机器之心报道
Tencent
深度学习是近些年来人工智能技术发展的核心,伴随而来的机器学习框架平台也层出不穷。到现在,一家科技巨头没有一个主导的机器学习平台都不好意思跟人打招呼,比如谷歌有 TensorFlow、微软有 CNTK、Facebook 是 Torch 的坚定支持者、IBM 强推 Spark、百度开源了 PaddlePaddle、亚马逊则是 MXNet 的支持者。而为了尽可能地获得开发者支持和抢占发展先机,很多平台都选择了开源。
在去年 12 月 18 日的腾讯大数据技术峰会暨 KDD China 技术峰会上,腾讯大数据宣布推出了面向机器学习的「第三代高性能计算平台」——Angel,并表示将于 2017 年开放其源代码,参见机器之心报道《腾讯大数据将开源高性能计算平台 Angel,机器之心专访开发团队》。现在,2017 年已经大约过去了一半,Angel 1.0.0 也终于在 GitHub 完全发布:
- Angel 发布地址:https://github.com/Tencent/angel
- 源码下载(.zip):https://github.com/Tencent/angel/archive/v1.0.0.zip
- 源码下载(tar.gz):https://github.com/Tencent/angel/archive/v1.0.0.tar.gz
据介绍,Angel 是腾讯大数据部门发布的「第三代计算平台」,是由腾讯大数据与中国香港科技大学、北京大学联合使用 Java 和 Scala 语言开发的面向机器学习的高性能分布式计算框架。它采用了参数服务器架构,解决了上一代框架的扩展性问题,支持数据并行及模型并行的计算模式,能支持十亿级别维度的模型训练。
不仅如此,Angel 还采用了多种业界最新技术和腾讯自主研发技术,性能更高、系统更具易用性。自去年年初在腾讯内部上线以来,Angel 已应用于腾讯视频、腾讯社交广告及用户画像挖掘等精准推荐业务。Angel 更是腾讯大数据下一代的核心计算平台。
下面,机器之心引用了 Angel 项目的 README.md 文件即其内部相关链接所介绍的内容,对 Angel 的功能、架构设计等内容进行了介绍,代码及最新动态请访问原项目。
Angel 是一个基于参数服务器(Parameter Server)理念开发的高性能分布式机器学习平台,它基于腾讯内部的海量数据进行了反复的调优,并具有广泛的适用性和稳定性,模型维度越高,优势越明显。Angel 由腾讯和北京大学联合开发,兼顾了工业界的高可用性和学术界的创新性。
Angel 的核心设计理念围绕模型。它将高维度的大模型合理切分到多个参数服务器节点,并通过高效的模型更新接口和运算函数,以及灵活的同步协议,轻松实现各种高效的机器学习算法。
