虽然SparkStreaming已经停止更新,Spark的重点也放到了 Structured Streaming ,但由于Spark版本过低或者其他技术选型问题,可能还是会选择SparkStreaming。SparkStreaming对于时间窗口,事件时间虽然支撑较少,但还是可以满足部分的实时计算场景的,SparkStreaming资料较多,这里也做一个简单介绍。
一. 什么是Spark Streaming
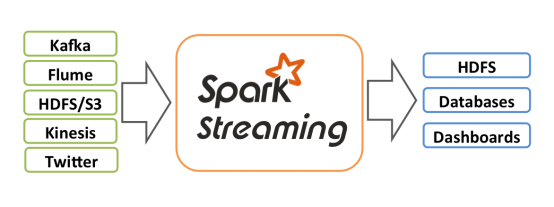
Spark Streaming在当时是为了与当时的Apache Storm竞争,也让Spark可以用于流式数据的处理。根据其官方文档介绍,Spark Streaming有高吞吐量和容错能力强等特点。Spark Streaming支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等等。数据输入后可以用Spark的高度抽象原语如:map、reduce、join、window等进行运算。而结果也能保存在很多地方,如HDFS,数据库等。另外Spark Streaming也能和MLlib(机器学习)以及Graphx完美融合。当然Storm目前已经渐渐淡出,Flink开始大放异彩。
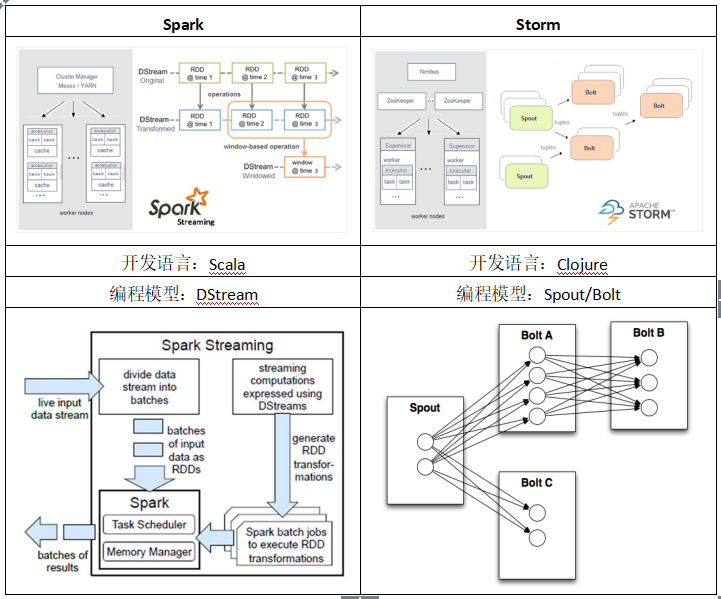
Spark与Storm的对比
二、SparkStreaming入门
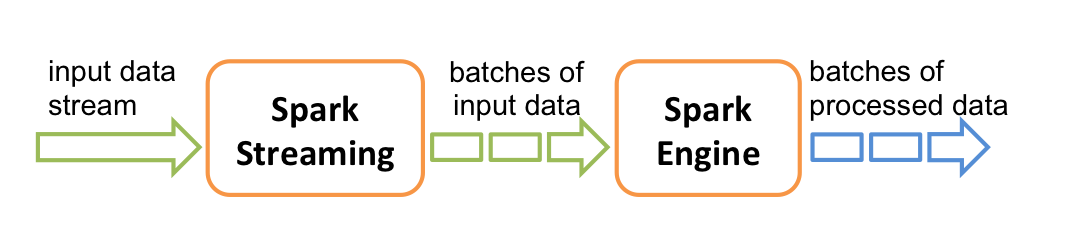
Spark Streaming 是 Spark Core API 的扩展,它支持弹性的,高吞吐的,容错的实时数据流的处理。数据可以通过多种数据源获取,例如 Kafka,Flume,Kinesis 以及 TCP sockets,也可以通过例如 map,reduce,join,window 等的高级函数组成的复杂算法处理。最终,处理后的数据可以输出到文件系统,数据库以及实时仪表盘中。事实上,你还可以在 data streams(数据流)上使用 [机器学习] 以及 [图计算] 算法。在内部,它工作原理如下,Spark Streaming 接收实时输入数据流并将数据切分成多个 batch(批)数据,然后由 Spark 引擎处理它们以生成最终的 stream of results in batches(分批流结果)。
Spark Streaming 提供了一个名为 discretized stream 或 DStream 的高级抽象,它代表一个连续的数据流。DStream 可以从数据源的输入数据流创建,例如 Kafka,Flume 以及 Kinesis,或者在其他 DStream 上进行高层次的操作以创建。在内部,一个 DStream 是通过一系列的 [RDDs] 来表示。
本指南告诉你如何使用 DStream 来编写一个 Spark Streaming 程序。你可以使用 Scala,Java 或者 Python(Spark 1.2 版本后引进)来编写 Spark Streaming 程序。
在idea中新建maven项目
引入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.4.4</version>
</dependency>Project Structure —— Global Libraries —— 把scala 添加到 add module
新建Scala Class
import org.apache.log4j.{Level, Logger} import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} import org.apache.spark.streaming.{Seconds, StreamingContext}object Demo {
//屏蔽日志
Logger.getLogger("org.apache")setLevel(Level.WARN)def main(args: Array[String]): Unit = {
