本文是对prompt Learning在CV领域的文献总结,读者阅读完全文会对prompt learning在CV的各种用法有所了解,希望能对大家未来研究工作有所启发。
CLIP(Learning Transferable Visual Models From Natural Language Supervision)
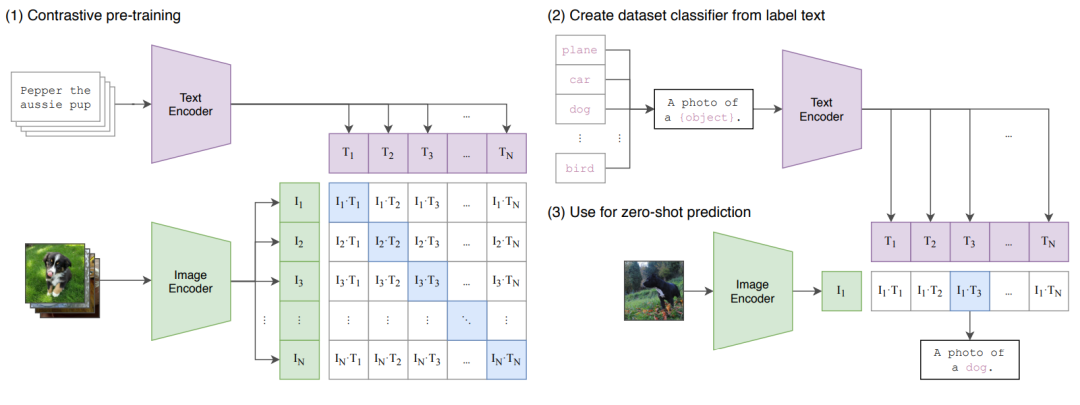
CLIP是OpenAI的一个非常经典的工作,从网上收集了4亿个图片文本对用于训练,最后进行zero-shot transfer到下游任务达到了非常好的效果,主要流程如下:
在训练阶段,文本会通过Text Encoder(Transformer)编码成一些文本Embedding向量,图像会通过Image Encoder(ResNet50或VIT)编码成一些图像Embedding向量,然后将文本Embedding和图像Embedding归一化后通过点积计算出一个相似度矩阵,这里值越接近于1代表文本Embedding和图像Embedding越相似,即这个文本和图像是配对的。我们的目标是让这个相似度矩阵对角线趋向于1,其他趋向于0(对角线代表图像和文本配对)。
测试zero-shot阶段,会将一张没见过的图片通过image Encoder得到图像embedding,然后将所有可能的类别,通过构造a photo of a {object}的文本标签,将所有类别填入object处,通过text encoder,得到所有类别对应的文本embedding,将文本embedding和图像embedding归一化后进行点积,选择点积最大的一个文本-图像对,该类别则为预测类别。
CoOp: Learning to Prompt for Vision-Language Models