Angel 基于 Java 和 Scala 开发,能在社区的 Yarn 上直接调度运行,并基于 PS Service,支持 Spark on Angel,未来将会支持图计算和深度学习框架集成。
欢迎对机器学习有兴趣的同仁一起贡献代码,提交 Issues 或者 Pull Requests。请先查阅 Angel 项目贡献指南:https://github.com/Tencent/angel/blob/master/CONTRIBUTING.md
Angel 1.0.0 新特性
1.ParameterServer 功能
- 基于 Matrix/Vector 的模型自动切分和管理,兼顾稀疏和稠密两种格式
- 支持对 Model 进行 Push 和 Pull 操作,可以自定义复杂的 psFunc
- 提供多种同步控制机制(BSP/SSP/ASP)
2. 开发运行
- 语言支持:系统基于 Scala 和 Java 开发,用户也可以自由选择
- 部署方便:可以直接在 Yarn 社区版本中运行,也支持本地调试模式
- 数据切分: 自动切分读取训练数据,默认兼容了 Hadoop FS 接口
- 增量训练:训练过程中会自动 Checkpoint,而且支持加载模型后,增量训练
3.PS Service
- 只启动 PSServer 和 PSAngent,为其他分布式计算平台提供 PS 服务
- 基于 PS-Service,不需要修改 Spark 核心代码,直接开发 Spark-on-Angel 算法,该模式无缝支持 Breeze 数值运算库
4. 算法库
- 集成 Logistic Regression,SVM,KMeans,LDA,MF,GBDT 等机器学习算法
- 多种优化方法,包括 ADMM,OWLQN,LBFGS 和 GD
- 支持多种损失函数、评估指标,包含 L1、L2 正则项
5. 算法优化
- LDA 采用了 F+LDA 算法用于加速采样的速度,同时利用流式参数获取的方法减少网络参数获取的延迟
- GBDT 使用两阶段树分裂算法,将部分计算转移到 PS,减少网络传输,提升速度
Angel 介绍
1.Angel 的架构设计
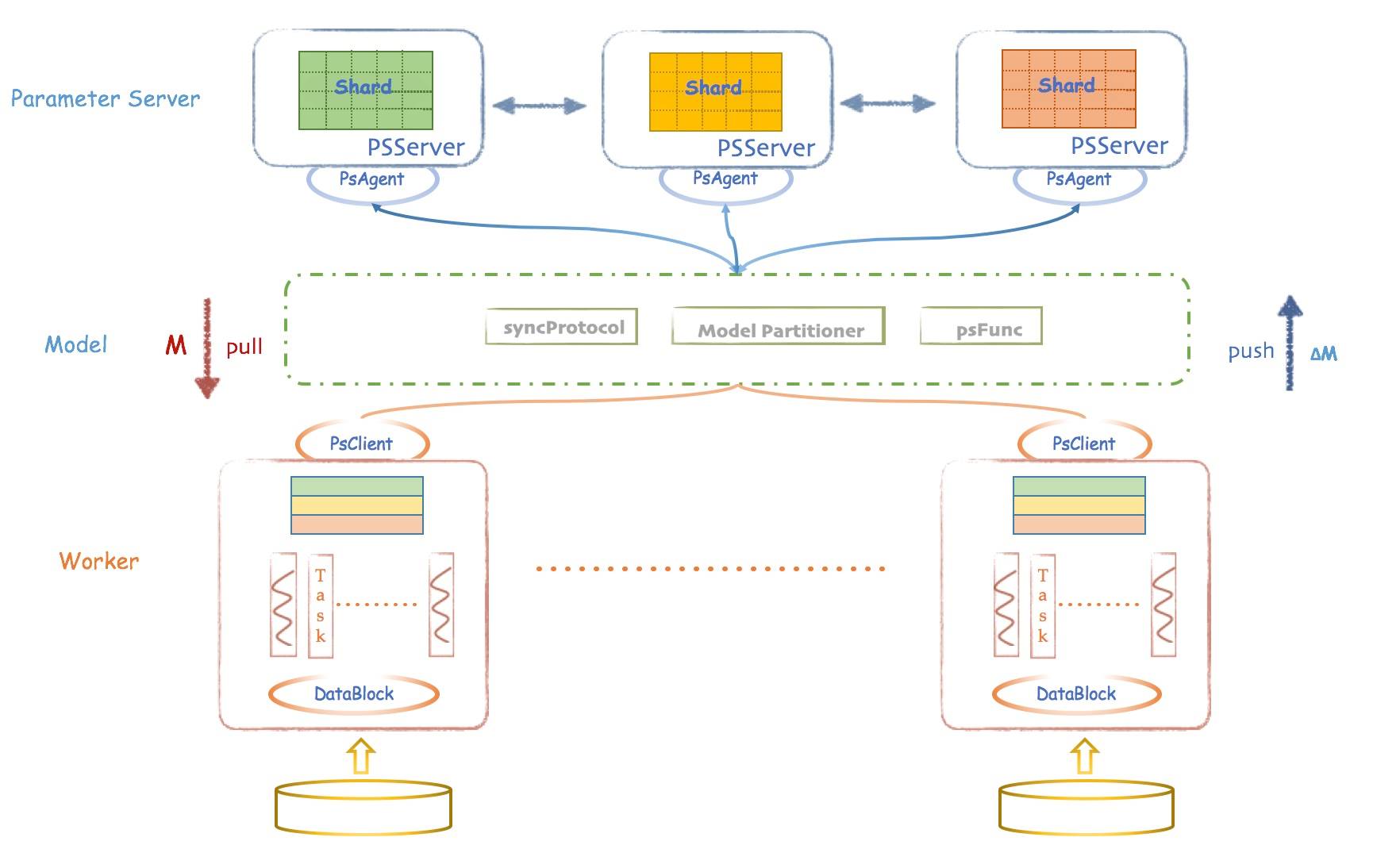
- Client:Angel 的客户端,它给应用程序提供了控制任务运行的功能。目前它支持的控制接口主要有:启动和停止 Angel 任务,加载和存储模型,启动具体计算过程和获取任务运行状态等。
- Master:Master 的职责主要包括:原始计算数据以及参数矩阵的分片和分发;向 Gaia(一个基于 Yarn 二次开发的资源调度系统)申请 Worker 和 ParameterServer 所需的计算资源; 协调,管理和监控 Worker 以及 ParameterServer。
