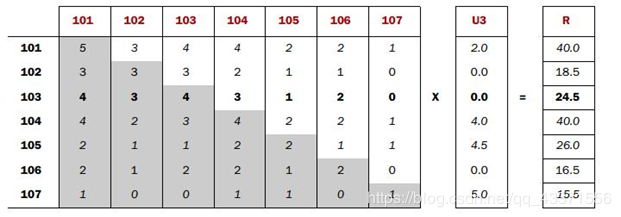
每一步迭代
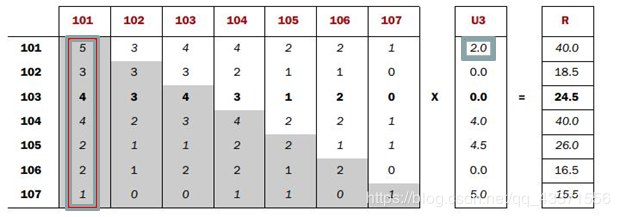
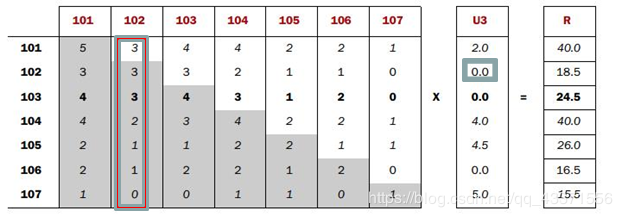
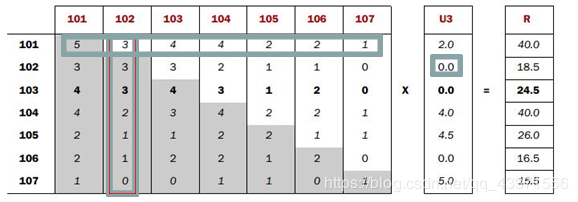
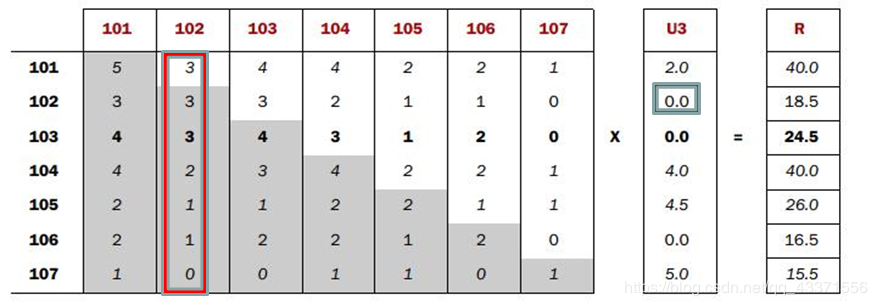
思路:
- 通过历史订单交易记录 ,计算得出每一件商品相对其他商品同时出现在同一订单的次数 so:每件商品都有自己相对全部商品的同现列表
- 用户会对部分商品有过加入购物车,购买等实际操作,经过计算会得到用户对这部分商品的评分向量列表
- 使用用户评分向量列表中的分值: 依次乘以每一件商品同现列表中该分值的代表物品的同现值 求和便是该物品的推荐向量
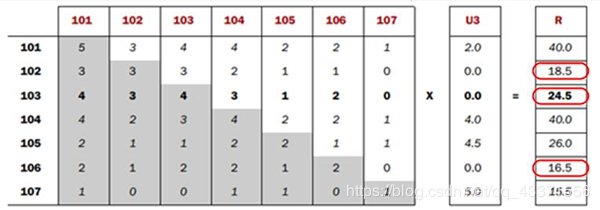
需求与实现
需求 根据MapReduce,实现对用户数据的ItemCF
思路:

- 去除重复数据
- 计算用户评分向量 key:用户 value:商品:评分 列表
- 计算同现矩阵 将每个用户的平分向量列表中的商品,两两组合输出(笛卡儿积),sum次数 key:商品A:商品B key:商品B:商品A value:1
- 计算乘积 按商品分组 同现矩阵:A商品同现列表 评分矩阵:所有用户对A商品的评分 乘机逻辑:不同同现商品下,A商品的乘机 but:计算商品A对于用户甲的推荐向量需要满足:商品A同现商品各自的评分乘机,再求和 map@key:商品 map@val: reduce@key:用户+同现 reduce@val:map@key+乘机
- 计算求和
- 计算取TopN
实现: 本项目代码以及所有代码打包至百度云
运行与测试
- 本项目依旧是运行在Windows上的单机版, 但是需要接入hdfs , 我们即使接入的是集群,也会只使用一个节点
- 需要在hdfs创建执行目录
/data/itemcf/input/,并上传文件(sample)sam_tianchi_2014002_rec_tmall_log.csv(在源码相关包下) - 在客户端程序中,依次放开每一步,然后运行即可(一定要按顺序放开)

- 最后一步运行结果
总结
链接:https://pan.baidu.com/s/17VE5yaMHn0UABc8qyQuyZg 本博文所有案例源码以及分词器jar 提取码:grss