//local会有问题 最少两个线程 一个拿数据 一个计算 //val conf = new SparkConf().setAppName(s"${this.getClass.getSimpleName}").setMaster("local") val conf = new SparkConf().setAppName(s"${this.getClass.getSimpleName}").setMaster("local[2]") //时间间隔 val ssc = new StreamingContext(conf,Seconds(1)) //接收数据 处理 //socket demo val value: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 9999) val words: DStream[String] = value.flatMap(_.split(" ")) val wordsTuple: DStream[(String, Int)] = words.map((_, 1)) val wordcount: DStream[(String, Int)] = wordsTuple.reduceByKey(_ + _) //触发action wordcount.print() ssc.start() //保持流的运行 等待程序被终止 ssc.awaitTermination()}
}
测试
下载一个win10 用的netcat
https://eternallybored.org/misc/netcat/
下载netcat 1.12
解压 在目录下启动cmd
输入
nc -L -p 9999开始输入单词 在idea中验证接收
原理
初始化StreamingContext
为了初始化一个 Spark Streaming 程序,一个 StreamingContext 对象必须要被创建出来,它是所有的 Spark Streaming 功能的主入口点。
import org.apache.spark._
import org.apache.spark.streaming._
val conf = new SparkConf().setAppName(appName).setMaster(master)
val ssc = new StreamingContext(conf, Seconds(1))
appName 参数是展示在集群 UI 界面上的应用程序的名称
master 是local 或者spark集群的url(mesos yarn)
本地测试可以用local[*] 注意要多于两个线程
Second(1)定义的是batch interval 批处理间隔 就是间隔多久去拿一次数据
在定义一个 context 之后,您必须执行以下操作。
- 通过创建输入 DStreams 来定义输入源。
- 通过应用转换和输出操作 DStreams 定义流计算(streaming computations)。
- 开始接收输入并且使用
streamingContext.start()来处理数据。 - 使用
streamingContext.awaitTermination()等待处理被终止(手动或者由于任何错误)。 - 使用
streamingContext.stop()来手动的停止处理。
需要记住的几点:
- 一旦一个 context 已经启动,将不会有新的数据流的计算可以被创建或者添加到它。
- 一旦一个 context 已经停止,它不会被重新启动。
- 同一时间内在 JVM 中只有一个 StreamingContext 可以被激活。
- 在 StreamingContext 上的 stop() 同样也停止了 SparkContext。为了只停止 StreamingContext,设置
stop()的可选参数,名叫stopSparkContext为 false。 - 一个 SparkContext 就可以被重用以创建多个 StreamingContexts,只要前一个 StreamingContext 在下一个StreamingContext 被创建之前停止(不停止 SparkContext)。
Discretized Stream or DStream
Discretized Stream or DStream 是 Spark Streaming 提供的基本抽象。它代表了一个连续的数据流。可能是数据源接收的流,也可能是转换后的流。