- Parameter Server:ParameterServer 负责存储和更新参数,一个 Angel 计算任务可以包含多个 ParameterServer 实例,而整个模型分布式存储于这些 ParameterServer 实例中,这样可以支撑比单机更大的模型。
- Worker:Worker 负责具体的模型训练或者结果预测,为了支持更大规模的训练数据,一个计算任务往往包含许多个 Worker 实例,每个 Worker 实例负责使用一部分训练数据进行训练。一个 Worker 包含一个或者多个 Task,Task 是 Angel 计算单元,这样设计的原因是可以让 Task 共享 Worker 的许多公共资源。
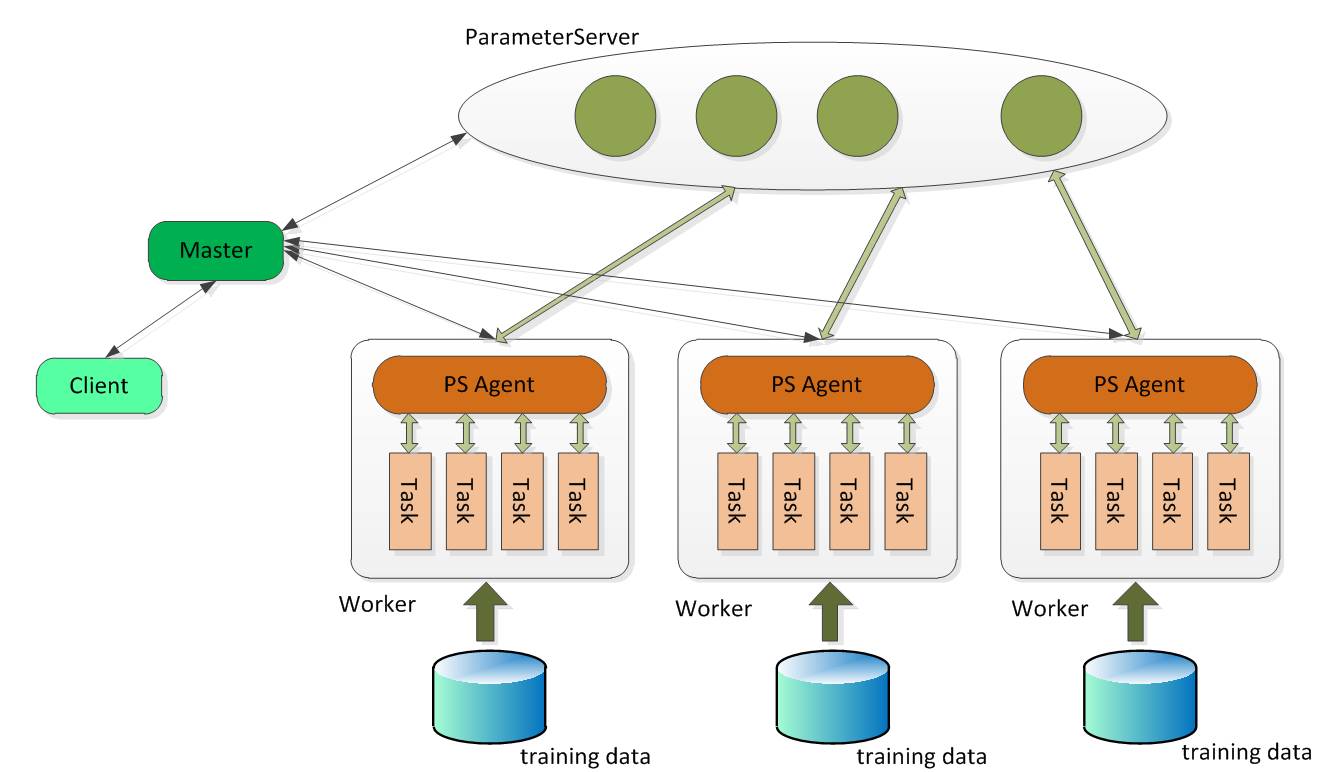
2.Angel 的系统框架
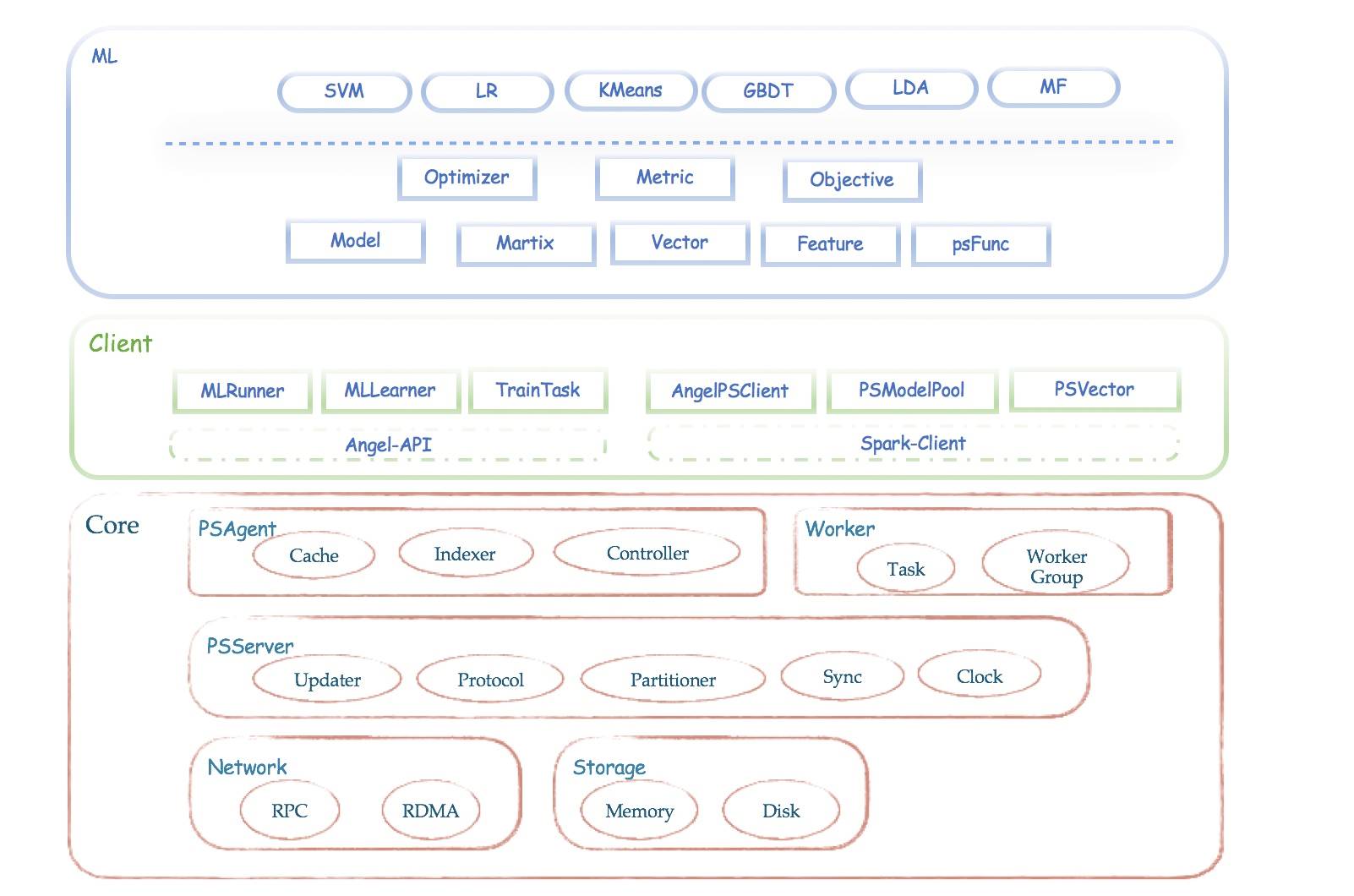
3.Angel 的设计理念
PS Service
Angel 支持两种运行模式:ANGEL_PS & ANGEL_PS_WORKER
- ANGEL_PS: PS Service 模式,在这种模式下,Angel 只启动 Master 和 PS,具体的计算交给其他计算平台(如 Spark,Tensorflow)负责,Angel 只负责提供 Parameter Server 的功能。
- ANGEL_PS_WORKER:启动 Master,PS 和 Worker,Angel 独立完成模型的训练。
同步协议
- 支持多种同步协议:除了通用的 BSP(Bulk Synchronous Parallel)外,为了解决 task 之间互相等待的问题,Angel 还支持 SSP(Stale Synchronous Parallel)和 ASP(Asynchronous Parallel)
良好的可扩展性
- psf(ps function):为了满足各类算法对参数服务器的特殊需求,Angel 将参数获取和更新过程进行了抽象,提供了 psf 函数功能。用户只需要继承 Angel 提供的 psf 函数接口,并实现自己的参数获取/更新逻辑,就可以在不修改 Angel 自身代码的情况下定制自己想要的参数服务器的接口。
- 自定义数据格式:Angel 支持 Hadoop 的 InputFormat 接口,可以方便的实现自定义文件格式。
- 自定义模型切分方式:默认情况下,Angel 将模型(矩阵)切分成大小相等的矩形区域;用户也可以自定义分区类来实现自己的切分方式。
易用性
- 训练数据和模型自动切割:Angel 根据配置的 worker 和 task 数量,自动对训练数据进行切分;同样,也会根据模型大小和 PS 实例数量,对模型实现自动分区。
- 易用的编程接口:MLModel/PSModel/AngelClient
容错设计和稳定性
- PS 容错
