PCL common中常见的基础功能函数
pcl_common中主要是包含了PCL库常用的公共数据结构和方法,比如PointCloud的类和许多用于表示点,曲面,法向量,特征描述等点的类型,用于计算距离,均值以及协方差,角度转换以及几何变化的函数。
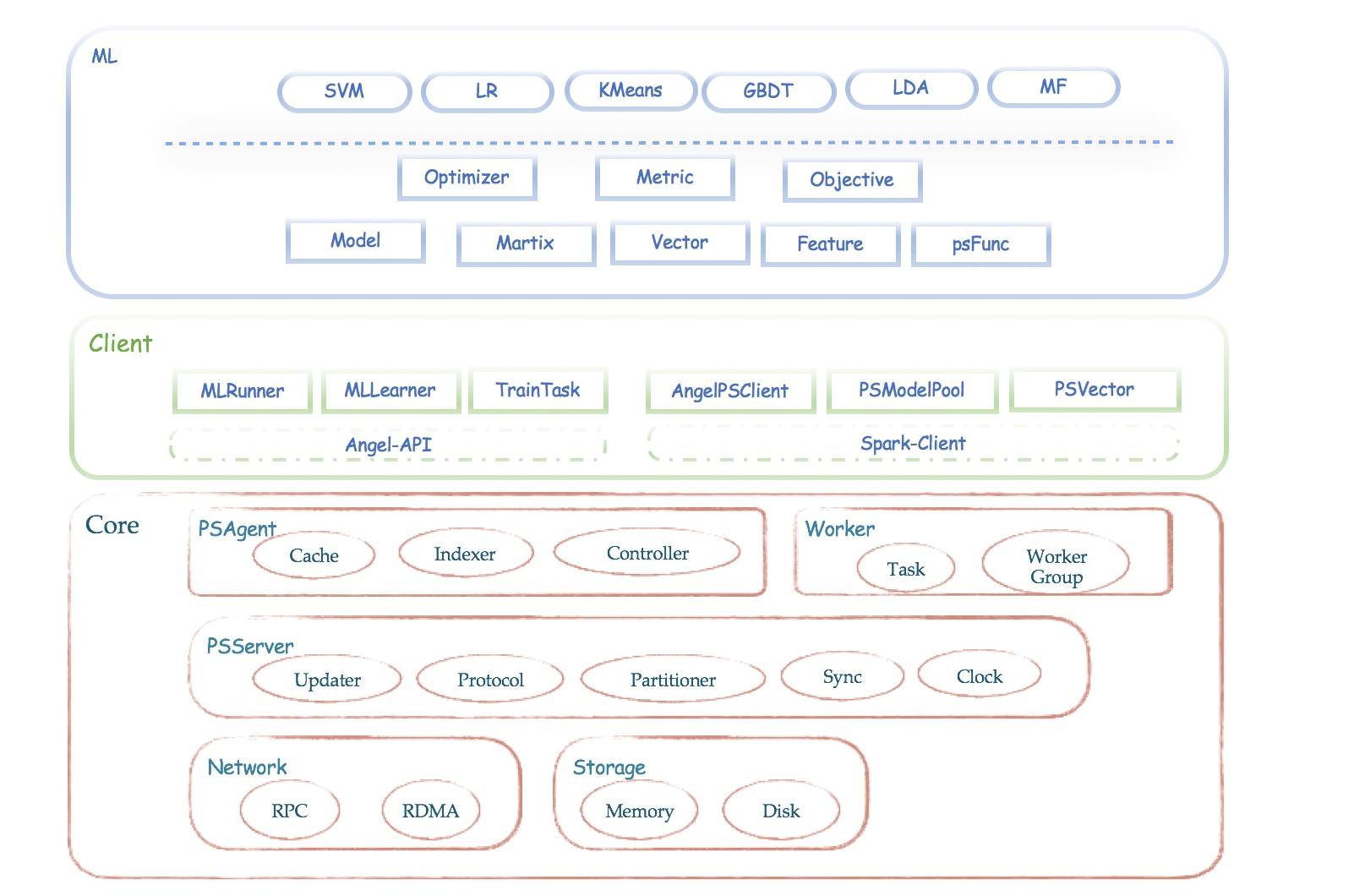
腾讯Angel 1.0正式版发布:基于Java与Scala的机器学习高性能计算平台
机器之心报道
Tencent
深度学习是近些年来人工智能技术发展的核心,伴随而来的机器学习框架平台也层出不穷。到现在,一家科技巨头没有一个主导的机器学习平台都不好意思跟人打招呼,比如谷歌有 TensorFlow、微软有 CNTK、Facebook 是 Torch 的坚定支持者、IBM 强推 Spark、百度开源了 PaddlePaddle、亚马逊则是 MXNet 的支持者。而为了尽可能地获得开发者支持和抢占发展先机,很多平台都选择了开源。
在去年 12 月 18 日的腾讯大数据技术峰会暨 KDD China
数据分析小结:使用流计算 Oceanus(Flink) SQL 作业进行数据类型转换
作者:吴云涛,腾讯 CSIG 高级工程师 在这个数据爆炸的时代,企业做数据分析也面临着新的挑战, 如何能够更高效地做数据准备,从而缩短整个数据分析的周期,让数据更有时效性,增加数据的价值,就变得尤为重要。将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程(即 ETL 过程),则需要开发人员则需要掌握 Spark、Flink 等技能,使用的技术语言则是 Java、Scala 或者 Python,一定程度上增加了数据分析的难度。而 ELT 过程逐渐被开发者和
新加坡总理的儿子,写了一本计算机入门书籍...