DStream就是多个和时间相关的一系列连续RDD的集合,比如本例就是间隔一秒的一堆RDD的集合
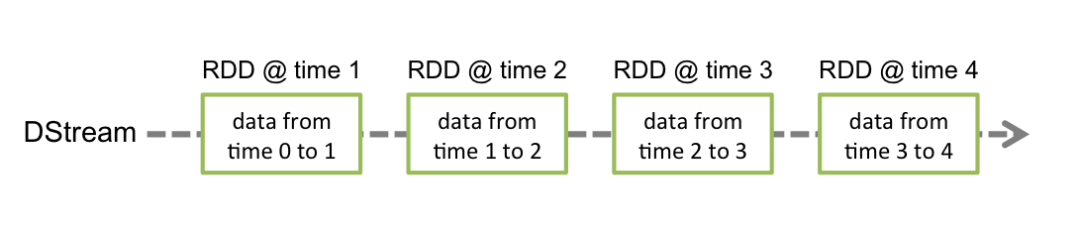
DStream也是有依赖关系的
flatMap 操作也是直接作用在DStream上的,就和作用于RDD一样 这样很好理解
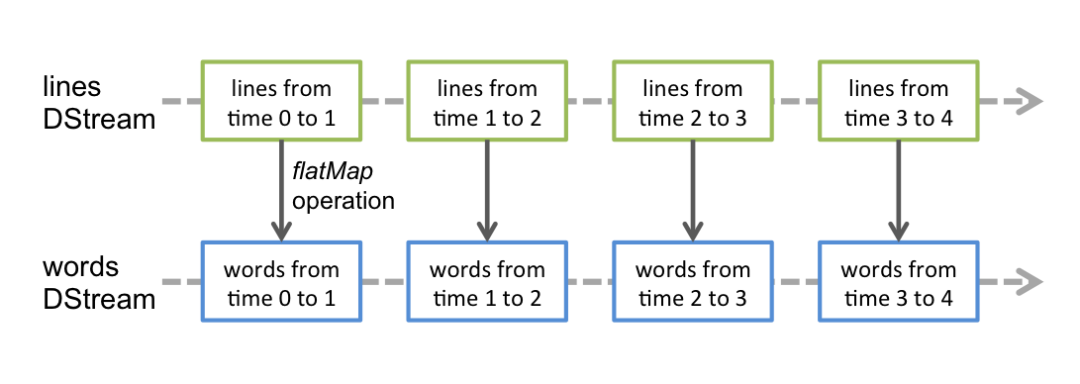
我们先来看数据源接收的流 这种叫做Input DStreams 他会通过Receivers接收器去不同的数据源接收数据。
Spark Streaming内置了两种数据源:
- 基础的数据源:比如刚才用的socket接收 还有file systems
- 高级的数据源:比如kafka 还有flume kinesis等等
注意本地运行时,不要用local或者local[1],一个线程不够。放到集群上时分配给SparkStreaming的核数必须大于接收器的数量,留一个核去处理数据。
我们也可以自定义数据源,那我们就需要自己开发一个接收器。
Transformations
在我们接收到Dstreams之后可以进行转换操作,常见转换如下:
Transformation(转换) | Meaning(含义) |
|---|---|
map(func) | 利用函数 func 处理原 DStream 的每个元素,返回一个新的 DStream。 |
flatMap(func) | 与 map 相似,但是每个输入项可用被映射为 0 个或者多个输出项。。 |
filter(func) | 返回一个新的 DStream,它仅仅包含原 DStream 中函数 func 返回值为 true 的项。 |
repartition(numPartitions) | 通过创建更多或者更少的 partition 以改变这个 DStream 的并行级别(level of parallelism)。 |
union(otherStream) | 返回一个新的 DStream,它包含源 DStream 和 otherDStream 的所有元素。 |
count() | 通过 count 源 DStream 中每个 RDD 的元素数量,返回一个包含单元素(single-element)RDDs 的新 DStream。 |
reduce(func) | 利用函数 func 聚集源 DStream 中每个 RDD 的元素,返回一个包含单元素(single-element)RDDs 的新 DStream。函数应该是相关联的,以使计算可以并行化。 |
countByValue() | 在元素类型为 K 的 DStream上,返回一个(K,long)pair 的新的 DStream,每个 key 的值是在原 DStream 的每个 RDD 中的次数。 |
reduceByKey(func, [numTasks]) | 当在一个由 (K,V) pairs 组成的 DStream 上调用这个算子时,返回一个新的,由 (K,V) pairs 组成的 DStream,每一个 key 的值均由给定的 reduce 函数聚合起来。注意:在默认情况下,这个算子利用了 Spark 默认的并发任务数去分组。你可以用 numTasks 参数设置不同的任务数。 |
join(otherStream, [numTasks]) | 当应用于两个 DStream(一个包含(K,V)对,一个包含 (K,W) 对),返回一个包含 (K, (V, W)) 对的新 DStream。 |
cogroup(otherStream, [numTasks]) | 当应用于两个 DStream(一个包含(K,V)对,一个包含 (K,W) 对),返回一个包含 (K, Seq[V], Seq[W]) 的 tuples(元组)。 |
transform(func) | 通过对源 DStream 的每个 RDD 应用 RDD-to-RDD 函数,创建一个新的 DStream。这个可以在 DStream 中的任何 RDD 操作中使用。 |
updateStateByKey(func) | 返回一个新的 "状态" 的 DStream,其中每个 key 的状态通过在 key 的先前状态应用给定的函数和 key 的新 valyes 来更新。这可以用于维护每个 key 的任意状态数据。 |