PS 容错采用了 checkpoint 的模式,也就是每隔一段时间将 PS 承载的参数分区写到 hdfs 上去。如果一个 PS 实例挂掉,Master 会新启动一个 PS 实例,新启动的 PS 实例会加载挂掉 PS 实例写的最近的一个 checkpoint,然后重新开始服务。这种方案的优点是简单,借助了 hdfs 多副本容灾,而缺点就是不可避免的会丢失少量参数更新。
- Worker 容错
一个 Worker 实例挂掉后,Master 会重新启动一个 Worker 实例,新启动的 Worker 实例从 Master 处获取当前迭代轮数等状态信息,从 PS 处获取最新模型参数,然后重新开始被断掉的迭代。
- Master 容错
Master 定期将任务状态写入 hdfs,借助与 Yarn 提供的 App Master 重试机制,当 Angel 的 Master 挂掉后,Yarn 会重新拉起一个 Angel 的 Master,新的 Master 加载状态信息,然后重新启动 Worker 和 PS,从断点出重新开始计算。
- 慢 Worker 检测
Master 会将收集一些 Worker 计算性能的一些指标,如果检测到有一些 Worker 计算明显慢于平均计算速度,Master 会将这些 Worker 重新调度到其他的机器上,避免这些 Worker 拖慢整个任务的计算进度。
4.Spark on Angel
Angel 在 1.0 版本开始,就加入了 PS-Service 的特性,不仅仅可以作为一个完整的 PS 框架运行,也可以作为一个 PS-Service,为不具备参数服务器能力的分布式框架,引入 PS 能力,从而让它们运行得更快,功能更强。而 Spark 是这个 Service 设计的第一个获益者。
作为一个比较流行的内存计算框架,Spark 的核心概念是 RDD,而 RDD 的关键特性之一,是其不可变性,来规避分布式环境下复杂的各种并行问题。这个抽象,在数据分析的领域是没有问题的,能最大化的解决分布式问题,简化各种算子的复杂度,并提供高性能的分布式数据处理运算能力。
然而在机器学习领域,RDD 的弱点很快也暴露了。机器学习的核心是迭代和参数更新。RDD 凭借着逻辑上不落地的内存计算特性,可以很好的解决迭代的问题,然而 RDD 的不可变性,却不适合参数反复多次更新的需求。这个根本的不匹配性,导致了 Spark 的 MLLib 库,发展一直非常缓慢,从 15 年开始就没有实质性的创新,性能也不好,从而给了很多其它产品机会。而 Spark 社区,一直也不愿意正视和解决这个问题。
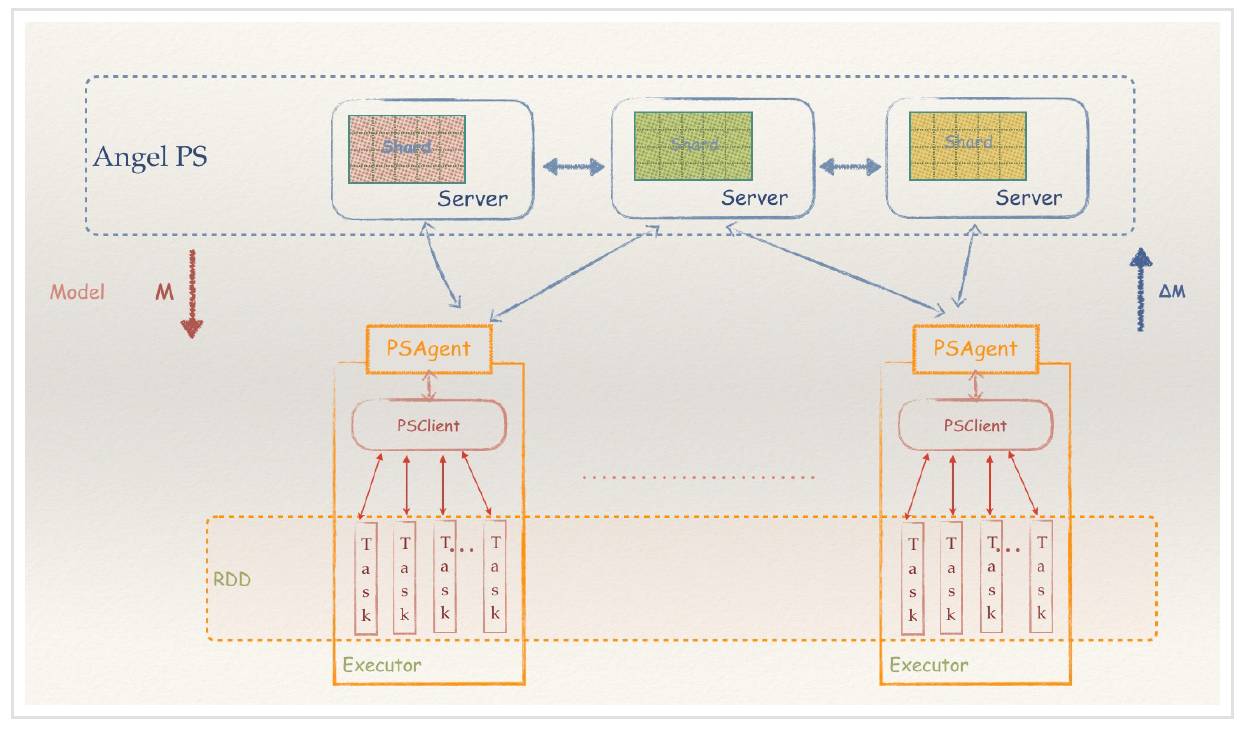
Spark-On-Angel 的系统架构
现在,由于 Angel 良好的设计和平台性,提供 PS-Service,Spark 可以充分利用 Angel 的参数更新能力,用最小化的修改代价,让 Spark 也具备高速训练大模型的能力,并写出更加优雅的机器学习代码,而不必绕来绕去。