CoOp的motivation如上图所示:CLIP是固定prompt:a photo of a [class],但是不同prompt的影响影响很大,比如从图a可以看出,少了一个a,acc直接低了6个点。每次根据人工设计prompt太麻烦,设计的还不一定好,那怎么办呢?熟悉nlp的prompt的小伙伴应该脱口而出了,应该像Prefix Tuning一样,学一个连续的prompt不就完事了吗?CoOp就是这么做的。
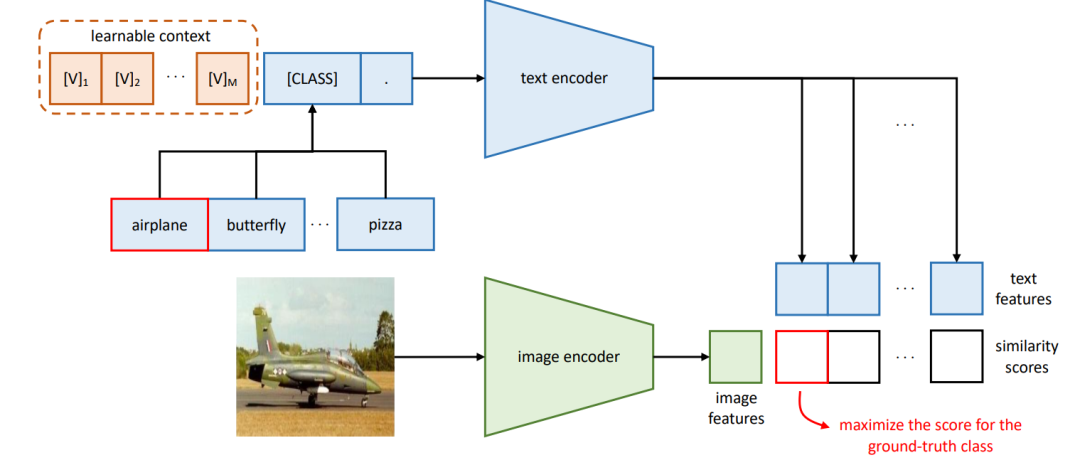
CoOp从原来a photo fo a [class]转换成
这样可学习的连续的prompt,这样就不需要人工去设计prompt了。这里的prompt分为unified和class-specific两种,unified context即对所有类别都是学一组一样的prompt参数,class-specific context指的是对每一个类别学一个单独的prompt 参数,事实证明后者对一些细粒度的任务效果比较好。(看到这里的小伙伴可能有一个疑惑,还有instance-specific context这种更细粒度的可能,为啥这里没提呢?因为当时作者没想好怎么设计,想好之后又写了一篇CoCoOp)另外这里prompt里的[CLASS]不一定要放最后,也可以放句中,那这样学习明显更加灵活。

在实验这有一个有意思的发现:nlp领域有一篇叫OptiPrompt的文献,提出连续的prompt不一定要随机初始化,可以用人工设计的prompt的embedding初始化来引入专家经验,CoOp做实验发现就算prompt参数是随机初始化的也能到达一样的效果。
CoCoOp: Conditional Prompt Learning for Vision-Language Models