这里我们特别介绍一下updateStateByKey
我们如果需要对历史数据进行统计,可能需要去kafka里拿一下之前留存的数据,也可以用updateStateByKey这个方法。
//保存状态 聚合相同的单词
val wordcount = wordsTuple.updateStateByKey[Int](
//updateFunction _
(newValues: Seq[Int], runningCount: Option[Int])=> {
val newCount = Some(newValues.sum + runningCount.getOrElse(0))
newCount
}
)比如刚才的单词计数,我们只能统计每一次发过来的消息,但是如果希望统计多次消息就需要用到这个,我们要指定一个checkpoint,就是从哪开始算。
//增加成员变量
val checkpointDir = "./ckp"
//在方法中加入checkpoint
ssc.checkpoint(checkpointDir)
val value: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 9999)
value.checkpoint(Seconds(4))//官方建议批次时间的1-5倍
这时候我们建立StreamingContext的方法就要改变了 我们把刚才的创建过程提取成方法。
def creatingFunc():StreamingContext = {val conf = new SparkConf().setAppName(s"${this.getClass.getSimpleName}").setMaster("local[*]") val ssc = new StreamingContext(conf, Seconds(1)) ssc.checkpoint(checkpointDir) val value: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 9999) value.checkpoint(Seconds(4))//官方建议批次时间的1-5倍 val words: DStream[String] = value.flatMap(_.split(" ")) val wordsTuple: DStream[(String, Int)] = words.map((_, 1)) //保存状态 聚合相同的单词 val wordcount = wordsTuple.updateStateByKey[Int]( //updateFunction _ (newValues: Seq[Int], runningCount: Option[Int])=> { val newCount = Some(newValues.sum + runningCount.getOrElse(0)) newCount } ) //触发action wordcount.print() ssc
}
在mian函数中修改为:
def main(args: Array[String]): Unit = {
val ssc = StreamingContext.getOrCreate(checkpointDir,creatingFunc _)
ssc.start()
//保持流的运行 等待程序被终止
ssc.awaitTermination()
}这样就是,如果有checkpoint,程序会在checkpoint中把程序加载回来(程序被保存为二进制),没有checkpoint的话才会创建。
将目录下的checkpoint删除,就可以将状态删除。
生产中updateStateByKey由于会将数据备份要慎重使用,可以考虑用hbase,redis等做替代。或者借助kafka做聚合处理。
//如果不用updatestateByKey 可以考虑redis
wordsTuple.foreachRDD(rdd => {
rdd.foreachPartition(i =>
{
//redis
}
)
})窗口操作