更多详情,请参阅:https://github.com/Tencent/angel/blob/master/docs/overview/spark_on_angel.md
Angel 快速入门指南
准备知识
这篇文档帮助你快速开始编写运行在 Angel-PS 架构上的程序,开始之前,你最好掌握以下能力:
- 会编写简单的 Scala 或者 Java 代码
- 掌握向量、矩阵和张量的基础知识,了解其定义和基础计算。
- 最好对机器学习算法有一定了解
如果没有学习过机器学习算法,也没有关系,你可以从这篇文档开始。在开始编程前,我们先来了解一些基础知识。
- 大多数的机器学习算法都可以抽象成向量(Vector)、矩阵 (Martix),张量(Tensor)间的运算,用向量、矩阵、张量来表示学习数据和算法模型。
- Angel-PS 实现了基于参数服务器的矩阵计算,将分布在多台 PS Server 上的参数矩阵抽象为 PSModel,你只需要完成 PSModel 的定义、实现其计算过程,就可以实现一个运行在参数服务器上的简单算法。
Angel-PS 架构
简单的 Angel-PS 架构如下图所示
- PS 是存储矩阵参数的多台机器,向计算节点提供矩阵参数的拉取、更新服务
- 每个 worker 是一个逻辑计算节点,一个 worker 可以运行一或多个 task
机器学习的算法,一般以迭代的方式训练,每次迭代 worker 从 PS 拉取最新的参数,计算一个更新值,推送给 PS。
开始你的第一个 Angel 算法: LR
本示例将以最简单的 Logistic Regression 算法为例,指导你完成第一个 Angel 算法。代码可以在 example.quickStart 里找到。
逻辑回归算法是机器学习中最简单的一个算法,它可以抽象为如下步骤:
1. 一个维度为 1×N 的矩阵,即一个 N 维向量,记为 w
2. 用梯度下降法训练 LR 模型,每次迭代
- task 从 PS 拉取最新的模型 w,
- 计算得到变化梯度△w
- 将△w 推送给 PS
为了实现该算法,我们需要如下 3 个步骤:
1. 定义一个模型 (LRModel)
实现 LRModel 类继承 MLModel,通过 addPSModel 添加一个 N 维的 PSModel 给 LRModel,在 setSavePath 方法中,设置运算结束后 LR 模型的保存路径。
N 的值、保存路径都可以通过 conf 配置。

2. 定义一个 Task(TrainTask)
Angel 的模型的训练是在 task 中完成,所以我们需要定义一个 LRTrainTask 来完成 LR 的模型的训练过程。
LRTrainTask 需要继承 TrainTask 类并实现如下 2 个方法:
- 解析数据
在模型开始训练前,输入的每一行文本被解析为一条训练数据,解析方法在 parse 方法里实现,此处我们使用 DataParser 解析 dummy 格式的数据。
override
def parse(key: LongWritable, value: Text): LabeledData = {
DataParser.parseVector(key, value, feaNum, "dummy", negY = true)
}
可以通过 task 的 dataBlock 访问预处理后的数据。
- 训练
Angel 会自动执行 TrainTask 子类的 train 方法,我们在 LRTrainTask 的 train 方法中完成模型训练过程。
在这个简易的 LR 算法例子中,我们
- 先实例化 myLRModel 模型对象 model,然后开始迭代计算。
- 每次迭代
- task 从 PS 拉取模型的参数 weight
- 训练数据计算得到梯度 grad,把 grad 推送给 PS,PS 上 weight 的更新会自动完成。
- 推送 grad 后,需要 clock()、incIteration()。
override
def train(ctx: TaskContext): Unit = {
// A simple logistic regression model
val model = new LRModel(ctx, conf)
// Apply batch gradient descent LR iteratively
while (ctx.getIteration < epochNum) { // Pull model from PS Server
val weight = model.weight.getRow(0)
// Calculate gradient vector
val grad = bathGradientDescent(weight)
// Push gradient vector to PS Server
model.weight.increment(grad.timesBy(-1.0 * lr))
// LR model matrix clock
model.weight.clock.get
// Increase iteration number
ctx.incIteration()
}
}
3. 定义一个 Runner(MLRunner)
前面,我们定义了 LR 模型,实现了它的训练过程。现在,还需要实现 Runner 类将训练这个模型的任务提交到集群。
定义 myLRRunner 类继承 MLRunner,在 train 方法中提交我们的 myLRModel 的模型类、和 myLRTrainTak 训练类就可以了。