CoCoOp的motivation如上图所示:作者发现他们之前提的CoOp在训练过类别的数据集上表现的很好,但是面对新的类别,能力却很差,从80的acc降到65,而原版的CLIP却保持了还不错的泛化能力,引起了作者思考,作者认为这是因为CoOp在下游任务上训练时容易overfit base classes上。我认为一这个本质原因一方面因为用的prompt是unified或者class-specific,而不是instance-specific context,另一方面我认为用unified也可以,但是要有足够的数据学到真正的unified的特征。
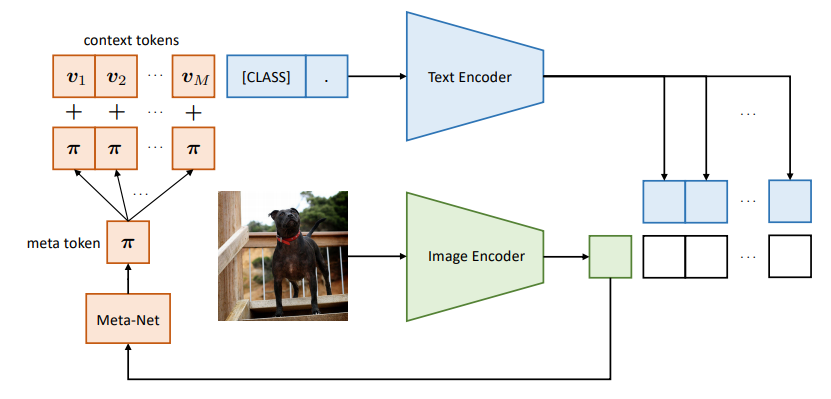
CoCoOp的做法很简单,他在CoOp的基础上,引入了一个轻量的网络Meta-Net(仅仅是Linear-ReLU-Linear),将image Encoder的输出通过Meta-Net得到一个M维的向量,将这M维的向量直接加在CoOp上的每一个prompt token上,通过这种方式做到instance-specific context。这种方式其实就是把每个图片的特征引入了prompt的构造里,所以CoCoOp的第一个Co就是指这种Conditional。
DenseCLIP: Language-Guided Dense Prediction with Context-Aware Prompting
由于这一系列的介绍主要围绕prompt进行,所以这篇文献也主要讲讲prompt设计那部分:

作者提出了prompt构造的2种方式,一种叫Pre-model prompting,即将图像通过image encoder之后得到图像embedding,这个embedding将作为Transformer的k和v输入进一个Decoder里面生成一个prompt的模板。这种方式和CoCoOp就挺像的,只不过CoCoOp是用一个很简单的backbone生成一个M维的token,再把这个token加在原来CoOp上生成的每一个prompt向量,这里是直接用一个更复杂的backbone直接生成一个prompt;第二种是Post-model prompting,即将图像通过image encoder之后得到图像embedding,然后作为k和v输入进decoder,这里decoder的query是CoOp生成模板加上[class]后的文本通过text encoder的文本embedding,通过decoder生成一个
