1、前言
这个项目是一次课程作业,要求是写一个并行计算框架,本人本身对openmp比较熟,
加上又是scala的爱好者,所以想了许久,终于想到了用scala来实现一个类似openmp的
一个简单的并行计算框架。
项目github地址:ScalaMp
2、框架简介
该并行计算框架是受openmp启发,以scala语言实现的一个模仿openmp基本功能的
简单并行计算框架,该框架的设计目标是,让用户可以只需关心并行的操作的实现而无需考
虑线程的创建和管理。本框架实现了最基本的并行代码块和并行循环两个功能。
接下来会介绍框架的接口设计和具体的技术实现细节。然后会以3个具体的例子来演示
框架的使用方法,和验证框架的正确性,更多的例子详见github上的example.Main.scala文件。
3个具体的并行计算问题包括:
1、梯形积分法
2、计算pi值
3、多线程分段下载文件(图片、mp3)
3、框架接口设计与技术实现
3.1、接口设计
该框架主要是模仿了openmp的“omp parallel”和“omp parallel for”两条并行命令,
以scala语言实现了自己的版本。
在介绍接口设计之前首先我们可以分析一下以上五个问题的做一下抽象,把相同的
可并行的部分抽象出来。并行这五个问题,抽象出来可以看成是给定一个任务(有固定长度)
和线程数,每个线程负责这个任务某一段的计算。比如:
1、梯形积分法
给了定积分区间和梯形个数,每个线程就负责某一段区间的梯形面积的计算。
2、计算pi值
公式:

然后给定精度k,每个线程就计算某段的和。
3、多线程分段下载文件(图片、mp3)
当知道了需要下载的文件的长度,每个线程就也是负责某段区间的数据下载。
所以根据以上并行问题的抽象和对openmp的理解再结合Scala语言,该框架设计
两个接口:
第一个是并行for 循环的接口:

range指的是循环的范围,比如for循环是从0到99则range等于0 to 99,对应于for
循环的结束条件,然后下一个参数是设置schedule,目前实现了static和dynamic,
如果不想自己设置,可以用提供的默认参数:“Default_Schedule_Static”和
“Default_Schedule_Dynamic”。然后withThread代表需要开启的线程数目,each
函数接受一个lamda表达式作为参数,表示一个线程执行的操作,具体实现由用户定义,
my_rank参数代表线程的标号,threadNum代表线程的总数目,range参数表示该线程
分到的某段长度范围,然后线程根据这段范围来做自己的事情。Critical代表临界区,
需要同步的代码就放到critical函数里面。
第二个是并行代码块的接口:
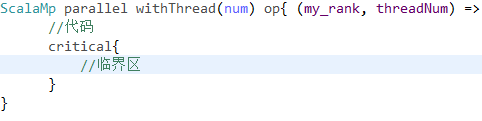
对应参数和parallel_for一样,只是代码块的并行接口比for版本简单,因为就是对
代码块的并行。
3.2技术实现细节
实现上主要是借助了Scala 和 Akka。
Scala(Scalable Langeaue) 是一种多范式的编程语言,设计初衷是要集成面向对象
编程和函数式编程的各种特性。Akka 是一个用 Scala 编写的库,用于简化编写容错的、
高可伸缩性的 Java 和 Scala 的 Actor 模型应用。
实现上主要是利用akka框架来实现后台的actor(轻量级的线程)的创建和管理。
为了使得接口的调用更接近于openmp,利用了scala语言的特性。
首先ScalaMp是一个单例对象,而且后面的parallel_for, parallel, withThread, op, each
等都是ScalaMp对象的成员函数,由于scala语言的特性,符合某些条件的成员函数的调用
可以省略“.”号,并且加上函数的链式调用就形成了接口的表现形式。
ScalaMp粗略代码,详细代码见github:

schedule的定义:

当ScalaMp对象被创建的时候,会在内部创建一个ActorSystem,可以看成是一个线程
环境,然后在环境中创建一个管理者actor,然后该actor会创建100个工人actor,并对它们
进行管理,可以看成是线程池。然后每次用户进行并行操作的时候,就从线程池中分配制定
的工人actor个数来执行操作。ScalaMp对象只会在第一次被访问的时候创建,然后在整个
程序周期结束前都会存在。
当用户调用接口时,管理者会将用户定义的线程函数发送给每个actor,然后每个actor
执行用户定义的函数。
临界区的实现时借助了actor模型的邮箱来实现的,因为actor之间的通信是通过发送
邮件的方式通信,而邮箱会对消息做同步,使得actor能够处理完一条消息再处理下一条消息。
所以临界区内的代码其实是被封装成了一个函数,然后由每个工人actor发送给管理者,管理者
一条一条的处理来自工人actor的临界区函数,也就是相当于同步执行了临界区的代码,也就是
说其实临界区的代码并不由每个工人actor执行,而是由工人actor发送给管理者,然后由管理者
执行,并且借助邮箱的同步特点,使得能够实现线程同步的操作。
4、框架演示
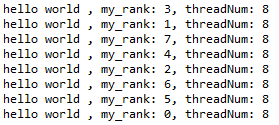
我们还是从经典的“hello world”例子开始
4.1、hello World
代码:

运行结果:
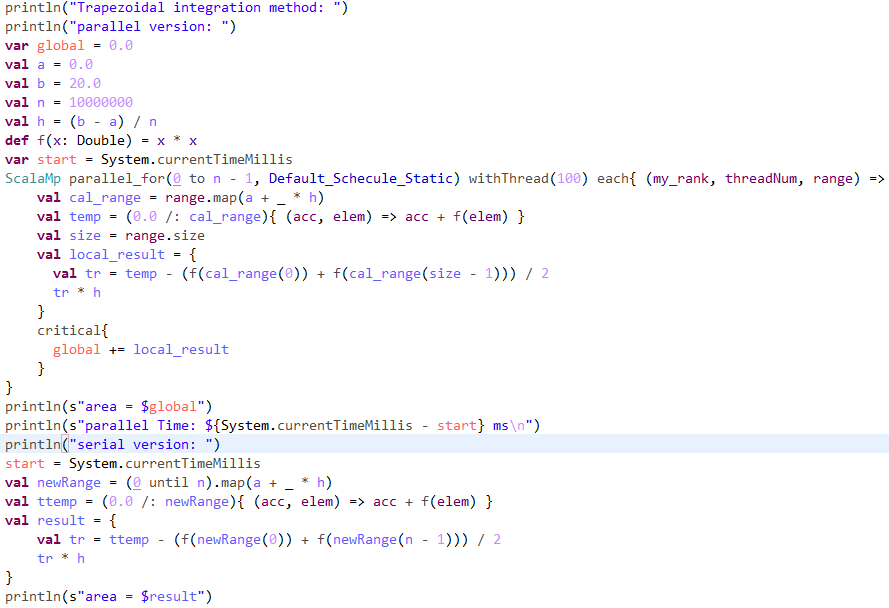
4.2、梯形积分法
代码:
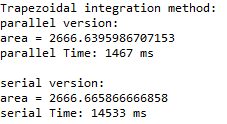
运行结果:
4.3、计算pi值
代码:
运行结果:
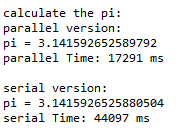
4.4、多线程下载文件
下载的文件时古巨基的“情歌王”:
代码:
//多线程下载文件 multi-thread download file
println("multi-thread download file: ")
println("parallel version: ")
import java.net._
import java.io._
import java.io.RandomAccessFile;
val url = new URL("http://yinyueshiting.baidu.com/data2/music/5140129/20572571421424061128.mp3?xcode=974dbf2923e1208ffe561ce0b05f51646b547126504ae00a")
val connection = url.openConnection.asInstanceOf[HttpURLConnection];
connection setRequestMethod "GET"
connection setRequestProperty("User-Agent", "Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:17.0) Gecko/20100101 Firefox/17.0")
connection setAllowUserInteraction true
val length = connection.getContentLength
println(s"content-length: $length")
val file = new File("F:\\情歌王_P.mp3")
CreateFile.createFile(file, length.toLong)
var start = System.currentTimeMillis
ScalaMp parallel_for(0 until length, Default_Schecule_Static) withThread(10) each{ (my_rank, threadNum, range) =>
val fos = new RandomAccessFile(file, "rw");
val BUFFER_SIZE = 256
val buf = new Array[Byte](BUFFER_SIZE);
var startPos = range(0)
var endPos = startPos + range.length - 1
var curPos = startPos
val connection2 = url.openConnection.asInstanceOf[HttpURLConnection];
connection2 setRequestMethod "GET"
connection2 setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)")
connection2 setAllowUserInteraction true
connection2.setRequestProperty("Range", "bytes=" + startPos + "-" + endPos);//设置获取资源数据的范围,从startPos到endPos
fos.seek(startPos);
val bis = new BufferedInputStream(connection2.getInputStream());
while (curPos < endPos) {
val len = bis.read(buf, 0, BUFFER_SIZE);
fos.write(buf, 0, len);
curPos = curPos + len;
}
}
println(s"parallel Time: ${System.currentTimeMillis - start} ms\n")
println("serial version: ")
val file2 = "F:\\情歌王_S.mp3"
if(connection.getResponseCode == 200) {
val out = new java.io.FileWriter(file2)
val in = connection.getInputStream
// 1K的数据缓冲
val bs = new Array[Byte](1024)
// 读取到的数据长度
var len = 0
val sf = new File(file2)
val os = new FileOutputStream(sf)
// 开始读取
len = in.read(bs)
while(len != -1){
os.write(bs, 0, len)
len = in.read(bs)
}
// 完毕,关闭所有链接
os.close
in.close
}
println(s"serial Time: ${System.currentTimeMillis - start} ms\n")</code></pre></div></div><p><strong>运行结果:</strong></p><figure class=""><div class="rno-markdown-img-url" style="text-align:center"><div class="rno-markdown-img-url-inner" style="width:26.03%"><div style="width:100%"><img src="https://cdn.static.attains.cn/app/developer-bbs/upload/1723307414075203969.png" /></div></div></div></figure><h2 id="4vl8v" name="5%E3%80%81%E6%80%BB%E7%BB%93">5、总结</h2><p>目前该框架只是实现了简单的线程管理,还有代码还存在许多bug,比如最大线程数不能</p><p>超过100,还有程序不会终止等,而且schedule策略只实现了static和dynamic策略,</p><p>dynamic的策略实现的可能不太对。最后希望感兴趣的朋友可以和我一起改进这个小框架,</p><p>虽然在实际问题中测试的不够多,但是我也尝试过在实际中的应用,并行还是显著效果的,</p><p>比如某个问题是我现在有4000个400维的特征,每个特征要寻找在另外3999个特征中距离</p><p>的top20个,使用了ScalaMp的并行版本比原串行快了6,7倍左右。</p>