class LRRunner extends MLRunner{
…… override
def train(conf: Configuration): Unit = {
train(conf, myLRModel(conf), classOf[myLRTrainTask])
}
}
运行任务
可以通过以下命令向 Yarn 集群提交刚刚完成的算法任务
./bin/angel-submit \
--action.type train \
--angel.app.submit.class com.tencent.angel.example.quickStart.myLRRunner \
--angel.train.data.path $input_path \
--angel.save.model.path $model_path \
--ml.epoch.num 10 \
--ml.feature.num 10000 \
--ml.data.type dummy \
--ml.learn.rate 0.001 \
--angel.workergroup.number 3 \
--angel.worker.memory.mb 8000 \
--angel.worker.task.number 3 \
--angel.ps.number 1 \
--angel.ps.memory.mb 5000 \
--angel.job.name myLR
提交完毕后,可以按照这个指引,《查看到 Yarn 上的作业》,如果你不熟悉 Yarn 的话:https://github.com/Tencent/angel/blob/master/docs/deploy/run_on_yarn.md
OK。至此,你已经完成了一个简单的 Angel 作业。想写出更加复杂的机器学习算法吗?请看完整的《Angel 编程指南》吧,欢迎来到 Angel 的世界:https://github.com/Tencent/angel/blob/master/docs/programmers_guide/angel_programing_guide.md
你也可以在这里查看 Spark on Angel 快速入门:https://github.com/Tencent/angel/blob/master/docs/tutorials/spark_on_angel_quick_start.md
编程手册
- Angel 编程手册:https://github.com/Tencent/angel/blob/master/docs/programmers_guide/angel_programing_guide.md
- Spark on Angel 编程手册:https://github.com/Tencent/angel/blob/master/docs/programmers_guide/spark_on_angel_programing_guide.md