和文本向量做相加来更新文本特征,经过实验发现第二种方式更好。从直观上也很好理解,因为这样的prompt image encoder和text encoder都参与了。
Unifying Vision-and-Language Tasks via Text Generation
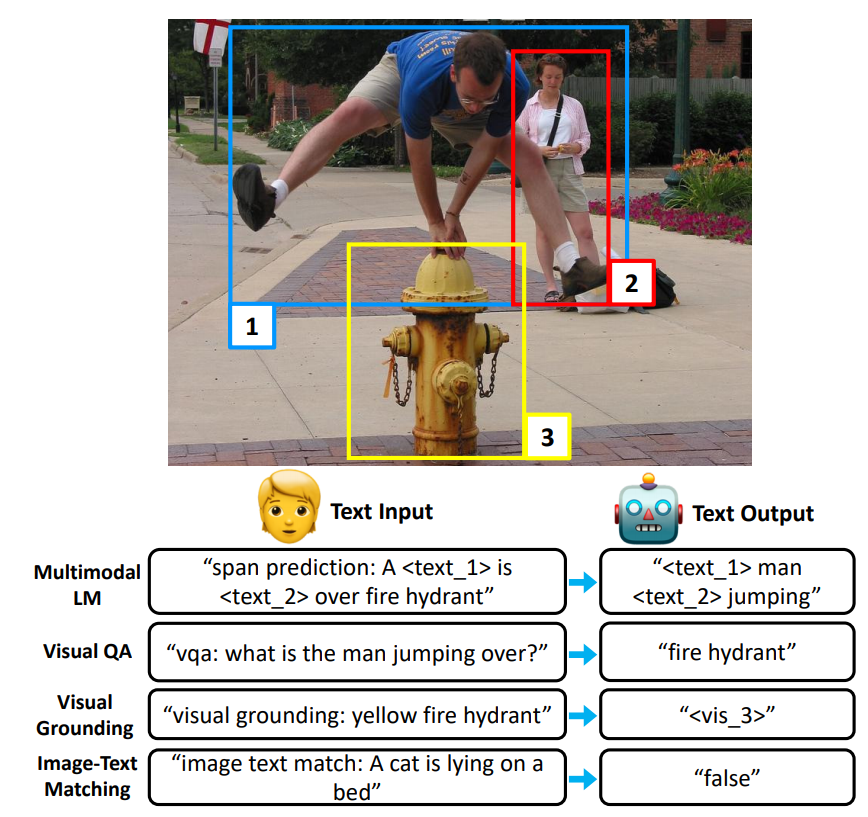
现在vision-language learning的方法都是task-specific的,即要为每个下游任务特别设计,本文利用prompt设计来兼容7个下游任务的学习,如上图所示,对不同的下游任务只需要加上不同的文本前缀即可,比如一个视觉问答的任务就加上vqa,对visual grounding的任务就加上visual grounding即可。具体模型如下所示:

整体流程是一个encoder-docoder的结构,encoder部分将prefix prompt、text embedding、 visual embedding作为输入,其中visual embedding由faster-rcnn提取的ROl features、Box coordinates, image ides, region ids构成,把encoder输出的结果传递给一个自回归的decoder得到模型的输出。不同下有任务模板如下所示:

MAnTiS:Multimodal Conditionality for Natural Language Generation
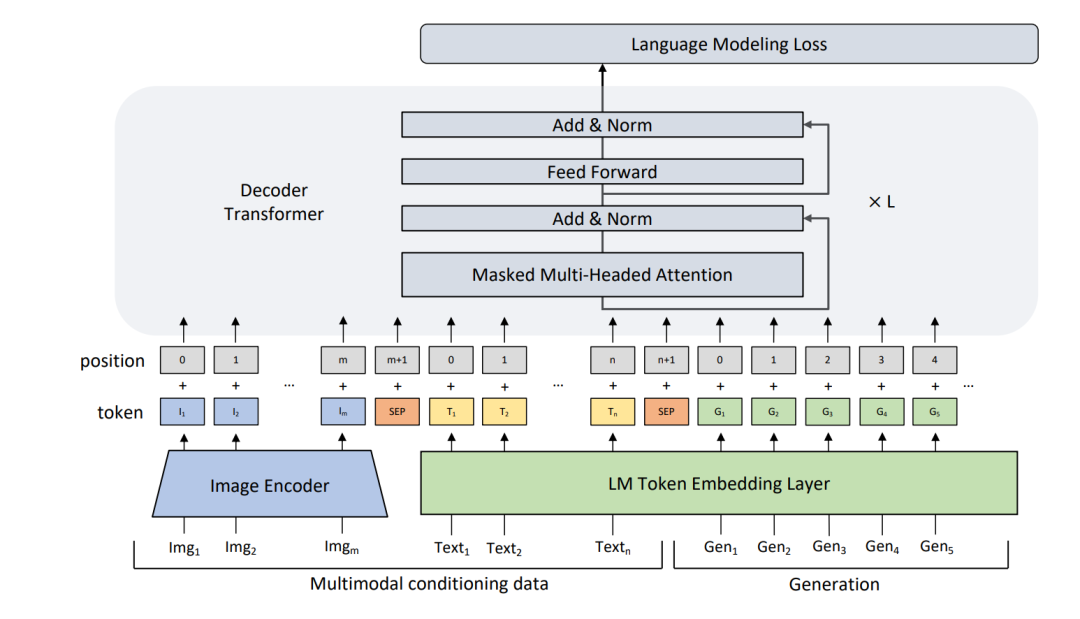