Spark Streaming 也支持 _windowed computations(窗口计算),它允许你在数据的一个滑动窗口上应用 transformation(转换)。
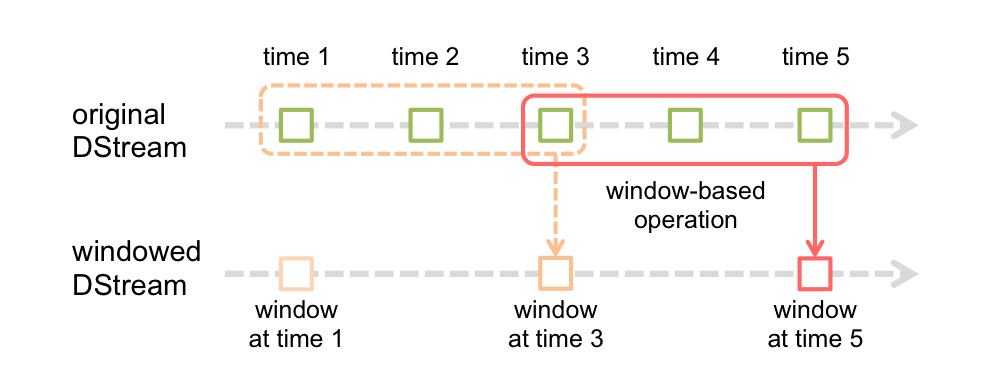
如上图显示,窗口在源 DStream 上 slides(滑动),任何一个窗口操作都需要指定两个参数:
- window length(窗口长度) - 窗口的持续时间。
- sliding interval(滑动间隔) - 执行窗口操作的间隔。
比如计算过去30秒的词频:
val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(30), Seconds(10))一些常用的窗口操作如下所示,这些操作都需要用到上文提到的两个参数 - windowLength(窗口长度) 和 slideInterval(滑动的时间间隔)。
返回一个新的 DStream,它是基于 source DStream 的窗口 batch 进行计算的。Join操作
在 Spark Streaming 中可以执行不同类型的 join
val stream1: DStream[String, String] = ...
val stream2: DStream[String, String] = ...
val joinedStream = stream1.join(stream2)
//也可以用窗口
val windowedStream1 = stream1.window(Seconds(20))
val windowedStream2 = stream2.window(Minutes(1))
val joinedStream = windowedStream1.join(windowedStream2)DStreams输出操作
输出操作允许将 DStream 的数据推送到外部系统,如数据库或文件系统。
会触发所有变换的执行,类似RDD的action操作。有如下操作:
在运行流应用程序的 driver 节点上的DStream中打印每批数据的前十个元素。这对于开发和调试很有用。foreachRDD设计模式使用
dstream.foreachRDD允许将数据发送到外部系统。
但我们不要每次都创建一个连接,解决方案如下:
减少开销,分区分摊开销
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
val connection = createNewConnection()
partitionOfRecords.foreach(record => connection.send(record))
connection.close()
}
}更好的做法是用静态资源池:
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
// ConnectionPool is a static, lazily initialized pool of connections
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record))
ConnectionPool.returnConnection(connection) // return to the pool for future reuse
}
}连接Kafka
Apache Kafka是一个高性能的消息系统,由Scala 写成。是由Apache 软件基金会开发的一个开源消息系统项目。
Kafka 最初是由LinkedIn 开发,并于2011 年初开源。2012 年10 月从Apache Incubator 毕业。该项目的目标是为处理实时数据提供一个统一、高通量、低等待(低延时)的平台。
更多kafka相关请查看Kafka入门宝典(详细截图版)
Spark Streaming 2.4.4兼容 kafka 0.10.0 或者更高的版本
Spark Streaming在2.3.0版本之前是提供了对kafka 0.8 和 0.10的支持的 ,不过在2.3.0以后对0.8的支持取消了。
Note: Kafka 0.8 support is deprecated as of Spark 2.3.0.