设计
- 核心类的说明:https://github.com/Tencent/angel/blob/master/docs/apis/interface_api.md
- psFunc 手册:https://github.com/Tencent/angel/blob/master/docs/design/psf_develop.md
算法
这里介绍了 Angel 支持的几种算法,详情请参看原项目:
- logistic 回归(Logistic Regression)
- 矩阵分解(Matrix Factorization)
- 支持向量机(SVM)
- K-均值(KMeans)
- GBDT
- LDA
- Spark on Angel Optimizer
部署
源码下载和编译
1. 编译环境依赖
- Jdk >= 1.8
- Maven >= 3.0.5
- Protobuf >= 2.5.0
2. 源码下载
git clone https://github.com/Tencent/angel
3. 编译
进入源码根目录,执行命令:
mvn clean package -Dmaven.test.skip=true
编译完成后,在源码根目录 dist/target 目录下会生成一个发布包:angel-1.0.0-bin.zip
4. 发布包
发布包解压后,根目录下有四个子目录:
- bin:Angel 任务提交脚本
- conf:系统配置文件
- data:简单测试数据
- lib:Angel jar 包 & 依赖 jar 包
本地运行
1. 运行环境准备
- Hadoop >= 2.2.0
- Java 1.8 版本
- Angel 发布包 angel-1.0.0-bin.zip
配置好 HADOOP_HOME 和 JAVA_HOME 环境变量,解压 Angel 发布包,就可以以 LOCAL 模式运行 Angel 任务了。
2.LOCAL 运行例子
发布包解压后,在根目录下有一个 bin 目录,提交任务相关的脚本都放在该目录下。例如运行简单的逻辑回归的例子:
./angel-example com.tencent.angel.example.SgdLRLocalExample
3. Yarn 运行:https://github.com/Tencent/angel/blob/master/docs/deploy/run_on_yarn.md
4. 系统配置:https://github.com/Tencent/angel/blob/master/docs/deploy/config_details.md
论文
目前腾讯还没公开发布相关论文,可关注本项目查看更新。

本文为机器之心报道,转载请联系本公众号获得授权。