这篇文章把prompt用在了商品的文案生成上,首先用ResNet-152作为image encoder提取视觉特征,提取出的视觉特征会用一个linear layer映射到文本embedding的维度;商品名称和我们希望生成的文案会通过LM Token Embedding Layer提取文本特征,这里用的GPT-2。不同数据之间会用SEP分开,然后输入进一个decoder生成文案。效果如下:

MAPLE: MULTI-MODAL PROMPT LEARNING

这篇文章的出发点很有新意,一直以来我们做prompt都是在图片或者文本一个模态做prompt,这篇文章觉得只在其中一个模态(分支)做prompt只能达到次优的性能,所以他们提出应该在每一个模态都应该做prompt,示意图如上所示。
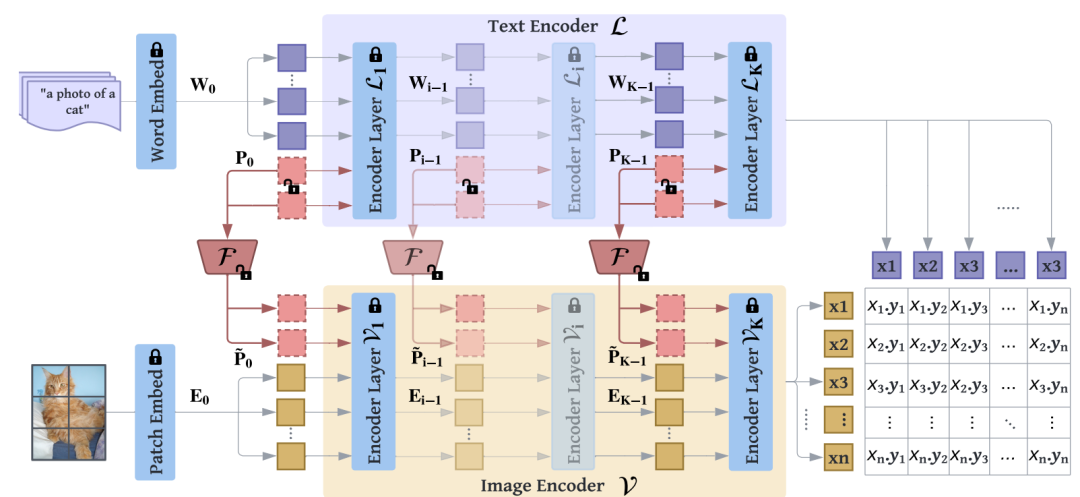
模型架构图如上所示:首先文本端除了文本的输入embedding,会拼接一些文本prompt向量,图像端同样除了图像的embedding输入,也会拼接一些图像prompt向量。这里要注意,这两个prompt向量是有交互的,因为作者认为为了让prompt发挥拉近不同模态距离的作用,不同模态的prompt应该要深层交互。具体交互的做法就是将文本prompt的embedding,通过一个linear层 映射到图像embedding维度,转换成图像prompt向量,但这个交互只会发生在前J层,后面J-K层就不需要交互了,因为作者认为经过前面的交互,后面层的特征已经不是各自独立模态的特征了,自然不需要交互了。
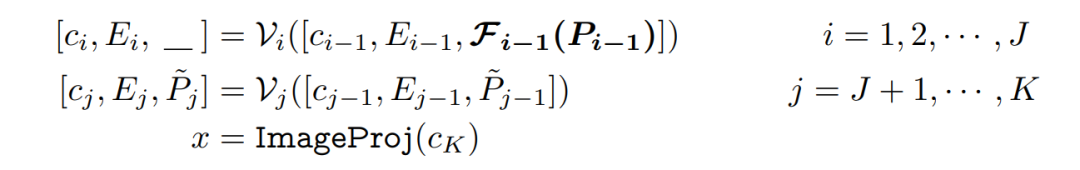
CPT:Colorful Prompt Tuning for Pre-Training Vision-Language Models
这篇文章是prompt用在image grounding的工作,我认为他的出发点十分值得思考:
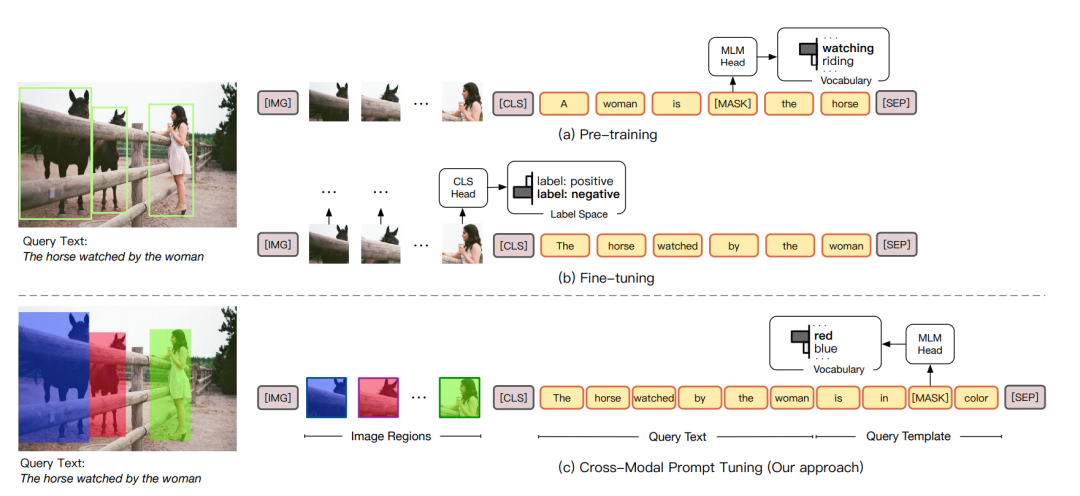