毕业自剑桥大学,且拥有数学与计算机专业双学位的新加坡总理李显龙,曾经在 2015 年的某次公开演讲提到过,自己在几年前用 C++ 写过一个数独求解器。

5000字详解:计算机网络在 Spark 的应用
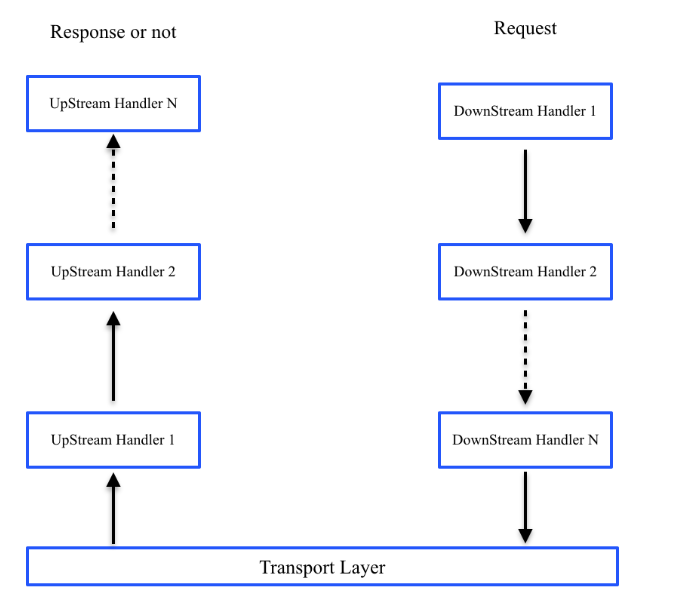
对于分布式系统来说,网络是最基本的一环,其设计的好坏直接影响到整个分布式系统的稳定性及可用性。为此,Spark专门独立出基础网络模块spark-network,为上层RPC、Shuffle数据传输、RDD Block同步以及资源文件传输等提供可靠的网络服务。
ScalaMP ---- 模仿 OpenMp 的一个简单并行计算框架
这个项目是一次课程作业,要求是写一个并行计算框架,本人本身对openmp比较熟,
ScalaMP ---- 模仿 OpenMp 的一个简单并行计算框架
这个项目是一次课程作业,要求是写一个并行计算框架,本人本身对openmp比较熟,
Spark Streaming——Spark第一代实时计算引擎
虽然SparkStreaming已经停止更新,Spark的重点也放到了 Structured Streaming ,但由于Spark版本过低或者其他技术选型问题,可能还是会选择SparkStreaming。SparkStreaming对于时间窗口,事件时间虽然支撑较少,但还是可以满足部分的实时计算场景的,SparkStreaming资料较多,这里也做一个简单介绍。
Scala语言基础之结合demo和spark讲实现链式计算
一,什么是链式计算
1,一般开发习惯把事情封装到一个方法中;链式编程思想是把要做的事情封装到block中,给外部提供一个返回这个block的方法
2,链式编程思想方法特点:方法的返回值必须是block,block的参数是需要操作的内容,block的返回值是返回这个block的方法的调用者
二,举例说明
比如我们定义个case class Person
case class Person(private val parent: Person = null ,private val name: String =
Actor 分布式并行计算模型: The Actor Model for Concurrent Computation
The Actor Model for Concurrent Computation

Actor 分布式并行计算模型: The Actor Model for Concurrent Computation
The Actor Model for Concurrent Computation

ScalaMP ---- 模仿 OpenMp 的一个简单并行计算框架
1、前言
这个项目是一次课程作业,老师要求写一个并行计算框架,本人本身对openmp比较熟,加上又是scala
的爱好者,所以想了许久,终于想到了用scala来实现一个类似openmp的一个简单的并行计算框架。
项目github地址:ScalaMp
2、框架简介
该并行计算框架是受openmp启发,以scala语言实现的一个模仿openmp基本功能的简单并行计算框架,
该框架的设计目标是,让用户可以只需关心并行的操作的实现而无需考虑线程的创建和管理。本框架实现了最
基本的并行代码块和
2018年那些值得推荐的计算机类书籍