spark-streaming-kafka-0-8 | spark-streaming-kafka-0-10 | |
|---|---|---|
Broker Version | 0.8.2.1 or higher | 0.10.0 or higher |
API Maturity | Deprecated | Stable |
Language Support | Scala, Java, Python | Scala, Java |
Receiver DStream | Yes | No |
Direct DStream | Yes | Yes |
SSL / TLS Support | No | Yes |
Offset Commit API | No | Yes |
Dynamic Topic Subscription | No | Yes |
Receiver
这里简单介绍一下对kafka0.8的一种支持方式:基于Receiver
依赖:
groupId = org.apache.spark
artifactId = spark-streaming-kafka-0-8_2.12
version = 2.4.4import org.apache.spark.streaming.kafka.
val kafkaStream = KafkaUtils.createStream(streamingContext,
[ZK quorum], [consumer group id], [per-topic number of Kafka partitions to consume])
这种情况 程序停掉数据会丢失,为了不丢失自己又写了一份,这种是很多余的。
由于采用了kafka高阶api,偏移量offset不可控。
Direct
Kafka 0.10.0版本以后,采用了更好的一种Direct方式,这种我们需要自己维护偏移量offset。

直连方式 并行度会更高 生产环境用的最多,0.8版本需要在zk或者redis等地方自己维护偏移量。我们使用0.10以上版本支持自己设置偏移量,我们只需要自己将偏移量写回kafka就可以。
依赖
groupId = org.apache.spark
artifactId = spark-streaming-kafka-0-10_2.12
version = 2.4.4kafka 0.10以后 可以将offset写回kafka 我们不需要自己维护offset了,具体代码如下:
val conf = new SparkConf().setAppName("KafkaStreaming").setMaster("local[*]")
val ssc = new StreamingContext(conf,Seconds(2))
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "localhost:9092,anotherhost:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "use_a_separate_group_id_for_each_stream",
//latest none earliest
"auto.offset.reset" -> "earliest",
//自动提交偏移量 false
"enable.auto.commit" -> (false: java.lang.Boolean)
)
//val topics = Array("topicA", "topicB")
val topics = Array("test_topic")
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
// 与kafka broker不在一个节点上 用不同策略
//在一个节点用 PreferBrokers策略 很少见
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams)
)
stream.foreachRDD(rdd => {
//普通的RDD不能强转HasOffsetRanges 但kafkaRDD有 with这个特性 可以强转
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
//处理数据 计算逻辑
rdd.foreachPartition { iter =>
//一次处理一个分区的数据 获取这个分区的偏移量
//计算完以后修改偏移量 要开启事务 类似数据库 connection -> conn.setAutoCommit(false) 各种操作 conn.commit(); conn.rollback()
//获取偏移量 如果要自己记录的话这个
//val o: OffsetRange = offsetRanges(TaskContext.get.partitionId)
//println(s"{o.topic} {o.partition} {o.fromOffset} {o.untilOffset}")
//处理数据
iter.foreach(println)
}
//kafka 0.10新特性 处理完数据后 将偏移量写回kafka
// some time later, after outputs have completed
//kafka有一个特殊的topic 保存偏移量
stream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
})