一般用Pre-Training Vision-Language Models做image grounding的做法如上图b所示,他们的做法是去随机mask一些词然后通过预测这个随机的MASK来完成预训练的任务。在预测即下游任务时,对没有mask的token做语义分类,来完成grounding的任务。那这样就会存在一个gap:因为你预训练的时候是去预测一些mask的token,而到下游任务时预测的token是非mask,那这样上下游的迁移就有可能会有问题,那为什么nlp不会有问题呢?我认为是对于文字来说,理解哪里的文字理解的方式是一样的,但是对于视觉是不一样的,比如我学会了人在“看”马这个看的概念,那和哪个是人,哪个是马来说这两个问题来说,我认为学会人在“看”马是一个不同等级的概念(可能是更高的),那这么来做效果就不一定会好了。所以CPT把问题转换为颜色预测的任务:看一些被涂上不同颜色的图片,然后把文本当作问题,最后回答什么颜色的图片是问题的答案并填空,再换句话说,原来想问你在一张人在看马的图片里,哪个是人,现在直接问你,什么颜色的人在看马,因为我们知道哪块被填上了颜色,所以解决了这个问题。
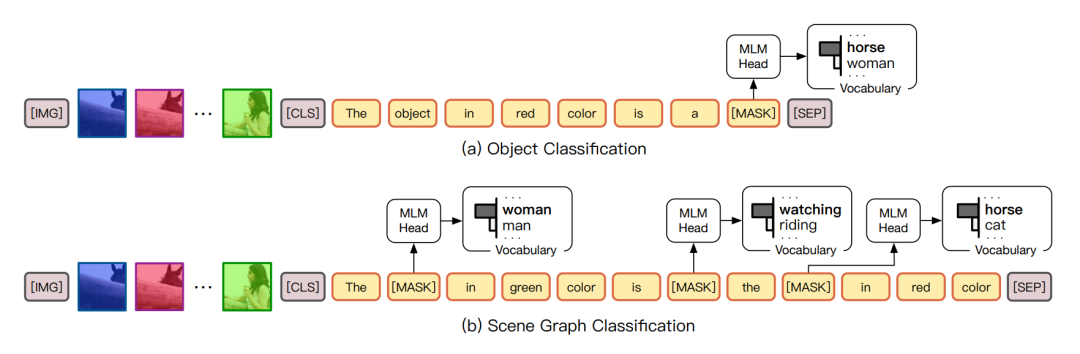
这个方法在zero shot、few shot 场景下取得了非常好的表现,除了image grounding,CPT也提出了别的下游任务建模方式:对目标分类任务,可以建模为红颜色的物体是一个什么,具体如上所示。
Multimodal Few-Shot Learning with Frozen Language Models
这篇文章讲故事的点很有意思,他认为之前对于文本大模型的prompt,都是在前面加上prefix prompt来提示做什么下游任务,然后可能和视觉模型一起微调或者冻住文本大模型来完成。这篇文章认为配对的图像特征就是一种prompt,我们可以利用这个文本配对的图像提取特征作为我们的prompt,具体结构如下所示:
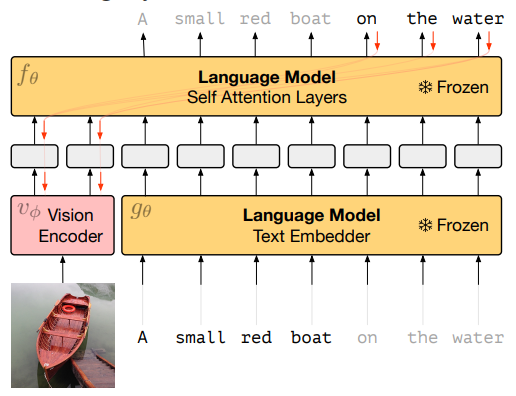
将图像通过一个NF-ResNet50提取特征,然后将一些文本通过一个text embedder提取特征,然后一起输入进一个在大数据集下预训练好的7billion参数的Transformer进行自回归预测完成训练,其中只有vision Encoder是可训练的,其他模块皆冻结。这样prompt的模型可以在很多场景的zero-shot和few-shot达到一个好的效果。其中作者还提到,在面对一个新的下游任务时,我们可以输一些图像文本对让模型学习到新的概念,这样会在下游任务上表现的更好,具体如下所示:
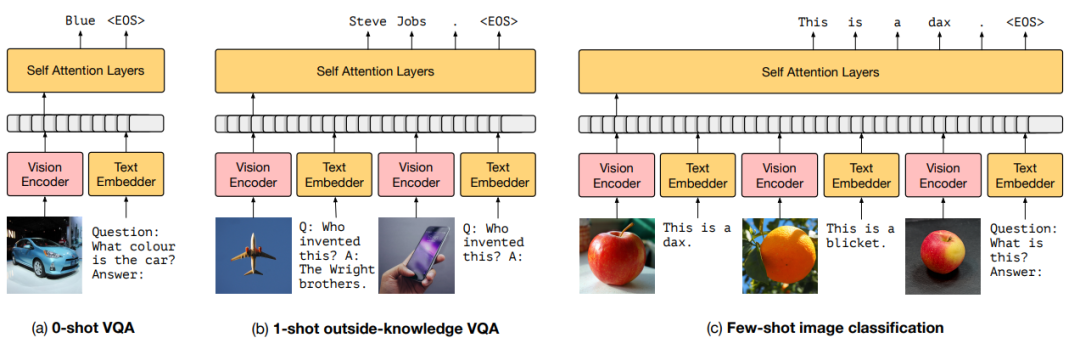
VPT:Visual Prompt Tuning
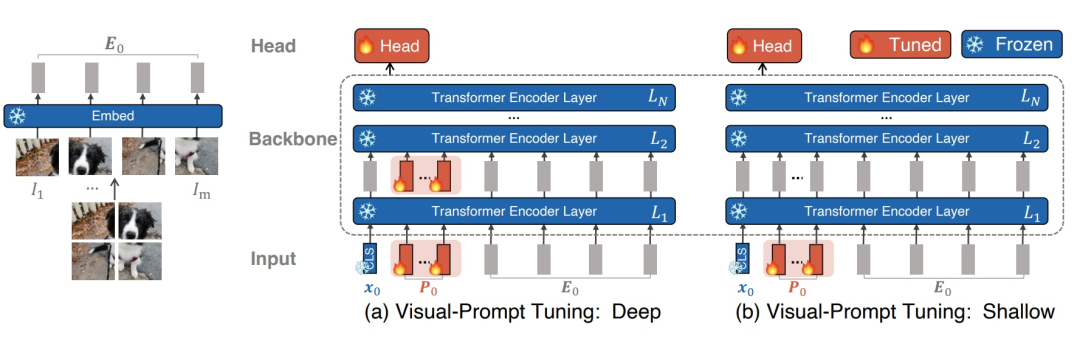
终于看到一篇不用文本来做视觉prompt的文章了。VPT分为deep和shallow两个版本,如果数据不充裕,就使用shallow版本,如果数据充裕,就使用Deep版本。我们可以看到VPT真的很简单,shallow版本只需要在第一层输入层之前,引入一些prompt参数,和CLS和其他输入embedding一起拼接起来输入进第一个Transformer的encoder即可。但是如果数据充裕,那自然我们觉得仅仅在输入引入prompt没法很好的利用这么多数据(说白点就是可学习参数少了),所以在每一层Transformer的输入层前都加入一些prompt参数学习。不管是shallow还是deep版本,都只需要学习输入的prompt参数和分类头。这篇文章的做法可以说是mainly-motivated by prefix-tuning/p-tuning的了,所以提示我们可以再找找nlp里work的prompt方法,看看怎么在cv上做work。