当之无愧的2018第一神书,虽然出版时间略晚,后发亦可先制。读此书之前可以先读《Streaming 101》和《Streaming 102》预热。《Streaming Systems》沉淀了谷歌过去十多年对流、批计算的思考,前半部分主要阐述了Dataflow模型,提出流计算不确定性和可靠性的有效解决方案,把批处理统一吸纳进同一套框架,后半部分叙述了Streaming SQL的可行性。这本书的也是大热的 Flink 和Structural Streaming 的理论基础。
深入字节码 -- 计算方法执行时间
原
java程序通过javac编译之后生成文件.class就是字节码集合,正是有这样一种中间码(字节码),使得scala/groovy/clojure等函数语言只用实现一个编译器即可运行在JVM上。 看看一段简单代码。
一文了解MEC 2019上的边缘计算动态
MWC是全球移动通信领域最具规模和影响力的盛会,集中展示了目前通信领域最新的研究成果以及未来趋势, 2月28号,MWC2019 (世界移动通信大会) 顺利落下帷幕, 5G在成为本届大会最大焦点的同时,手机、边缘计算、物联网等与5G紧密相关的应用领域也倍受瞩目。

about云spark开发基础之Scala快餐
----
spark是用Scala语言来写的,因此学习Scala成为spark的基础。当然如果使用其它语言也是可以的。从性能上来讲,及代码简洁等方面,Scala是比较好的一个选择。
当前我们的生活都是处于快节奏,各方面都讲究快,快--讲究的是效率,这里同样是想让大家快速入门Scala,如同吃快餐一样,因此命名为快餐Scala。文中如有不当之处,大家多批评指正。
Scala是函数式编程,继承了其它语言的很多特点,并且发展了自己特性。因此下面所涉及的内容,需要熟悉一门语言,特别是Java语言。如果没有语言基础
利用杰卡德系数计算文本相似度
两个集合A和B交集元素的个数在A、B并集中所占的比例,称为这两个集合的杰卡德系数,用符号 J(A,B) 表示。
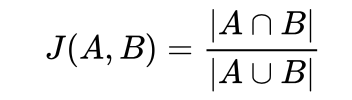
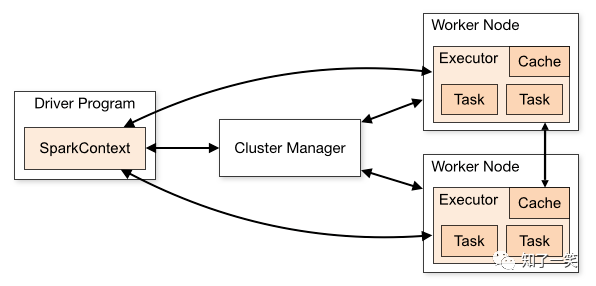
实时计算框架:Spark集群搭建与入门案例
Spark是专为大规模数据处理而设计的,基于内存快速通用,可扩展的集群计算引擎,实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流,运算速度相比于MapReduce得到了显著的提高。
在Spark上用LDA计算文本主题模型
在新闻推荐中,由于新闻主要为文本的特性,基于内容的推荐(Content-based Recommendation)一直是主要的推荐策略。基于内容的策略主要思路是从文本提取出特征,然后利用特征向量化后的向量距离来计算文本间的相关度。这其中应用最广的当属分类(Category)相关和关键词(Keywords/Tag)相关,然而这两种策略却有很多无法覆盖的场景。首先,关键词无法解决同义词和一词多义的问题。比如下面两篇文章的关键词:
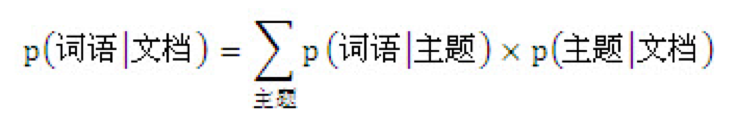
ERP软件成本结算之计算实际作业价格
声明:本文章仅代表原作者观点,仅用于SAP软件的应用与学习,不代表SAP公司。注:文中所示截图来源SAP软件,相应著作权归SAP所有。文中所指ERP即SAP软件。
